Fio Benchmark
This document includes guidelines for planning and designing performance tests and performance results under different conditions. If you are only interested in the JuiceFS performance results, please go directly to the relevant sections below.
Define test goals and resource limits
The JuiceFS client can achieve very high throughput (2GB/s for reading a single large file) — provided it has sufficient resources and uses a high-performance object storage service. Before beginning the file system test, it is essential to clarify the purpose: are you aiming to push the limits with maximum resources, or testing under conditions that resemble actual production resource constraints?
Setting clear testing goals will guide optimization if results do not meet your expectations. If you aim to test JuiceFS' peak performance, maximize resources to eliminate any resource-based performance bottlenecks. However, the peak performance measured under such ideal conditions is often impossible to replicate in a real-world environment, as production resources cannot be endlessly allocated to a single application (or the JuiceFS client). For this reason, we recommend testing in conditions that closely approximate actual production resource limitations, focusing on the performance achievable with a fixed allocation of resources. The tests conducted in this article were designed based on this approach.
Test object storage performance (optional)
Before starting, it is recommended to first verify the object storage performance to see if it meets the advertised specifications. When there are high performance expectations for the storage backend but actual testing reveals limited throughput, it can lead to confusion about whether the issue lies in insufficient tuning of JuiceFS, a possible bug, or simply the object storage not delivering the expected performance. To avoid this, we recommend confirming the true performance level of the object storage beforehand to establish a solid foundation.
If you are using public cloud object storage services (such as S3 and OSS), this step may not be necessary. However, for self-hosted object storage or commercially licensed object storage in an on-premises deployment, we advise that performance testing of the object storage be treated as essential and completed before starting any further tests.
Unless you have specific requirements, the juicefs objbench command is recommended for testing object storage performance. Here is an example using Ceph, beginning with a single-thread throughput test to establish a baseline:
# Record the benchmark when p=1 to obtain the best latency and single-thread bandwidth data for later estimation.
juicefs objbench --storage=ceph --access-key=ceph --secret-key=client.jfspool jfspool -p=1 --big-object-size=4096
Gradually increase concurrency (-p), doubling it each time (up to the number of CPU cores), to observe latency and bandwidth. In the early stages, the performance should ideally grow linearly. It is important to note that when concurrency is high, if a larger bandwidth is anticipated, increase the --big-object-size parameter to ensure there is sufficient data for accurate read and write operations. For example:
juicefs objbench --storage=ceph --access-key=ceph --secret-key=client.jfspool jfspool -p 128 --big-object-size=4096
After reaching the peak using incremental concurrency, for certain object storage SDKs, you may also need to increase the --object-clients parameter. For example, the Ceph SDK imposes a bandwidth limit on individual client instances. Increasing the number of client instances with this parameter allows for higher object storage concurrency and improved throughput, thereby identifying the limits of a single server. For example:
juicefs objbench --storage=ceph --access-key=ceph --secret-key=client.jfspool jfspool -p 128 --big-object-size=4096 --object-clients=[2|3|4]
Confirm hardware information (optional)
For self-built data centers, it is recommended to record and verify the specifications of the machines in advance for the following reasons:
- Ensuring the accuracy of the environment
- Confirming that the hardware performance meets expectations
CPU
Record details about the CPU model, count, cores, and frequency:
dmidecode -t processor | grep -E 'Socket Designation|Version|Speed|Core|Thread'
Check the CPU governor. Depending on the model and driver, the method of querying may vary. A simple way to check is by viewing the current running frequency:
cat /proc/cpuinfo | grep MHz
If the frequency significantly deviates from the nominal value, it is recommended to consult with the vendor to confirm that performance modes and related options are correctly set (for example, selecting "performance mode") to minimize the impact of CPU frequency fluctuations on the accuracy of performance testing.
Memory
Record information about type, count, size, frequency, and NUMA:
dmidecode --type memory | grep -E "Configured Memory Speed|Volatile Size|Type: DDR" | grep -vE "None|Unknown"
numactl --hardware
Disk
The disk's performance is crucial for the caching capability of JuiceFS, especially in distributed caching scenarios. If using a self-built data center, it is recommended to test the disk's performance immediately after installation to ensure it meets the specified standards.
For example, for NVMe disks, you can use nvme-cli to check:
nvme list
Use fio to conduct read and write benchmark tests. The examples below will provide IOPS for 4k random read/write and throughput for 1M large files.
fio --name=4k --filename=/dev/nvme0n1 --ioengine=libaio --direct=1 --iodepth=128 --bs=4K --rw=randwrite --numjobs=16 --group_reporting
fio --name=4k --filename=/dev/nvme0n1 --ioengine=libaio --direct=1 --iodepth=128 --bs=4K --rw=randread --numjobs=16 --group_reporting
fio --name=1m --filename=/dev/nvme0n1 --ioengine=libaio --direct=1 --iodepth=128 --bs=1M --rw=write --numjobs=16 --group_reporting
fio --name=1m --filename=/dev/nvme0n1 --ioengine=libaio --direct=1 --iodepth=128 --bs=1M --rw=read --numjobs=16 --group_reporting
Compare the test results with the nominal performance data for the disk model to ensure compliance with expectations. If performance discrepancies are noted, aside from potential disk faults, it might also be due to incorrectly connecting a disk that should use the NVMe protocol to a SATA AHCI interface, leading to performance degradation. You can collaborate with data center operations personnel to investigate.
Network card
-
Record network card information and identify the corresponding network interface based on the planned network segment. Run
ethtool <interface>to confirm its bandwidth. If the network card is bonded, usecat /proc/net/bonding/<interface>to record bond information, including details about replicas and hash policies. -
Network card rates may be influenced by CPU and other factors. In the absence of additional network load, use
iperffor throughput testing and record the results. -
During testing, verify routing correctness. For example, by using
sar -n DEV 1to check network card traffic status, determining if traffic is correctly routed and if bond traffic is balanced. -
If independent caching cluster scenarios are required, ensure clarity on the locations of the caching provider and consumer nodes and whether these machines are within the same network environment. If cross-VPC or other network environments are involved, it is recommended to test performance across these environments in advance to prevent network-related performance degradation.
Mount parameters pre-optimization
As recommended in the previous section, you should first set resource limits and conduct testing within those constraints. Before using fio for testing, optimize the performance parameters of the mount point according to your specific scenario. Note that JuiceFS' mount parameters extend beyond those mentioned in this section; many other parameters can also influence performance. However, it is certain that in most scenarios, by thoroughly understanding and setting these key parameters, you can achieve very good performance.
Buffer optimization
Since all I/O operations in JuiceFS go through buffers, --buffer-size is the most impactful parameter on JuiceFS performance. If you are unfamiliar with what a read/write buffer is, see this document.
Assuming a resource limit of 32 CPU cores and 64 GB of memory, for high-load scenarios, the estimated memory consumption for the client can be approximately 4 times the buffer size. Therefore, throughout the testing process, --buffer-size should not exceed 64 * 1024 / 4 = 16384.
