















This article is from the monthly share of Juicedata founder & CEO Davies in the Shanghai Linux User Group (SHLUG) (2018/6/23).
What is a file system?
A file system is an essential component of a computer that provides consistent access and management for storage devices. There are some differences in the file system between different operating systems, but there are some commonalities that have not changed for decades:
- The data exists in the form of files and provides APIs such as Open, Read, Write, Seek, and Close for access;
- Files are organized in a tree-style directory that provides atomic rename (Rename) operations to relocate files or directories.
The access and management methods provided by the file system support most of the computer applications. The philosophy of Unix's “everything is a file” highlights the prominent position of files. However, the complexity of the file system makes its scalability fail to follow with the rapid development of the internet, and the greatly simplified object storage fills the gap in time to develop rapidly. Since the object storage lacks a tree structure and does not support atomic rename operations, it is quite different from the file system. It's a different topic, and we are not planning to discuss it here.
Challenges of the stand-alone file system
Most file systems are stand-alone, providing access and management for one or more storage devices within an operating system. With the rapid development of the internet, stand-alone file systems are facing many challenges:
- Sharing: It is not possible to provide access to applications distributed across multiple machines at the same time. Therefore the NFS protocol born. With the help of NFS, a single file system can be accessed to multiple machines simultaneously via the network.
- Capacity: The data has to be split across multiple isolated stand-alone file systems because of unable to provide enough space to store data.
- Performance: The application has to do a logical splitting and read and write from multiple file systems because of unable to fulfill very high read and write performance requirements of specific applications.
- Reliability: Limited by the reliability of a single machine, machine failure can result in data loss.
- Availability: Limited by the availability of a single operating system, failures or operations such as reboots can result in unavailability.
- With the rapid development of the internet, these problems have become increasingly prominent, and some distributed file systems have emerged to meet these challenges.
Here we introduce some fundamental architectures of distributed file systems I learned and compare the advantages and limitations of different architectures.
GlusterFS
GlusterFS is a POSIX distributed file system developed by Gluster Inc. of the United States (open source as GPL). The first public release was released in 2007 and was acquired by RedHat in 2011.
Its principle is to provide users with a unified namespace by combining multiple stand-alone file system through a stateless middleware. This middleware is implemented by a series of superimposable translators. Each translator solves a particular problem, such as data distribution, copying, splitting, caching, locks, etc., and users can flexibly configure according to specific application scenarios. For example, a typical distributed volume is shown below:
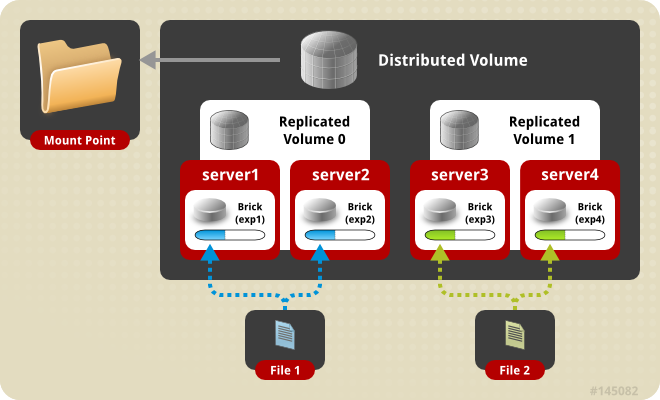
Image Source: https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/
Server1 and Server2 form a Volume0 with 2 copies, and Server3 and Server4 form Volume1, which are then merged into a distributed volumes with more space.
Pros:
- Data files are eventually stored on a stand-alone file system in the same directory structure, so you don't have to worry about data loss due to unavailability of GlusterFS.
- No obvious single point of failure problem and it can be extended linearly.
- Decent support for a large number of small files.
Cons:
- This structure is relatively static, not easy to modify, and requires each storage node to have the same configuration. When data or access is unbalanced, space or load adjustment is unable to perform. The fault recovery capability is relatively weak. For instance, when Server1 fails, the files on Server2 cannot be used to increase the reliability of copy data on the healthy Server3 or Server4.
