















Kubernetes (K8s) has become the de facto standard for application orchestration, with more applications continuously shifting toward cloud-native architectures. Concurrently, the rapid advancement of artificial intelligence (AI), particularly large language models (LLMs), has led to a significant increase in data that enterprises need to handle. For example, the Llama 3.1 model boasts 405 billion parameters, resulting in a model file size of 231 GB. As model parameters grow, so do the sizes of model files.
In this post, we’ll deep dive into the storage challenges involved in training LLMs within Kubernetes environments and explore how JuiceFS, a cloud-native high-performance distributed file system, effectively addresses these issues.
From complex permission management and system stability to data consistency across multi-cloud architectures, we’ll look at how JuiceFS optimizes large-scale AI workloads with its unique architecture. Key features like metadata and data separation, distributed caching, sidecar deployment for serverless environments, and full POSIX compatibility make JuiceFS a powerful tool for enterprises managing vast datasets on Kubernetes clusters with thousands of nodes.
Storage challenges in LLM training with Kubernetes
As the scale of data clusters continues to expand, managing large-scale data in Kubernetes poses multiple challenges:
- Complex permission management: Large-scale AI training often involves hundreds of algorithm engineers. This creates complex requirements for file system permission management. In a Kubernetes environment, this fine-grained control over dynamic and distributed resources becomes particularly challenging while ensuring efficiency for development and operations.
- Stability challenges: The extreme elasticity of cloud-native environments puts significant pressure on file system stability. Engineers want to ensure that restarting or upgrading file system services does not disrupt application operations.
- System observability: In complex Kubernetes systems, enhancing observability and simplifying operations and troubleshooting is challenging. In addition, storage systems must meet performance requirements for high concurrency, throughput, low latency, and maintain data consistency in multi-cloud architectures.
How JuiceFS’ architecture addresses these challenges
JuiceFS separates metadata and data storage. Metadata is stored in databases like Redis, PostgreSQL, and proprietary high-performance cloud data engines, while data is chunked and stored in object storage, compatible with nearly all object storage types. This chunking method allows I/O requests to be accurately sent to specific blocks, making it ideal for reading and writing large files while ensuring data consistency.
As shown in the figure below, the JuiceFS client is at the system's top layer, handling all file I/O requests and providing various access methods for upper-layer applications, including POSIX interfaces, JuiceFS CSI Driver, and S3 Gateway.
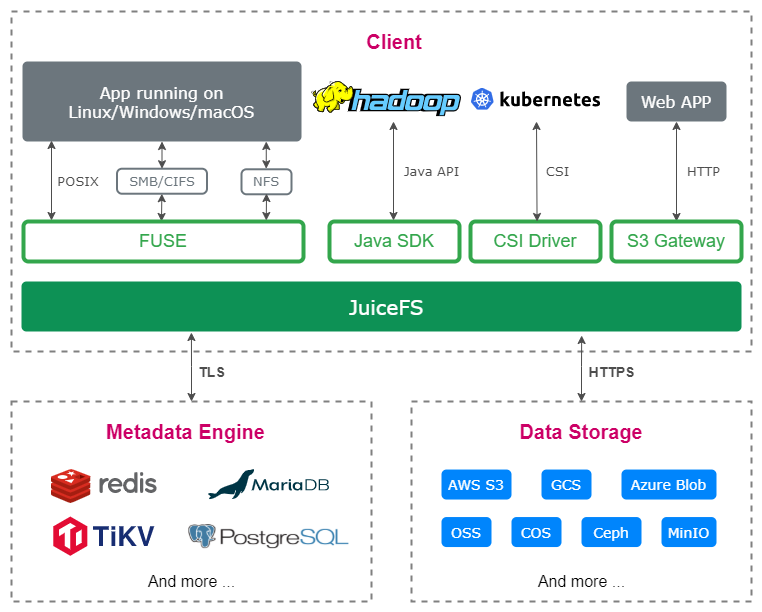
JuiceFS in Kubernetes
JuiceFS offers a CSI Driver that allows users to utilize the file system in Kubernetes environments through native PersistentVolumeClaim (PVC) methods. This supports both static and dynamic configurations.
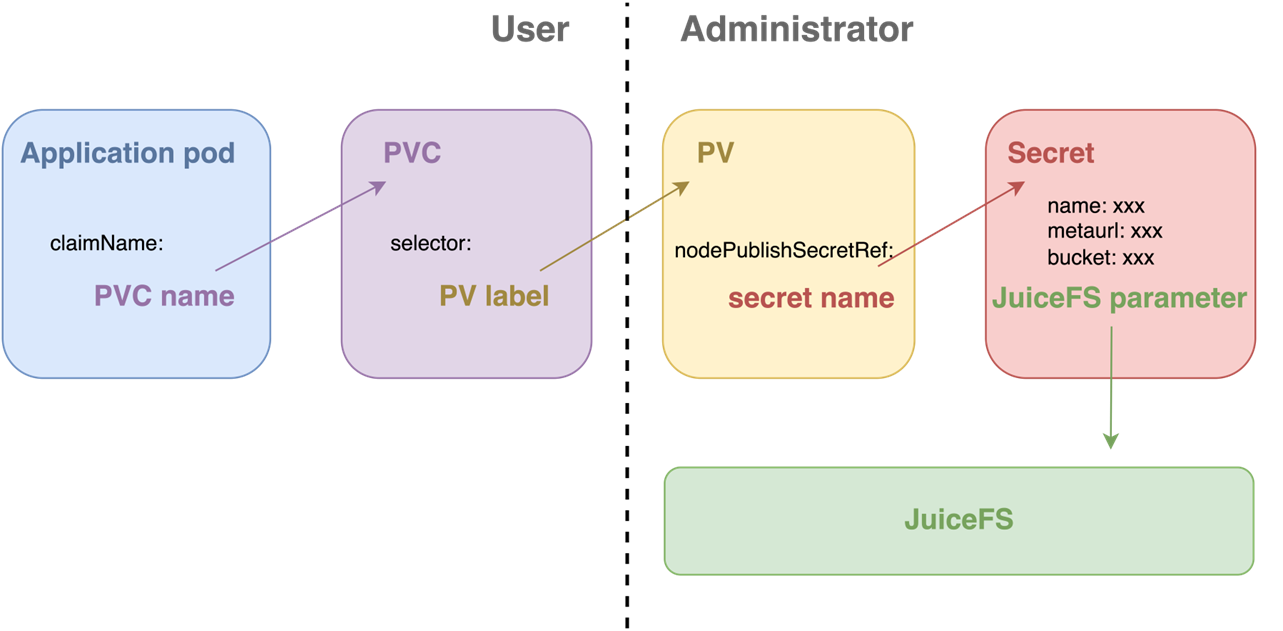
In static configuration, administrators create a separate PersistentVolume (PV) for application Pods. Users only need to create a PVC and declare it in their Pods to use JuiceFS.
