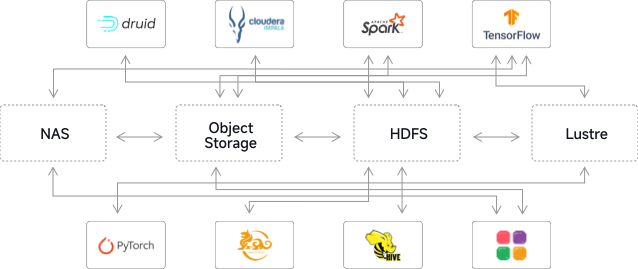
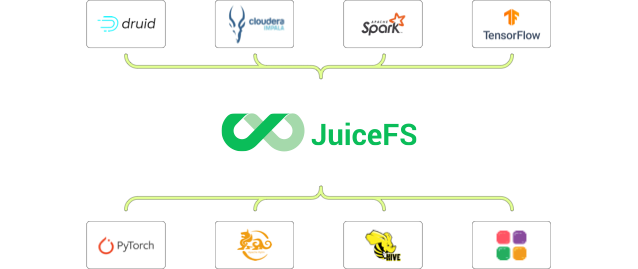
Why Choose JuiceFS Cloud Service?
99.95% service availability SLA, 99.99999999% (10 nines) data reliability SLA
Effortlessly manage tens of billions of files
Our in-house distributed metadata storage engine ensures smooth scalability without bottlenecks.
High performance, tailored for large-scale AI model training scenarios
Benefit from multi-level caching acceleration, elastic throughput scalability, and the resolution of data hotspot issues.
Streamline cross-cloud data access
Our mirror file system offers efficient cross-regional, cross-cloud data storage, sharing, and synchronization capabilities.