















We’re a financial technology company. When we migrated our data platform to the cloud, the first site adopted an architecture similar to our on-premises data center (IDC), constructing a Hadoop-based tech stack on cloud hosts. As our business rapidly developed, this architecture encountered several challenges, including high block storage costs, complexity of Hadoop components, and limited scalability. Additionally, to support different public cloud platforms, we needed to quickly scale our compute resources.
For our storage system, we switched from object storage + EMR to Kubernetes+JuiceFS, an open-source distributed file system. The updated architecture achieved performance comparable to HDFS, while also providing more efficient resource scalability and storage-compute separation. Moreover, the new architecture resulted in about 85% cost savings on storage and a 90% reduction in maintenance efforts.
In this post, we’ll deep dive into the comparison of HDFS and object storage, challenges and solutions in cloud migration for our big data platform, our implementation of K8s+JuiceFS, and our benefits from this architecture.
Big data platform: HDFS vs. object storage
When we discuss storage solutions in big data scenarios, Hadoop is often considered the first choice, and its standard storage component is HDFS. However, with the popularity of object storage, many enterprises have begun to consider implementing big data scenarios on object storage. Therefore, comparing the characteristics and advantages of traditional block storage systems like HDFS with object storage has become a crucial topic in discussions about big data storage solutions.
We’ll first give a quick summary of the comparison results and then dive into the details.
A quick summary of HDFS vs. object storage
Complexity of architecture:
- HDFS: The production environment in HDFS requires configuring multiple components, including NameNode, DataNode, JournalNode, ZooKeeper Failover Controller (ZKFC), and ZooKeeper. This makes the architecture complex and requires maintenance and management efforts.
- Object storage: Object storage, especially the one provided by cloud services, is usually simpler for users. Users don't need to maintain any underlying processes and can focus on storage usage and data management.
Scalability:
- HDFS: The storage capacity of HDFS can be expanded by adding DataNode nodes, which also helps improve the cluster's I/O performance. However, this requires hardware scaling.
- Object storage: Object storage is considered to have theoretically unlimited usage space, easily scalable in the cloud without the need for adding hardware, reducing operational complexity and costs.
Cost:
- HDFS: Block storage is expensive, depending on the disk type.
- Object storage: Object storage cost is lower than block storage cost.
Read/write performance:
- HDFS: Read/write performance depends on cluster configuration, including network bandwidth, storage hardware, and cluster size.
- Object storage: Performance depends on the service provider, concurrent read/write operations, and file size. While it generally provides adequate performance, there may be performance limitations in some cases.
Metadata performance:
- HDFS: Efficient metadata operations with NameNodes, subject to NameNodes’ memory and processing capability.
- Object storage: It may have limitations in handling extensive metadata operations, especially during traversals and statistics on a large number of objects.
Block storage vs. object storage
Let's compare the underlying storage differences between these two solutions: block storage and object storage.