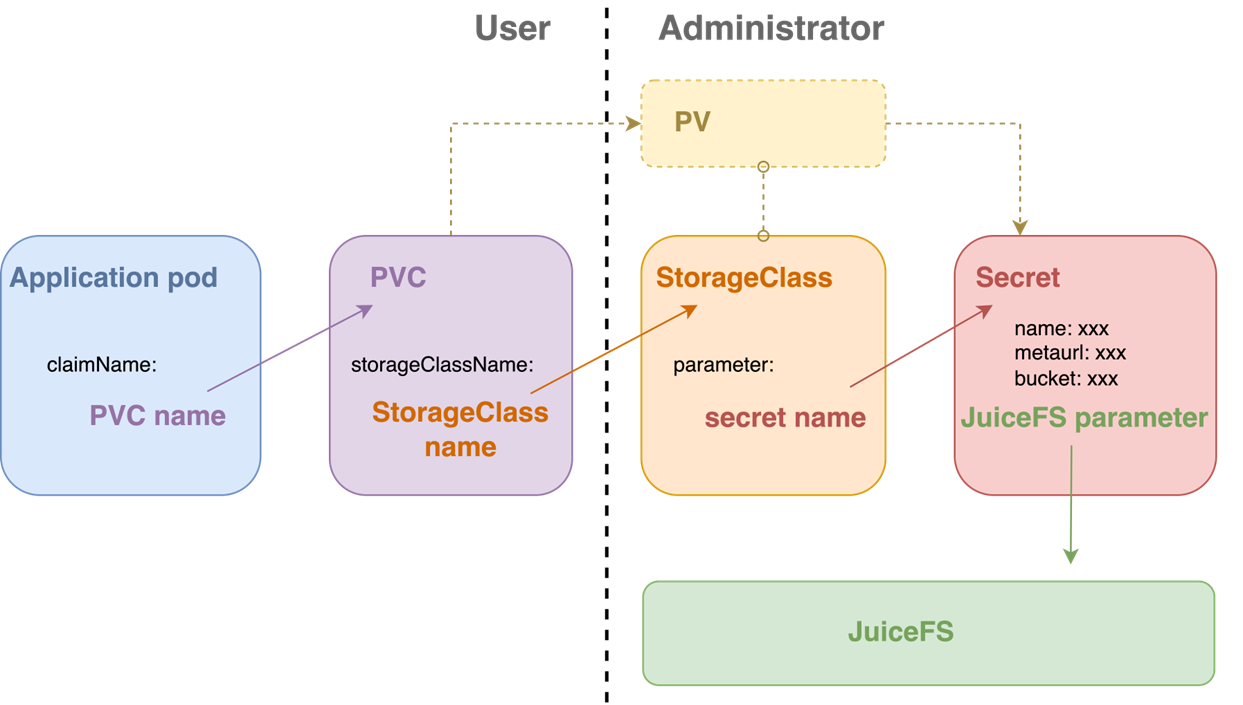
Dynamic configuration simplifies the administrator's workload. Instead of creating individual PVs for each Pod, administrators create a template PV known as a StorageClass. Users still need to create a PVC, and the system will automatically generate the required PV based on the StorageClass. During operation, the system automatically creates the corresponding PV.
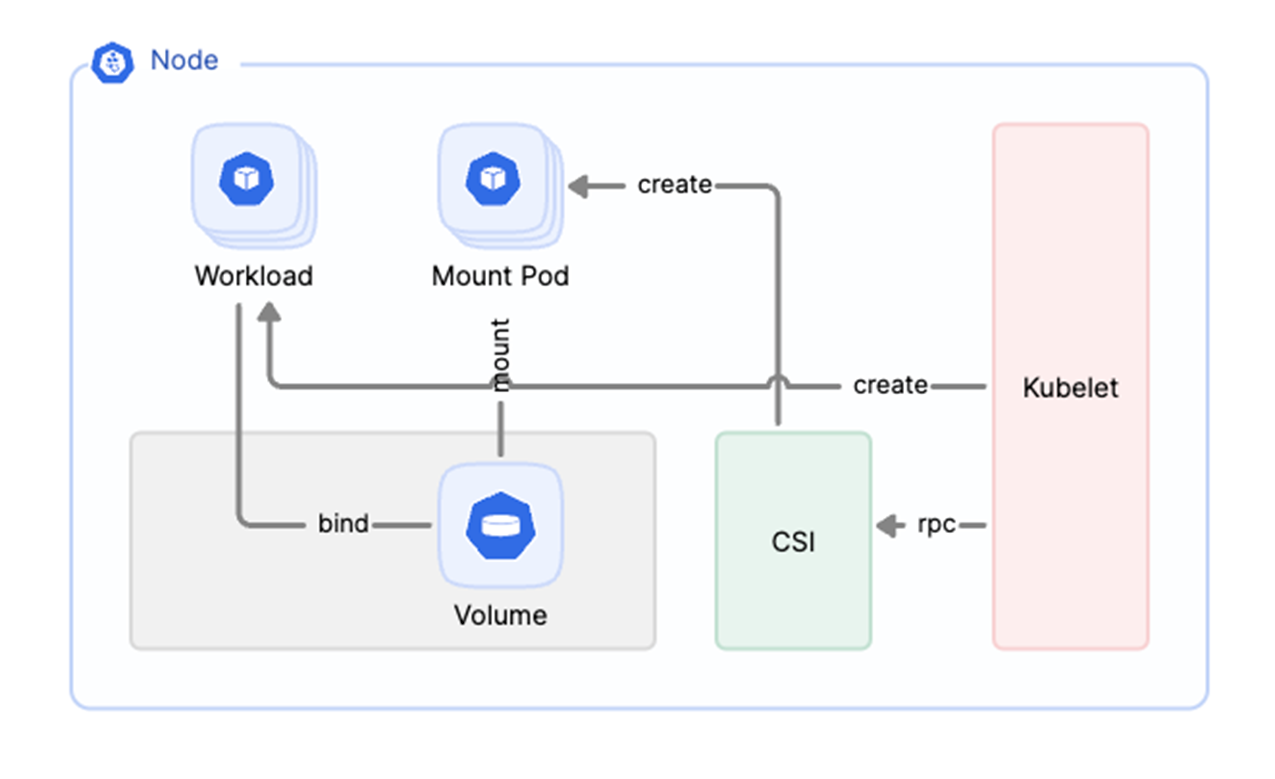
The following diagram shows the workflow after JuiceFS CSI Driver receives a mounting request from Kubernetes. The system creates a separate Pod to run the JuiceFS client. This design brings several notable benefits:
- Increased stability and scalability: The FUSE client is completely decoupled from JuiceFS CSI Driver component. This means that the restart and upgrade of the CSI Driver will not affect the operation of the FUSE client.
