Cache
To improve the performance, JuiceFS supports caching in multiple levels to reduce the latency and increase throughput, including metadata cache, data cache and cache sharing among multiple clients (also known as cache group).
Data caching will effectively improve the performance of random reads. For applications that require high random read performance (e.g. Elasticsearch, ClickHouse), it is recommended to use faster storage medium and allocate more space for cache.
Meanwhile, cache improve performance only when application needs to repeatedly read files, so if you know for sure you're in a scenario where data is only accessed once (e.g. data cleansing during ETL), you can safely turn off cache to prevent overhead.
Consistency
Distributed systems often need to make tradeoffs between cache and consistency. Due to the decoupled architecture of JuiceFS, think consistency problems in terms of metadata, file data (in object storage), and file data local cache.
For metadata, the default configuration offers a "close-to-open" consistency guarantee, i.e. after a client have modified and closed a file, other clients will see the latest state when they open this file again. Also, default mount option uses 1s of kernel metadata cache which provides decent performance for the usual cases. If your scenario demands higher level of cache performance, learn how to tune cache settings in below sections. In particular, the client (mount point) initiating file modifications will enjoy a stronger consistency, read consistency exceptions for more.
As for object storage, JuiceFS clients split files into data blocks (default 4MiB), each is assigned an unique ID and uploaded to object storage. Subsequent modifications on the file are carried out on new data blocks, and the original blocks remain unchanged. This guarantees consistency of the object storage data, because once the file is modified, clients will then read from the new data blocks, while the stale ones which will be deleted through Trash or compaction.
Local file data cache is object storage blocks downloaded into local disks. So consistency depends on the reliability of the disks, if data are tempered, clients will read bad data. To resolve this concern, choose an appropriate --verify-cache-checksum strategy to ensure data integrity.
Metadata Cache
As a userspace filesystem, JuiceFS metadata cache is both managed as kernel cache (via FUSE API), and maintained in client memory space, creating a multi-level cache architecture similar to the data cache.
Metadata Cache in Kernel
Kernel metadata cache cannot be actively invalidated and can only wait for natural expiration (except for the host initiating file changes). If you haven't carefully test through, do not increase kernel metadata cache timeouts, which can cause serious consistency issues.
JuiceFS Client controls these kinds of metadata as kernel cache: attribute (file name, size, permission, mtime, etc.), entry (inode, name, and type. The word entry and direntry is used in parameter names, to further distinguish between file and directory.). Use the following parameters to control TTL through FUSE:
# File attribute cache TTL in seconds, default to 1, improves getattr performance
--attrcacheto=1
# File entry cache TTL in seconds, default to 1, improves lookup performance
--entrycacheto=1
# Directory entry cache TTL in seconds, default to 1, improves lookup performance
--direntrycacheto=1
Caching these metadata in kernel for 1 second really speeds up lookup and getattr calls.
Do note that entry cache is gradually built upon file access and may not contain a complete file list under directory, so readdir calls or ls command cannot utilize this cache, that's why entry cache only improves lookup performance. The meaning of direntry here is different from kernel directory entry, direntry does not tell you the files under a directory, but rather, it's the same concept as entry, just distinguished based on whether it's a directory.
All kernel cache items mentioned above also exist in client memory cache, forming a kernel → client memory multi-level cache architecture. Memory cache is kept for 5 minutes by default, and supports active invalidation (introduced in the next section), so there's usually no need to further increase kernel metadata cache timeouts, except:
- Files rarely change, or are completely read-only.
- Applications really need to perform intensive
lookupcalls on a large file system (like large Git repositories), and would like to avoid cache penetration to user space as altogether.
Real world scenarios scarcely require setting different values for --entrycacheto and --direntrycacheto, these options exist for theoretical possibilities like when directories seldomly change while files change a lot, in that situation, you can use a higher --direntrycacheto than --entrycacheto.
