







Disclaimer: This article is translated by DeepL, there is the original post in Chinese.
Background
ClickHouse, an open source OLAP engine, is widely used in the Big Data ecosystem for its outstanding performance. Unlike Hadoop ecosystem components that usually rely on HDFS as the underlying data storage, ClickHouse uses local disk to manage data itself, and the official recommended uses SSDs as storage media to improve performance. One of JuiceFS's customers recently encountered such a problem and wanted to migrate the warm and cold data in ClickHouse from SSD to a larger capacity and lower cost storage to better support business.
JuiceFS is an open source distributed file system based on object storage and fully compatible with POSIX, while the data caching features of JuiceFS can intelligently manage query hot data, which is ideal as a storage system for ClickHouse.
Introduction to MergeTree storage format
MergeTree is the main storage engine used by ClickHouse, when creating a table you can specify one or more fields as partitioned fields with the PARTITION BY statement, the data on the disk directory structure is similar to the following form.
$ ls -l /var/lib/clickhouse/data/<database>/<table>
drwxr-xr-x 2 test test 64B Mar 8 13:46 202102_1_3_0
drwxr-xr-x 2 test test 64B Mar 8 13:46 202102_4_6_1
drwxr-xr-x 2 test test 64B Mar 8 13:46 202103_1_1_0
drwxr-xr-x 2 test test 64B Mar 8 13:46 202103_4_4_0Take 202102_1_3_0 as an example, 202102 is the name of the partition, 1 is the smallest block number, 3 is the largest block number, and 0 is the depth of the MergeTree. You can see that the partition 202102 has more than one directory, because ClickHouse generates a new directory every time it writes, and it is immutable once written. Each directory is called a part, and as the number of parts grows ClickHouse does a compaction of multiple parts in the background, the usual advice is not to keep too many parts, otherwise it will affect query performance.
Each part directory is composed of many small and large files, which contain both data and meta information, a typical directory structure is as follows:
$ ls -l /var/lib/clickhouse/data/<database>/<table>/202102_1_3_0
-rw-r--r-- 1 test test ? Mar 8 14:06 ColumnA.bin
-rw-r--r-- 1 test test ? Mar 8 14:06 ColumnA.mrk
-rw-r--r-- 1 test test ? Mar 8 14:06 ColumnB.bin
-rw-r--r-- 1 test test ? Mar 8 14:06 ColumnB.mrk
-rw-r--r-- 1 test test ? Mar 8 14:06 checksums.txt
-rw-r--r-- 1 test test ? Mar 8 14:06 columns.txt
-rw-r--r-- 1 test test ? Mar 8 14:06 count.txt
-rw-r--r-- 1 test test ? Mar 8 14:06 minmax_ColumnC.idx
-rw-r--r-- 1 test test ? Mar 8 14:06 partition.dat
-rw-r--r-- 1 test test ? Mar 8 14:06 primary.idxAmong the more important files are:
primary.idx: this file contains the primary key information, but not the primary key of all the rows of the current part, the default will be stored in accordance with the 8192 interval, that is, every 8192 rows to store the primary key.ColumnA.bin: this is the data of a column after compression,ColumnAis just an alias for this column, the actual situation will be the real column name. The compression is done in blocks as the smallest unit, and the size of each block varies from 64KiB to 1MiB.ColumnA.mrk: This file holds the offset of each block in the correspondingColumnA.binfile after and before compression.partition.dat: This file contains the partition IDs after the partition expression has been calculated.minmax_ColumnC.idx: This file contains the minimum and maximum values of the raw data corresponding to the partition fields.
JuiceFS-based storage and computation separation solution
Since JuiceFS is fully POSIX-compatible, it is possible to use the JuiceFS-mounted filesystem directly as a ClickHouse disk. In this case, the data is written directly to JuiceFS, and in combination with the cache disk configured for the ClickHouse node, the hot data involved in the query is automatically cached locally on the ClickHouse node. The overall solution is shown in the figure below.