Block storage:
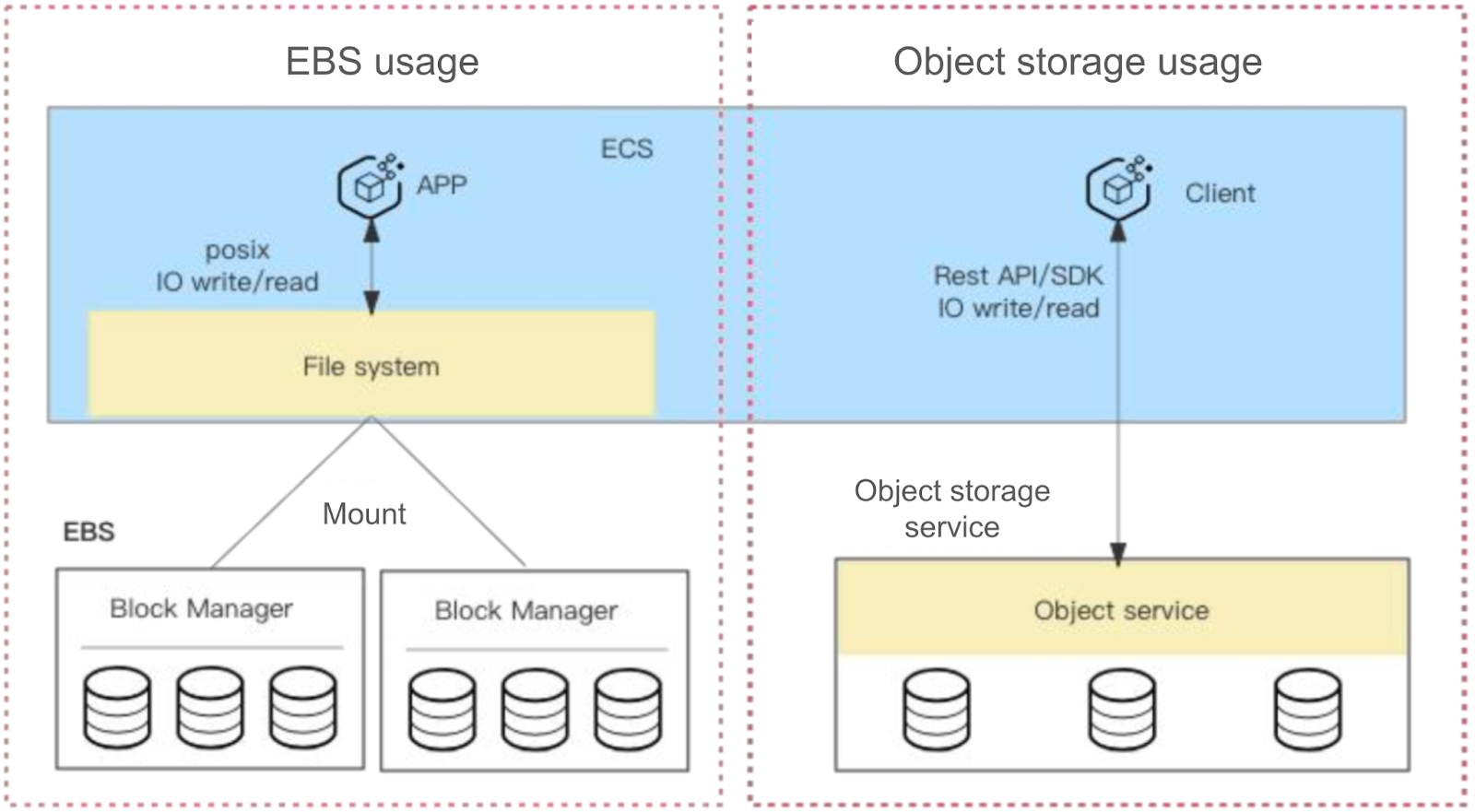
- It’s functionally similar to hard drives in bare metal servers. It typically needs to be formatted into a file system before being mounted on a host.
- Block storage uses the POSIX protocol for data access, supporting efficient random read and write operations. This storage method is particularly suitable for scenarios requiring frequent reads and writes, such as database applications. To enhance the storage efficiency of a single disk, multiple block storage devices can be mounted in the system.
Object storage:
-
It’s an internet-based storage service that adopts a flat file organization. This storage type is accessed through RESTful APIs or SDKs, with a storage structure resembling key-value pairs.
- The key is a uniform resource identifier (URI) used to uniquely identify and locate the stored file.
- The value is the actual file, i.e., the object.
-
The design of object storage makes it suitable for storing large amounts of unstructured data, such as images and video files, and allows efficient access over the network from any location.