- Because of the lack of independent metadata services, all storage nodes are required to have a complete data directory structure. When traversing directories or making directory structure adjustments, all nodes need to be accessed to get correct results, resulting in limited scalability of the entire system. It is acceptable to manage several nodes but challenging to manage hundreds of nodes efficiently.
CephFS
CephFS began with a doctoral thesis study by Sage Weil to implement distributed metadata management to support EB-level data scale. In 2012, Sage Weil established InkTank to continue supporting the development of CephFS, which was acquired by RedHat in 2014. Until 2016, CephFS released a stable version available for production environments (the metadata portion of CephFS is still stand-alone). However, the distributed metadata of CephFS is still immature.
Ceph is a layered architecture. The bottom layer is a CRUSH-based (hash) distributed object storage. The upper layer provides three APIs: object storage (RADOSGW), block storage (RDB), and file system (CephFS), as shown in the following figure:
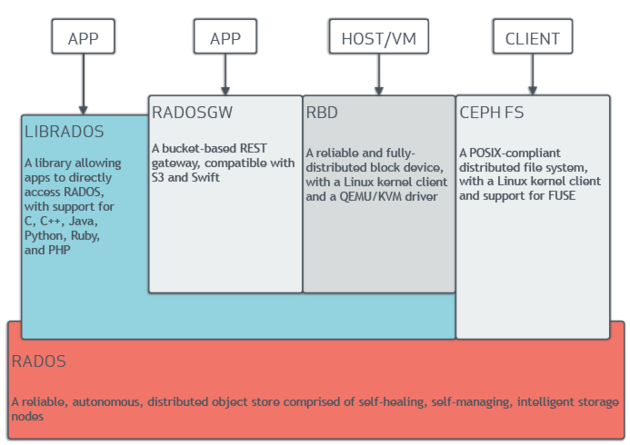
Image Source: https://en.wikipedia.org/wiki/Ceph_(software)
Using a single storage system to meet the storage needs of multiple scenarios (virtual machine images, massive small files, and general file storage) is still very attractive. But because of the complexity of the system, it requires strong operation and maintenance capabilities to support. At present, only block storage is relatively mature and has wide application, the object storage and file system are not ideal in that case. I have heard some use cases that they gave up after a period of use.
The architecture of CephFS is shown below:
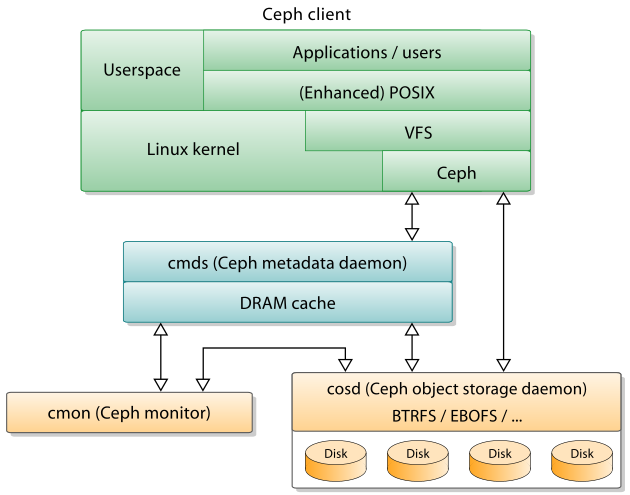
Image Source: https://en.wikipedia.org/wiki/Ceph_(software)
CephFS is implemented by MDS (Metadata Daemon), which is one or more stateless metadata services that load the meta information of the file system from the bottom layer OSD and cache it in memory to improve access speed. Because MDS is stateless, it is relatively easy to configure multiple spare nodes to implement HA. However, the backup node has no cache and needs to be warmed up again. It is possible that the recovery time will be notable longer.
Because loading or writing data from the storage tier is relatively slow, MDS must use multiple-threads to increase throughput, and various concurrent file system operations result in increased complexity, likely to occur deadlocks or performance sharply decline due to slow I/O. In order to achieve better performance, MDS often needs to have enough memory to cache most of the metadata, which also limits its actual support capabilities.