Metadata Cache in Client Memory
To reduce metadata queries (like ls) as much as possible, JuiceFS by default stores structured file metadata in client memory. Different from kernel cache, client memory cache is actively invalidated upon file modifications (client subscribes to metadata and listen for change events, and cleans up memory cache asynchronously), so a longer TTL of 5 minutes is used as default. You can adjust using below parameters:
# Cache metadata in client memory, enabled by default
--metacache
# Memory metadata cache timeout in seconds, default to 5 minutes
--metacacheto=300
# Cache 500000 inodes at most
--max-cached-inodes=500000
The --metacache option (enabled by default) caches all visited files for 5 minutes, which is quite a long time for this crucial information. However, there's no real consistency worries because:
- Client memory metadata only serves to accelerate file & directory traversal,
lookup、getattr、access、opencan all benefits from this cache, note theopenhere refers to opening directories, not opening files, to ensure strong consistency. To also cacheopencalls, see the--opencacheoption introduced below. - Clients will also cache symbolic links. but since symbolic links are immutable (when new symlink is created, the existing one is overwritten), so the cached content will never expire.
- Memory metadata is actively invalidated, as illustrated in below diagram. When a file is modified, metadata service notifies all clients via a subscription mechanism, and clients then invalidate the corresponding metadata cache in their memory space. Such that with a TTL as long as 5 minutes, all cache entries are still kept up-to-date.

To maintain the default close-to-open consistency, open calls (against file rather than directory) will always query metadata service, bypassing local cache, modifications done by client A isn't guaranteed available immediately for client B, but once A is done and closes file, all other clients (across different nodes) will see the latest state. File attribute cache isn't necessarily obtained through open, for example tail -f will periodically query attributes, in this case, latest state is fetched without reopening the file.
For read-only or read intensive scenarios (e.g. model training), use --opencache to enable cache for open (timeout is also controlled via --metacacheto), so that opening a file also utilizes file attribute cache in client memory, this client memory attribute cache includes not only the kernel cached file attributes like size, mtime, but also information specific to JuiceFS like the relationship between file and its chunks and slices. These cached information avoids the overhead of querying metadata service on every open.
Even with --opencache enabled, since memory cache is actively invalidated, the system is still operating under a "pretty good consistency", similar to kernel metadata cache, the client initiating the modifications still enjoys strong consistency, for other clients, because the invalidation is accomplished asynchronously via the file change event subscription mechanism, this process will still cause a tiny delay. Hence, if modified files are immediately accessed by other clients, do not enable --opencache.
Consistency exceptions
The metadata cache in kernel & client memory discussed above really only pertain to multi-client situations, which can be deemed as a "minimum consistency guarantee". But for the client initiating file changes, it's not hard to imagine that due to changes happening "locally", the client initiating changes will enjoy a higher level of consistency:
- For the client initiating changes, kernel cache is automatically invalidated upon modification. But when different mount points access and modify the same file, active kernel cache invalidation is only effective on the client initiating the modifications, other clients can only wait for expiration.
- When a
writecall completes, the mount point itself will immediately see the resulting file length change (e.g. usels -alto verify that file size is growing)——but this doesn't mean the changes have been committed, beforeflushfinishes, these modifications will not be reflected onto the object storage, and other mount points cannot see the latest writes. - As an extreme case of the previous situation, if you
writesuccessfully and have observed file size change in the current mount point, but the eventualflushfails for some reason, for example file system usage exceeds global quota, then the previously growing file size will suddenly be reduced, for example, dropped from 10M to 0, this often leads to misunderstanding that JuiceFS just emptied your files, while the reality is that the files haven't been successfully written from the beginning, the file size change that's only available to the current mount point is simply a preview of things, not an actual committed state. - The client initiating changes will invalidate its client memory metadata cache immediately, while others subscribe to the metadata service and listen for file change events, their cache invalidation will inevitably comes with a tiny delay.
- The mount point initiating changes have access to file change events, and can use tools like
fswatchorWatchdog. But the scope is obviously limited to the files changed within the mount point itself, i.e. files modified by A cannot be monitored by mount point B. - Due to the fact that FUSE doesn't yet support inotify API, if you'd like to monitor file change events using libraries like Watchdog, you can only achieve this via polling (e.g.