The table below compares the cost, performance, and application scenarios of block storage and object storage:
| Comparison basis | Block storage | Object storage |
|---|---|---|
| Cost | $150/TB/month ~ several thousand dollars /TB/month | $20.00/TB/month |
| Performance |
Example: I/O: 140 MB/s to several GBs/s IOPS: 1,800 to hundreds of thousands Response time: 0.2 ms to 3 ms Capacity: 20 GB to 3 2TB |
Example: Internal and external network upload/download bandwidth of 680 MB/s IOPS: 10,000 Response time: a few milliseconds to tens of milliseconds Capacity: unlimited |
| Application scenarios | Suitable for I/O-intensive high-performance, low-latency scenarios such as OLTP databases and NoSQL databases | Mainly used for data storage in internet applications developed based on object APIs, for example, internet application audio/video storage, cloud albums, personal/corporate cloud drives. Widely used in big data storage due to its cost-effectiveness |
Architecture: HDFS vs. object storage
In the big data scenario, the storage architectures of HDFS and Amazon S3 share some similarities but also exhibit notable differences.
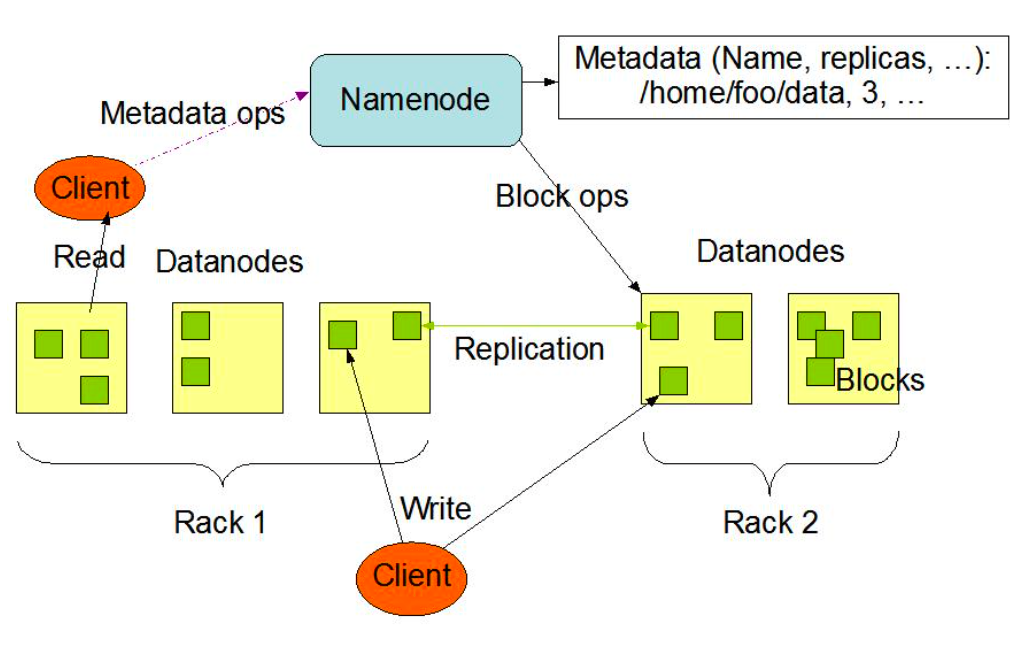
HDFS consists of two processes:
- NameNode: It stores the metadata of the entire file system and manages DataNodes. This metadata includes file attribute information, such as file permissions, modification time, and file size, and the mapping relationship between files and blocks.
- DataNode: It manages the actual data storage and responds to client read and write requests. Additionally, the metadata includes the mapping relationship between file blocks and DataNodes, which is a core part of data storage.
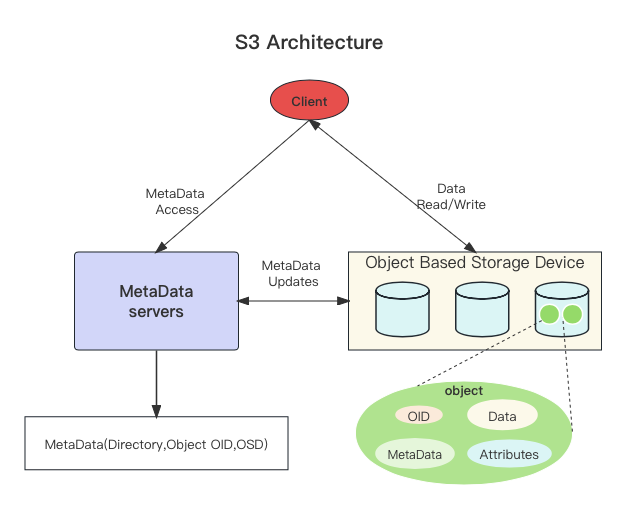
S3 comprises two parts:
- Metadata service manages metadata, including directory, object organization relationships, and the mapping relationship between objects and object storage devices.
