Distributed cache
By default, JuiceFS Client cache is exclusive to the client mount point only, when many clients need to access the same data set repeatedly, distributed cache is a great way to share cache data and improve performance. Distributed cache is best suited for deep learning model training based on GPU cluster. By caching the training dataset into memory or SSD on all nodes, JuiceFS provides high-performance data access capabilities, so that the GPU capability is not bottlenecked by data access.
Architecture
When distributed caching is enabled, client members will form a "distributed cache group," which is actually a consistent hashing ring. Each cached data block's storage location is calculated using consistent hashing and shared within the group. Every group member is essentially a normal JuiceFS mount point client, with its group name specified by the --cache-group option. All clients with the same group name make up a "cache group," and all cache sharing only happens within the same group: when a client initiates a read request, the data block is obtained directly from the member node. If the data is not yet cached on the node, the node will download the data from object storage and store it in the cache disk.

As illustrated above, node D is trying to read file a (consisting of 4 data blocks, a1-a4), assuming by consistent hashing that a1-a4 are to be located on nodes A-D, so every member node will access object storage to fetch the corresponding data block. Upon download completion, nodes A-C will send the blocks back to node D to conclude this read request.
Currently, distributed caching assumes high-performance, security private network. If however, hosting on public internet is required, here are some important considerations:
- Public internet typically yields far worse network quality compared to the object storage service, make sure you benchmark in advance, and if latency & throughput isn't ideal, consider giving up on distributed caching and directly download from object storage instead;
- Distributed caching service comes with no authentication mechanism, serving a public network poses data security risks, so network ACL should be properly managed.
Service discovery
In the distributed architecture, our metadata service is used as a service-discovery: every group member client will listen on a local port to serve distributed cache, and register its access address with the metadata service to share cache with its peers. Clients will discover its peers within the same cache group, and then communicate to share cache data.
In a cache group, read & write are carried out via peer communication, if there's any failure during this process, the client will give up on the cache group and execute locally instead. Still using the above diagram as an example: when D is trying to read a file, and request towards A fails (e.g. network timeout), hence block a1 is unavailable, then D will download a1 directly from object storage to complete this read.
If communication with a cache node fails multiple times, the node will be considered unreachable and will be removed from the cache group.
When faced with cache group failures, JuiceFS Client always tries stay serviceable, this means if client fails to communicate with its peers, many requests might penetrate to the object storage, hindering performance. In order to ensure a high performance distributed cache service, pay attention to:
- Client logs, all cache group failures are logged, search for "peer" to focus on cache group only if logs are too large to process.
- Monitoring, particularly
juicefs_remotecache_errors, which contains all end-to-end errors.
Scaling and data rebalancing
When a node joins or leaves the cache group, the data will be migrated to neighboring nodes on the hashing ring (in real world implementation, the migration occurs 10 minutes after the cache group member changes to prevent unintended fluctuations). Therefore, member changes in a cache group only affect a small part of cached data. JuiceFS also implements virtual nodes to ensure load balance, preventing the creation of hot spots in data migrations. Refer to this article to learn more about consistent hashing and virtual nodes.
Group backup
By default, JuiceFS' distributed cache feature caches data only once without creating additional replicas. This is the most efficient setup as long as cache group nodes do not change frequently and internal network communication is stable.
However, in certain scenarios, enabling the group backup feature for JuiceFS clients can improve the stability of cache services. Starting from JuiceFS 5.1, you can enable the group backup feature by specifying the --group-backup parameter during client mount. Here is how it works:
When --group-backup is enabled, if a cache miss occurs, the client calculates the group backup node corresponding to the data block using the cache key and forwards the request to that node for handling. The backup node then checks whether the data is cached locally and either returns the data directly or requests it from object storage. In contrast to a cache group without backup, the cache block is processed by two cache group members before reaching the client. Therefore, ideally the cache block is stored on both member nodes.
Assuming no special circumstances, the architecture of the group backup feature is as follows:

In the diagram:
-
The client requests the data block
b1. The cache group's consistent hash algorithm determines thatb1is located on Node A. -
Node A attempts to serve the request but does not have
b1cached locally. Then, it computes that Node B is the backup node forb1and forwards the request to Node B. -
Node B also misses the cache, so it fetches the data from object storage.
If any of the steps from "client → A → B → object storage" find the data already cached, the request is returned early without further access to the next step. Therefore, the group backup feature does not strictly guarantee two local replicas for every data block. Factors like insufficient cache space, eviction of data, or early cache hits can result in fewer than two replicas.
The target scenarios for the group backup feature include:
- Frequent changes in cache group members, where maintaining stable cache hit rates is important.
- Cache group expansion, where stable hit rates are desirable during the process.
- Unreliable or unstable network quality between cache group nodes, with frequent disconnections, where improving hit rates is crucial.
On the other hand, the following scenarios are not suitable for enabling the group backup feature or must avoid keeping it enabled for extended periods:
- Cache space is already insufficient. Enabling backup will increase space usage, further degrading cache service capacity.
- The group backup feature is not designed to increase throughput. This is a common misconception. Cache group throughput is limited by inter-node bandwidth and cache disk capacity, and adding more replicas does not improve throughput. If you are concerned about hotspots, JuiceFS already distributes cache data across nodes using consistent hashing to balance access pressure, and adding more replicas will not further distribute the load.