A buffer size of 16 GB is already quite large and can provide high concurrency and throughput. Fio testing usually does not require such a large buffer. Therefore, an initial setting of 1,024 or 2,048 is recommended. If signs of insufficient buffer space arise (using juicefs stats to monitor buffer usage in real time), you can further increase it within acceptable limits.
juicefs mount --buffer-size=1024 myjfs /jfs
Concurrency optimization
The concurrency of the JuiceFS client is primarily controlled by buffer size—the larger the buffer, the greater the concurrency for pre-fetching and concurrent uploading. Therefore, increasing buffer size inherently increases concurrency. However, in specific scenarios where the derived concurrency based on buffer size may not be appropriate, JuiceFS provides the --max-uploads and --max-downloads parameters to explicitly set concurrency limits. These parameters are tuning options for specific scenarios, and generally (especially in large file sequential read scenarios), there is no need to adjust them further for the following reasons:
- The default value for
--max-uploadsis 20. Assuming a 4 MB object storage block’sPUTlatency is 50 ms, the maximum upload throughput within a second is1000 / 50 * 4 * 20 = 1600M. This is already extremely high. Therefore, upload concurrency usually does not require further increases. Higher upload concurrency is only necessary in cases of high-frequency small writes or frequent small file creations. - The default value for
--max-downloadsis 200, and similar reasoning applies. This value does not need further adjustment. Even in scenarios with a large number of random reads or small files, the default value can handle the workload well.
"Usually not required" is based on empirical experience. If you encounter bottlenecks in practice, you can check the output of juicefs stats to determine whether adjustments to these two parameters are necessary based on actual concurrency monitored.
Cache and cache group related optimization
If you only need to test single-machine performance, setting the cache size --cache-size is easy: set it as large as the available cache space. If you want to test without caching, you can specify --cache-size=0 to disable local caching.However, note that even with local caching disabled, the JuiceFS client will still occupy approximately 100 MB of memory as cache space. This may still show about 100 MB of cache usage in monitoring.
If the test requires [distributed caching]](../guide/distributed-cache.md), a detailed testing plan for the cache group must be developed. You need to consider the following:
- What is the maximum number of nodes that the cache group provider can support?
- What is the total capacity of the cache group? Can it hold the estimated amount of hot data? If the estimated data volume exceeds the cache group capacity, consider incorporating penetration tests within the fio test.
- Will a dedicated cache cluster architecture be used? If so, define the resource limits for both the provider and the client on the consumption side.
- If a dedicated cache cluster is not used and application access occurs directly within the cache group, it is recommended to use a high-performance network with sufficient bandwidth to support communication between nodes.
After confirming these aspects, translate the specifications into cache-related parameters such as
--cache-size,--group-weight,--group-ip, and--no-sharingto configure the JuiceFS mount point accordingly.
Testing tools
Fio offers a wide range of parameters. If you are new to this tool, you can learn the usage of the most essential parameters in the table below to construct tests effectively.
| Parameter | Description |
|---|---|
name | The name of the test job. |
directory | The path for reading/writing test data, typically set to the JuiceFS mount point (for example, /jfs in the following examples). |
readwrite, rw | Read/write mode. For testing with JuiceFS, use one of read, write, randread, or randwrite to test sequential read, sequential write, random read, and random write performance, respectively. |
blocksize, bs | Block size for each read/write operation. Use 1m or 4m for sequential read or write scenarios, and 4k-256k for random tests, or set it according to your application’s requirements. |
numjobs | Concurrency level. By default, each job is a separate forked thread. With no special settings, each job reads and writes a separate batch of files, without multiple jobs accessing the same file simultaneously. This is also recommended for testing. |
openfiles | Unless otherwise required (such as when using time_based mode), use --openfiles=1 to restrict each thread to opening and processing one file at a time. By default, fio opens nrfiles number of files. This can lead to JuiceFS’ buffer quickly becoming overwhelmed, severely affecting performance. If testing multiple files open for repeated reads is not essential, the default configuration is serial handling within a single thread. |
filename_format | Generally, avoid this parameter. Fio does not support multiple jobs reading the same batch of files concurrently, so specifying filename_format may lead to a in single-threaded, non-concurrent, serial reads. Modify test cases so that each job reads a distinct batch of files instead. |
filename | Generally, avoid this parameter. For example, using it during sequential write tests to specify file names can cause fio to write to the same file from multiple threads. This can cause FUSE write traffic to exceed object storage’s PUT traffic. |
size | Total file size processed by each job. |
nrfiles | Number of files generated in each job. |
filesize | Size of each file created per job. This should meet the condition filesize * nrfiles = size, so it is not necessary to set this along with size. |
direct | After a file is read, the kernel caches data and metadata using available memory. This means only the initial read triggers a FUSE request, while subsequent reads are handled by the kernel. To avoid kernel caching and focus on testing FUSE mount performance, use --direct=1 unless otherwise needed. However, if you want to make the most of the actual scenario and fully utilize available memory to enhance I/O performance, you can remove --direct=1 to use the kernel cache. |
ioengine | Use the default ioengine=psync unless otherwise specified. If your application in production uses aio, configure ioengine=libaio in fio and add -o async_dio to the JuiceFS mount point to match. |
refill_buffers | By default, fio reuses data segments created at the start of the job. By setting this parameter, fio regenerates data for each I/O submission, ensuring randomness in test file content. |
end_fsync | With JuiceFS, a successful write only commits data to the read/write buffer, not to object storage. A close or fsync is required for persistence. For accurate write performance testing, enable this parameter to reflect the true performance of JuiceFS. |
file_service_type | Defines how files are selected during the test, with random, roundrobin, and sequential options. Some test cases in this document use file_service_type=sequential to ensure that the test tasks promptly close files, triggering JuiceFS to persist the written data. In this regard, using end_fsync would be more appropriate. |
Construct tests
This section provides examples of fio commands to help you design tests for your environment.
If files in the test set are reusable for both read and write, begin with a write test. The generated files can serve as input for subsequent read tests.
The sequential write test:
# Sequential write to a single large file.
fio --name=big-write --directory=/mnt/fio --group_reporting \
--rw=write \
--direct=1 \
--bs=4m \
--end_fsync=1 \
--numjobs=1 \
--nrfiles=1 \
--size=1G
# Concurrent sequential write to a single large file with 16 threads, writing 16 large files in total.
fio --name=big-write --directory=/mnt/fio --group_reporting \
--rw=write \
--direct=1 \
--bs=4m \
--end_fsync=1 \
--numjobs=16 \
--nrfiles=1 \
--size=1G
# Concurrent sequential write to multiple large files, with 16 threads each writing 64 large files.
fio --name=big-write --directory=/mnt/fio --group_reporting \
--rw=write \
--direct=1 \
--bs=4m \
--end_fsync=1 \
--numjobs=16 \
--nrfiles=64 \
--size=1G
The sequential read test:
# Clear local and kernel cache as needed before testing.
rm -rf /var/jfsCache/*/raw
sysctl -w vm.drop_caches=3
# Sequential read of a single large file.
fio --name=big-read-single --directory=/jfs/fio --group_reporting \
--rw=read \
--direct=1 \
--bs=4m \
--numjobs=1 \
--nrfiles=1 \
--size=1G
# Sequential read of multiple large files.
fio --name=big-read-multiple --directory=/jfs/fio --group_reporting \
--rw=read \
--direct=1 \
--bs=4m \
--numjobs=1 \
--nrfiles=64 \
--size=1G
# Concurrent sequential read of multiple large files with 64 threads each reading 64 files.
fio --name=big-read-multiple-concurrent --group_reporting \
--directory=/jfs/fio \
--rw=read \
--direct=1 \
--bs=4m \
--numjobs=64 \
--nrfiles=64 \
--openfiles=1 \
--size=1G
For random read/write tests, refer to the commands above, adjusting only the following parameters:
- Use
rw=[randread|randwrite]to specify random read or write. - Set
bsto 4k to 128k or set it to the actual application’s I/O size.