When there are multiple active MDSs, a part of the directory structure (subtree) can be dynamically assigned to an MDS and completely processed by it to achieve horizontal expansion. Before having multiple MDSs activities, it is inevitable to need a self-lock mechanism to negotiate the ownership of the subtree, and the atomic renaming of the cross subtree through distributed transactions, these mechanisms are very complicated to implement. The current official documentation still does not recommend using multiple MDSs (it's OK to use as a backup).
GFS
Google's GFS is a pioneer and a typical representative of distributed file systems, developed by early BigFiles. Its design concept and details were elaborated in the paper published in 2003, which has a great impact on the industry. Many later distributed file systems inspired by its design.
As the name implies, BigFiles/GFS is optimized for large files and is not suitable for scenarios with an average file size of less than 1MB. The architecture of GFS is shown in the figure below.
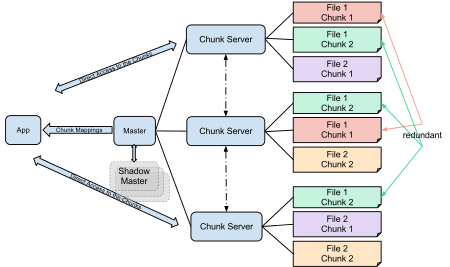
Image Source: https://en.wikipedia.org/wiki/Google_File_System
GFS has a Master node to manage metadata (loaded into memory, write snapshots and update logs to disk), divided files into 64MB Chunk and store to several ChunkServers (using a stand-alone file system directly). Files can only be appended write, no need to worry about Chunk's version and consistency issues (you can use length as a form of version). The use of completely different techniques to solve the metadata and data design greatly simplifies the system complexity and has sufficient scalability (if the average file size is larger than 256MB, the Master node can support about 1PB of data per GB of memory). Dropping support some of the features of the POSIX file system (such as random writes, extended attributes, hard links, etc.) further simplifies system complexity in exchange for better system performance, robustness, and scalability.
Because of the mature and stable of GFS, it makes Google easier to build upper-layer applications (MapReduce, BigTable, etc.). Later, Google developed Colossus, a next-generation storage system with greater scalability, separate metadata and data storage completely, implement distributed (automatic sharding) metadata, and use Reed Solomon encoding to reduce storage space to achieve costs cutting.
HDFS
Hadoop from Yahoo is an open source Java implementation of Google's GFS, MapReduce, etc. HDFS is also a copy of GFS design, so we omitted discussion here. The following figure is an HDFS architecture diagram:
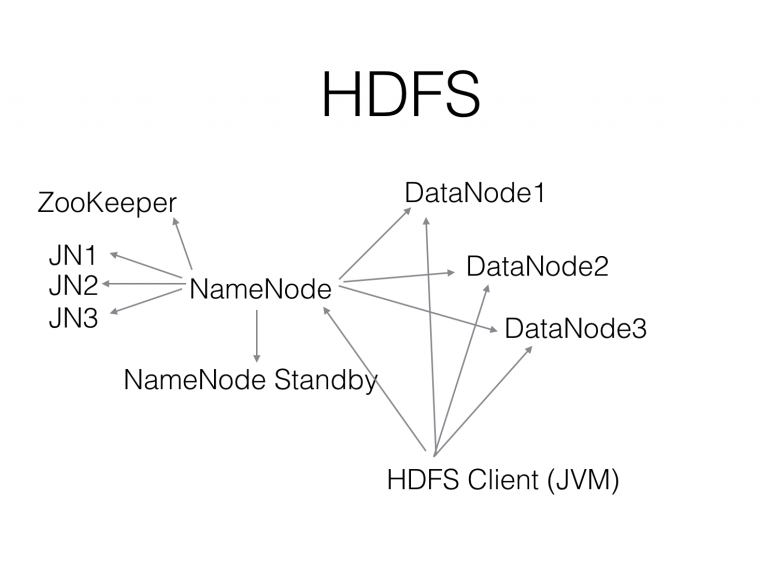
The reliability and scalability of HDFS are very excellent. There are many thousands of nodes and 100PB level deployment cases. The performance of supporting big data applications is also very gorgeous. Only rare cases about losing data (except for no trash policy configured and removed data by mistake).