Cache data priority
Users might want to associate different importance to different cache data, so that when capacity is full, the less important cache are evicted first to save space for higher priority data. Use --cache-priority for this purpose.
This option can be specified in different subcommands, read below example for more.
# Add this option directly to a mount point, then all cache built through
# this mount point will carry the specified priority.
# This is especially helpful in Kubernetes CSI, as you can associate different priority
# to different PV, to distinguish imporance of application cache data
juicefs mount myjfs /jfs --cache-group=mygroup --no-sharing --cache-priority=3
# Add this option to the warmup command, and the data built via warmup will have the specified priority
juicefs warmup /jfs/big-dir --cache-priority=3
Although cache priority is usually used against distributed cache clusters, it works the same in a single node scenario, you can use the warmup command with different priority to built cache of different importance.
Using distributed cache
A distributed cache group is composed of multiple individual JuiceFS clients, to set up a cache group, simply run the mount command as shown below, in a set of nodes within the same VPC:
# Replace $VOL_NAME with the actual file system name, --cache-group is the user-defined group name
juicefs mount $VOL_NAME /jfs --cache-group=mygroup
Cluster networks can be complicated with nodes attaching multiple interfaces of different performance levels. To achieve the highest performance, it is recommended to allocate the best performing network device to the cache group:
# --group-ip represents the network device assigned to the cache group. It is not necessary to specify the full IP address; a prefix can be used effectively as a CIDR.
# For example, with the high-performance network interface IP being 10.6.6.1, its CIDR is 10.6.0.0/16.
# Specifying --group-ip=10.6.0.0 will smartly attach the corresponding network interface.
juicefs mount $VOL_NAME /jfs --cache-group=mygroup --group-ip=10.6.0.0
Upon a successful mount, check the client log or directly view TCP connection to verify:
# Search for the word "peer" to see distributed cache related content
# Like <INFO>: Peer listen at 172.16.255.181:36985 [peer.go:790]
grep peer /var/log/juicefs.log
# Check both established and listening TCP sockets to verify that the cache group is working
ss -4atnp | grep jfsmount
Now that the cache group has been built, but it's still empty, in order to improve the first time read performance, the warm up command is often run in advance to cache all the data that needs to be used:
# Execute the warmup in any of the group member yields the same result
# In large scale scenarios, increase concurrency via -c, to speed things up
juicefs warmup /jfs/train-data -c 80
Additionally, you can also specify the --fill-group-cache option (disabled by default), so that data blocks uploaded to object storage are also sent directly to the cache group, so that every write operation contributes to cache. It is important to note that sending data blocks to the cache group may fail, so there is no guarantee that they will be cached.
Some important considerations when building a cache group, which also applies to dedicated cache clusters (introduced in the next section):
- Use a homogeneous set of nodes (at least same disk size for cache storage) for cache group, because the consistent hashing algorithm currently used by JuiceFS assumes all nodes have the same cache storage size. Expect waste on disk usage if you were to use nodes with different disk size for JuiceFS cache group.
- Cache group members are connected to each other at least with 10 Gigabit Ethernet, if multiple network interfaces are installed, use
--group-ipto specify the network device with larger bandwidth. - Cache group members need to ensure high-speed access to the object storage service, low internet speed will result in a poorer use experience.
Dedicated cache cluster
In a distributed cache group, all clients contribute to cache, but if the cache group exists within a cluster that's constantly scaling up and down (like Kubernetes), cache utilization is not ideal because cache nodes are frequently destroyed and re-created. In this case, consider deploying a dedicated cache cluster on a set of nodes (or containers) so that the computation cluster have access to a more stable cache.

While application clients will join this cache group, and obtain data from the group, they'll enable the --no-sharing option, this option literally means that clients will not share their own cache data, and only take from the group. This eliminates ephemeral clients from the cache group and improves stability for the distributed cache group.
As can be seen, a dedicated cache cluster is essentially a distributed cache group, but cache providers and users are different JuiceFS clients. Thus in this scenario, we usually use the phrase "cache cluster" to refer to this stable, permanent cache group, and the word "client" to refer to the application clients that's actually using the cache service, even though they are all JuiceFS clients, just mounted with different options.
Building a dedicated cache requires a cache group, in Kubernetes this is usually deployed as DaemonSet or StatefulSet (see example in our docs), taking the cache group demonstrated in the above section as an example, clients can connect to this group by running:
# Application clients will mount with the --no-sharing option,
# they will join the cache group, but do not provide cache service to other members
juicefs mount $VOL_NAME /jfs --cache-group=mygroup --no-sharing
# You can warm up the data from --no-sharing mount points as well, the result is the same as warming up in any other group members
juicefs warmup /jfs/train-data -c 80
After clients have been set up like above, they will use the cache group in a "only take, never give" manner, but note that even for them, the multi-level cache design still applies: data sent from the remote cache group will be cached locally, in the client cache directory. If you wish to disable client cache altogether, and direct all file access to the cache cluster, you can disable the client cache through --cache-size=0 option:
# Disable client cache to direct all read to the cache cluster
juicefs mount $VOL_NAME /jfs --cache-group=mygroup --no-sharing --cache-size=0
Disabling client cache in order to maximally utilize cache cluster disks, and save client disk space. If client disk comes with poor performance, you can also use this method to increase IO.