Test different buffer sizes
Buffer size is widely considered one of the most impactful factors on performance. For sequential read/write operations, achieving good performance is only possible with an appropriately sized buffer. This set of tests focuses on the throughput provided by JuiceFS mount points with different buffer sizes. Fio tests will be conducted on each mount point to measure throughput.
Simply put, for large file sequential reads/writes, larger buffers generally lead to better performance (in a reasonable range). If you plan to perform sequential read/write operations on JuiceFS, we recommend setting --buffer-size to at least 1024.
Test environment
Results may differ significantly depending on the object storage service used. There is no guarantee that you will get similar results in your environment. The test environment is as follows:
- JuiceFS mount points are deployed on Google Cloud Platform (GCP), using a c3-highmem-176 server, with 176 CPU cores, 700G memory, and 200Gbps network bandwidth. This setup is an obvious overkill for the tests we're about to run. It ensures there is no resource bottleneck at the client level.
- Tests are run with fio 3.28.
- Apart from buffer size, object request concurrency may need to be adjusted according to its request latency: with ideal latencies (around 30ms), the default low concurrency level is sufficient. But if latencies are high (around 100ms-400ms), we will increase
--max-uploadsand--max-downloadsaccordingly to avoid congestion. At the time of this test, Google Cloud Storage (GCS) latency is around 100ms-400ms, hence a higher concurrency is used.
Sequential writes
The fio settings:
[global]
stonewall
group_reporting
openfiles=1
end_fsync=1
ioengine=sync
rw=write
bs=4M
filesize=1G
directory=/jfs/fio-dir

Sequential reads
[global]
stonewall
group_reporting
openfiles=1
end_fsync=1
ioengine=sync
rw=read
bs=4M
filesize=1G