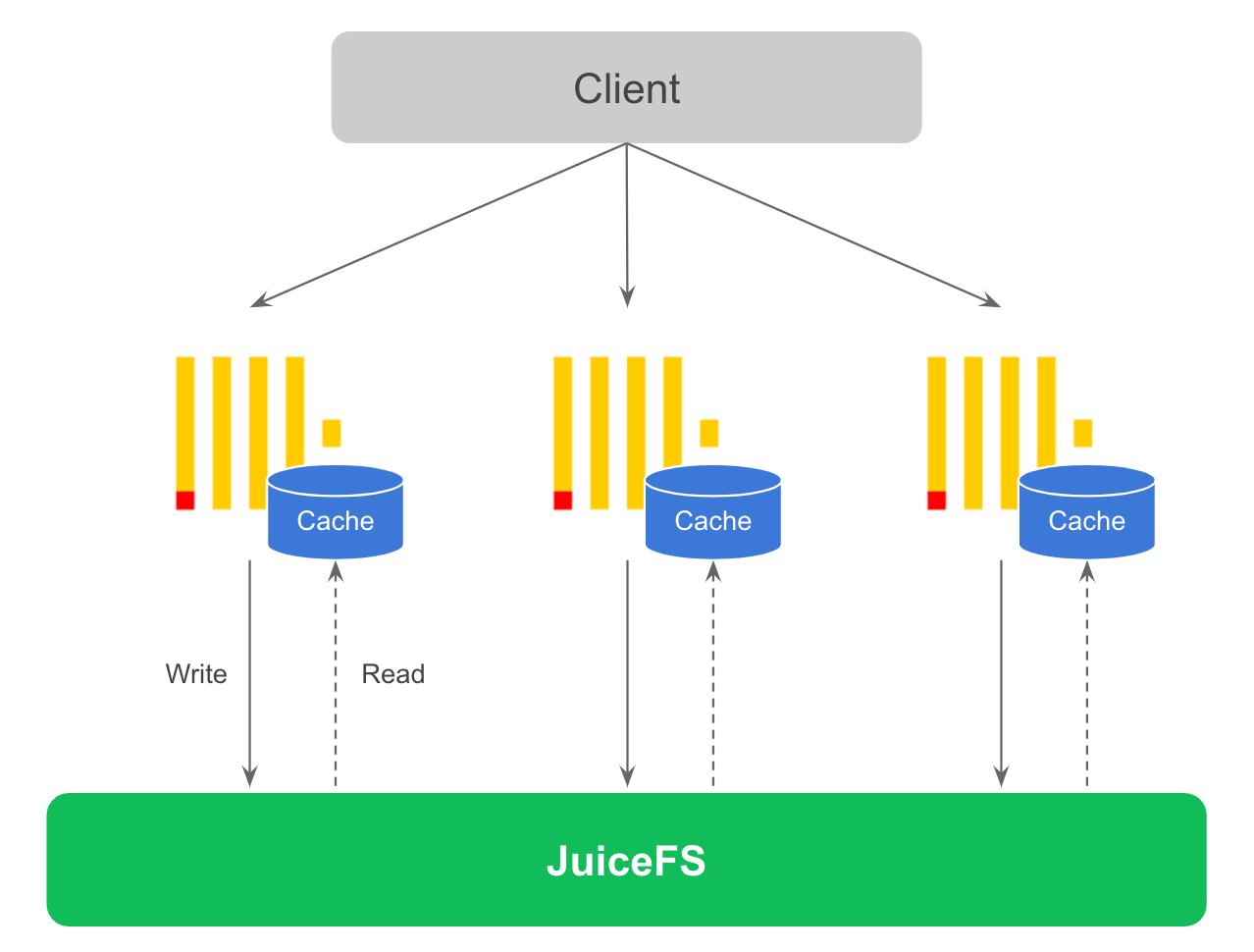
ClickHouse generates a large number of small files when writing, so if the write pressure is high this solution will have an impact on both write and query performance. It is recommended to increase the write cache when writing data and try to write as much data as possible at once to avoid this problem of too many small files. The easiest way to solve the problem of too many small files is to use ClickHouse's Buffer table, which basically does not require any changes to the application code. Suitable for scenarios where a small amount of data is allowed to be lost when ClickHouse is down. This has the advantage that storage and computation are completely separated, ClickHouse nodes are completely stateless and can be recovered quickly if a node fails, without involving any data copies. In the future it will be possible for ClickHouse to sense that the underlying storage is shared, enabling automatic migration without data copy.
