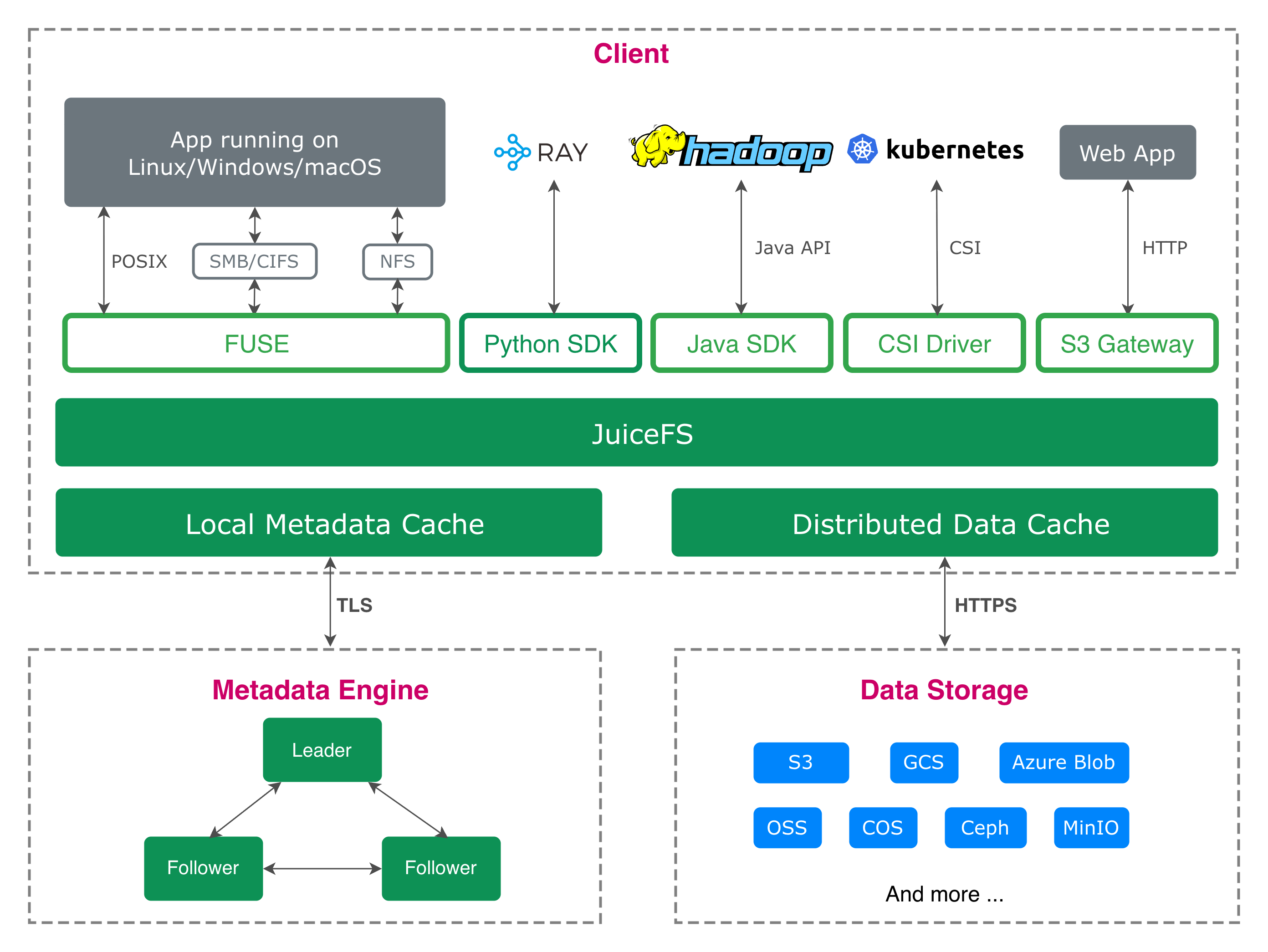
Highly scalable: Horizontally scalable, supporting 100 billion+ files per volume.
High performance: Delivers sub-millisecond latency, further reduced in real-world applications through client metadata caching.