- Ease of management: This architecture allows for intuitive management of the FUSE daemon using Kubernetes, enhancing transparency and management efficiency.
Running JuiceFS CSI Driver in serverless environments
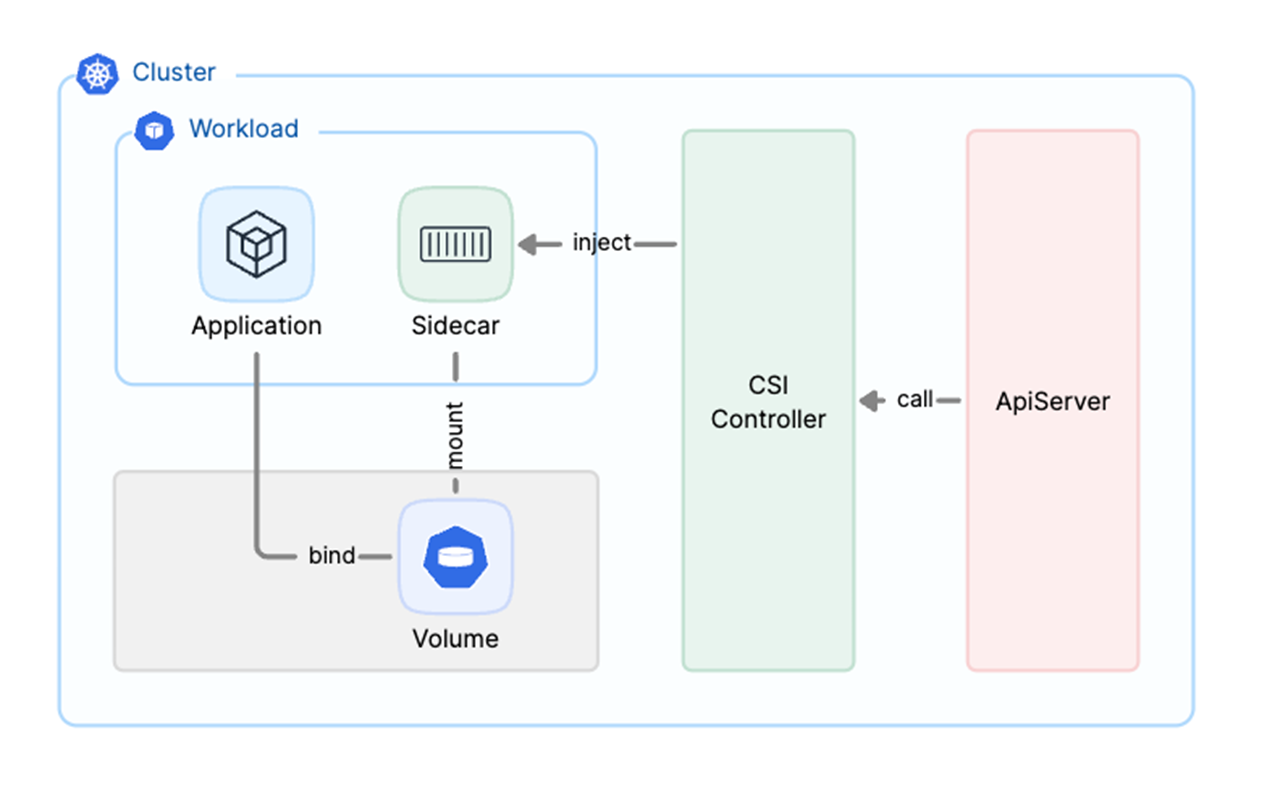
In serverless environments, services typically do not associate with specific nodes. This makes it impossible to run daemons (DaemonSet) on nodes, which can hinder the normal operation of the CSI node component. To address this, we implemented an innovative solution using the sidecar mode to support JuiceFS' operation in a serverless elastic environment. This ensures high availability and flexibility of the storage client.
In this operation, we registered a webhook with the CSI controller to the API server. When the API server needs to create a Pod, it sends a request to this webhook. Through this mechanism, we inject a sidecar container into the application Pod and run the JuiceFS client within it. This configuration allows the JuiceFS client to coexist with the application container in the same Pod, sharing the same lifecycle, which enhances overall operational efficiency and stability. Check out more details about sidecar mode.
Ensuring data security in multi-tenant environments
Ensuring data security in multi-tenant environments presents a significant challenge. JuiceFS employs various security mechanisms to address this challenge:
- Data isolation: JuiceFS achieves data isolation between different application entities by allocating separate storage directories for dynamically declared PVCs in StorageClass.
- Data encryption: By enabling static data encryption at the file system startup, users can set the key password and key file in a Secret, thus activating JuiceFS' data encryption feature.
- Permission control: Users can manage file permissions using Unix-like UID and GID, which can be set directly in the Pod. In addition, JuiceFS supports POSIX ACLs for more granular permission control.
Virtually unlimited storage capacity
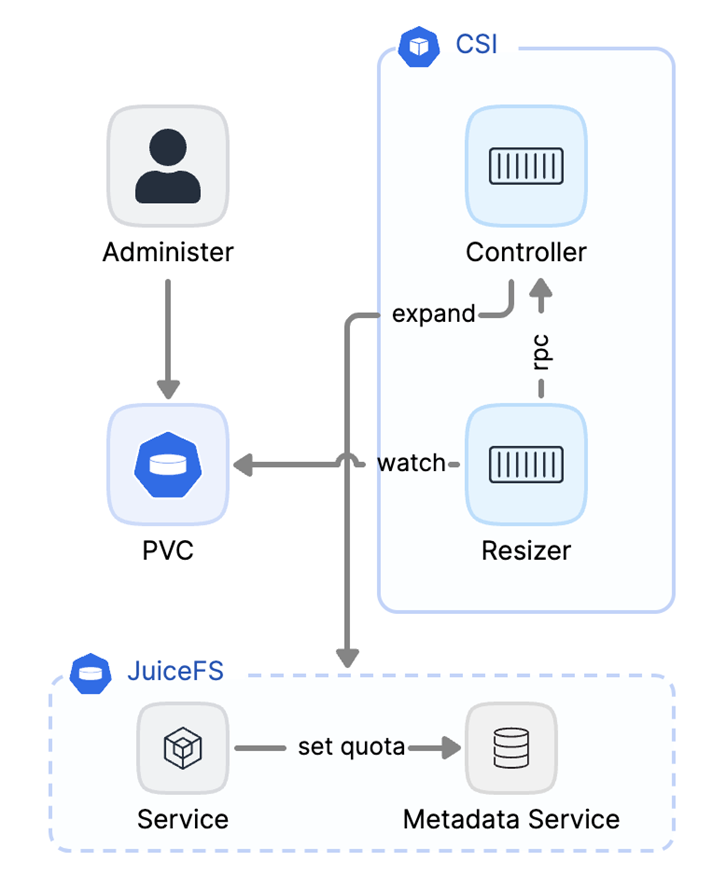
JuiceFS is built on object storage. This means it has no storage capacity limits. We’ve implemented a logical data management system on top of object storage.