HDFS's HA solution was added later and implemented complexly. It was so complicated that Facebook, the first to do this HA solution, manually do failover switch (does not trust automatic failover) for a long time (at least 3 years).
Because the NameNode is implemented in Java, depending on the pre-allocated heap memory size. Insufficient allocation can trigger Full GC and affect the performance of the entire system. Some teams tried to rewrite it in C++, but still no mature open source solution.
HDFS also lacks mature non-Java clients, making it challenging to use in scenarios (such as deep learning) other than big data (such as Hadoop).
MooseFS
MooseFS is an open source distributed POSIX file system from Poland. It also inspired by the architecture of GFS. It implements most of the POSIX semantics and APIs. It can be accessed like a local file system after being mounted by a very mature FUSE client. The architecture of MooseFS is shown below:
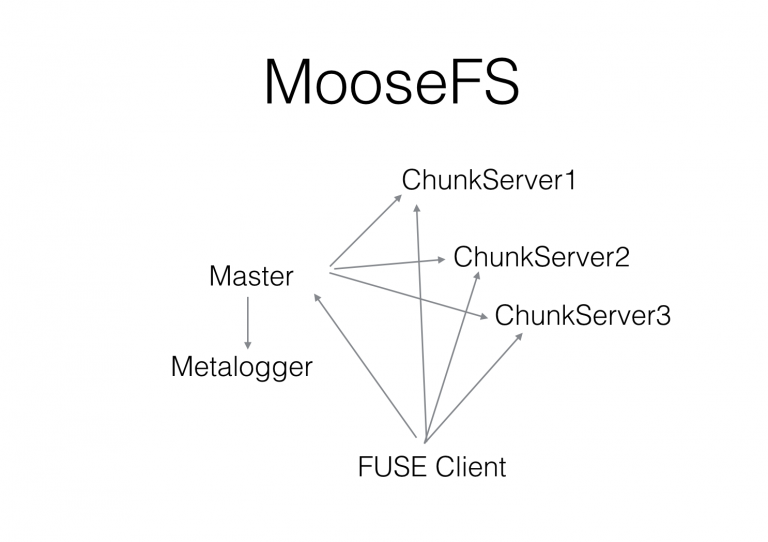
MooseFS supports snapshots, and it is convenient to use for data backup or backup recovery scenarios.
MooseFS is implemented by C. The Master is a standalone thread of asynchronous event-driven, similar to Redis. However, the network part uses poll instead of the more efficient epoll, which results in consume tremendous CPU resources when concurrent reach about 1000.
The open source community version does not have HA, it is implemented asynchronous backup by metalogger. The close source commercial version support HA.
In order to support random write operations, the chunks in MooseFS can be modified. A series of version management mechanism is used to ensure data consistency. This mechanism is more complicated and likely to occur different problems (for example, there may be a few chunk actual copies below expected after the cluster restart).
JuiceFS
The above GFS, HDFS and MooseFS are designed for the environments of self-built datacenter. The reliability of the data and the node availability are combined to solved by multi-machine and multiple copies. However, in a public cloud or private cloud virtual machine, the block device is already a virtual block device with three copies of reliability design. If implemented by multiple machines and multiple copies way, the cost of data will be extremely high (actually it is 9 copies).