- Object storage daemon stores the actual data.
The S3 metadata is simple, including basic file attributes such as modification time, size, and file type.
Performance: HDFS vs. object storage
I/O and cluster performance:
- HDFS performance is influenced by the cluster's network bandwidth, disk types, cluster scale, and the concurrency of client read and write operations. HDFS is renowned for its high throughput, making it less prone to I/O bottlenecks.
- The performance of object storage depends on the specific service provider and technical implementation. Generally, the maximum throughput of object storage ranges from 5 Gb/s to 16 Gb/s, and the maximum IOPS is between 5,000 and 10,000. For data processing with high throughput requirements, object storage may encounter performance bottlenecks.
Metadata operation performance:
- In HDFS, metadata operations involving
ls,du, andcount, which relate to metadata, can be efficiently calculated in the NameNode's memory and typically return results in milliseconds to seconds. - In object storage systems, the metadata service (MDS) usually contains metadata such as directories, objects, and the mapping to object storage devices (OSD). Therefore, calculating the size of a directory containing a large number of objects may require traversing the metadata of each object, which can be time-consuming.
Differences in RENAME operations:
- When HDFS performs a
RENAMEoperation, since it maintains the mapping relationship between files and data blocks, it only needs to modify the mapping relationship in memory. This makes theRENAMEoperation fast and easy in HDFS. - In object storage systems, common operation interfaces include
PUT,GET,COPY,DELETE, andLIST, but there is usually no directRENAMEoperation. To implement aRENAME, you need to translate this into steps of listing the object (LIST), copying it to a new name (COPY), and deleting the old object (DELETE). Especially when large amounts of data are involved, this process can be quite time-consuming.
Challenges & solutions in cloud migration for our big data platform
Originally, the architecture was consistent with our on-premises data center (IDC), constructing a technology stack on cloud hosts that included Hadoop, Hive, Spark, and a self-developed IDE.
This architecture has several advantages:
- It was mature and stable, effectively supporting application operations.
- It provided benchmark performance similar to the local IDC, ensuring operational efficiency.
- Due to the compatibility of Hadoop and Spark versions, this approach maintained consistency when integrating with IDC or user-side applications. This reduced the need for debugging and testing and accelerating application deployment.
Challenges in cloud migration
As the data volume grew, this approach faced some challenges:
- The block storage cost at the site continued to rise, adding pressure on our budget.
- Due to the lack of elastic computing resources in the self-built platform, scaling storage resources needed manual operations, increasing management complexity.
- The environment with multiple components resulted in high operational costs.
Therefore, to adapt to the growing application needs and optimize costs, we needed to redesign the architecture of the data service center.
Initial architecture: object storage + EMR
To tackle the challenges posed by the growth in data volume and business expansion, we implemented a series of methods to optimize the architecture of our data center:
- Introduction of object storage to address the elasticity issues in data storage, mainly focusing on storing low-frequency accessed data. For response-time (RT) sensitive tasks, we didn’t process them on object storage. We interfaced with various cloud service providers, including S3, OSS, OBS, and GPS.
- Adoption of Amazon Elastic MapReduce (EMR) to enhance cluster elasticity and adapt to diverse resource usage requirements due to business fluctuations. This approach aimed to achieve the separation of storage and computation, making resource configuration more elastic. EMR provides elastic configuration, allowing scheduled scaling based on needs or dynamic adjustment of computing nodes based on cluster resource usage.