Users can set quotas for JuiceFS in PVC by specifying the attributes of StorageClass. This process is similar to setting a capacity quota for JuiceFS. When data expansion is needed, the operation is easy. Users simply modify the storage capacity value in the PVC using the kubectl command.
How to achieve high performance
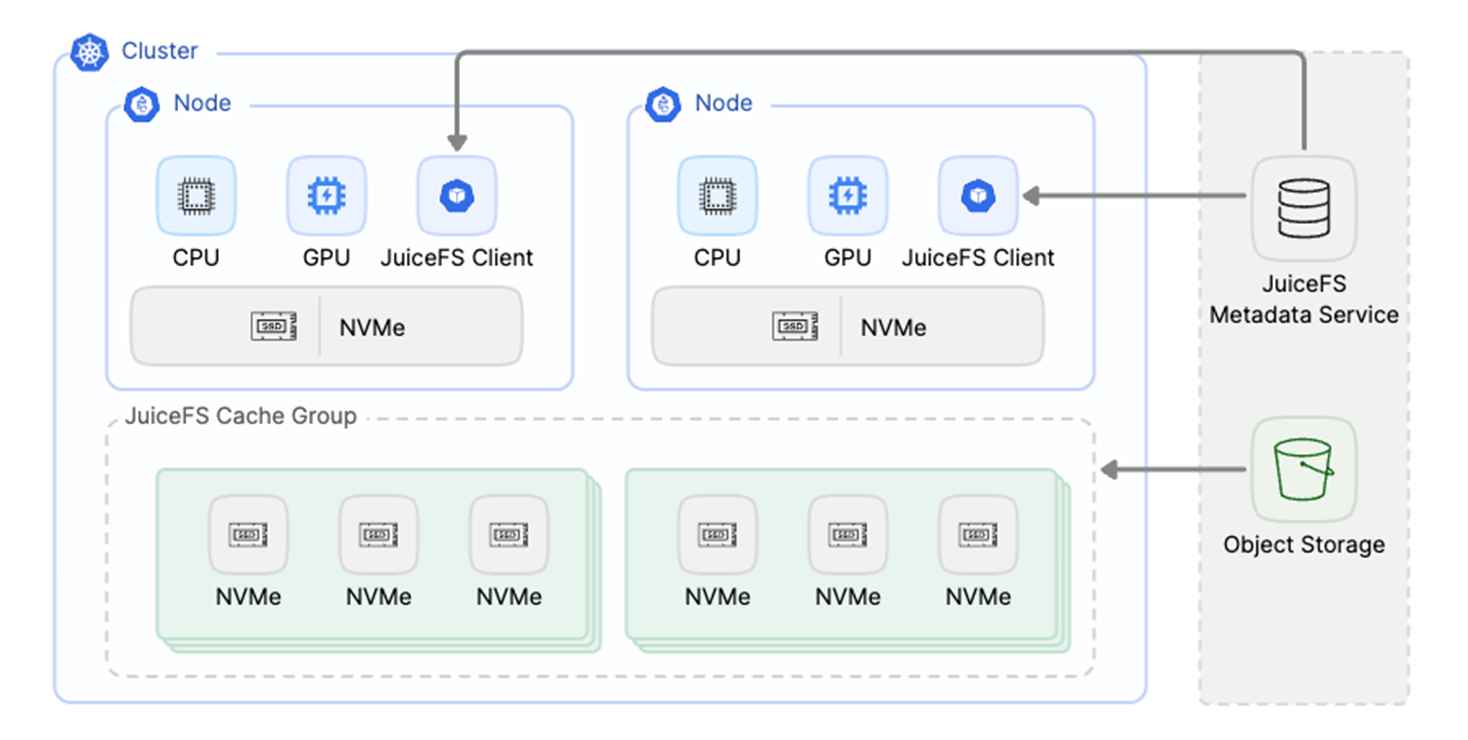
When numerous clients frequently access the same dataset, distributed caching allows multiple clients to share the same cached data, significantly enhancing performance. This mechanism is particularly suitable for scenarios involving GPU clusters for deep learning model training.
The following figure shows a typical deployment of a distributed cache cluster. In GPU compute nodes, the JuiceFS client runs and utilizes local NVMe storage as local cache. The distributed file cache cluster is typically deployed close to the GPU nodes and pre-fetches data from remote object storage.
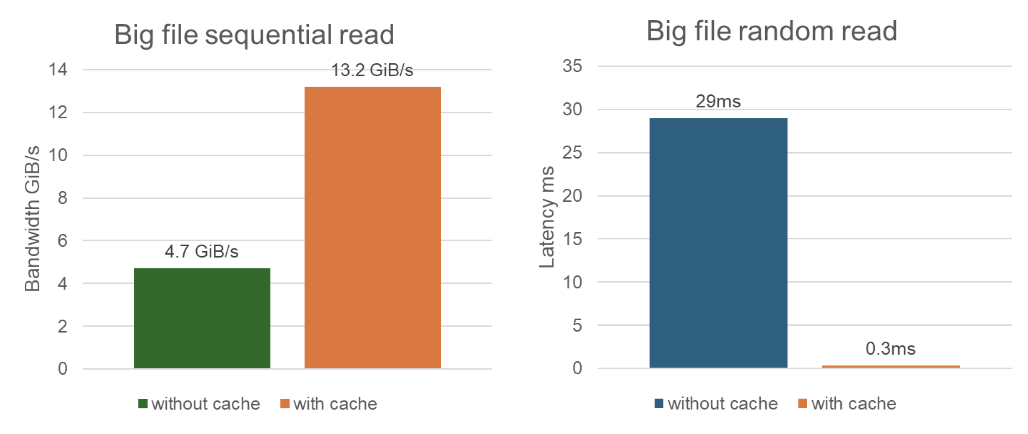
Here’s a performance test focusing on large file sequential and random reads, demonstrating the effectiveness of distributed caching. As shown, in sequential read tests for large files, bandwidth increased from 4.7 GB without caching to 13.2 GB with caching. In random read tests, latency reduced dramatically from 29 milliseconds to 0.3 milliseconds with caching enabled. This showcases a significant performance improvement.