directory=/jfs/fio-dir

Random writes
Random reads/writes are not strengths of JuiceFS yet, and performance largely depends on metadata latency and object storage latency. Due to the small I/O involved, buffer size has little impact on random read/write performance. Therefore, only random write results are provided here, with client write cache (--writeback) enabled. Random read tests were not conducted.
[global]
stonewall
group_reporting
openfiles=1
end_fsync=1
ioengine=sync
rw=write
bs=4M
filesize=1G
directory=/jfs/fio-dir

Test different block sizes
This set of tests aims to explore JuiceFS' performance with different block sizes (--block-size), so all clients were created according to the getting started guide, with no optimization for specific scenarios.
Moreover, JuiceFS Cloud Service file systems use Zstandard compression, so the --refill_buffers parameter was added to each test job below to generate highly random and low-compressibility data, simulating worst-case performance for comparison. In real applications, JuiceFS often performs better than these baseline metrics. If you'd like to see the test results conducted on optimized mount points, see Test different buffer sizes.
As shown in the results, a 4M block size generally offers the best performance. Larger or smaller sizes may cause performance trade-offs in different scenarios.
Test environment
Performance varies across different cloud providers, object storage types, VM configurations, and operating systems. Unless otherwise noted, the test environment is as follows:
- JuiceFS file systems created on AWS S3 in us-west2 (instructions here).
- EC2 instance type: c5d.18xlarge (72 CPUs, 144 GB RAM) running Ubuntu 18.04 LTS (kernel 4.15.0). This instance supports 25 Gbps networking and enables Elastic Network Adapter (ENA), boosting S3 bandwidth to 25 Gbps, ensuring JuiceFS performance is not limited by network bandwidth during testing.
