















vivo is a global technology company focused on designing and developing smartphones, smartphone accessories, software, and online services. With 10,000 employees, we operate 10 R&D centers across the world.
In the early stage, our AI computing platform used GlusterFS as the storage foundation. However, as the volume of data increased and diverse application scenarios were incorporated, performance and maintenance issues surfaced. To address these, we developed the XuanYuan file system. It’s a distributed storage solution built on the open-source edition of JuiceFS, a cloud-native high-performance distributed file system.
In this article, we’ll introduce the new features developed on top of JuiceFS for the vivo XuanYuan file system and highlight optimizations for key scenarios, such as faster sample data retrieval and checkpoint write operations. We’ll also cover vivo's technical roadmap, including optimizations to FUSE, metadata engines, and RDMA communication. Our goal is to offer insights to JuiceFS users operating in large-scale AI environments.
Why we replaced GlusterFS with the XuanYuan file system
Initially, our AI platform used GlusterFS, maintained by the in-house team. However, this setup encountered two key challenges:
- Performance slowed down significantly when handling small files.
- Scaling and balancing data on GlusterFS caused substantial disruptions to application operations.
To address storage limitations in early clusters, the computing team deployed new clusters. But this increased the management complexity with multiple clusters to maintain. In addition, as a platform provider with limited storage development personnel, the team found it difficult to implement new features.
After evaluating our in-house file storage solution and conducting extensive testing, they decided to migrate their data to our XuanYuan file system.
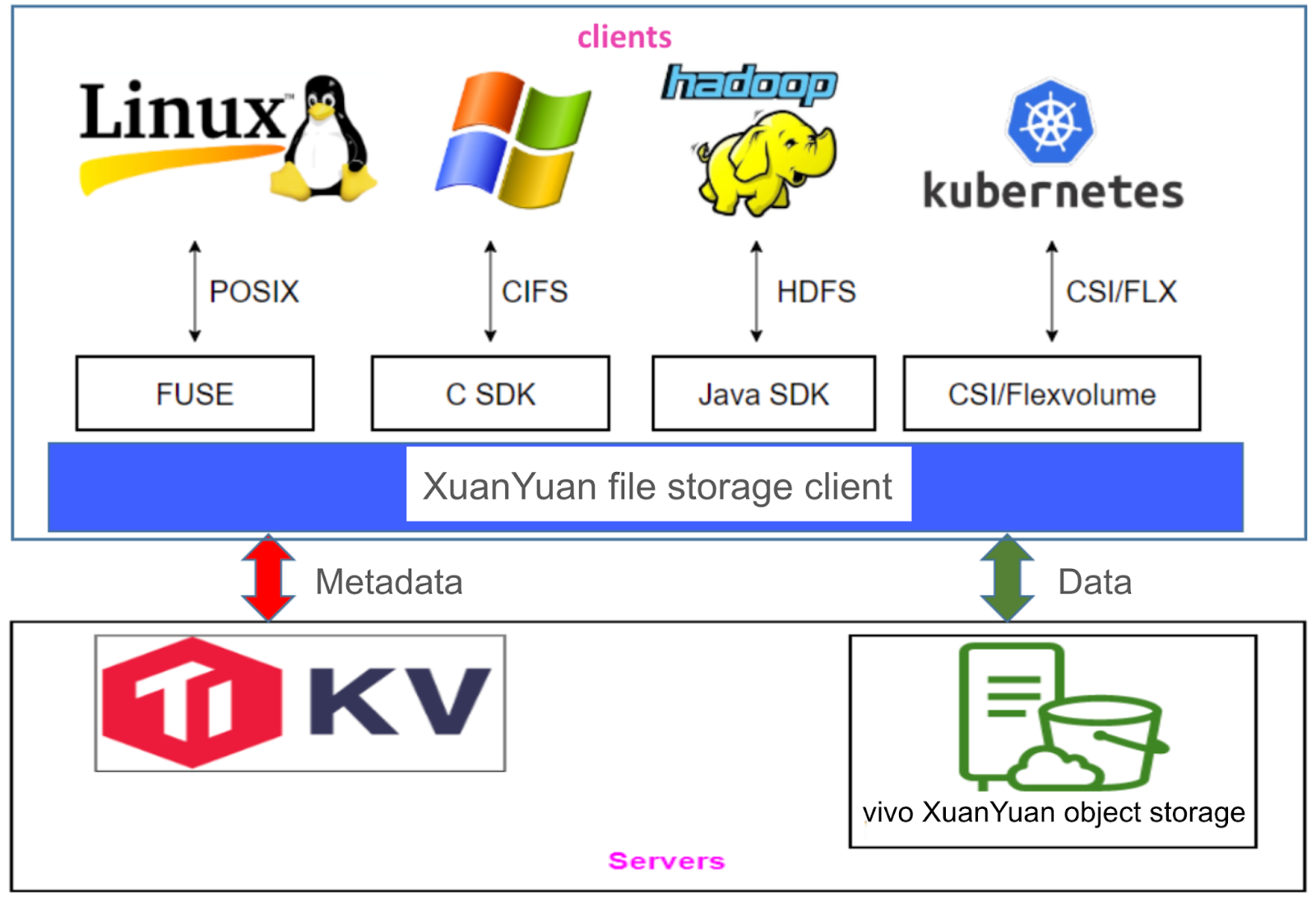
The XuanYuan file system’s architecture
The XuanYuan file system is built on open-source JuiceFS, extending support for multiple standard access protocols, including POSIX, HDFS, and CIFS for Windows. We also provide a data recovery feature that enables data recovery to its original path.