Therefore we designed JuiceFS for the public cloud, improved HDFS and MooseFS architecture. The architecture is shown below:
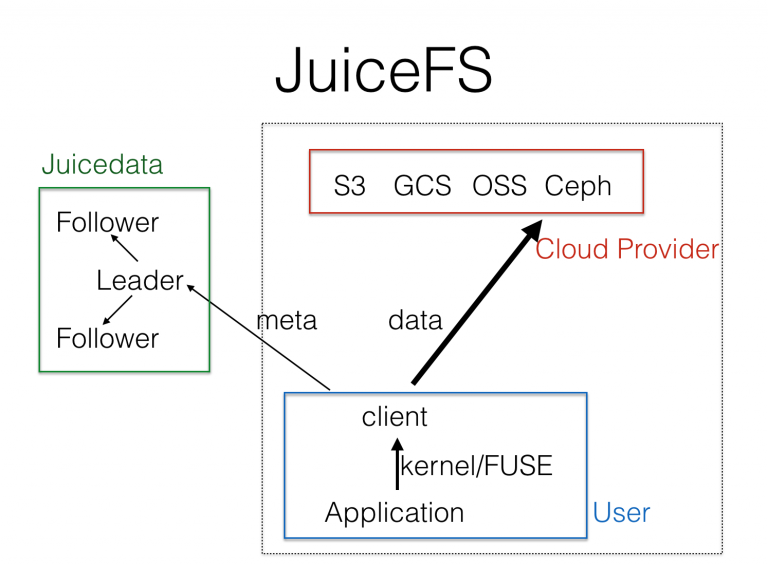
JuiceFS replaces DataNode and ChunkServer with the object storage which is already existed in the public cloud, implemented a fully flexible serverless storage system. Public cloud object storage has already well solved the security and efficiency problem of large-scale data store. JuiceFS only needs to focus on the management of metadata, and dramatically reduces the complexity of metadata services (master of GFS and MooseFS need simultaneously solve metadata storage and health management of data blocks). We've also made many improvements to the metadata part, and implemented Raft-based high availability from the beginning. To provide a service with high availability and high performance, metadata management and operation are still very challenging. Metadata is provided to users as a service. Because the POSIX File system API is the most widely used API, we implement a highly POSIX compatible client based on FUSE, which allows users to mount JuiceFS to Linux or macOS with a command line tool, access as fast as a local file system.
The dotted line on the right in the figure above is the part responsible for data storage and access. For the sake of the user's data privacy, they are entirely running in the customer's own account and network environment, and unable to communicate with the metadata service. We (Juicedata) have no way to access the customer's content (except for metadata, please do not put sensitive content in the file name).
Conclusion
The above briefly introduces the architecture of several distributed file systems that I have learned. The following diagram put them together in the order of time (arrows indicate that the latter refers to the former or is the new generation version):
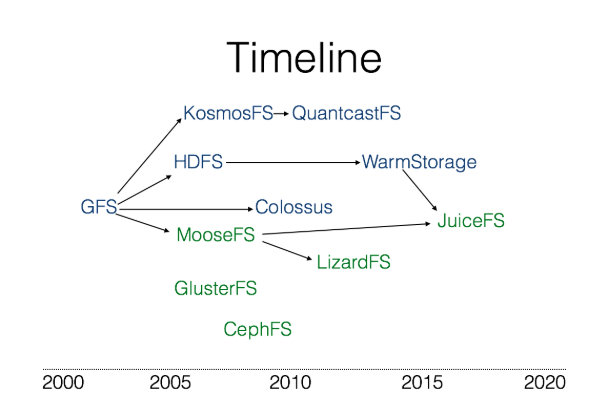
The blue ones in the upper part of the above figure are mainly used for big data scenarios, which implements a subset of POSIX, while the green ones below are POSIX-compatible file systems.
The system design of separate metadata and data represented by GFS can effectively balance the complexity of the system, effectively solve the storage problem of large-scale data (usually large files), and has better scalability. Colossus and WarmStorage, which support distributed storage of metadata under this architecture, are even more scalable.
As a successor, JuiceFS learned how MooseFS implements a distributed POSIX file system. Also learned the idea of completely separating metadata and data from Facebook's WarmStorage, and desires to provide the best experience of distributed storage for public or private cloud scenarios. By storing data in object storage, JuiceFS effectively avoids the cost problem of double-layer redundancy (block storage redundancy and distributed system multi-machine redundancy) when using the above distributed file system. JuiceFS also supports all public clouds, without worrying about a cloud service lock, and smoothly migrating data between public clouds or regions.
Conclusively, if you have a public cloud account on hand, [Sign up with JuiceFS] (https://juicefs.com/accounts/register), you can mount a file system with a PB capacity in your virtual machine (or even your macOS) in 5 minutes.