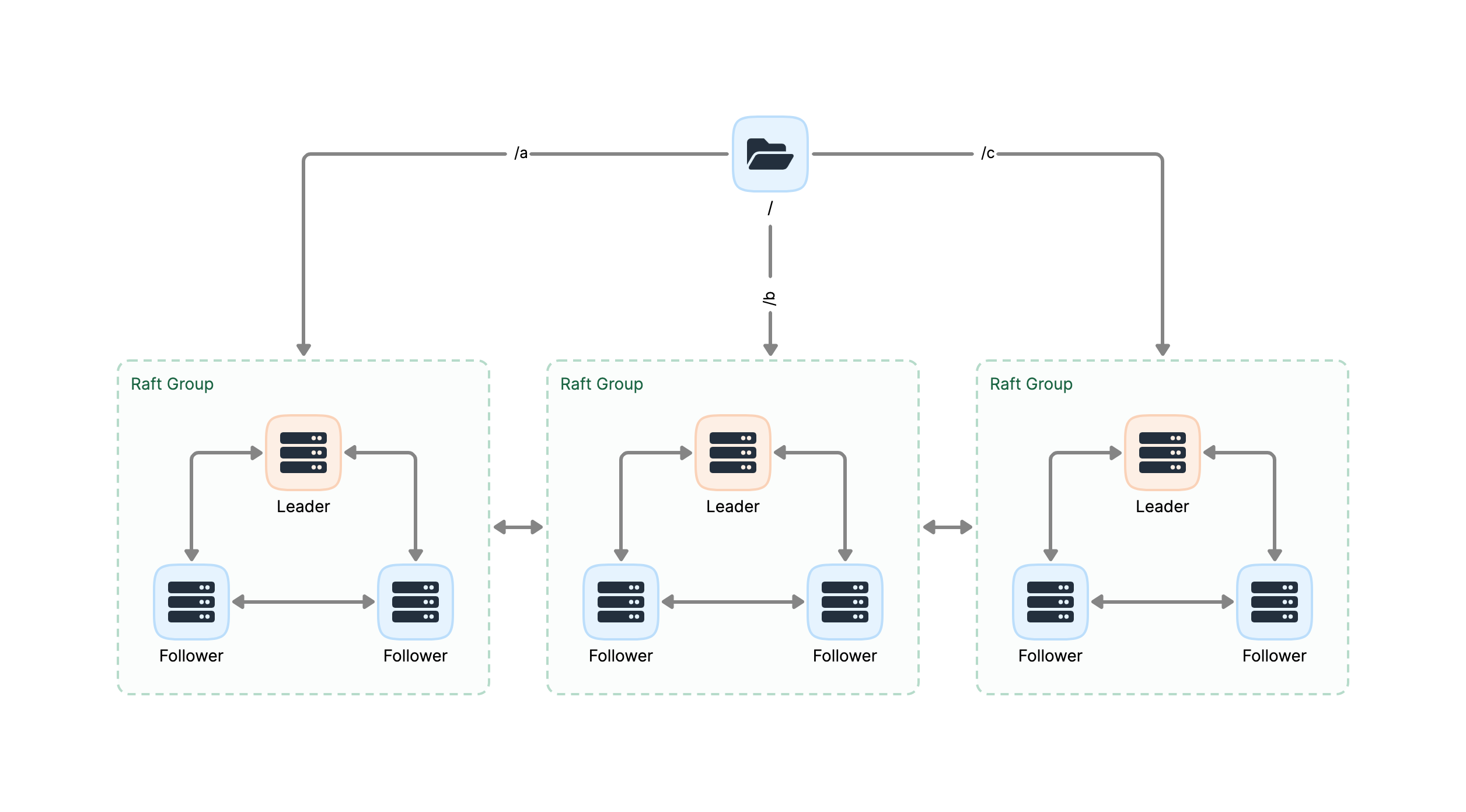
Strong consistency: Data replication based on the Raft consensus algorithm.