- Establishment of an additional EMR adaptation layer beneath the data development IDE to ensure compatibility with EMR and object storage services from different cloud providers.
Advantages of this solution included:
- Reduction in storage costs.
- Separation of storage and computation, enabling elastic resource configuration.
- Multi-cloud compatibility.
However, it had some disadvantages:
- EMRFS had low performance, failing to address the lack of metadata in object storage.
- High adaptation costs. Despite claims of compatibility with open-source versions by some cloud services, official SDKs were still required to address specific issues and avoid potential conflicts.
- High operational costs. Although it was a cloud service, all processes still required handling by our company.
- Limited elastic capabilities, with potentially longer response times, especially in scenarios with custom environment variables.
Evolved architecture: K8s+JuiceFS
Building upon the previous advancements, we proceeded with the next round of optimization. In the storage layer, we selected JuiceFS as the solution. JuiceFS employs a data-metadata separated storage architecture, fully compatible with HDFS interfaces and comparable to HDFS in metadata operation performance. This improvement not only optimized storage efficiency but also enhanced the scalability and performance of the storage system.
On the computation layer, we adopted the Spark solution running on Kubernetes. This change allowed us to completely eliminate dependencies on Hadoop, significantly reducing deployment, adaptation, and operational efforts. The services based on Kubernetes are fully managed, with deployment and operational tasks handled by the cloud service provider, providing higher operational convenience and lower operational costs. Additionally, Kubernetes-based services offer minute-level elastic scalability, with costs only involving Elastic Compute Service (ECS) instances, further reducing operational expenses.
JuiceFS’ advantages
The advantages of JuiceFS for our architecture: - Performance comparable to HDFS, effectively addressing metadata performance issues in object storage. - Open source with low maintenance costs. JuiceFS itself has no server components (serverless), significantly reducing maintenance costs. - Low additional costs. JuiceFS requires additional costs only for the metadata engine, which can often be realized through managed services purchased from cloud providers, resulting in low costs. - Extensive compatibility with object storage. JuiceFS supports integration with nearly all major object storage services, providing convenience when adapting to EMR without requiring additional adaptation efforts.
Advantages of Spark on K8s
The advantages of Spark on Kubernetes include:
- Fully managed Kubernetes service, with Spark running on fully managed Kubernetes, meaning no deployment and operational costs, significantly reducing management complexity and costs.
- Resource elasticity and flexibility. Kubernetes provides flexible and rapid resource elasticity capabilities, dynamically scaling out and in resources based on actual needs.
- No adaptation costs. Custom management images enable Spark on Kubernetes to be universally applicable across the network, without the need for special adaptations to different environments, further reducing costs.
How we implemented K8s+JuiceFS
JuiceFS on Redis
When opting for JuiceFS on Redis for storage, we chose Redis hosted by cloud providers for high-performance and stable services. To ensure data availability, we implement appendfsync operations on each stored data.
Spark Operator
For deploying Spark on Kubernetes, we chose the open-source Spark Operator from Google, instead of Kubernetes spark-submit. Spark Operator is better suited for the Kubernetes environment, providing greater flexibility, especially in secondary development and customization through APIs. In comparison, spark-submit is restricted in some aspects by Spark's built-in encapsulation and usually requires exposing Spark UI through ingress.
Benefits of K8s+JuiceFS
Our data scale and resource configuration:
- The data scale is approximately 100 GB, with the main job logic involving data aggregation and group sorting. Regarding resource configuration, dynamic allocation ranged from 1 to 12 executors, with each executor configured with 1 - CPU core and 4 GB of memory.
- Read and write operations were performed on the same type of storage.