At the same time, as ClickHouse is usually used in real-time analytics scenarios, this scenario has high requirements for real-time data updates, and also requires frequent queries for new data during analysis. Therefore, the data has a relatively obvious hot and cold characteristics, that is, generally new data is hot data, and over time historical data gradually becomes cold data. The overall solution is shown in the figure below.
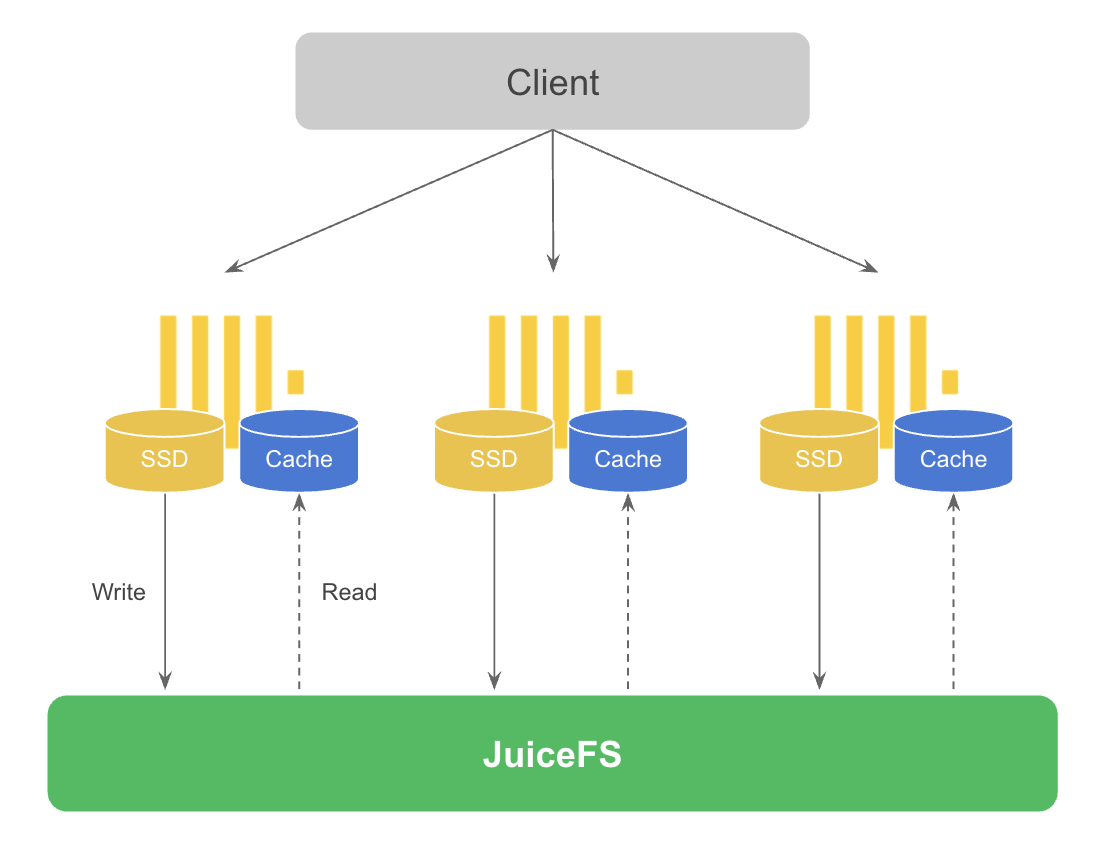
In this solution the data is first written to local disk, and when certain conditions are met ClickHouse's background threads will asynchronously migrate the data from local disk to JuiceFS. As in the first solution, the hot data is automatically cached at query time. Note that in the diagram two disks are drawn in order to distinguish between writes and reads, in practice there is no such restriction and the same disk can be used. Although this solution is not a complete separation of storage and computation, it can meet the needs of scenarios with particularly high write performance requirements and retain a certain amount of storage resource elasticity and scalability. The following will describe in detail how this solution is configured in ClickHouse.