High availability: Fault-tolerant with automatic failover for node failures. (Learn more)
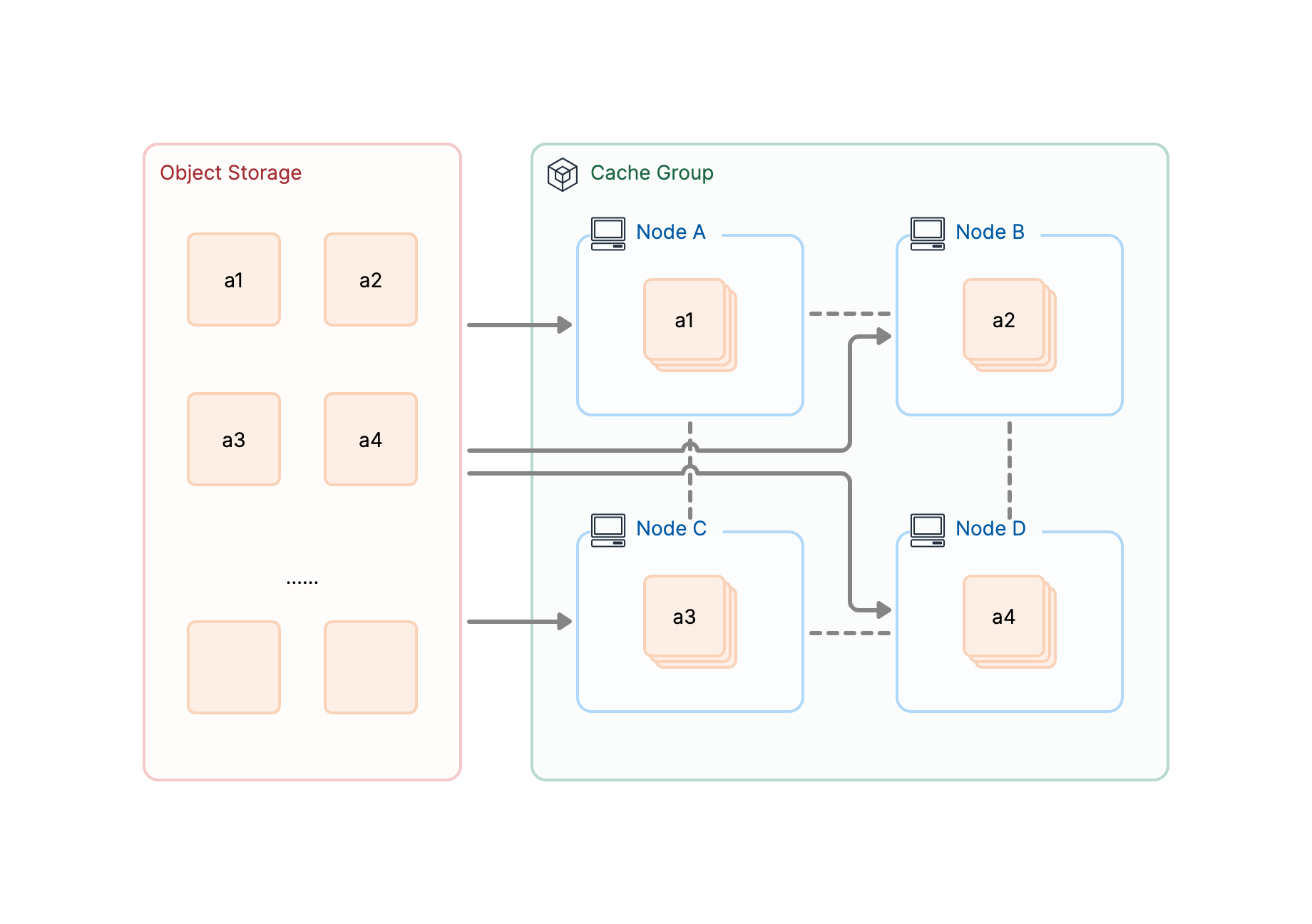
Distributed caching enhances read bandwidth and reduces latency.
Unlimited cluster read throughput: Scales out cluster read throughput with near-linear aggregate performance for concurrent access.
Decentralized architecture: Effectively prevents single points of failure (SPOF).