Some other --no-sharing caveats:
- If the client node does not hit the cache, the cache group will be responsible for downloading and caching the data, and then provide it to the client. Unless peer communication timeouts or fails, clients themselves do not directly download files from object storage.
- When multiple clients simultaneously access a file that's currently uncached, only a single cache penetration takes place, the corresponding cache group member will handle this download request and then return the result to the clients, there will not be wasted, repeated requests.
Multi-level cache architecture
The multi-level cache architecture introduced previously in the single-node caching scenario also works similarly in distributed caches. That is, upon the existing single-node multi-level cache, there is another layer of multi-level cache from cache group nodes.

However, the multi-level cache under distributed cache is not the single node multi-level cache stacked repeatedly on top: when reading a file through the cache group, FUSE isn't involved in the server side, it just reads from disk and send to peer via network, therefore the page cache is built from the local file system accesses. While in the client side, the read is performed via FUSE, so the kernel page cache is also built via FUSE accesses.
If --cache-size=0 is specified on the client's side, to maximize cache cluster disk usage while saving client disk space, JuiceFS clients will reserve 100MiB of process memory for cache. Together with the kernel page cache built through FUSE, accessing files repeatedly will yield very good performance.
Since 5.0, when a JuiceFS client deletes a file, its cache group (if joined any, regardless of whether its --no-sharing) will actively delete relevant local cache data as well.
Cache group mixed deployment
If you are in a scenario where the performance of the local disk is poor, disabling the local cache as described in the previous section is suitable. However, if you are facing the opposite situation and wish to maximize the utilization of local cache disks for better I/O performance and reduce network communication between nodes, consider mixing and deploying two JuiceFS clients on all nodes: one for the cache cluster and the other serving as the application end client.

Such mixed deployment offers the following benefits:
- The high performance disks are used both as distributed cache and local cache, not wasting any I/O capability;
- All nodes join the same cache group, all file reads are handled by the cache group, which only download from object storage once, effectively consolidating object storage requests and reduce the number of API calls.
Mixed deployment puts cache cluster and --no-sharing clients on a same set of nodes. Assuming a 1TB (1000000MB) disk on each node, use the following mount commands:
# Cache cluster mount point
# --cache-size=500000 limit cache size to 0.5TB
# --free-space-ratio=0.1 limit cache usage to 90% of total disk space
juicefs mount $VOL_NAME /distributed-cache --cache-group=mygroup --cache-dir=/data/distributed-cache --cache-size=500000 --free-space-ratio=0.1
# Application mount point
# --cache-size=1000000 limit cache size to 1TB
# --free-space-ratio=0.01 limit cache usage to 99% of total disk space
juicefs mount $VOL_NAME /jfs --cache-group=mygroup --cache-dir=/data/local-cache --cache-size=1000000 --no-sharing --free-space-ratio=0.01
Even though the two mount point share the same cache disk, they manage their own cache data, and require different cache directories (--cache-dir). Do not use the same cache directory for two mount points or there will be conflicts. This obviously creates redundancy because data will be cached both in the cache cluster and clients, this redundancy is necessary for increasing performance. But note that the above commands have already been tuned to favor local I/O: using smaller --free-space-ratio and larger --cache-size for local clients, this ensures that when cache disks are full, distributed cache is evicted in favor of local client cache.
Mixed deployment can be flexibly tuned according to your specifications, for example, if your environment comes with an excessive amount of memory, you can also use this memory as cache disks to gain even higher I/O:
# Cache cluster mount point
# Adjust --cache-size according to actual available memory
juicefs mount $VOL_NAME /distributed-cache --cache-size=4096 --cache-dir=/dev/shm --cache-group=mygroup
# Application mount point
# Use a minimal --free-space-ratio to maximize cache disk usage
juicefs mount $VOL_NAME /jfs --cache-size=102400 --cache-dir=/data --cache-group=video-render --no-sharing --free-space-ratio=0.01
Maintenance
Remove/replace cache disk
Starting from version 5.1, the JuiceFS client supports the group backup feature. When this feature is enabled, the client forwards cache miss requests to other nodes for assistance. This allows users to handle disk removal or replacement operations more smoothly. Therefore, for clients running version 5.1 or above, it is recommended to follow the steps below:
The steps below assume that only one copy of data is being cached, so --group-backup is used temporarily and turned off once the process is completed. However, if your cluster has already enabled dual replicas, all mount points have the --group-backup parameter enabled by default. Therefore, you can skip the steps related to group backup below.
-
Copy the data from the disk to be removed to other disks. If the available space on a single disk is insufficient to hold the data to be migrated, you can group the data and copy it to other disks based on available capacity.
-
Adjust the following mount parameters:
- Add the
--group-backupparameter. This ensures that after the mount point restarts, the client forwards cache miss requests to other clients for assistance. - Modify the
--cache-dirparameter to remove the old disk. - Since removing the disk changes the total cache capacity of the node, adjust
--group-weightto lower the weight and prevent inefficient utilization caused by inconsistent space between nodes.