ClickHouse supports configuring multiple disks for data storage, the following is an example configuration file.
<storage_configuration>
<disks>
<jfs>
<path>/jfs</path>
</jfs>
</disks>
</storage_configuration>The /jfs directory above is the path where the JuiceFS file system will be mounted. After adding the above configuration to the ClickHouse configuration file and successfully mounting the JuiceFS file system, you can move a partition to JuiceFS with the MOVE PARTITION command, for example:
ALTER TABLE test MOVE PARTITION 'xxx' TO DISK 'jfs';Of course this manual move is for testing purposes only, ClickHouse supports automatic movement of data from one disk to another by means of configured storage policies. Here is the sample configuration file.
<storage_configuration>
<disks>
<jfs>
<path>/jfs</path>
</jfs>
</disks>
<policies>
<hot_and_cold>
<volumes>
<hot>
<disk>default</disk>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</hot>
<cold>
<disk>jfs</disk>
</cold>
</volumes>
<move_factor>0.1</move_factor>
</hot_and_cold>
</policies>
</storage_configuration>The above configuration file has a storage policy named hot_and_cold, which defines two volumes, the volume named hot is the default SSD disk and the volume named cold is the JuiceFS disk defined in the previous step disks. The order of these volumes in the configuration file is important, the data will be stored in the first volume first, and the max_data_part_size_bytes configuration means that when the data part exceeds the specified size (1GiB in the example) it will automatically be moved from the current volume to the next The final move_factor configuration also triggers a data move to JuiceFS when the SSD disk exceeds 90% of the disk capacity.
Finally, when creating the table, you need to explicitly specify the storage policy to be used.
CREATE TABLE test (
...
) ENGINE = MergeTree
...
SETTINGS storage_policy = 'hot_and_cold';When the conditions for moving data are met, ClickHouse will start a background thread to perform the operation of moving the data, by default there will be 8 threads working at the same time, this number of threads can be obtained by background_move_pool_size.
In addition to configuring the storage policy, it is possible to move data older than a certain period of time to JuiceFS at table creation time via TTL, for example:
CREATE TABLE test (
d DateTime,
...
) ENGINE = MergeTree
...
TTL d + INTERVAL 1 DAY TO DISK 'jfs'
SETTINGS storage_policy = 'hot_and_cold';The above example is moving data older than 1 day to JuiceFS, which together with the storage policy allows for very flexible management of the data lifecycle.
Write Performance Testing
With the hot/cold data separation solution, data is not written directly to JuiceFS, but to SSD disks first, and then migrated to JuiceFS asynchronously via background threads. However, we want to directly evaluate how much performance difference there is in the scenario of writing data to different storage media, so here in the test of write performance is not configured for hot and cold data separation storage strategy, but to allow ClickHouse to write directly to different storage media.
The specific test method is to use a ClickHouse table from a real business as a data source, and then use the INSERT INTO statement to insert a batch of tens of millions of rows of data, comparing the throughput of direct writes to SSD disks, JuiceFS and object storage. The final test results are shown in the following figure.