Our system includes hot-upgrade support for clients, a feature also available in the open-source edition, and local UID/GID-based authorization for user access management. We also implemented username-based authorization similar to the JuiceFS Enterprise Edition.
The figure below shows the XuanYuan file system architecture, which is similar to that of JuiceFS. Our system uses TiKV for metadata storage, while data is stored in our self-developed object storage. In Windows environments, we developed a Samba plugin that directly calls the JuiceFS API, enabling users to access the file system on Windows.
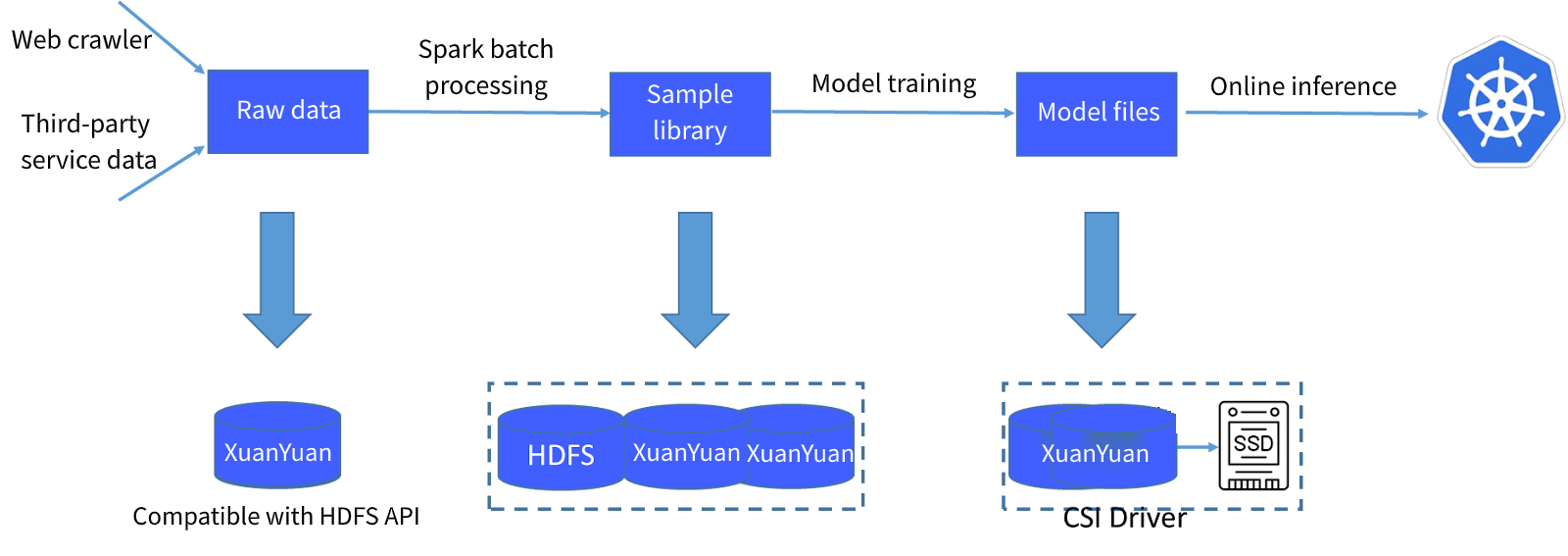
The AI computing platform's storage workflow is as follows:
- Raw data is processed through a 40,000-task system to generate sample libraries.