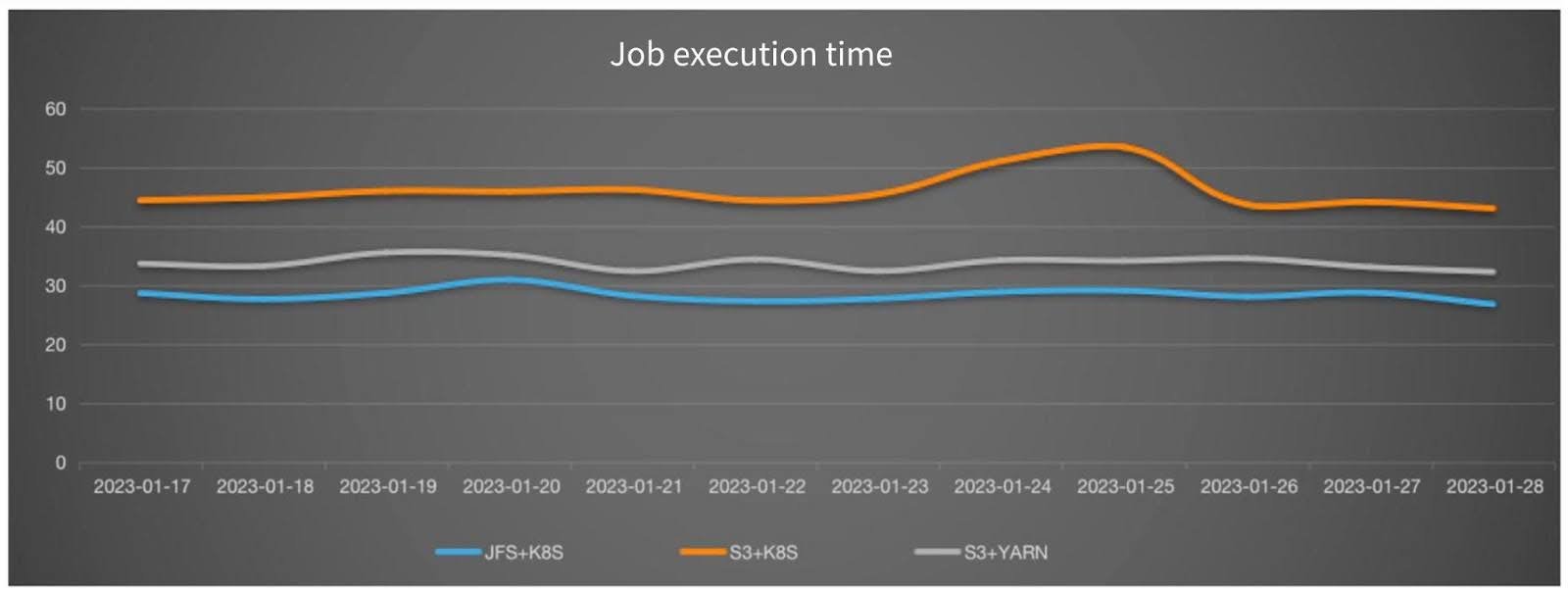
Performance analysis:
- Using Spark on Kubernetes resulted in a performance decrease of about 24% compared to running on YARN.
- JuiceFS provided a performance improvement of approximately 60% compared to S3.
- Despite the lower performance of Spark on Kubernetes, when combined with JuiceFS, the overall job efficiency remained higher than S3+YARN.