PollingObserver).
Read/Write Buffer
The Read/Write buffer is a memory space allocated to the JuiceFS Client, size controlled by --buffer-size which defaults to 300 (in MiB). Read/Write data all pass through this buffer, making it crucial for all I/O operations, that's why under large scale scenarios, increase buffer size is often used as a first step of optimization.
Readahead and Prefetch
To accurately describe the internal mechanism of JuiceFS Client, we use the term "readahead" and "prefetch" to refer to the two different behaviors that both download data ahead of time to increase read performance.
When a file is sequentially read, JuiceFS Client performs what's called "readahead", which involves downloading data ahead of the current read offset. In fact, the similar behavior is already being built into the Linux Kernel: when reading files, kernel dynamically settles on a readahead window based on the actual read behavior, and load file into the page cache. With JuiceFS being a network file system, the classic kernel readahead mechanism is simply not enough to bring the desired performance increase, that's why JuiceFS performs its own readahead on top of kernel readahead, using algorithm to "guess" the size of the readahead window (more aggressive than kernel's), and then download the object storage data in advance.

The readahead window is controlled by the client's buffer size and download concurrency, i.e. pick the minimum from buffer-size / 5, block-size * max-downloads, block-size * 128MiB (where block-size is the block size, the default is 4MiB). This algorithm ensures even if an excessively large buffer (or high concurrency) is used, the resource taken by large file sequential read is always controlled. If you need to further improve large file sequential read, use the --max-readahead option (unit is MiB).
Buffer size impact performance through many aspects, apart from the readahead window introduced above, it also controls the object storage request concurrency. That is to say, using a large --max-downloads or --max-uploads does not necessarily elevate performance, because buffer might need to be increased accordingly. Continue reading below sections for observation and tuning.
Apparently readahead is only good for sequential reads, that's why there's another similar mechanism called "prefetch": when a block is randomly read by a small offset range, the whole block is scheduled for download asynchronously.

This mechanism assumes that if a file is randomly read at a given range, then its adjacent content is also more likely to get read momentarily. This isn't necessarily true for various different types of applications, for example, if an application decides to read read a huge file in a very sparse fashion, i.e. read offsets are far from each other. In such case, prefetch isn't really useful and can cause serious read amplification, so if you are already familiar with the file system access pattern of your application, and concluded that prefetch isn't really needed, you can disable by using --prefetch=0.
Readahead and prefetch effectively increase sequential read and random read performance, but it also comes with read amplification, read "Read amplification" for more information.
Write
A successful write does not mean data is persisted: that's actually fsync's job (or fdatasync, close). This is true for both local file systems, and JuiceFS file systems. In JuiceFS, write only commits changes to the buffer, from the writing mount point's POV, you may notice that file size is changing, but do not mistake this for persistence (this behavior is also covered in detail in consistency). To sum up, before flush actually finishes, changes are only kept inside the client buffer. Applications may explicitly invoke fsync, but even without this, flush is automatically triggered when a pending slice exceeds block size, or have waited in the buffer for 5 seconds (can be adjusted using --flush-wait).
Together with the previously introduced readahead mechanism, buffer function can be described in below diagram:

Buffer is shared by both read & write, obviously write is treated with higher priority, this implies the possibility of write getting in the way of read. For instance, if object storage bandwidth isn't enough to support write load, there'll be congestion:

As illustrated above, a high write load puts too much pending slices inside the buffer, leaving little buffer space for readahead, file read will hence slow down. Due to a low upload speed, write may also fail due to flush timeouts.
Observation and Optimization
Buffer is crucial to both read & write, as is already introduced in above sections, making --buffer-size the first optimization target when faced with large scale scenarios. But simply increasing buffer size is not enough and might cause other problems (like buffer congestion, illustrated in the above section). The size of the buffer should be smartly decided along with other performance options.
Before making any adjustments, we recommend running a juicefs stats command to check the current buffer usage, and read below content to guide your tuning.