- These sample libraries train models on GPUs to generate model files.
- These models are used in online inference systems.
Raw data and sample libraries are stored directly in the XuanYuan file system, which supports the HDFS API for direct Spark processing. Model files are also stored in XuanYuan, and online inference systems access them directly using a CSI plugin.
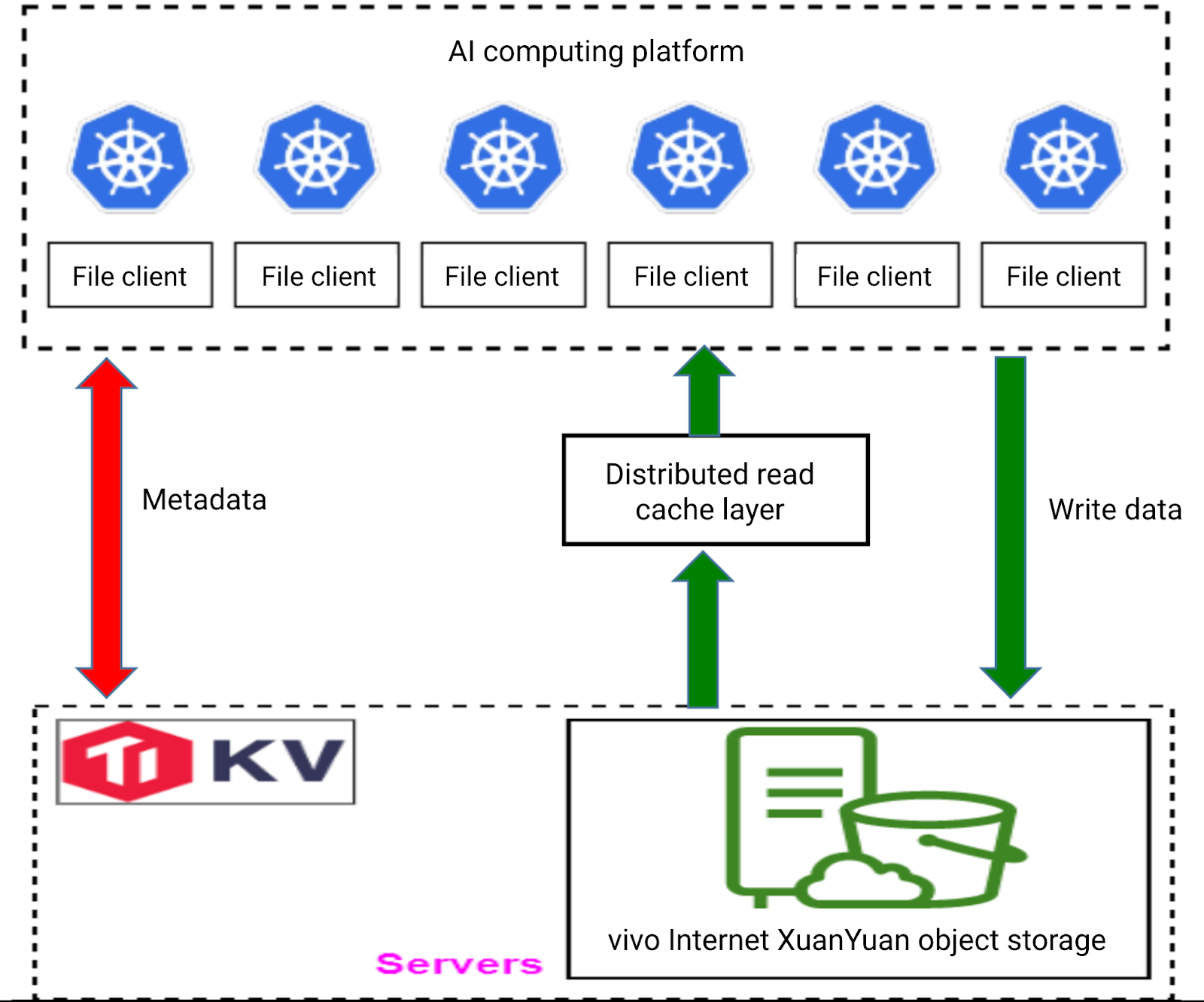
Storage performance optimization
During training, storage plays a vital role in two main areas:
- Sample reading
- Checkpoint writes
Accelerating sample reads
To speed up sample loading, we developed a distributed read cache layer. Before training, we use JuiceFS' warm-up feature to preload required data into the cache layer. This allows data retrieval directly from cache, bypassing object storage. Typically, reading data directly from object storage takes tens of milliseconds, but with the read cache, this time is reduced to under 10 milliseconds, significantly accelerating data loading to the GPU.