- Add the
-
After modifying the parameters, seamlessly restart the JuiceFS client to apply these changes.
-
After the restart, the client rescans the cache directories and rejoins the cache group. If the weights were adjusted, the cache group rebalances the data.
-
After rebalancing the data, to avoid the group backup feature consuming too much space, remove the
--group-backupparameter and smoothly restart the mount point again.
If you are still using a version earlier than 5.1, the JuiceFS client also supports migrating data across multiple disks. However, since the group backup feature is not supported, you may experience more significant cache hit rate fluctuations. Follow these steps:
-
Copy the data from the disk to be removed to other disks. If the available space on a single disk is insufficient to hold the data to be migrated, you can group the data and copy it to other disks based on available capacity.
-
Adjust the following mount parameters:
- Modify the
--cache-dirparameter to remove the old disk. - Since removing the disk changes the total cache capacity of the node, you should adjust
--group-weightto lower the weight and prevent inefficient utilization caused by inconsistent space between nodes.
- Modify the
-
After modifying the parameters, seamlessly restart the JuiceFS client to apply these changes.
-
After the restart, client will scan local cache data and rebalance within the cache group according to the new weight.
Steps are largely the same for disk replacement. Just copy the data to the new disk, change the mount option when needed, and then re-mount.
Cache group member change
For planned maintenance events involving the addition of nodes, it is recommended to use the group backup feature of JuiceFS 5.1 to reduce cache hit rate fluctuations during migration. For planned maintenance events involving node removal, it is recommended to adjust the cache group weight to minimize cache hit rate fluctuations.
The steps below assume that only one copy of the data is cached, so the --group-backup parameter is used temporarily and turned off after use. However, if your cluster has already enabled dual replicas, since the data is already cached in two copies, the impact of adding or removing nodes is minimized, and no additional operations are needed.
If a cache group is deployed within Kubernetes, there's no easy way to adjust mount options for a single client, rendering below procedure undoable. You must first exclude a node from Kubernetes deployment, and mount directly to host using JuiceFS Client, only then can you adjust mount options (and seamless restart) for this single node, and migrate cache data via --group-weight.
When you plan to add nodes, follow these steps:
- Mount JuiceFS on the new node and add it to the cache group. Be sure to include the
--group-backupparameter on the new node. Since the cache disk on this new node is empty, the group backup feature helps excessive access to object storage from this new node. - After running for some time, observe the object storage penetration traffic. Once it stabilizes at a low level, remove the
--group-backupparameter from the new node to avoid excessive space usage by group backup replicas.
For node removal scenarios, JuiceFS clients support adjusting the weight of member nodes via the --group-weight parameter. This parameter can be used not only to form heterogeneous cache clusters (cache groups with nodes of different capacities) but also to explicitly migrate cached data during planned node removal. Follow these steps:
-
Add the
--group-weight=0parameter to the node scheduled for removal:# Set the weight of the node for removal to 0 to explicitly trigger cache data migration.
juicefs mount myjfs /jfs --cache-group=mygroup --group-weight=0Notes:
- After setting the weight to 0, data migration begins 10 seconds after remounting (unlike during node restart or shutdown, where migration starts after 10 minutes). During this data redistribution, cache misses may occur when data is accessed, leading to cache penetration. Refer to the next section for details on how to evaluate the impact of such changes.
- Before data migration completes, accessed data may cause cache penetration. If you want to minimize penetration, avoid reducing the weight to 0 all at once. Instead, gradually lower the weight within an acceptable range.
-
During the ongoing data migration, monitor the migration progress by checking the cache data size (
blockcache_bytes) or cache write traffic (remotecache_putBytes) in the monitoring dashboard. You can also observe object storage traffic and I/O latency to assess the current cache penetration and system performance. Once the local cache size on the node scheduled for removal drops to 0 or near 0, and the cache data on other nodes stabilizes, you can remove the node.
Evaluate the impact of member node changes
Taking node restart as an example, this section outlines the steps to evaluate the impact on the cache group when there is a member change. Node restart seldom exceeds 10 minutes, thus a simple restart will not cause data migration (see architecture). But during downtime, data on the restarting node cannot be accessed, so a restart will definitely fluctuate the cache hit ratio. To actually quantify the impact, we should head to the file system monitor page to do the math.