- Fio 3.1 was used for testing.
- JuiceFS was mounted with default settings (mount instructions).
Large files
In scenarios like log collection, data backup, and big data analysis, sequential read/write of large files is common, and JuiceFS is well-suited to handle this workload.
Note that before testing you must create JuiceFS file systems with different block sizes and mount them. Adjust the --directory parameter in test scripts to point to the appropriate JuiceFS mount point.
Sequential reads of large files
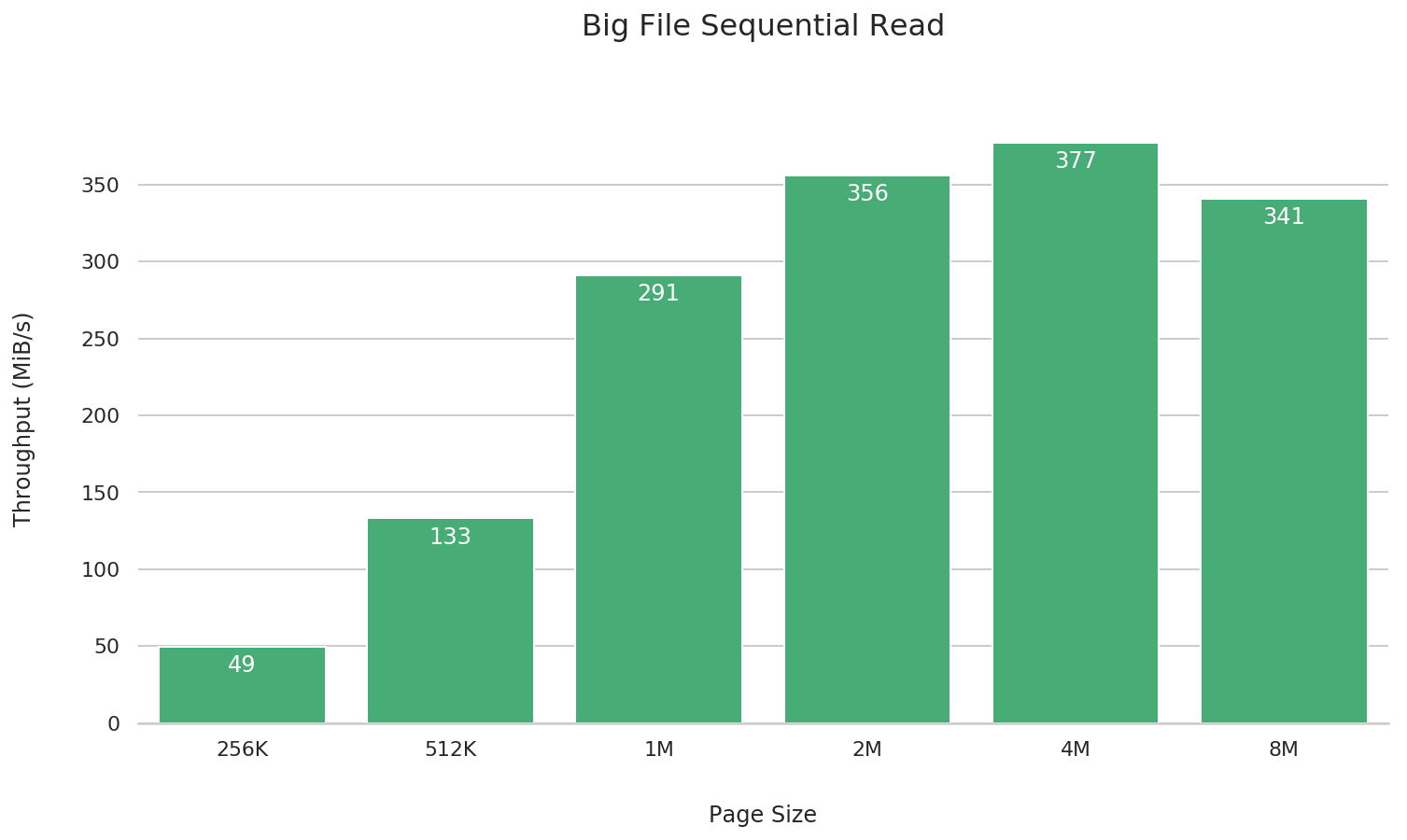
fio --name=big-file-sequential-read \
--directory=/jfs \
--rw=read --refill_buffers \
--bs=256k --size=4G
Sequential writes of large files
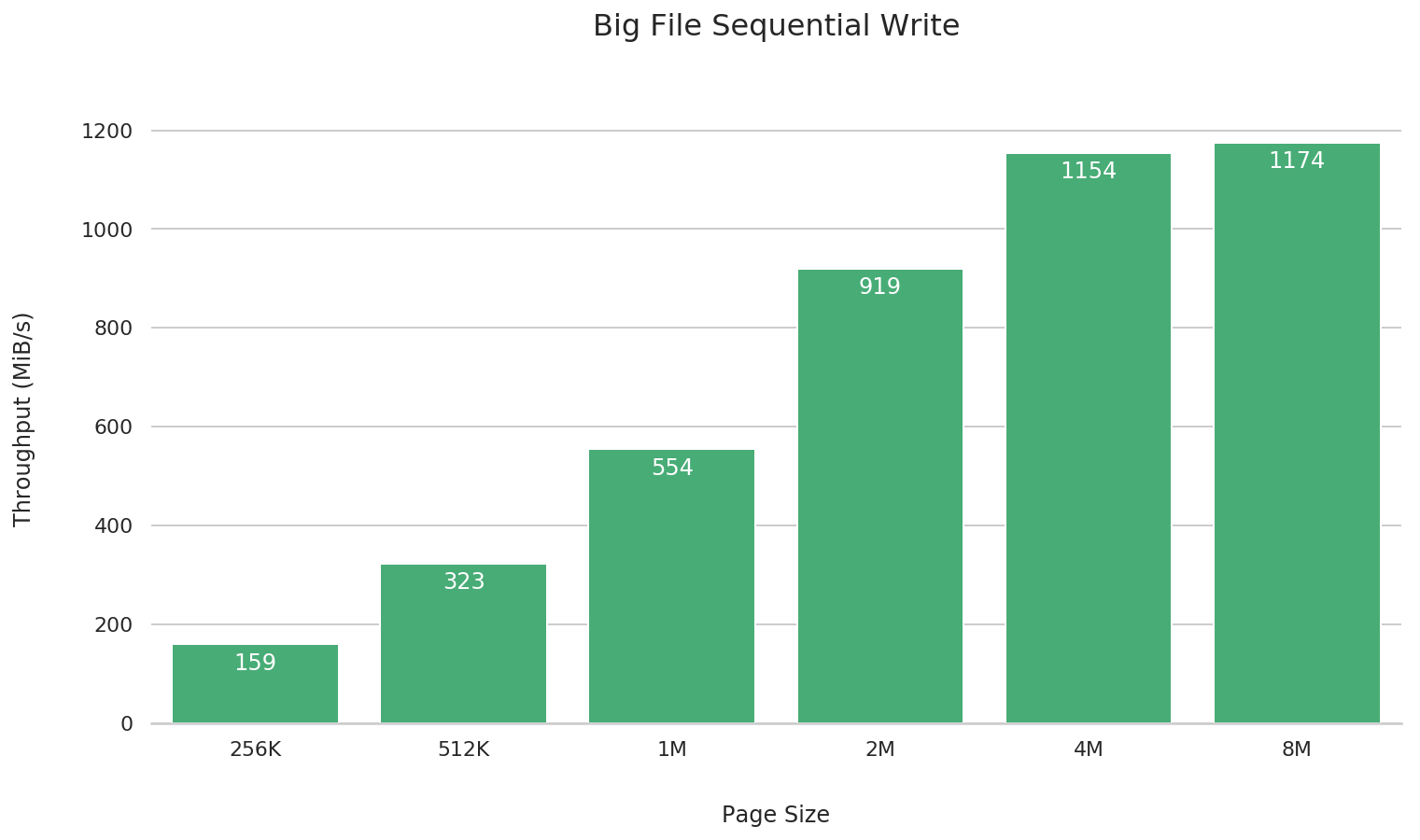
fio --name=big-file-sequential-write \
--directory=/jfs \
--rw=write --refill_buffers \
--bs=256k --size=4G
Large file concurrent read
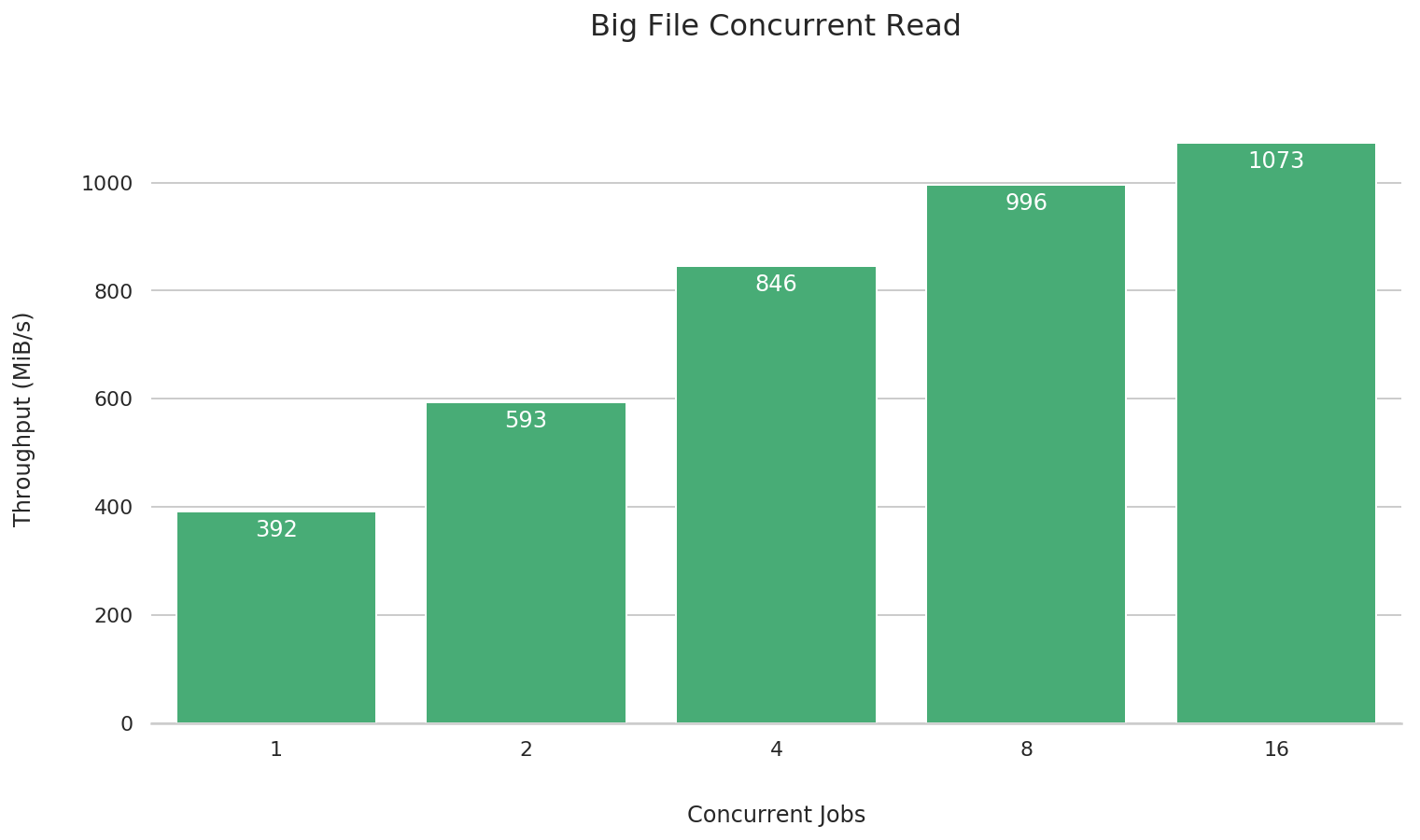
fio --name=big-file-multi-read \
--directory=/jfs \
--rw=read --refill_buffers \
--bs=256k --size=4G \
--numjobs={1, 2, 4, 8, 16}
Large file concurrent write
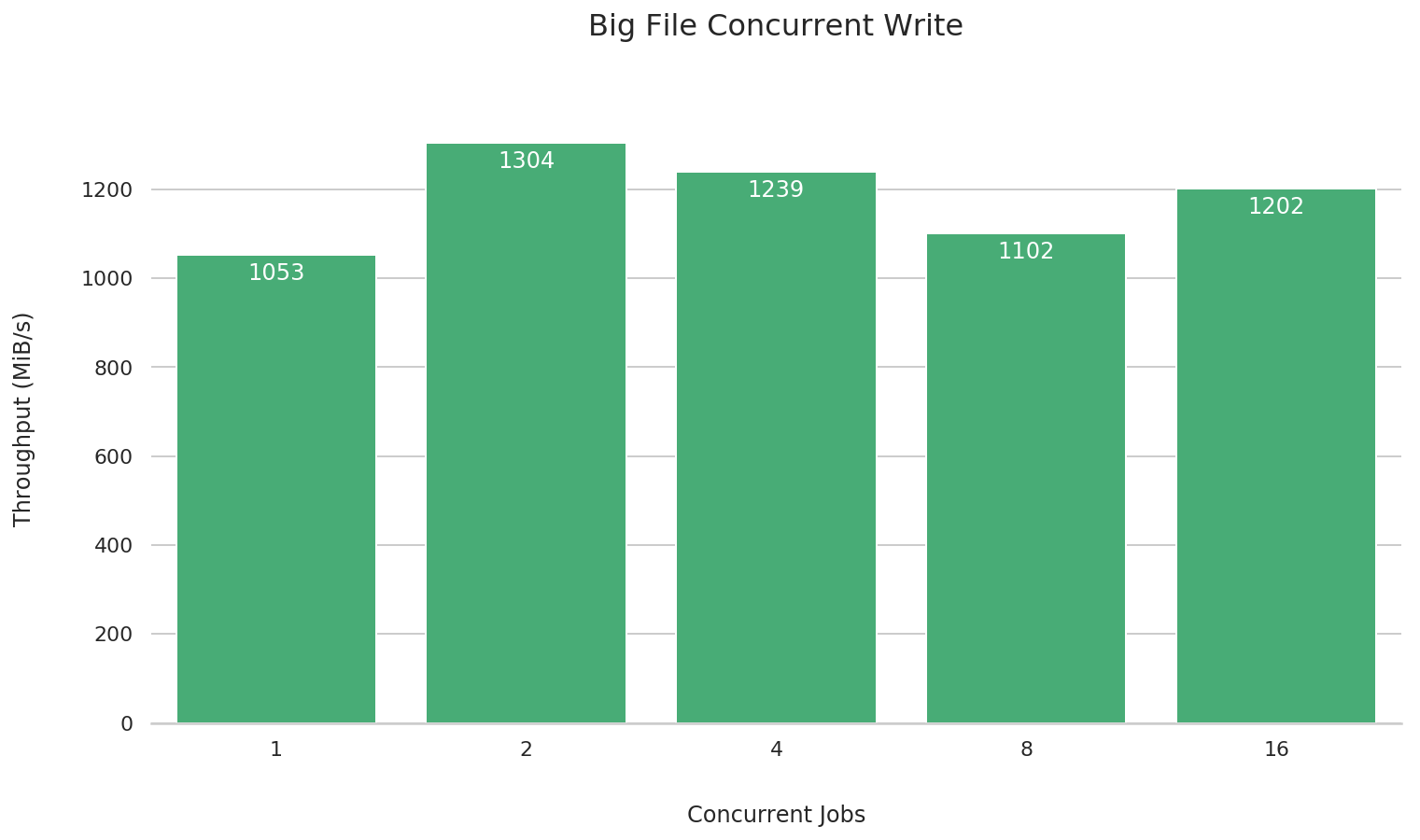
fio --name=big-file-multi-write \
--directory=/jfs \
--rw=write --refill_buffers \
--bs=256k --size=4G \
--numjobs={1, 2, 4, 8, 16}
Large file random read
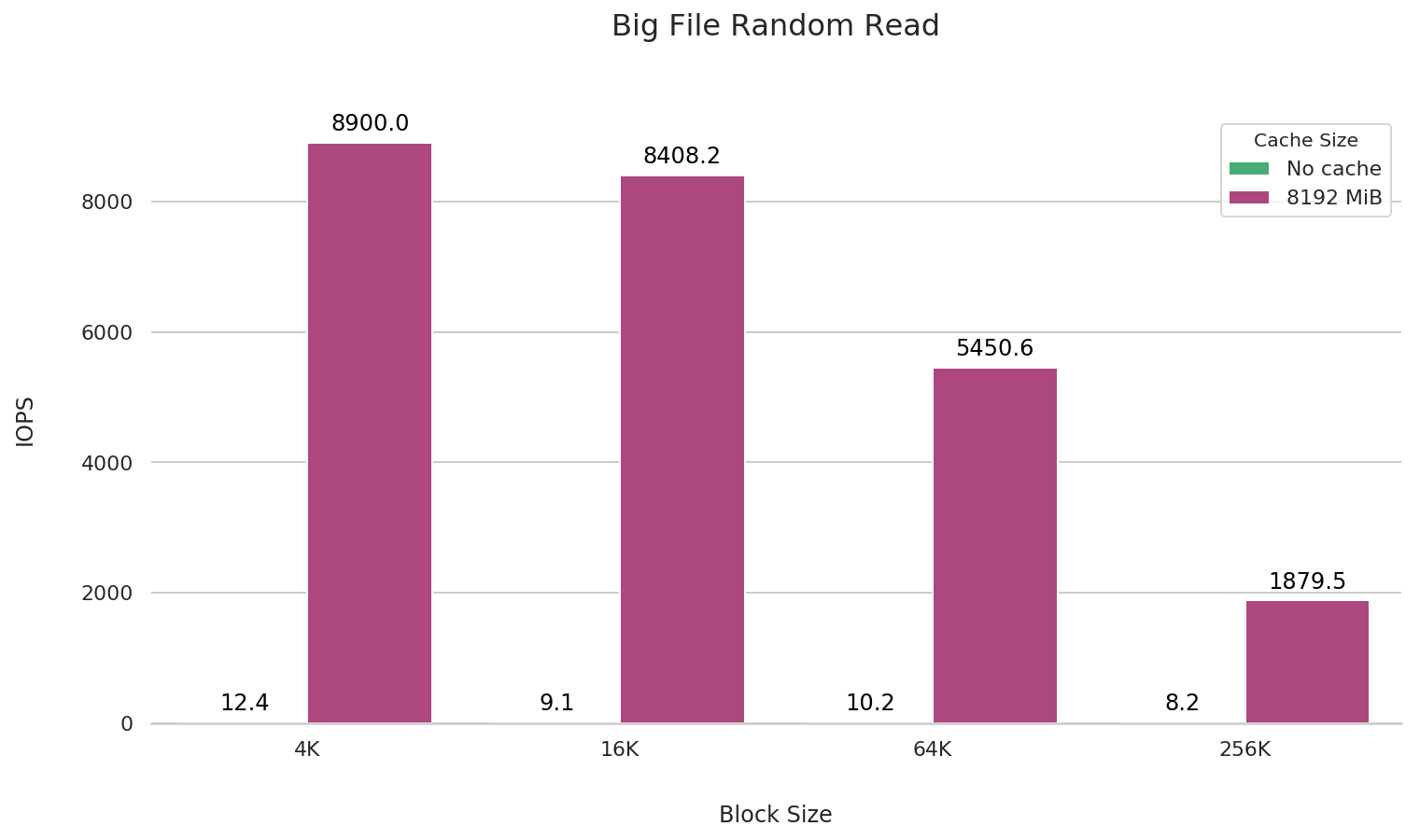
fio --name=big-file-rand-read \
--directory=/jfs \
--rw=randread --refill_buffers \
--size=4G --filename=randread.bin \
--bs={4k, 16k, 64k, 256k} --pre_read=1
sync && echo 3 > /proc/sys/vm/drop_caches
fio --name=big-file-rand-read \
--directory=/jfs \
--rw=randread --refill_buffers \
--size=4G --filename=randread.bin \
--bs={4k, 16k, 64k, 256k}
To accurately assess the performance of large file random reads, we use fio to perform readahead on the file, clear the kernel cache (sysctl -w vm.drop_caches=3), and then use fio to conduct the random read performance test.