Maintaining data consistency in multi-cloud environments
As model parameters and dataset sizes continue to grow, public cloud GPU resources are increasingly preferred for their abundance and flexibility. To reduce costs and meet multi-cloud architecture needs, many companies are distributing GPU resources across different cloud platforms.
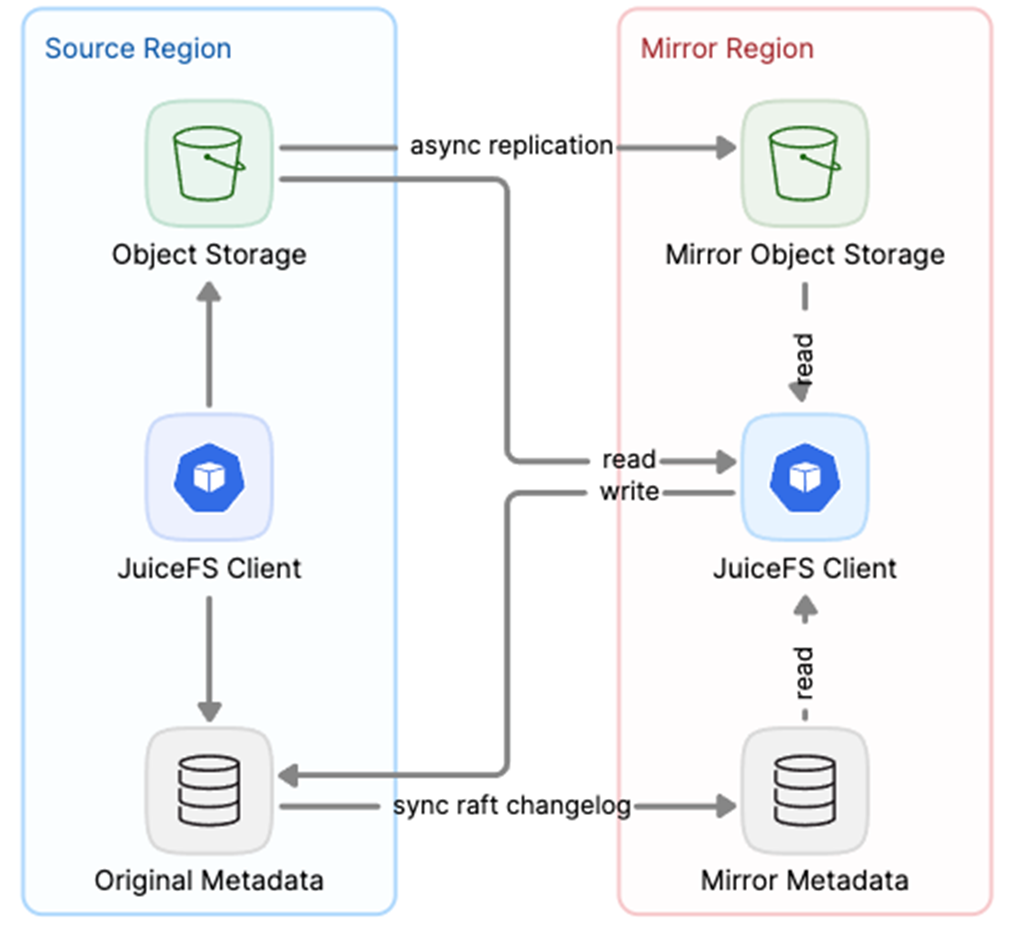
We introduced a mirror file system feature that enables users to access JuiceFS data across different cloud platforms while maintaining data consistency. This system synchronizes data asynchronously from the original file system to object storage.
Moreover, we enhance data consistency through a metadata engine that periodically synchronizes the Raft changelog. In the mirror file system, clients can initiate write requests to the original file system, while read requests can be made from either the original or the mirror file system. This ensures data consistency across multi-cloud architectures.
Practice and optimization for clusters with thousands of nodes
In a cluster with thousands of nodes, managing numerous nodes and associated resources presents a significant challenge. As the demand for these resources grows, the API server faces immense pressure.