Effortless data tiering: Easily separate hot and cold data for optimized storage management. (Learn more)
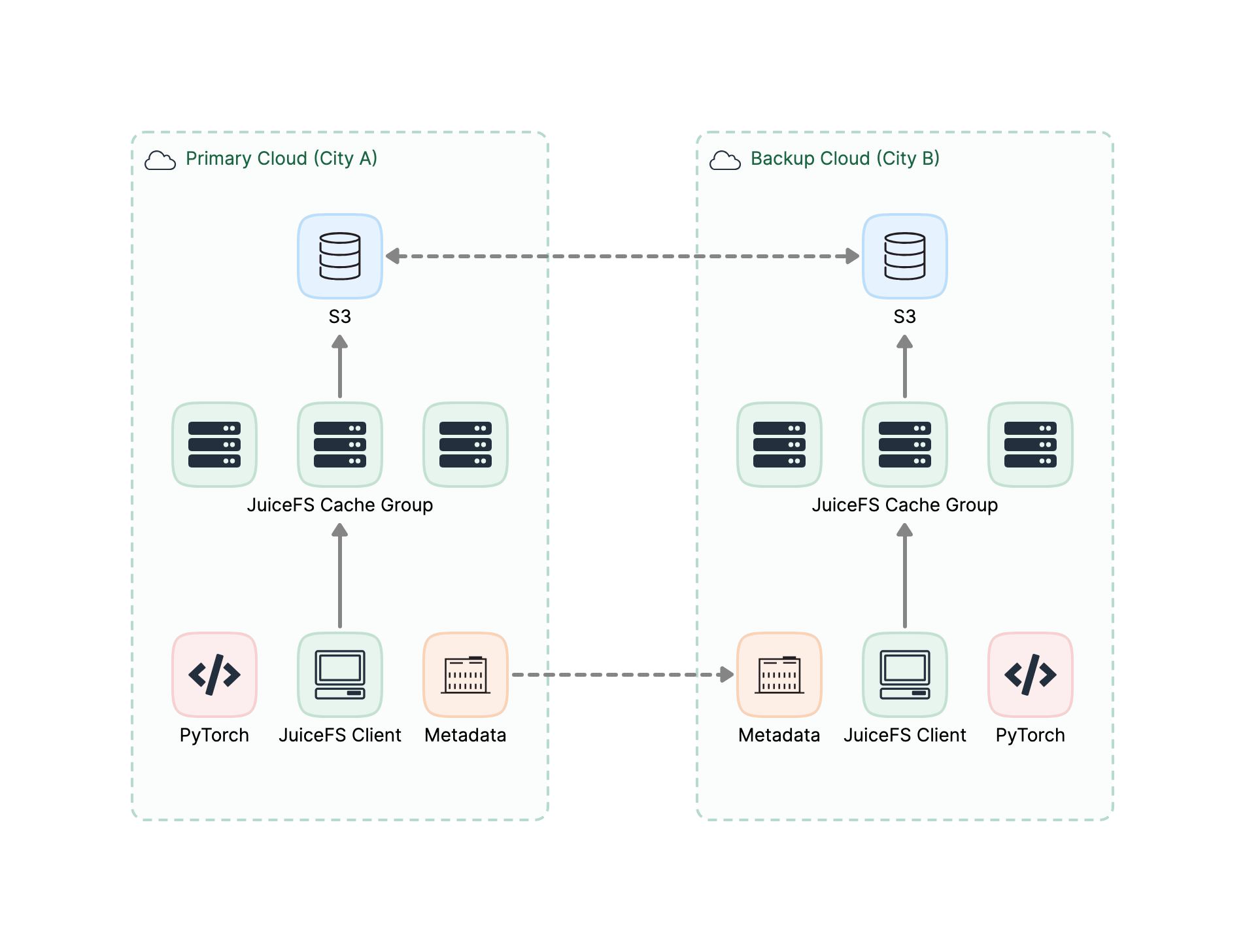
Automatic data distribution across multi-cloud architectures.
Automatic data replication across clouds and regions: Meets efficient enterprise data management needs in a multi-cloud architecture.
Sub-second metadata synchronization: Supports AI training scenarios across regions and clouds.
Deployable on all public clouds: Can be deployed on all public clouds, freeing users from reliance on a single cloud platform.
Strong data consistency: Instantly syncs updates across nodes, ensuring a single source of truth. (Learn more)
Application Scenarios
Generative AI
High-throughput, low-latency data access supports the entire AI pipeline's data processing. This reduces data movement and improves GPU utilization.
Autonomous Driving
JuiceFS supports managing hundreds of billions of files in a single volume with high performance, making it ideal for the autonomous driving.
Quantitative Trading
JuiceFS alleviates the enormous metadata pressure during backtesting with a dynamic caching layer and enables elastic scaling of throughput performance.
Bioinformatics Technology
JuiceFS demonstrates outstanding performance in dealing with massive small files in the bioinformatics field.