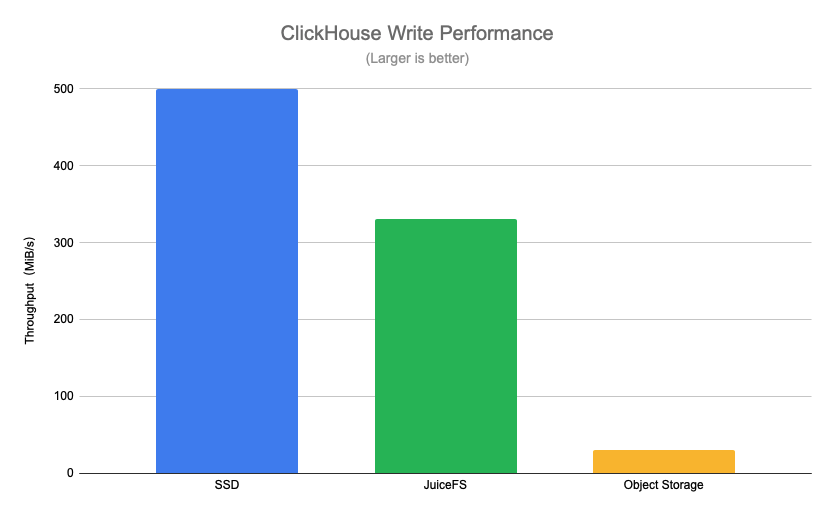
Using SSD disks as a benchmark, you can see that JuiceFS has about a 30% performance difference in write performance compared to SSD disks, but has an 11x performance improvement compared to object storage. The writeback option is turned on in the JuiceFS test here, this is because ClickHouse generates a large number of small files (KiB level) per part when writing, and the client can significantly improve performance by using asynchronous writing, while a large number of small files can have an impact on query performance.
After understanding the performance of writing directly to different media, we next test the write performance of the hot and cold data separation solution. After actual business tests, the JuiceFS-based hot and cold data separation solution performs stably, as new data is written directly to SSD disks, so the write performance is comparable to that of SSD disks in the above tests. The data on the SSD disk can be migrated to JuiceFS quickly, and the merging of data parts on JuiceFS is no problem.
Query Performance Test
The query performance test uses data from real business and selects several typical query scenarios for testing. Among them, q1-q4 are queries that scan the whole table, and q5-q7 are queries that hit the primary key index. The test results are as follows.
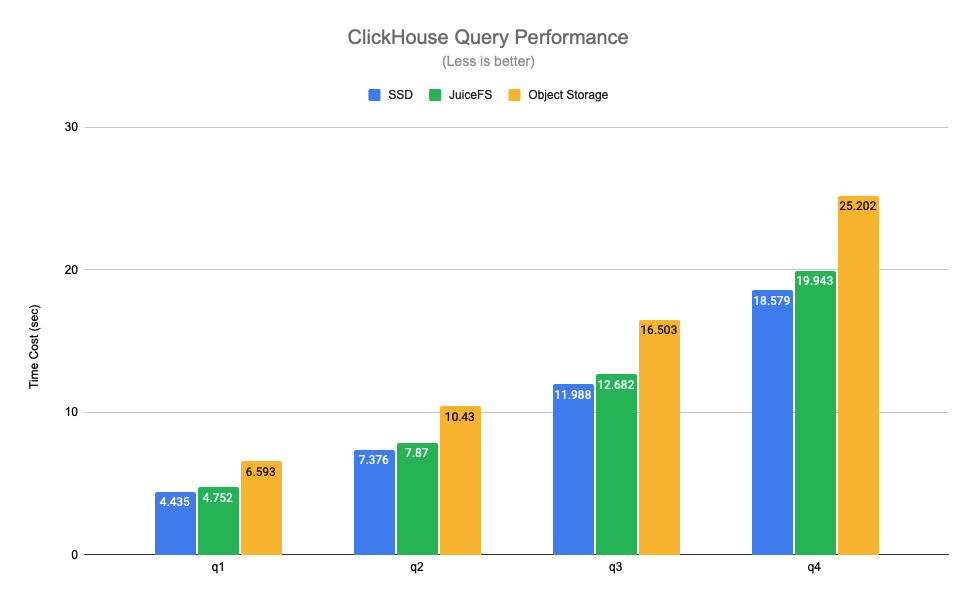

You can see that the query performance between JuiceFS and SSD disks is basically comparable, with an average difference of about 6%, but object storage has a performance drop of 1.4 to 30 times compared to SSD disks. Because of JuiceFS' high performance metadata operations and local caching feature, the hot data needed for query requests is automatically cached locally on ClickHouse nodes, which significantly improves ClickHouse's query performance. Note that the object storage in the above tests was done via ClickHouse's S3 disk type for access, this way only the data is stored on the object store, the metadata is still on the local disk. If the object store is mounted locally in a similar way to S3FS, there is a further performance degradation.