Assuming the node expecting maintenance is A, open up the monitor page and first pay attention to the overall cache group capacity, which can be viewed directly from the Distributed Cache section:
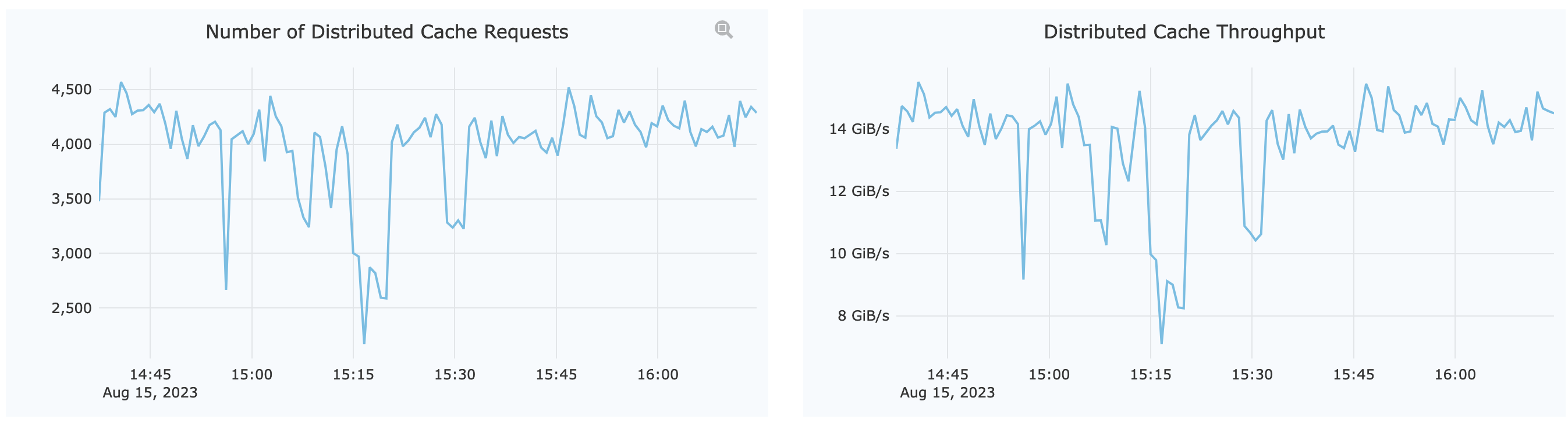
As shown in Number of Distributed Cache Requests, the current number of cache requests is around 4,300 per minute.
Next, find out the actual request load for our node A, filter this node out using the top right All Clients menu, and select node A to focus on its local cache request load:
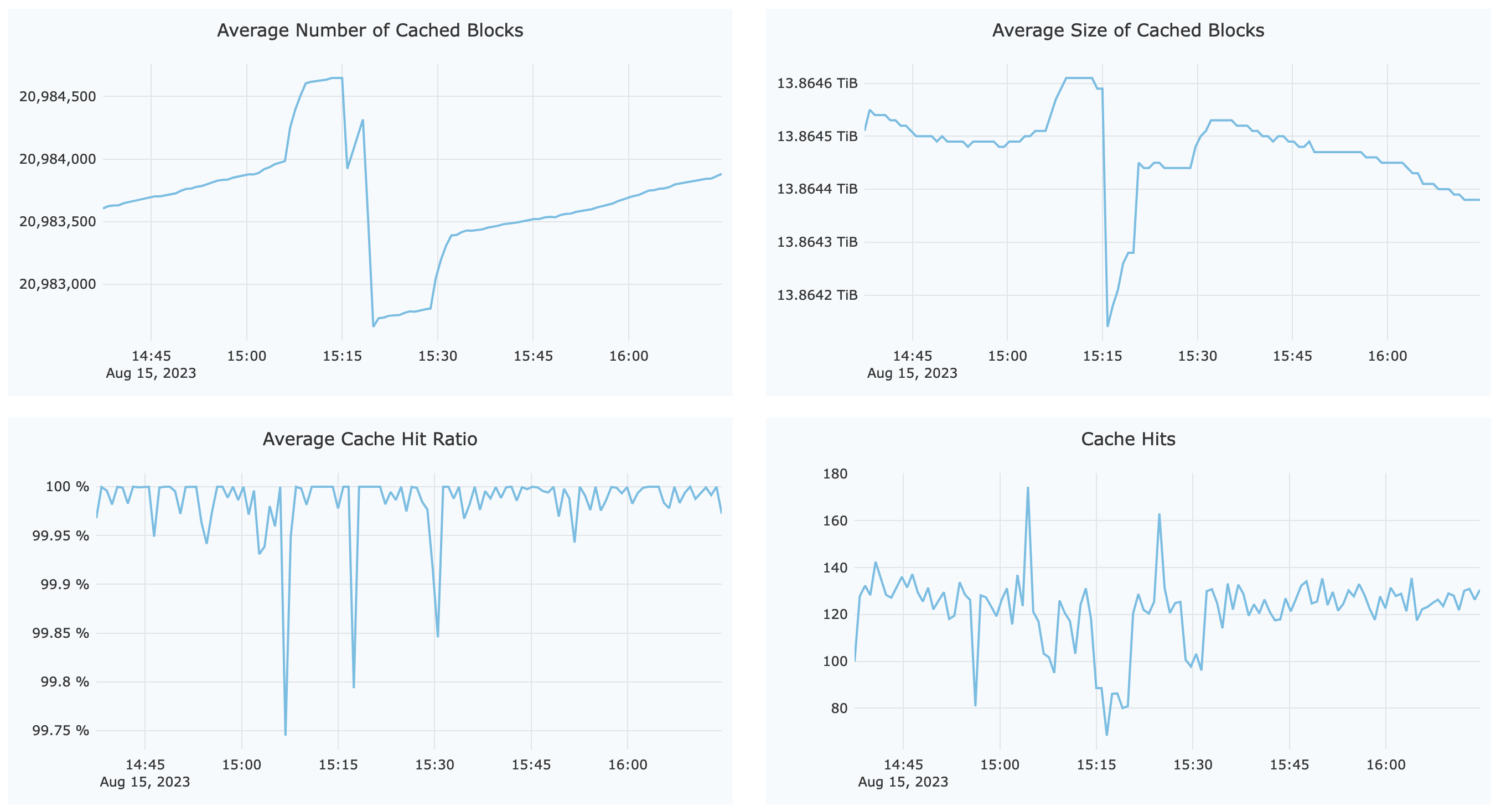
As shown in the figure Average Size of Cached Blocks, node A contains approximately 13TiB of cache data. Keep in mind that the monitor page is already filtered to display only node A. The current Cache Hits value is 130 per minute. Therefore, when this node goes offline, the affected requests are 130 out of 4300, or 3%. That is to say, during node restart, approximately 3% of read requests will penetrate to the object storage, served by its neighbors in the hashing ring. When A goes back online and rejoins the cache group within 10 minutes, the hashing ring topology is kept intact so no data migration is scheduled (except for the few penetrated requests, which are downloaded and cached in its neighbors).