If you wish to improve write speed, and have already increased --max-uploads for more upload concurrency, with no noticeable increase in upload traffic, consider also increasing --buffer-size so that concurrent threads may easier allocate memory for data uploads. This also works in the opposite direction: if tuning up --buffer-size didn't bring out an increase in upload traffic, you should probably increase --max-uploads as well.
The --buffer-size also controls the data upload size for each flush operation, this means for clients working in a low bandwidth environment, you may need to use a lower --buffer-size to avoid flush timeouts. Refer to "Connection problems with object storage" for troubleshooting under low internet speed.
If you wish to improve sequential read speed, use a larger --buffer-size to expand the readahead window, all data blocks within the window will be concurrently fetched from object storage (concurrency controlled by --max-downloads). Also keep in mind that, reading a single large file will never consume the full buffer, the space reserved for readahead is between 1/4 to 1/2 of the total buffer size. So if you noticed that juicefs stats indicates buf is already half full, while performing sequential read on a single large file, then it's time to increase --buffer-size to set a larger readahead window.
Data Cache
To improve performance, JuiceFS also provides various caching mechanisms for data, including page cache in the kernel, local file system cache in client host, and read/write buffer in client process itself. Read requests will try the kernel page cache, the client process buffer, and the local disk cache in turn. If the data requested is not found in any level of the cache, it will be read from the object storage, and also be written into every level of the cache asynchronously to improve the performance of the next access.
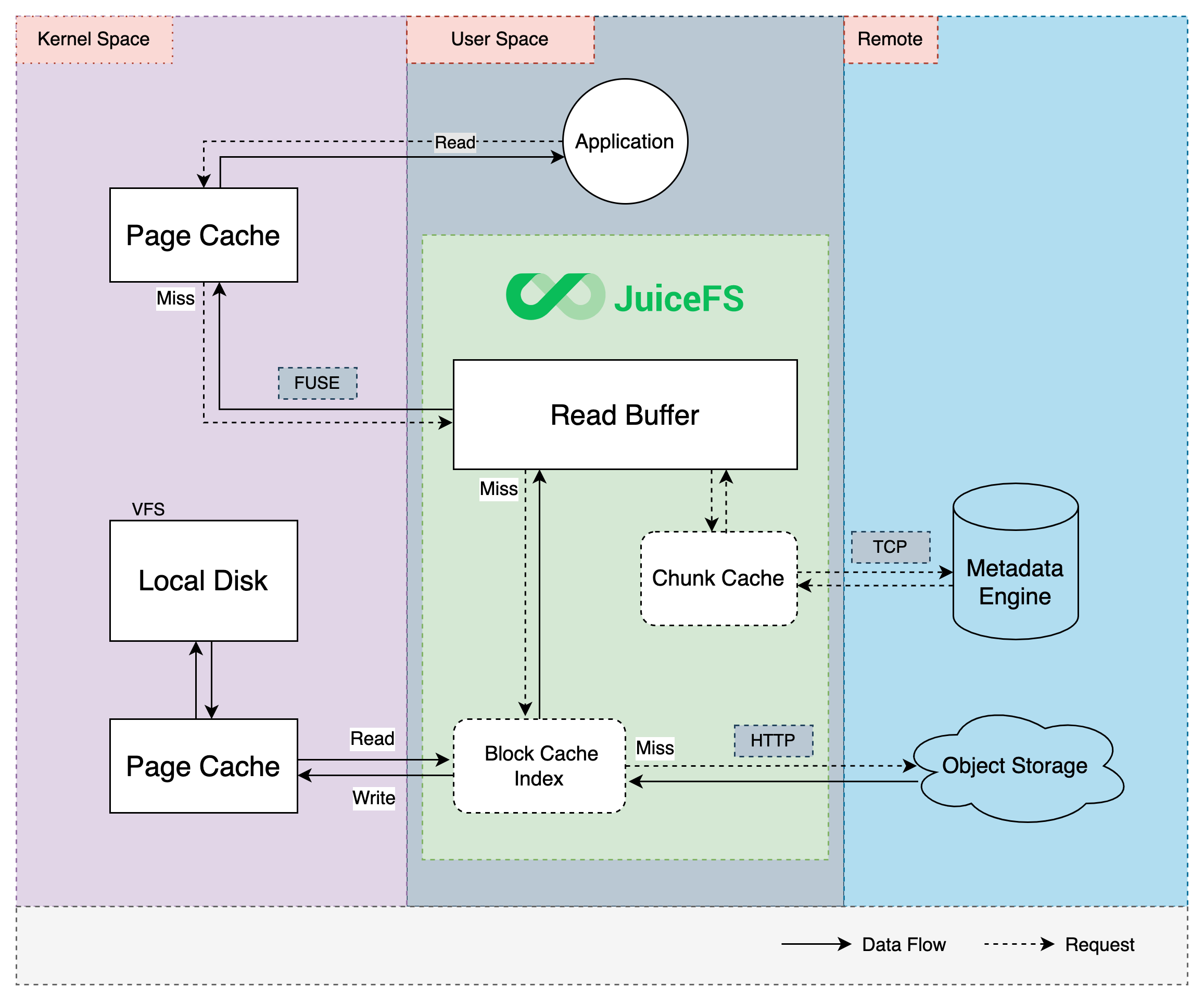
Kernel Page Cache
Kernel will build page cache for recently visited files. When files are reopened, data will be fetched directly from page cache to achieve the best performance.
JuiceFS Metadata Service tracks a list of recently opened files. If one file is opened repeatedly by the same client, metadata service will inform the client whether the kernel page cache is valid by checking the modification history, if file is already modified, all relevant page cache is invalidated on the next open, this ensures that the client can always read the latest data.
Reading the same file in JuiceFS repeatedly will be extremely fast, with milliseconds latency and gigabytes throughput.
Writeback Cache in Kernel
Starting from Linux kernel 3.15, FUSE supports writeback-cache mode, the kernel will consolidate high-frequency random small (10-100 bytes) write requests to significantly improve its performance, but this comes with a side effect: sequential writes are also turned into random writes, hence sequential write performance is hindered, so only use it on intensive random write scenarios.