In scenarios involving large file random reads, it is recommended to set the cache size of the mount parameters larger than the file size being read to achieve better performance.
Random writes of large files
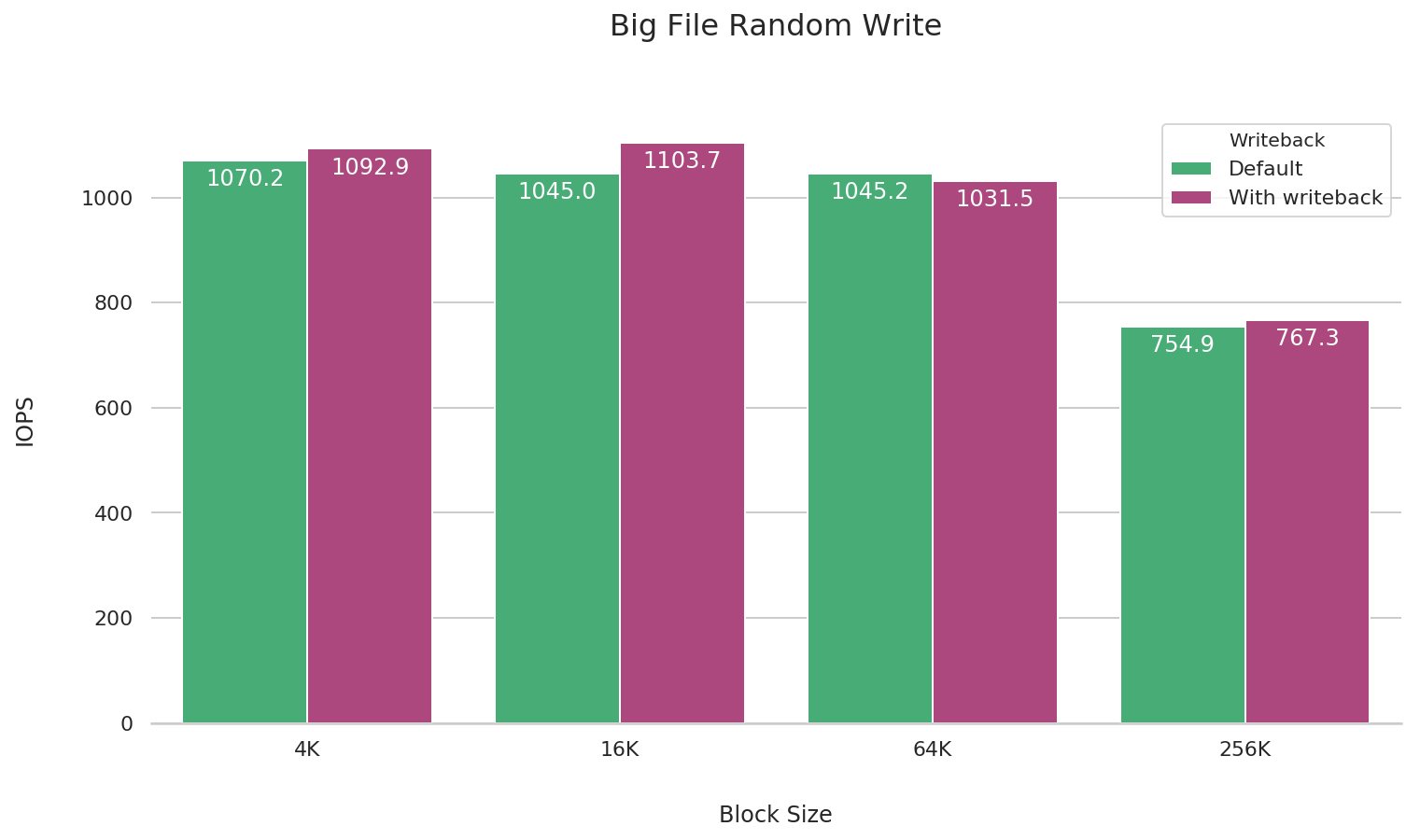
fio --name=big-file-random-write \
--directory=/jfs \
--rw=randwrite --refill_buffers \
--size=4G --bs={4k, 16k, 64k, 256k}
Small files
Small file reads
JuiceFS enables a default local data cache of 1G during mounting, significantly enhancing the IOPS for small file reads. You can disable this cache by using the --cache-size=0 parameter when mounting JuiceFS. The following presents a performance comparison with and without caching.