From the cache group's perspective, a node restart involves a quick exit and rejoining. If you're planning a permanent eviction, the evaluation process is largely the same: use the math provided above to calculate the request proportion and local cache size to determine the impact of this eviction.
If the overall capacity is insufficient (also follow the below Observation and monitor section to check current usage and whether an expansion is required), and you decide to add a new node into the cluster, data will be migrated after the cache group member list is stable for 10 minutes to maximize utilization of available disk space and I/O capacity. During this migration, access to affected data will result in cache penetration.
Assuming a total of 500TiB of data is distributed across 40 cache group member nodes and it's expected to grow to 50 nodes, depending on different network bandwidths, the estimated data rebalancing duration will be:
The "Theoretical balancing time" is calculated assuming that the network bandwidth can be fully utilized, which is impossible in real world scenarios, so the calculation results are for reference only.
| Cache group total size | Current number of nodes | Expected number of nodes | Network bandwidth | Theoretical balancing time |
|---|---|---|---|---|
| 500TiB | 40 | 50 | 10Gbps | 2h26m |
| 500TiB | 40 | 50 | 25Gbps | 58m |
The algorithm used to reach this conclusion:
- Before expansion, each node holds 12.5TiB of data (500 / 40 = 12.5). After expansion, the estimated node data size will be 10TiB (500 / 50 = 10). Each node expects to move 2.5TiB of data (12.5 - 10 = 2.5). This means the total migration size is 100TiB (40 * 2.5 = 100).
- Physical nodes are translated into virtual nodes in the hashing ring. Even though only 10 physical nodes are added, the resulting ring topology will see hundreds (to thousands) of new virtual nodes. The existing 40 nodes will transfer these 100TiB of data evenly to the 10 newcomers.
- Assuming the peer network bandwidth being 10Gbps, each new node will receive 10TiB of migration data. The estimation of time spent is 2h26m (10TiB / 10Gbps = 2h26m).
Observation and monitor
Import our Grafana Dashboard and it already includes distribute cache related panels:
- Remote Cache Requests
- Remote Cache Throughput
- Remote Cache Latency
The most important thing to keep in mind about distributed cache hit ratio: a drop in client's cache hit ratio, doesn't necessarily indicate penetration against the cache group. When a client access file data that's not cached locally, it'll fetch all the data blocks from the cache group. Hence, client's miss becomes cache group members' hit. So next time when you noticed a drop in hit ratio, check for any obvious object storage traffic spikes, this'll tell you if cache group has been penetrated.
To calculate overall hit ratio of a cache group using Prometheus query language:
# Depending on your environment, metric prefix may need substitution
# For on-prem deployments, Grafana dashboard "volume overview" already contains this query
1 - (sum(rate(mount_get_bytes{owner="", subdir="$name", cache_group!="", cache_group=~"${cache_group:raw}"}[1m])) / sum(rate(mount_read_bytes{owner="", subdir="$name", cache_group!="", cache_group=~"${cache_group:raw}"}[1m])))
The denominator of the above query is read_bytes, i.e. FUSE read traffic, which may contain various non-disk reads. If you wish to accurately represent hit ratio, you need to calculate hits / (hits + object_get) where hits is the local cache hits on all member nodes, and object_get being the penetrated object storage requests.
Some common maintenance based on monitoring:
- Check the "Block Cache Hit Ratio" and "Object Requests" for signs of cache penetration, if there's indeed unexpected cache penetration, check "Block Cache Size" for the current usage, and see if the cache disks need an upgrade.
- Low cache group storage storage will cause block eviction, observe this using
juicefs_blockcache_evictand other relevant metrics. See Metrics for more. - Check requests latency for cache group server nodes, i.e. Remote Cache Latency (server), if any node are running with high latency, there may be a black sheep in the group, you need to examine this node and probably add a
--no-sharingoption to prevent it from serving other members.
Troubleshooting
If a cache group doesn't yield expected performance, before going into troubleshooting, we recommend:
- If possible, enable DEBUG logging for all cache group members, and pay special attention to the word
peer, as this word usually appears in the log text when the cache group member changes. - Check distributed cache related metrics, under on-premises deployments, you can directly view "Remote cache" related panels in Grafana.