Optimization 1: Visual monitoring
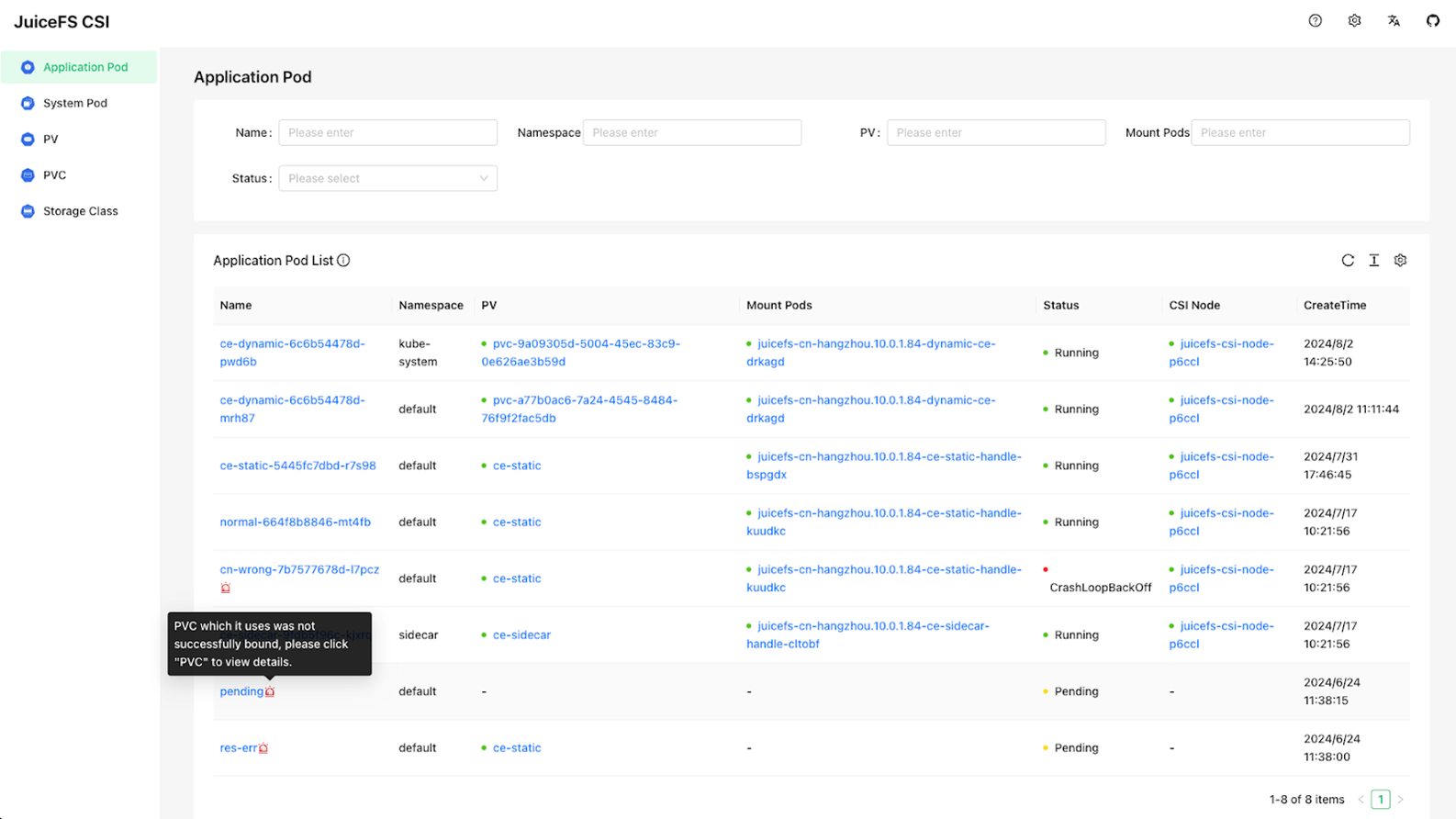
When resources in a cluster become numerous, troubleshooting failures can become cumbersome. To address this, we provide a visual dashboard that lists all application Pods using JuiceFS PVCs and displays the corresponding mount Pods and their operational status.
If an application Pod encounters an issue, the dashboard offers tips for potential causes, simplifying the troubleshooting process for users. Check out this blog post to learn more details about this feature.
Optimization 2: Resources and performance
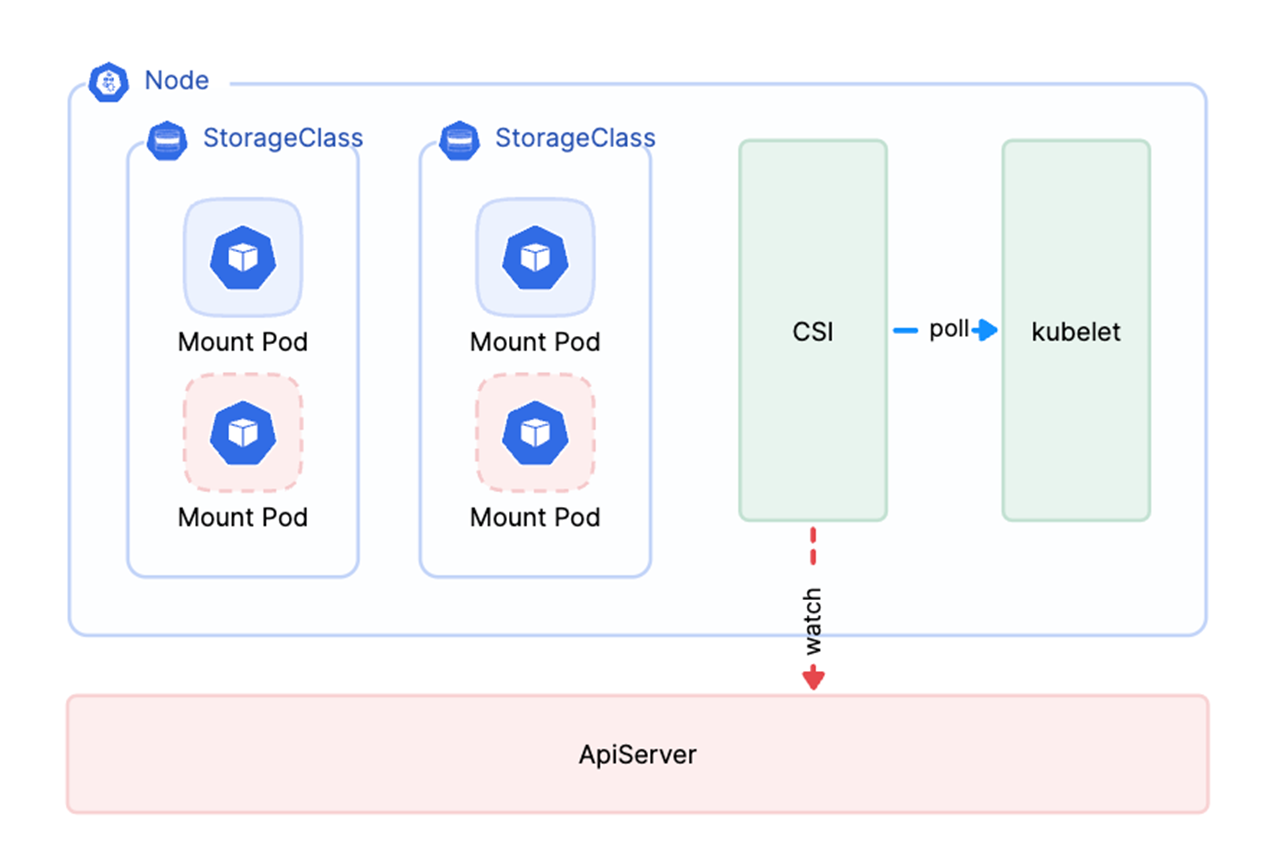
Creating separate mount points for each application Pod is impractical and resource-wasting. Thus, all application Pods using the same PVC will share a single mount Pod by default. In certain configurations, all application Pods using the same StorageClass will also share a mount Pod to further optimize resource usage.
CSI manages the lifecycle of mount Pods using a list-watch approach. In large-scale clusters, a full list request during the CSI component's startup can put immense pressure on the API server, potentially leading to crashes. To mitigate this, each node's CSI component polls its corresponding node's kubelet, thereby reducing the pressure on the API server.