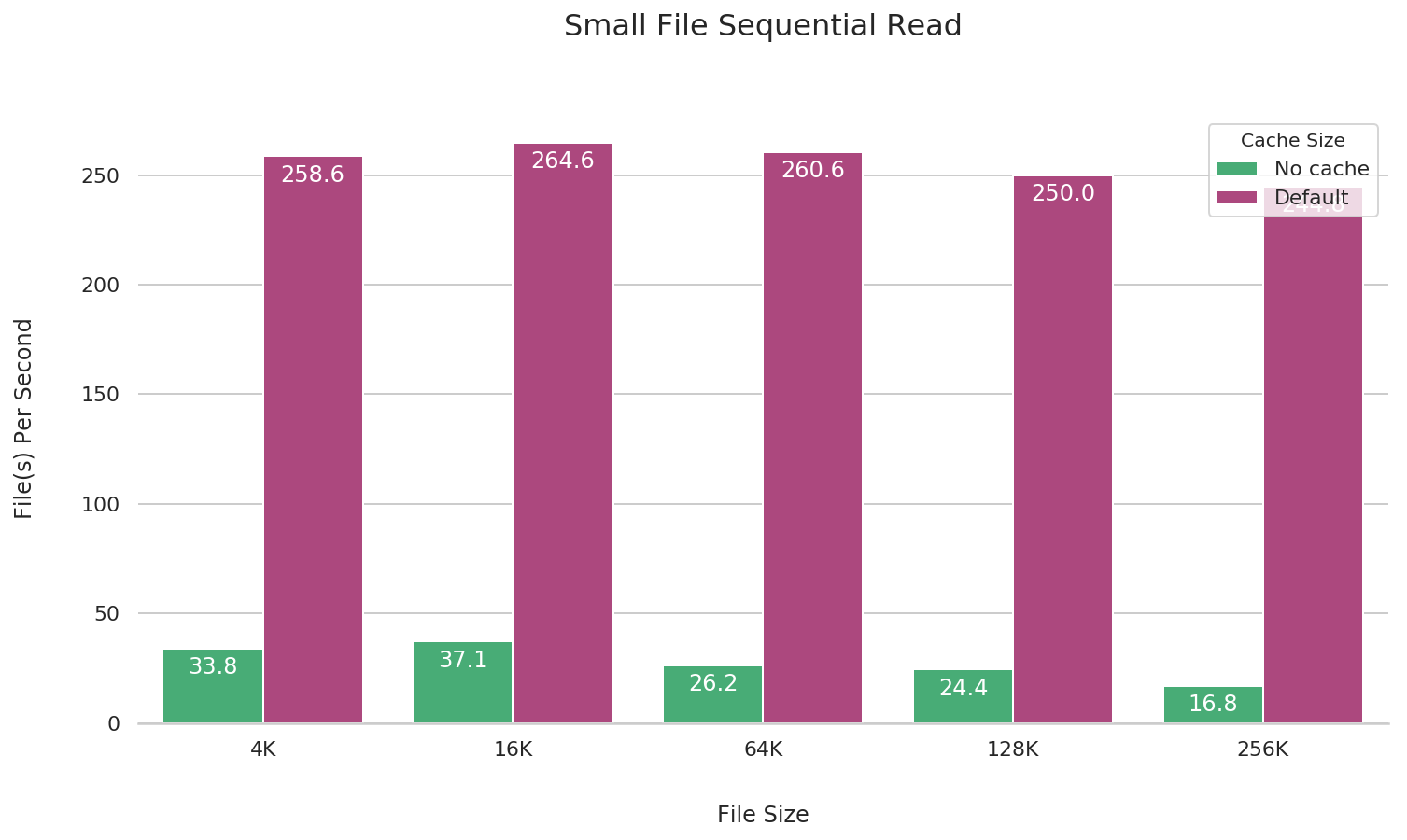
fio --name=small-file-seq-read \
--directory=/jfs \
--rw=read --file_service_type=sequential \
--bs={file_size} --filesize={file_size} --nrfiles=1000
Small file writes
By adding the --writeback parameter during the JuiceFS mount, the client can use write caching. This can significantly improve the performance of small file sequential writes. The following is a comparative test.
In the default behavior of the fio test, file closure operations are executed at the end of the task. This can lead to data loss in distributed file systems due to network issues or other factors. Therefore, the JuiceFS team has employed the --file_service_type=sequential parameter in the fio test settings. This ensures that fio writes the complete data into object storage by executing a flush and close operation for each file before proceeding to the next one.