Is cache capacity enough, data completely warmed up?
When using dedicated cache cluster, data is usually warmed up in advance, if there's still massive object storage penetrations, it may indicate insufficient cache capacity, and the cluster cannot hold all of the data blocks.
When using juicefs warmup, a frequently encountered situation to keep in mind is that even the command succeeds, file data isn't necessarily completely stored locally. The warmup intrinsically only cares about the download process, you're responsible to ensure a sufficient cache capacity (both in the cache disk, and the --cache-size option) so that cache blocks aren't evicted. For a single node cache disk, you can manually run something like du --max-depth 1 -h /var/jfsCache to verify the actual size, but for a cache group, you'll have to check the Block Cache Eviction Rate monitor for signs of eviction. An empty panel indicates that there's no eviction, which means the warmup runs without a problem. But if there's eviction happening (shown below), it means capacity is limited and cannot hold all cache data.
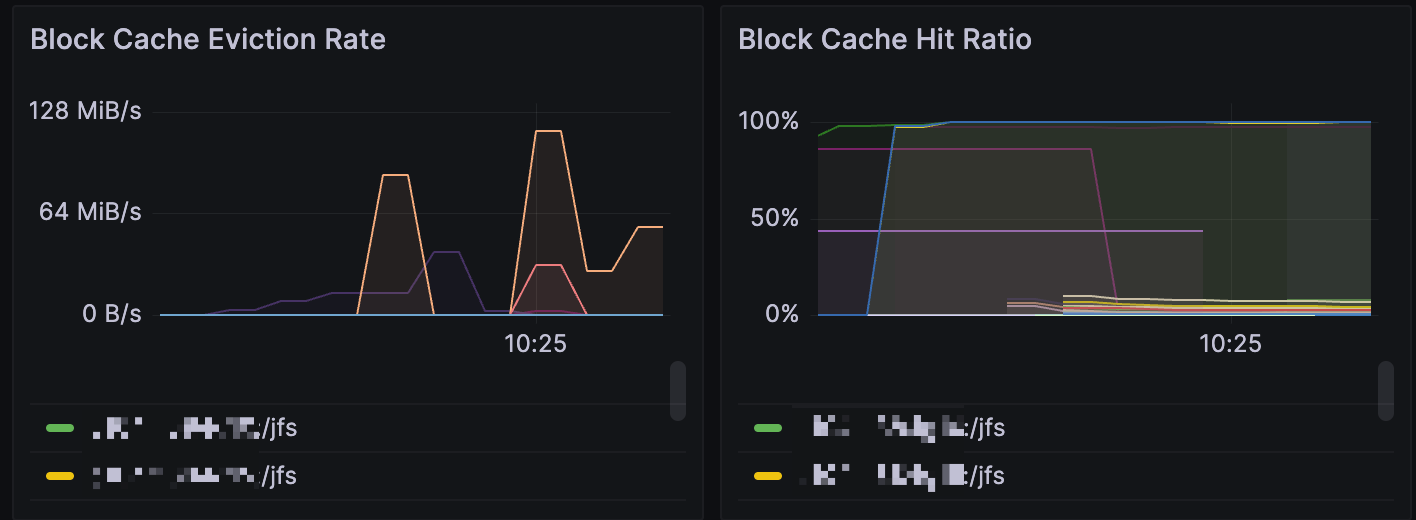
As explained above, a warmup success is necessary condition for a 100% hit ratio, but not a sufficient one, because eviction can happen due to a variety of reasons. But on the other hand, if warmup doesn't succeed (return a non-zero code), then some data blocks does not successfully download, continue reading for troubleshooting steps.
juicefs warmup works against the specified mount point, add --verbose to the mount command, and check client log for errors, like:
<ERROR>: xxx could be corrupted: chunk x:x:xxx is not available: read header: EOF
This means cache group members encountered errors when downloading the data blocks, there're various causes for this, enable --verbose as well on cache group member nodes, and check their logs for signs of error.
Are there multiple network interfaces in cache group member nodes? Is the correct one being used?
For nodes with multiple network interfaces, if those network cannot connect to each other, or has poor bandwidth, then it might be unfit for distributed cache use. Check network connectivity using commands like:
# Enter a cache group member node (or container)
# For member nodes, JuiceFS Client listens on a local port, for peer communication
# pprof listens at 6060 and 6070 by default, the port used for distributed cache is usually the largest one
lsof -PiTCP -sTCP:LISTEN | grep jfs
# Enter a client node (or container), and test network connectivity against distributed cache member node
telnet [member-ip] [port]
If it's required that you change the bind network interface for cache group, use the --group-ip option in the mount command to specify desired IP address. Note that CIDR prefix is also supported, e.g. --group-ip=172.16.0.0 to match with 172.16.0.0/16, this eliminate the need to specify different mount commands for different cache group members, making things easier to manage.
Is the intranet bandwidth of cache group members limited?