Optimization 3: Stability
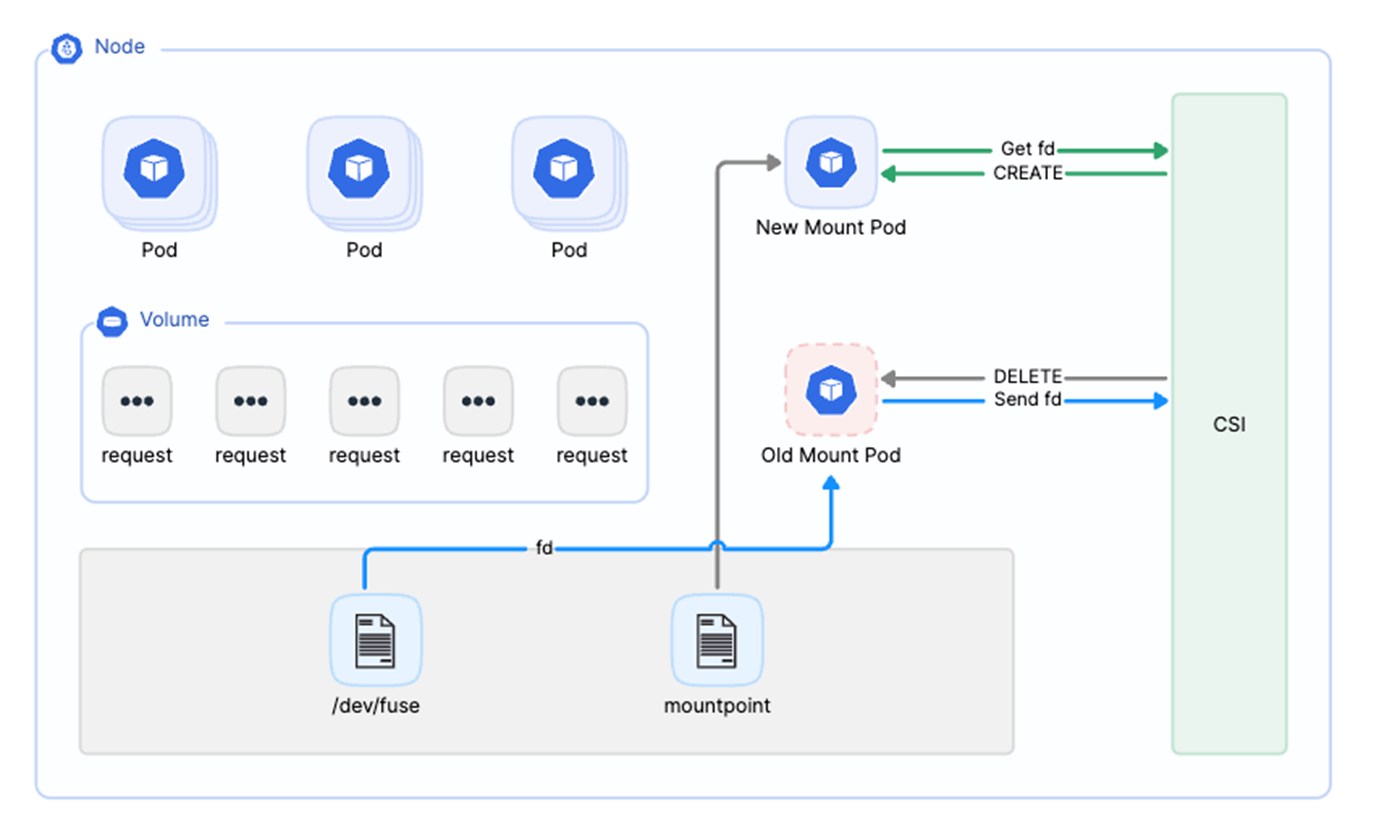
Due to the nature of FUSE clients, a remounted point may remain unusable after a restart. This affects all application data requests. To address this, we optimized the process by remounting for application Pods in CSI when the Mount Pod restarts due to OOM or other reasons. While this recovers the mount point, file requests may still be impacted during the transition.
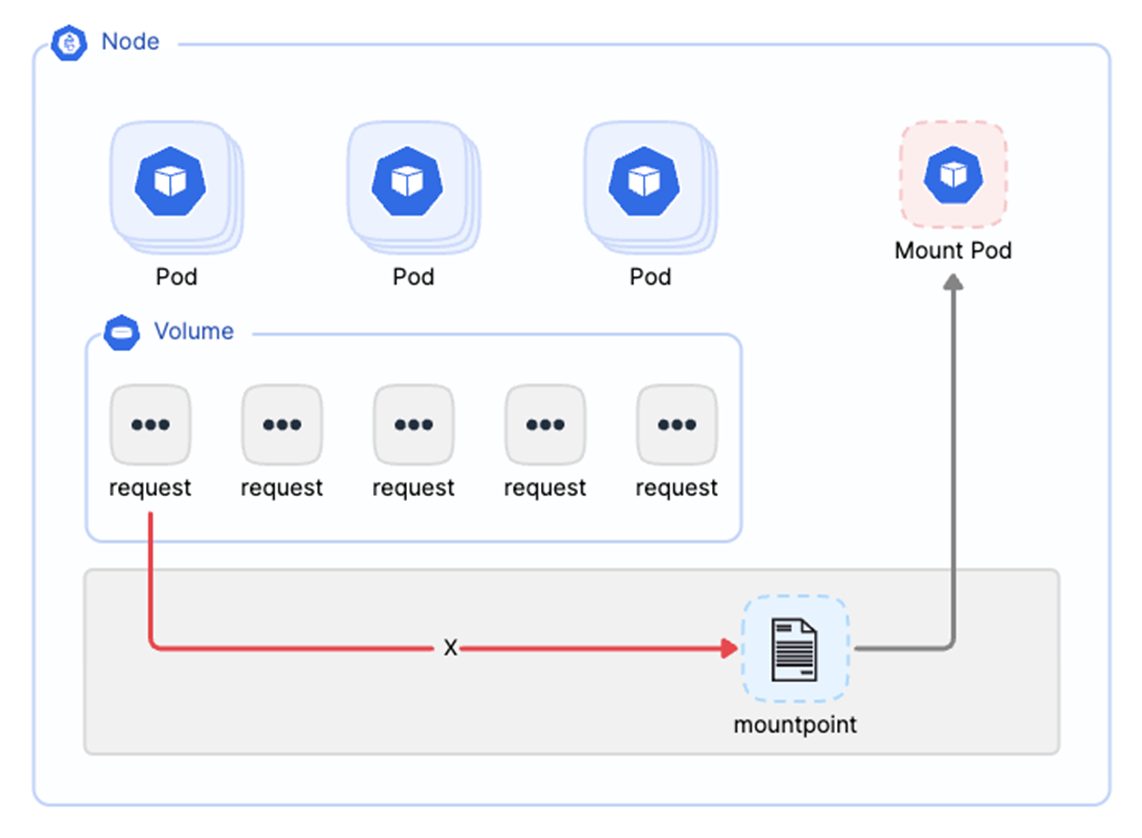
To further enhance this, we now acquire the fuse file descriptor (fd) used by the Mount Pod from /dev/fuse upon its startup and pass this fd to CSI Driver via inter-process communication (IPC). The CSI Driver maintains a mapping of Mount Pods to their respective fuse fds in memory. If a Mount Pod restarts due to OOM, CSI will promptly delete it and start a new Pod in its place.