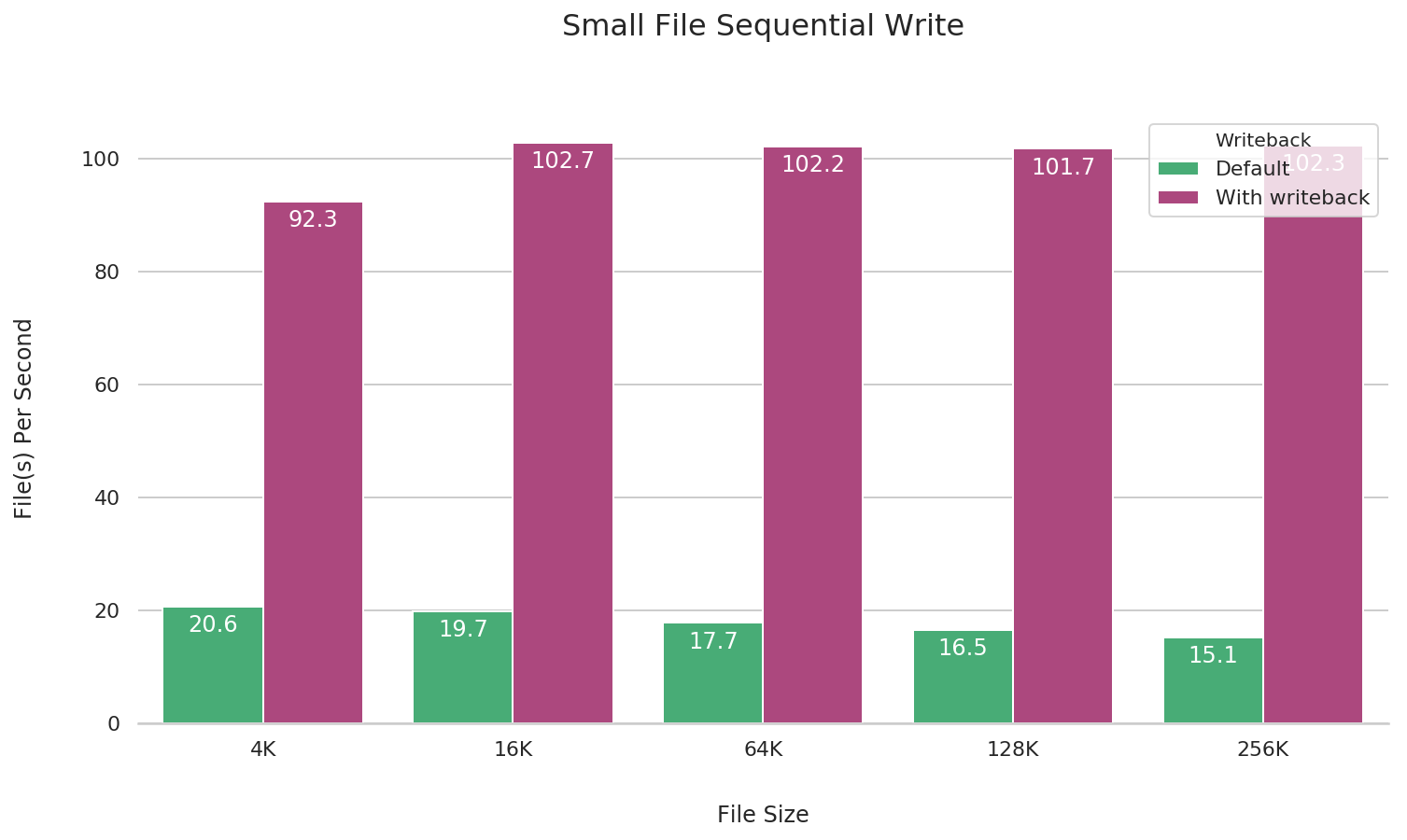
fio --name=small-file-seq-write \
--directory=/jfs \
--rw=write --file_service_type=sequential \
--bs={file_size} --filesize={file_size} --nrfiles=1000
Concurrent reads of small files
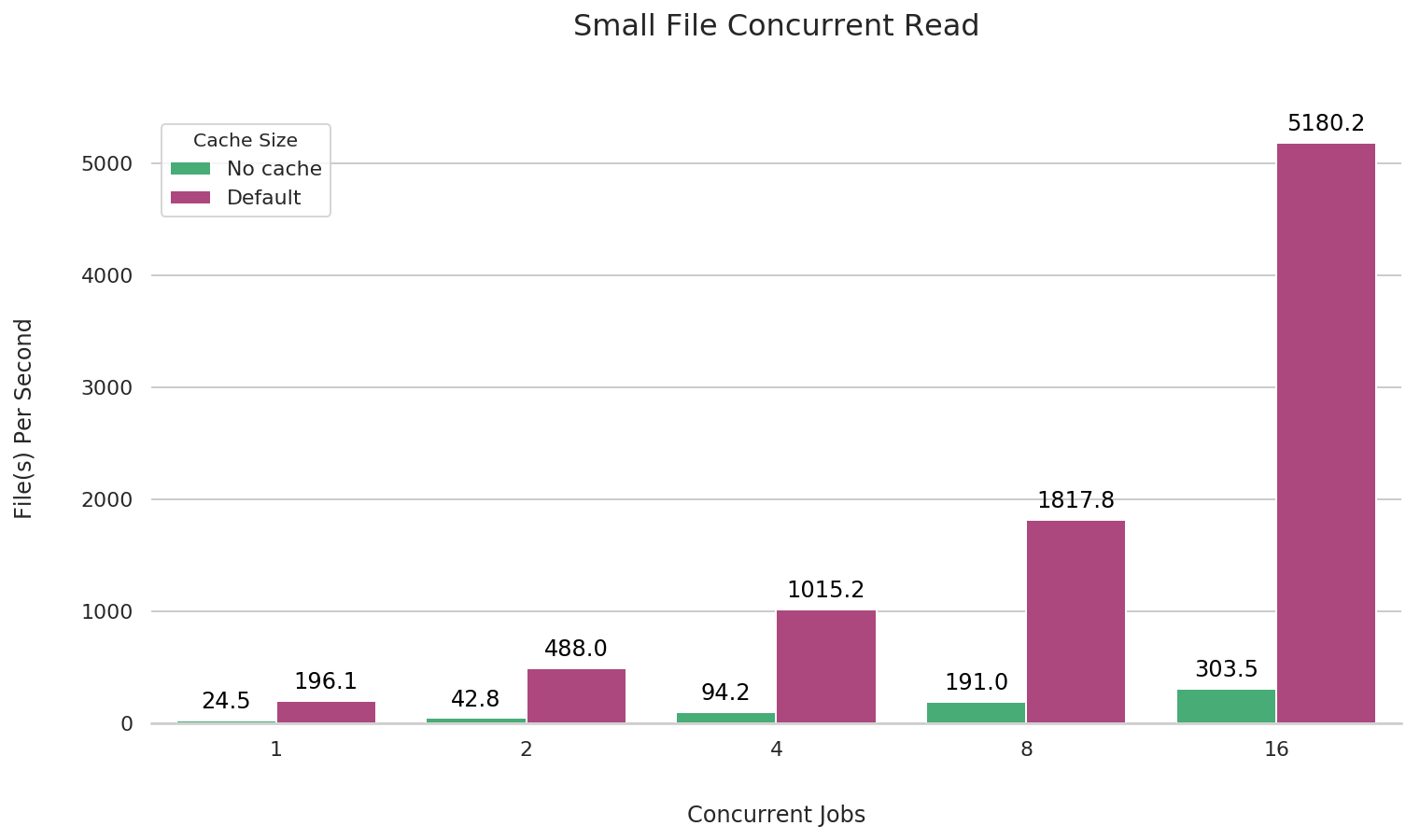
fio --name=small-file-multi-read \
--directory=/jfs \
--rw=read --file_service_type=sequential \
--bs=4k --filesize=4k --nrfiles=1000 \
--numjobs={1, 2, 4, 8, 16}
Concurrent writes of small files
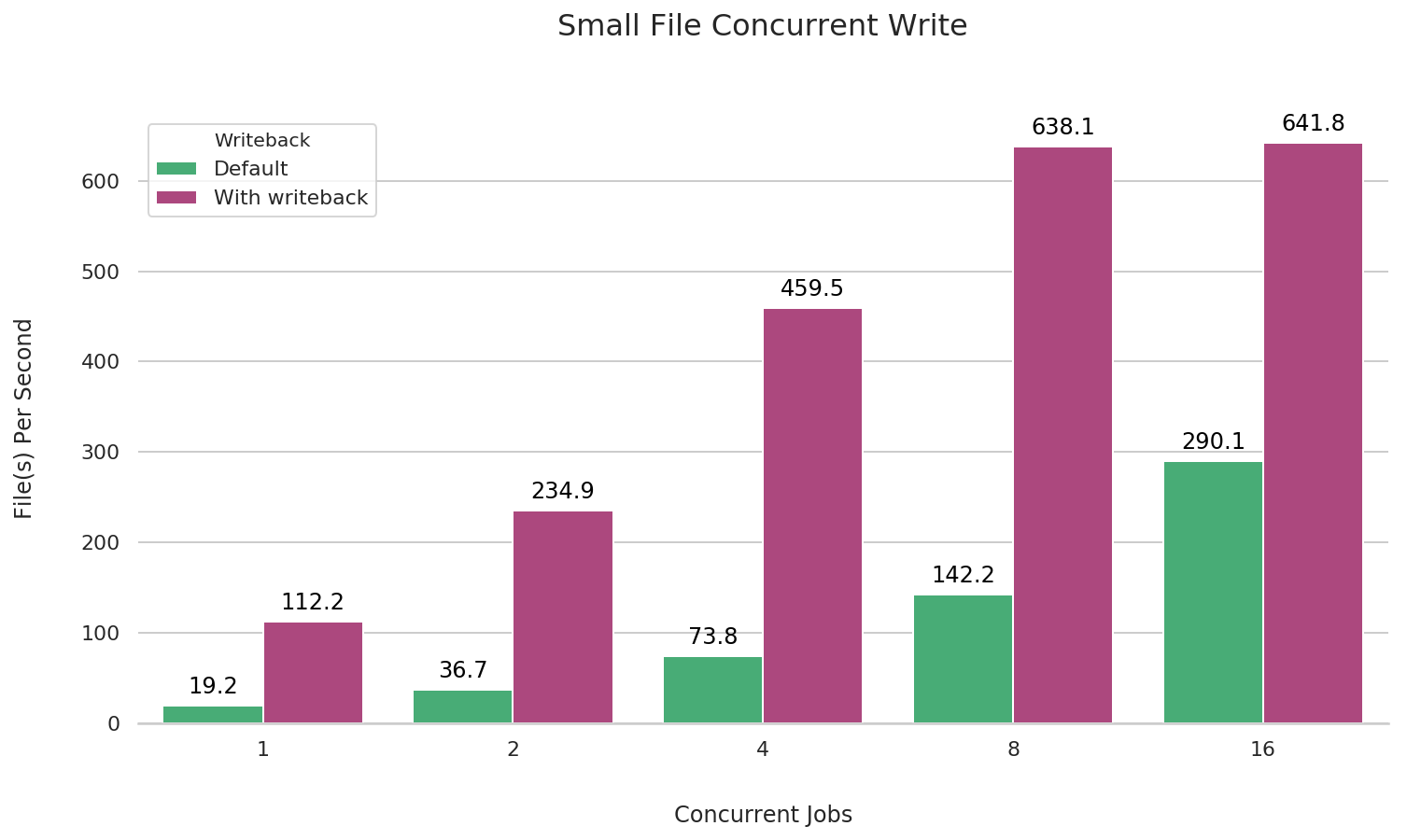
fio --name=small-file-multi-write \
--directory=/jfs \
--rw=write --file_service_type=sequential \
--bs=4k --filesize=4k --nrfiles=1000 \
--numjobs={1, 2, 4, 8, 16}