Enable writeback-cache mode by using the -o writeback_cache option when running juicefs mount. Note that the FUSE writeback-cache mode is different from Write Cache in Client, the former is a kernel implementation aiming to improve performance for small random writes or small appends, while the latter happens within the JuiceFS Client, which is mainly used when in need of creating a large amount of small files in a short period of time.
Read Cache in Client
The client will perform prefetch and cache automatically to improve sequence read performance according to the read mode in the application. Data will be cached in local file system, which can be any local storage device like HDD, SSD or even memory.
Data downloaded from object storage, as well as small data (smaller than a single block) uploaded to object storage will be cached by JuiceFS Client, without compression or encryption. To achieve better performance on application's first read, use juicefs warmup to cache data in advance.
If the file system where the cache directory is located is not working properly, the JuiceFS client can immediately return an error and downgrade to direct access to object storage. This is usually true for local disk, but if the file system where the cache directory is located is abnormal and the read operation is stuck (such as some kernel-mode network file system), then JuiceFS will also get stuck together. This requires you to tune the underlying file system behavior of the cache directory to fail fast.
JuiceFS Client automatically detects malfunctioning disks, if there's been frequent disk read errors during a short period of time, client process will remove the bad disks and cease to use them. Disks with poor performance are not recommended as cache storage for JuiceFS.
Below are some important parameters for cache config (see juicefs mount for complete reference):
-
--cache-dirCache directory, default to
/var/jfsCache, specify multiple paths separated by:or wildcard character*, to increase both cache capacity and total cache IO. Also,/dev/shmis supported if you'd like to use memory for cache. Another way to use memory for cache is to pass the stringmemoryto this parameter, this puts cache directly in client process memory, which is simpler compared to/dev/shm, but obviously cache will be lost after process restart, use this for tests and evaluations.It is recommended to use an independent disk for the cache directory as much as possible, do not use the system disk, and do not share it with other applications. Sharing not only affects the performance of each other, but may also cause errors in other applications (such as insufficient disk space left). If it is unavoidable to share, you must estimate the disk capacity required by other applications, limit the size of the cache space (see below for details), and avoid JuiceFS's read cache or write cache takes up too much space.