This new Pod will obtain the previous fuse fd through IPC from CSI, allowing it to resume application requests. This approach minimizes user impact, resulting in only a brief delay during file read operations without affecting subsequent processing.
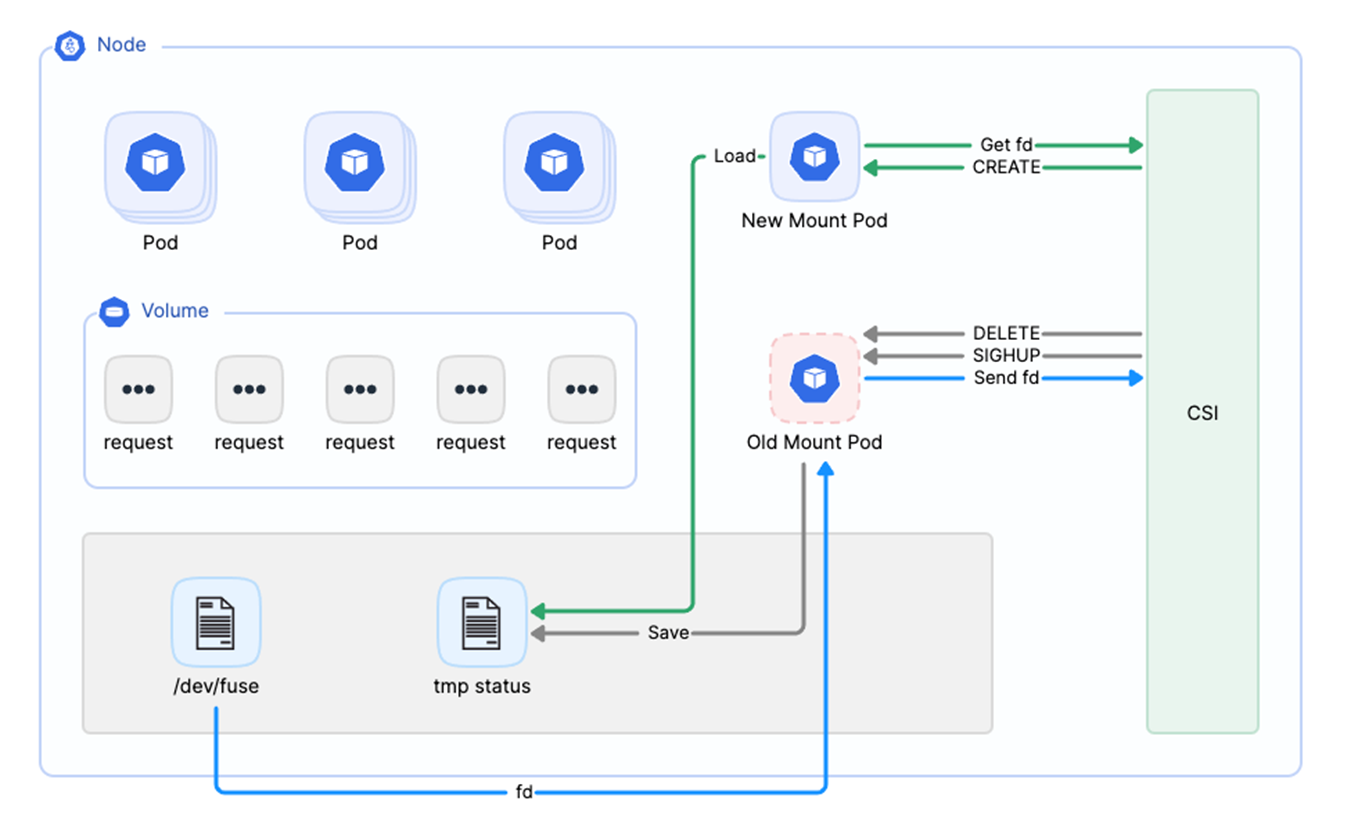
Optimization 4: Smooth upgrade
The smooth upgrade process for Mount Pods is similar to the fault recovery previously mentioned, but with a key distinction. During the old upgrade process, the existing client saves all ongoing data requests to a temporary file. With the implementation of the smooth upgrade feature, the new client performs two operations: it retrieves its fuse file descriptor (fd) from CSI and immediately reads data requests from the temporary file upon startup. This ensures that no application requests are missed during the upgrade, facilitating a truly smooth upgrade process.
Conclusion
Since JuiceFS CSI Driver was launched in July 2021, the growing number of Kubernetes users and expanding cluster scales have led to increasingly complex application scenarios. Over the past three years, we’ve continually optimized and improved JuiceFS CSI Driver in key areas such as stability and management permissions. This makes JuiceFS an ideal choice for persistent data storage in Kubernetes environments.
In summary, here are the core features and key optimizations of JuiceFS to assist users in making informed storage choices in Kubernetes environments:
- Data security: JuiceFS ensures data security through isolation, encryption, and permission control. Its distributed caching technology not only enhances system performance but also effectively manages costs.
- Data elasticity: In serverless environments, JuiceFS employs a sidecar design pattern and dynamic data scaling technology to enhance data elasticity.
- Data consistency: The mirror file system feature of JuiceFS guarantees data consistency in multi-cloud architectures, ensuring stability and reliability across different cloud platforms.
- High performance and cost control: JuiceFS can swiftly pull necessary file data from object storage into local cache, typically within 10 to 20 seconds. This significantly reduces data retrieval times compared to the 400 to 500 seconds it would take without caching. The warm-up process is executed in parallel, completing before model loading starts, which effectively minimizes startup time.
- POSIX compatibility: JuiceFS offers full POSIX compatibility, ensuring seamless integration with a wide range of applications and systems.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.