It is recommended to connect the nodes of JuiceFS distributed cache with at least 10 Gigabit network. If you build a cache group under a low-bandwidth network, such as a Gigabit network, the following errors may occur:
# Peer network bandwidth too low, or not connected at all
<INFO>: remove peer 10.8.88.242:40010 after 31 failure in a row [peer.go:532]
# Peers are connected, but network quality is bad, causing peers to be removed from group following immediate rejoin
<INFO>: add peer 10.8.88.242:40010 back after 829.247µs [peer.go:538]
# Failure to download data blocks from peer
<WARNING>: failed to get chunks/6C/4/4020588_14_4194304 for 10.6.6.241:38282: timeout after 1m0s [peer.go:667]
<ERROR>: /fio_test/read4M-seq.2.0 could be corrupted: chunk 1:0:4020660 is not available: read header: read tcp 10.8.88.241:34526->10.8.88.242:40010: i/o timeout [fill.go:235]
# Download speed too slow
<INFO>: slow request: GET chunks/6E/4/4020590_0_4194304 (%!s(<nil>), 105.068s)
Make sure cache group peers are connected using 10 Gigabit Ethernet, use tools like iperf3 if you need to measure.
If you cannot easily improve cache group hardware (network and disk), be sure to use JuiceFS 5.1 or later. In previous versions, the JuiceFS client set cache group header timeouts to 10 seconds and body timeouts to 1 second. JuiceFS 5.1 extends these timeouts to 65 seconds and enhances concurrency control. This enables distributed caching to perform more effectively under network congestion.
Is there a black sheep within the cache group?
Cache group's high performance really requires that all peers are equipped with network devices of similar bandwidth, and cache disks of similar available capacity. If any of the member nodes comes with poor network performance, it'll systematically hinder the overall performance.

As shown above, assuming an equal distribution of cache data between the three nodes, but one comes with poor network (could be potentially caused by a faulty --group-ip setting, binding the wrong net interface, or this node comes from a different network environment, not suitable for this cache group at all), then obviously, 1/3 of the cache requests will be served by this slow node, systematically degrading the cache group performance.
In a larger scale cache cluster, the black sheep problem can cause obscure performance issues difficult to debug, for example if there's only one bad node among all 200 members, the total affected requests percentage may be low enough to escape debugging. In this case, check Remote Cache Latency (server) to see if there's any members with abnormally high latency, as they are likely the culprit.
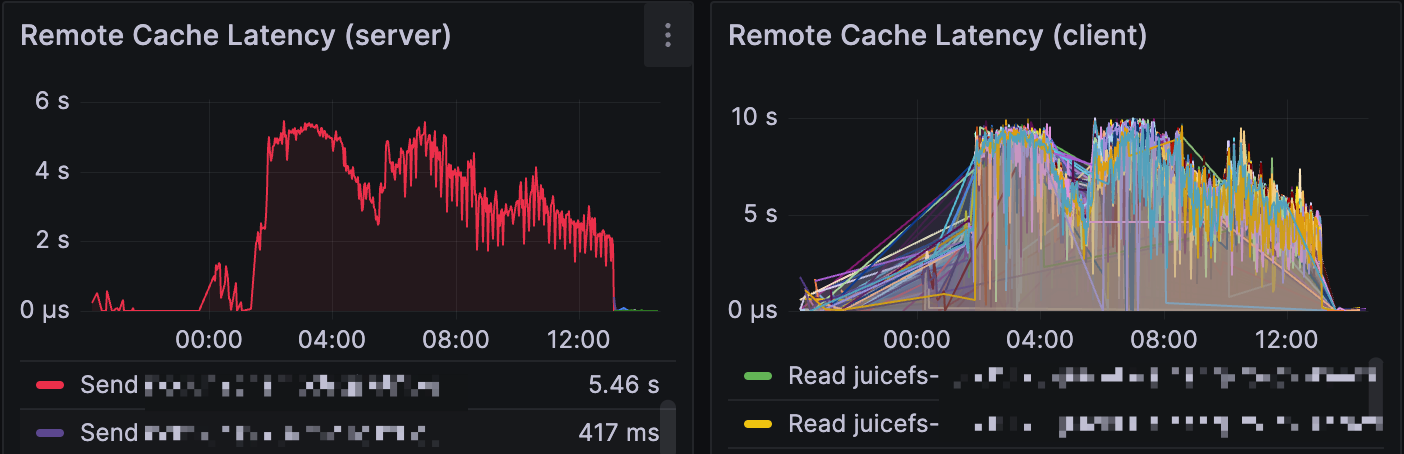
As demonstrated above, one bad apple among the cache group can worsen the overall performance, in the Remote Cache Latency (server) panel, sort by the Send latency and find if the top ones are abnormally high, if that's indeed the case, check the problematic nodes and consider add a --no-sharing option to prevent them from serving cache requests.
Can the cache group access the object storage service at high speed?
If cache group members cannot download data from object storage fast enough, you'll get similar problems listed above. Use a lower download concurrency to try to achieve a more stable warmup process, like juicefs warmup --concurrent=1.
Is client load too high?
High client load can cause low hit rates for distributed cache. For example, client enabled --fill-group-cache option, so that processed data is contributed back to the distributed cache while written to the file system. If these clients run into performance problems due to high load, writes to JuiceFS file system will still succeed, but cache data exchange with peers will likely fail due to timeouts (cache write failures are not retried), in this case, --fill-group-cache doesn't work well, read requests on relevant files will cause penetration to object storage, resulting in a low cache hit rate.