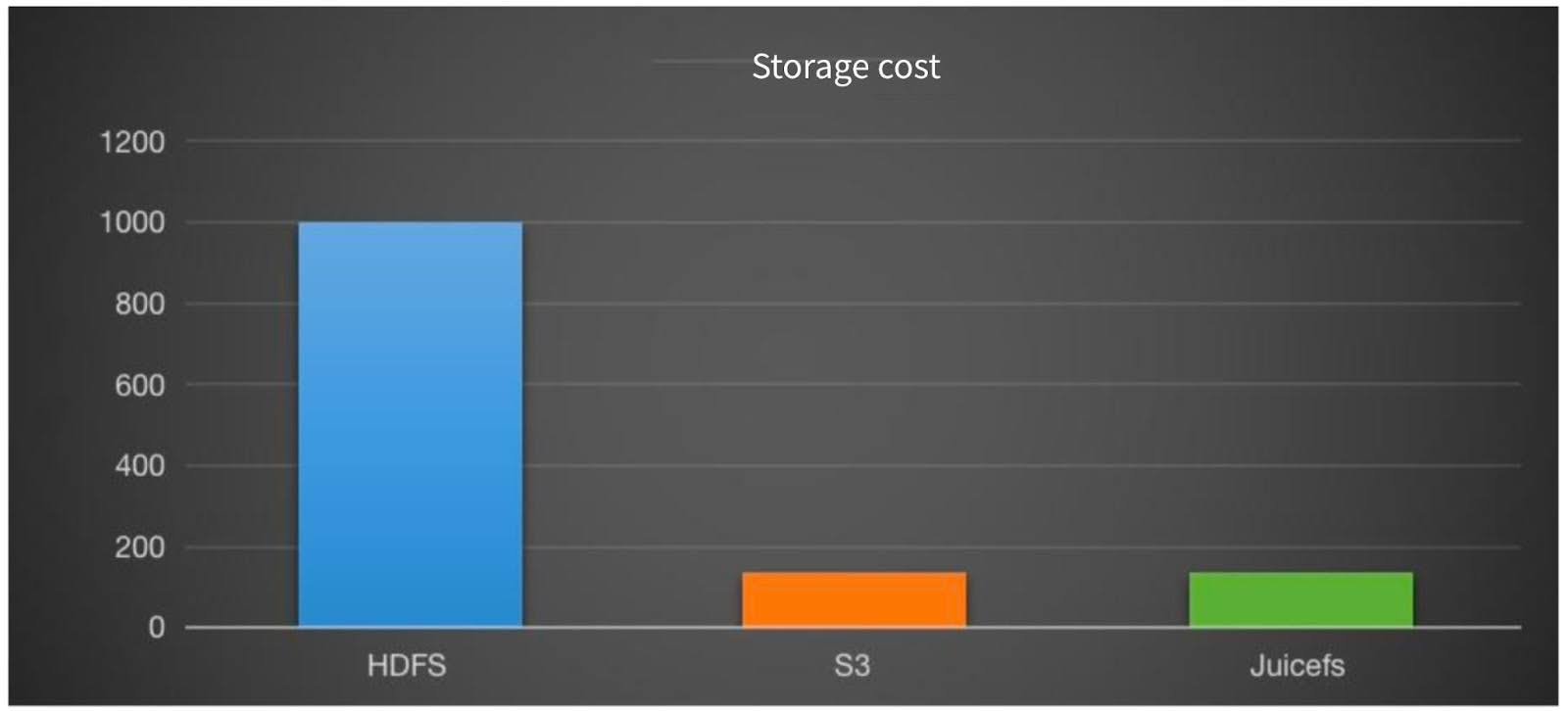
Storage cost analysis:
- JuiceFS saved approximately 85% of costs compared to HDFS (2 replicas, 70% capacity buffer, HDD disk).
- Compared to S3, JuiceFS costs slightly increased, mainly due to metadata storage costs, with an increase of only about 3%.
Compute resource costs and efficiency:
- The average resource allocation rate of the cluster during off-peak periods was approximately 50%, with an average utilization rate of about 65%.
- As jobs could elastically scale, the time required for resource allocation during peak periods reduced from 4 hours to 1 hour, significantly improving the response capability to job resource demands.
Operational costs:
| Operational aspect | Self-built Hadoop | EMR + object storage | K8s+JuiceFS |
|---|---|---|---|
| Storage engine | HDFS processes (nn, dn, zk, zkfc, jn) scaling | HDFS processes (nn, dn, zk, zkfc, jn) S3 (managed service) | S3/Redis (managed service) |
| Compute engine | YARN processes (rm, nm) scaling | YARN processes (rm, nm) auto-scaling | K8s (managed service) Spark Operator pod |
| Hive metadata | HMS | HMS | HMS |
| Self-built IDE | Universal across network | Cloud-specific adaptations | Universal across network |
If you have any questions or would like to learn more, feel free to join JuiceFS discussions on GitHub and their community on Slack.