When multiple cache directories are set, the
--cache-sizeoption represents the total size of data in all cache directories. JuiceFS balance cache writes with a simple hash algorithm, and cannot tailor write strategies for different cache directories, thus it is recommended that the free space of different cache directories are close to each other, otherwise, the space of a cache directory may not be fully utilized. This is also true when multiple disks are used as cache devices. Follow our guide if you need to remove or replace a cache disk.For example,
--cache-diris/data1:/data2, where/data1has a free space of 1GiB,/data2has a free space of 2GiB,--cache-sizeis 3GiB,--free-space-ratiois 0.1. Because the cache write strategy is to write evenly, the maximum space allocated to each cache directory is3GiB / 2 = 1.5GiB, resulting in a maximum of 1.5GiB cache space in the/data2directory instead of2GiB * 0.9 = 1.8GiB.If you are in urgent need to free up disk space, manually delete the cache directory, which defaults to
/var/jfsCache/<vol-name>/raw/. You should only delete only therawdirectory, for removing the entire/var/jfsCache/<vol-name>will trigger a full cache rebuild (downloading all cache blocks into local disks again), a feature that's specifically designed so that cache disks can be easily replaced. -
--cache-sizeand--free-space-ratioCache size (in MiB, default to 102400) and minimum ratio of free size (default 0.1). Both parameters is able to control cache size, if any of the two criteria is met, client will evict cache using the simple 2-random strategy, i.e. randomly pick 2 blocks, and drop the one with an earlier access time. Under most real world scenarios, the overall outcome is similar to LRU algorithm, while random-2 comes with lower overhead.
If you do not want to automatically evict the cache, you can disable cache eviction through the
--cache-eviction=noneoption (requires client version 5.0.1 and above). In this case, you need to manually manage the data in the cache directory.When files are deleted, cached blocks are cleaned from cache directory for the current mount point only, other nodes will not actively delete the corresponding cache, and can only wait for passive eviction when cache storage reach its capacity limit. Thus, after a file is deleted, its cache blocks may still persist on other nodes' cache directories, but due to metadata consistency, these lingering blocks will not be read.
Actual cache size may exceed configured value, because it is difficult to calculate the exact disk space taken by cache. Currently, JuiceFS takes the sum of all cached objects sizes using a minimum 4 KiB size, which is often different from the result of
du. -
--cache-partial-onlyFor the read cache, only data blocks smaller than one block size (default 4MiB) are cached, such as small files smaller than one block size, and data blocks smaller than one block size at the end of large files. The default value is
false(that is, all read data blocks are cached).There are two main read patterns, sequential read and random read. Sequential read usually demands higher throughput while random reads needs lower latency. When local disk throughput is lower than object storage, consider enable
--cache-partial-onlyso that sequential reads do not cache the whole block, but rather, only small reads (like Parquet / ORC footer) are cached. This allows JuiceFS to take advantage of low latency provided by local disk, and high throughput provided by object storage, at the same time.Another feature which impacts random read performance is compression (same also applies for encryption). When compression is enabled, the block will always be fetched and cached from object storage, no matter how small the read actually is. This hinders first time read performance, so it's recommended that you disable compression for JuiceFS when the system does intensive random reads. Without compression, JuiceFS can do partial reads on a block, this improves read delay and reduces bandwidth consumption.
Therefore, this option is suitable for the following scenarios:
- The throughput of object storage is higher than that of the cache disk, resulting in slower reading of large files cached locally.