Checkpoint writes
For checkpoint writes, checkpoint data is first saved to a temporary cache, then gradually flushed to object storage. In this process, we use a single-replica mode, as checkpoints are saved periodically. This means the loss of a checkpoint from any given interval has limited impact on overall training.
In addition, we’ve implemented strategies to ensure the safety of critical data, as not all data is sent to the intermediate cache area. Generally, only checkpoint files and training-stage log files are written there. If training is interrupted, checkpoint files can be retrieved from this intermediate cache area.
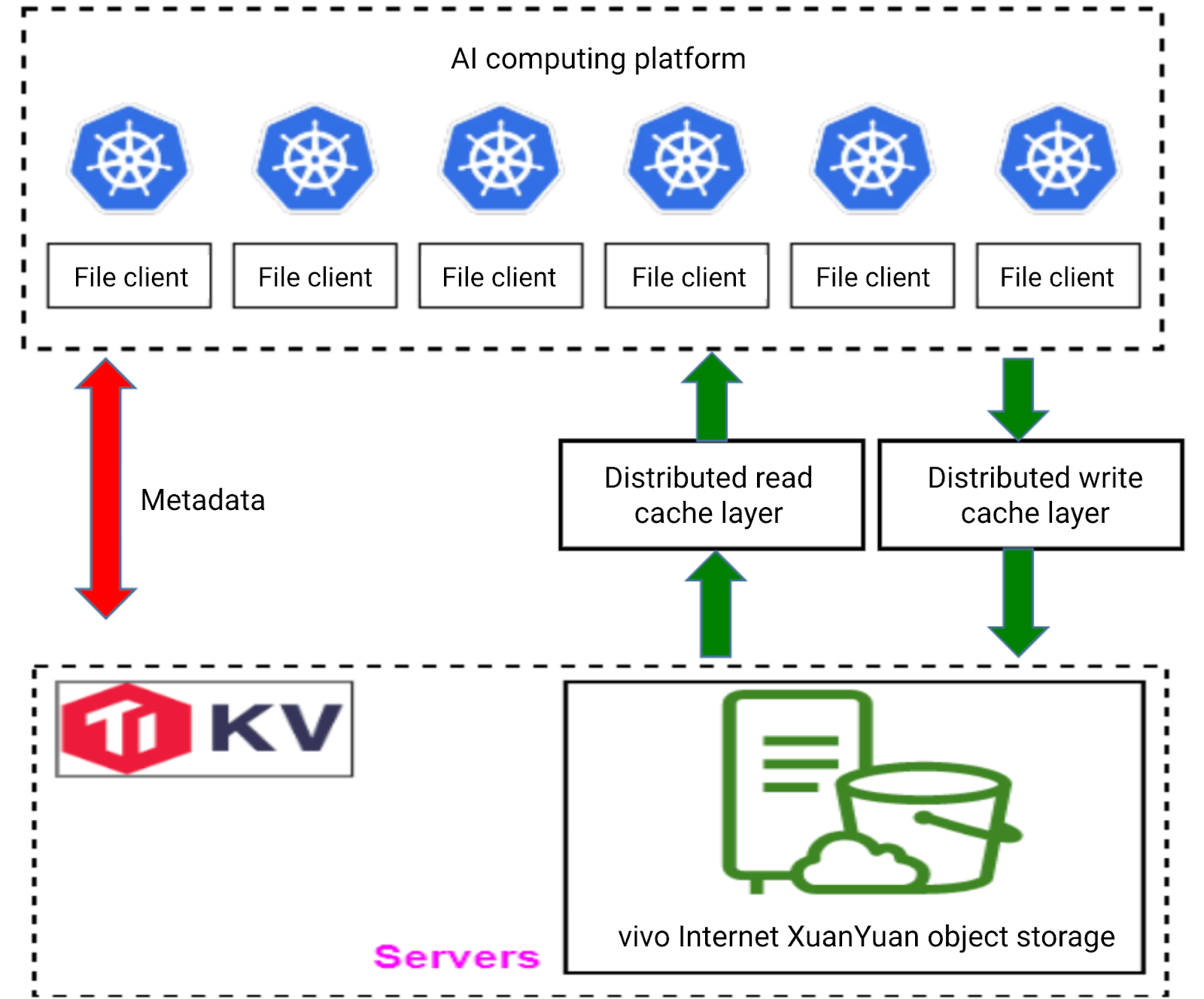
When data is written and flushed to object storage, we don’t immediately clear it from the checkpoint cache. Since training can be interrupted at any time, clearing cached checkpoint data would require reloading from object storage. This is time-consuming. To address this, we’ve set a time-to-live (TTL) mechanism. For example, if checkpoint data is flushed to object storage every hour, we set the TTL to 1.5 hours. This way, even if training is interrupted, the checkpoint cache retains the most recent backup for quick recovery.