After the basic query performance test, the next test is the query performance under the hot and cold data separation solution. In contrast to the previous tests, when using the hot/cold data separation solution, not all data is in JuiceFS, and data is written to SSD disks first.
First, a fixed query time range is chosen to evaluate the impact of JuiceFS caching on performance, and the results are shown in the following figure.
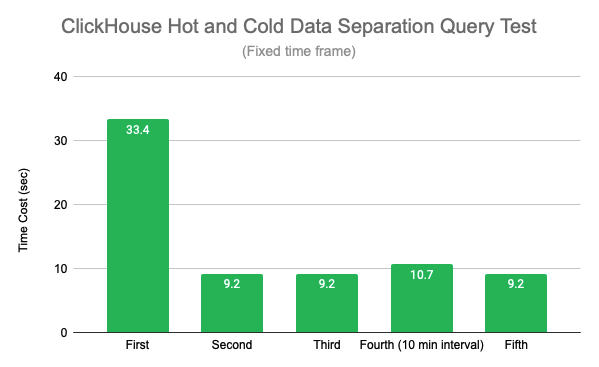
The first query is slower than the last few because there is no cache, from the second query onwards JuiceFS query performance is more stable, with about 70% performance improvement compared to the first query. The fourth query was done 10 minutes after the last one, and the performance fluctuated slightly (probably due to the system page cache), but it was within the expected range, and the fifth query resumed the previous query time.
Then, using queries with variable time ranges, while there is still data being written in real time, meaning that each query involves new data, the test results are as follows.
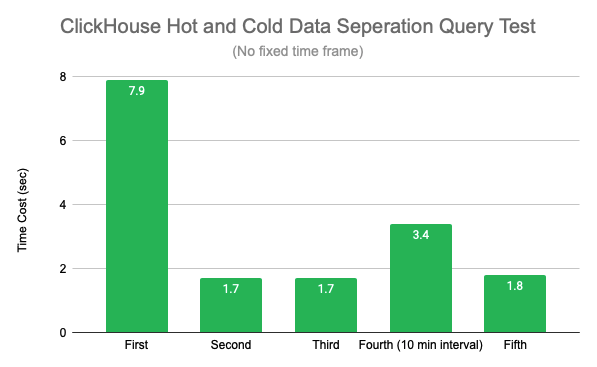
As with the fixed time range query, the second query brings about a 78% performance improvement due to the cache build from the second query. The difference is that the fourth query involves querying new writes or merged data, and JuiceFS currently does not cache large files on writes, which can have an impact on query performance, and will later provide parameters to allow caching of writes to improve query performance on new data.
Summary
With ClickHouse's storage strategy it is easy to combine SSD and JuiceFS to achieve both performance and cost solutions. The results of write and query performance tests show that JuiceFS is perfectly suited to ClickHouse scenarios, so users no longer have to worry about capacity and can easily cope with future data growth several times over at a small increase in cost. JuiceFS is currently supported of more than 20 public clouds, combined with full compatibility with POSIX features, without changing ClickHouse makes it easy to access object storage on the cloud without changing a single line of code.
Outlook
In the current environment of increasing emphasis on cloud-native, storage compute separation has become a major trend. ClickHouse's 2021 roadmap has explicitly identified storage separation as a key goal, and while ClickHouse currently supports storing data on S3, the implementation is still relatively rough. In the future, JuiceFS will also work closely with the ClickHouse community to explore the direction of store-compute separation, so that ClickHouse can better identify and support shared storage and achieve cluster scaling without making any data copies.
If you're interested in JuiceFS, visit GitHub and start trying it out: https://github.com/juicedata/juicefs
Reference