- The large files are only read once sequentially and will not be read repeatedly. In this scenario, the disk cache has little value and can be discarded.
tipRegardless of whether this option is enabled, the JuiceFS client only caches complete object storage blocks. If you randomly read a small segment of data less than one block in a large file, this part of the data will not be written to the cache directory (nevertheless, it'll be kept in client buffer & kernel page cache, making subsequent reads very fast). If
--prefetchis larger than 0, then these type of random small read triggers asynchonous downloads of the corresponding data blocks, via the prefetch mechanism.The
--cache-partial-onlyoption will also affect the cache construction of distributed cache. When the client enabled the--fill-group-cacheoption, the client will send all written data to the cache cluster. If the--cache-partial-onlyoption is also enabled at this time, the client will only send data smaller than one block size (default 4MiB) to the cache cluster.
Write Cache in Client
Enabling client write cache can improve performance when writing large amount of small files. Read this section to learn about client write cache.
Client write cache is disabled by default, data writes will be held in the read/write buffer (in memory), and is uploaded to object storage when a chunk is filled full, or forced by application with close()/fsync() calls. To ensure data security, client will not commit file writes to the Metadata Service until data is uploaded to object storage.
You can see how the default "upload first, then commit" write process will not perform well when writing large amount of small files. Use --writeback to enable client write cache, and the write process becomes "commit first, then upload asynchronously", file writes will not be blocked by data uploads, instead it will be written to the local cache directory and committed to the metadata service, and then returned immediately. The file data in the cache directory will be asynchronously uploaded to the object storage in the background.

With client write cache, data cannot be read by other clients until the async upload completes (when clients read unfinished data, the request will hang until timeout). Data might be kept on disk for a significant period of time, disk reliability is crucial to data integrity, if write cache data suffers loss before upload completes, file data is lost forever. Use with caution when data reliability is critical.
Learn its risks and caveats before use:
- Write cache data by default is stored in
/var/jfsCache/<vol-name>/rawstaging/, if this directory suffers deletion or tempering, data will be lost. - Write cache size is controlled by
--free-space-ratio. By default, if the write cache is not enabled, the JuiceFS client uses up to 80% of the disk space of the cache directory (the calculation rule is(1 - <free-space-ratio>) * 100). After the write cache is enabled, a certain percentage of disk space will be overused. The calculation rule is(1 - (<free-space-ratio> / 2)) * 100, that is, by default, up to 90% of the disk space of the cache directory will be used. - Write cache and read cache share cache disk space, so they affect each other. For example, if the write cache takes up too much disk space, the size of the read cache will be limited, and vice versa.
- If local disk write speed is lower than object storage upload speed, enabling
--writebackwill only result in worse write performance. - If the file system of the cache directory raises error, client will fallback and write synchronously to object storage, which is the same behavior as Read Cache in Client.
- If object storage upload speed is too slow (low bandwidth), local write cache can take forever to upload, meanwhile reads from other nodes will result in timeout error (I/O error). See Connection problems with object storage.
- Added in v4.9.22 If
--fill-group-cacheis enabled, then the staging data will also be asynchronously sent to the distributed cache group, in other words, even if it has not been uploaded to the object storage, there is a certain probability that the cache group members can read the data that has not yet been persisted.
Improper usage of client write cache can easily cause problems, that's why only recommend to temporarily enable this when writing large number of small files (e.g. extracting a compressed file containing a large number of small files). Adjusting mount options are also very easy: JuiceFS Client supports seamless remount, just add the needed parameters, and run the mount command again, see Seamless remount.
Distributed cache
Caching on a single node can easily hit a performance or capacity limit, to overcome this limit, JuiceFS supports distributed cache (also referred to as client cache sharing), which distributes large amount of cache data across multiple JuiceFS clients, effectively improving performance. Read "Distributed cache" for more.
Observation and monitor
Our Grafana Dashboard already contains many key cache-related monitoring charts. For single node cache, you can refer to the following related metrics in Grafana Dashboard:
- Block Cache Hit Ratio
- Block Cache Count
- Block Cache Size
- Other Block Cache related metrics in Grafana Dashboard
The single node cache metrics isn't solely used for single node cache, observation in distributed cache scenarios is also achieved through "Block Cache" related metrics of each member node. See "Distributed cache" for more.