In the process of developing the write cache, we faced a challenge: the gRPC protocol, used for client-to-cache communication, required frequent memory reallocation during data deserialization. This caused frequent memory allocation and release. Since our system was developed in Go, its garbage collection (GC) mechanism could be slow under these conditions, potentially leading to memory exhaustion in the write cache.
To address this issue, we explored alternative data deserialization options and ultimately adopted Facebook's FlatBuffers. Unlike gRPC's Protocol Buffers, FlatBuffers allows direct use after data deserialization without extra parsing steps. This approach reduced memory usage by 50% compared to Protocol Buffers. In addition, our performance tests revealed that switching to FlatBuffers improved write performance by 20%.
Reducing model loading traffic during online inference
During online inference, we observed significant bandwidth consumption from model downloads, occasionally saturating the object storage gateway. A deeper analysis revealed that numerous instances were independently loading entire models into memory, often simultaneously, creating intense traffic demands.
To address this, we implemented a logical grouping strategy within Pods. In this approach, each group retrieves a single complete model from the underlying storage. Nodes within the group access portions of the model through inter-node data sharing, similar to a P2P setup. This effectively reduces overall traffic demands on the object storage, substantially alleviating bandwidth pressure.
Our technical roadmap
Improving read/write performance by bypassing the FUSE kernel with libc calls
The figure below, sourced from an ACM journal, illustrates the significant overhead in context switching when handling requests through the FUSE mount, which involves switching from user space to kernel space and back again.
In the figure, the taller bars represent native FUSE performance, while the shorter bars show optimized solutions:
- Small file workloads: Native FUSE involves nearly 1,000 times more context switches compared to the optimized method.
- Large file workloads: Context switching in native FUSE is around 100 times higher than in the optimized approach.
- Mixed workloads: Similar, substantial differences in context switch counts are evident.
This data highlights the impact of context switching. This motivates our planned optimization of the FUSE layer, particularly for metadata and small file scenarios.
Developing a self-built metadata engine and file semantic integration
We are planning to develop our own metadata engine. Currently, we use a metadata engine based on TiKV, which lacks file semantics. All file semantics are implemented on the client side. This setup significantly hinders our feature development efforts.
Moreover, when multiple nodes write to the same key simultaneously, transaction conflicts occur frequently. Recently, we’ve also encountered issues where processes can suddenly hang for durations ranging from a few minutes to over ten minutes, which remain unresolved.
In addition, in the active mode of TiKV and PD components, once requests exceed 100,000, latency increases noticeably. The CPU usage of the PD nodes (with 112 cores) approaches saturation. To address this, we’re exploring various solutions to reduce the CPU utilization of the primary node in hopes of improving latency issues. We’ve referenced several papers, including Baidu’s CFS paper, aiming to minimize distributed transaction overhead by converting as many metadata operations as possible into standalone transactions.
Implementing RDMA in the cache layer
Our data center's GPU nodes currently use remote direct memory access (RDMA) networking. Their communication with the cache layer still relies on the TCP protocol. We plan to develop an RDMA-based communication method to facilitate low-latency and low-CPU communication between the client and cache.
We’ve observed significant delays in RPC communication from the client's flame graph. Although the data handling for write caching only takes one or two milliseconds, the time taken for the client to upload data across the entire network can reach five to six milliseconds, or even ten milliseconds. In scenarios where the client CPU is heavily loaded, this delay can extend to twenty or thirty milliseconds. In contrast, RDMA consumes minimal CPU resources and has lower memory overhead. Therefore, we consider it a promising solution worth exploring.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.