















Content
Challenges and pain points
- The tight coupling of traditional Hadoop systems is not designed for the elastic scalability for the cloud
- Deploying HDFS on the cloud disks is about 3 times that of deploying HDFS on bare metal due to the three-copy design of HDFS.
- If deploying HDFS on virtual machines on public clouds, the same O&M challenges in IDC persist in the cloud too and companies can not enjoy the benefits of the cloud.
- The HDFS NameNode that manages a single namespace cannot support massive data well when the amount is over 300 millions files . HDFS Federation addresses this limitation by supporting multiple Namenodes/namespaces to HDFS but it brings the high O&M cost.
- Directly accessing data for big data analytics in the object storage would result in problems like poor performance, lack of strong consistency guarantee, etc., which would greatly impact efficiency, stability, and accuracy.
Why JuiceFS?
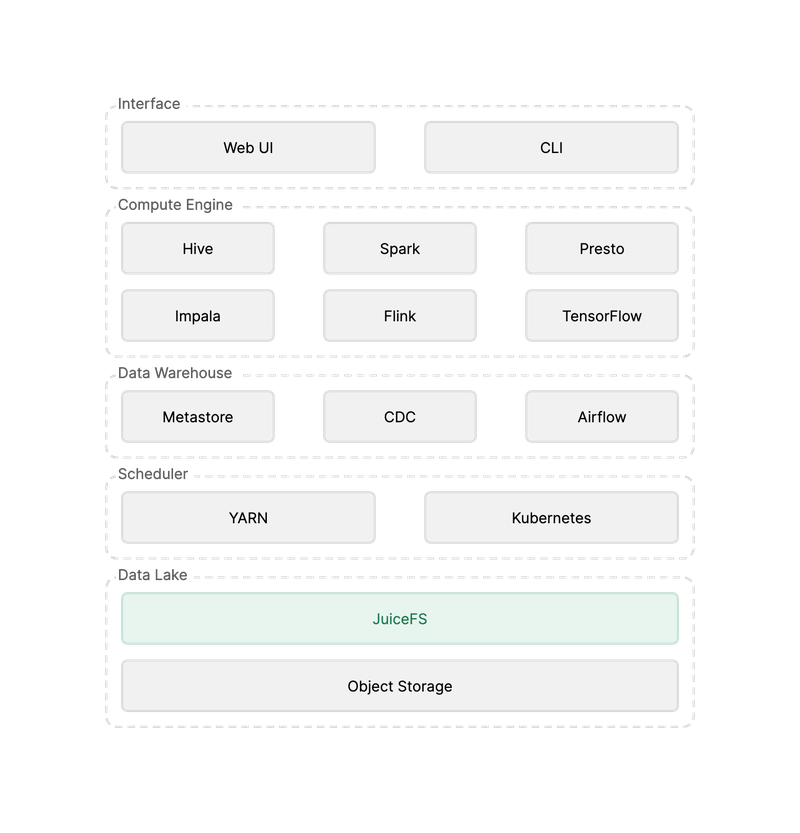
- JuiceFS is fully compatible with HDFS API and all the Hadoop ecological components (Hadoop 2.x or 3.x), and compatible with mainstream Hadoop distributions;
- JuiceFS is based on object storage on the cloud, which can not only achieve elastic scaling of storage space, but also greatly reduce storage costs;
- The JuiceFS single namespace can support tens of billions of files and hundreds of PiB data storage, significantly reducing O&M costs;
- JuiceFS provides strong consistency guarantee, and has better metadata and data read and write performance than object storage;
- JuiceFS is also fully compatible with POSIX and S3 APIs and can easily integrate various types of applications (such as AI) into the big data platform.