















INTSIG Information Co., Ltd. (INTSIG) is an industry-leading tech company specialized in business data, artificial intelligence, and mobile applications. We focus on optical character recognition (OCR) technology and currently hold 110+ global invention patents. We can provide integrated “OCR+Data+AI” solutions that deliver competitive advantages in various industries, including banking, insurance, logistics, retail, and manufacturing.
As the scale of the AI training platform continues to expand, our company has accumulated hundreds of billions of files and hundreds of petabytes of data, covering various task types such as natural language processing (NLP) and computer vision (CV). Storage requirements have become increasingly complex. In the original architecture, BeeGFS served as high-speed parallel storage with RDMA access but had limited capacity. SeaweedFS provided large-capacity object storage but faced performance bottlenecks and resource contention issues due to mixed deployment with online services. Under this architecture, frequent data migration, fragmented access paths, and low resource utilization became major bottlenecks.
To address these challenges, we introduced JuiceFS to build a unified storage access architecture, combined with BeeGFS to provide distributed caching capabilities. JuiceFS now stably supports billions of files, tens of petabytes of existing data, and PB-scale daily data increments, with an average cache hit rate exceeding 90%, significantly improving I/O performance for AI training and big data tasks. This architecture integrates high-speed caching with low-cost object storage access paths, enables seamless multi-source data flow, improves overall resource scheduling efficiency, and supports efficient mixed deployment with online services.
AI platform and early storage architecture
The AI training platform primarily serves the training and inference of various algorithm models, while the big data platform focuses on supporting the storage and computational analysis of massive datasets. Both AI model iterations and big data mining tasks place high demands on computing resources and storage performance. To enhance overall resource utilization, we introduced an offline hybrid deployment strategy for the computing and storage layers, achieving efficient use of limited computing and storage resources through unified scheduling and resource reuse.
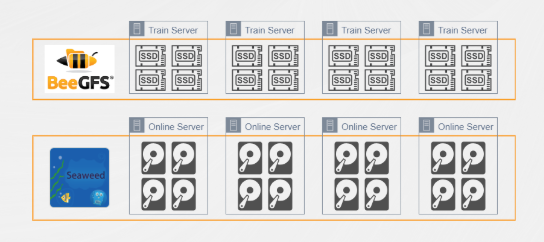
Early distributed file storage architecture: BeeGFS + SeaweedFS
Initially, our tasks were primarily single-node training, with datasets typically relying on local storage on training servers. With the development of multi-GPU and multi-node training tasks in recent years, the need for cross-node shared datasets grew. This prompted our introduction of distributed storage to meet these requirements.
To address this change, we introduced two open-source projects to build the storage system. We constructed a distributed all-flash storage system based on BeeGFS and SSDs on training nodes. This solution adopted a mixed deployment approach with training servers, leveraging existing computing resources to achieve high storage performance and low access latency, making it suitable for training tasks with high I/O demands. However, due to deployment limitations tied to the number of training nodes, the overall storage capacity was small. This made it difficult to support large-scale datasets.
Considering the large total volume of training data, we deployed another storage system based on SeaweedFS. Originally designed for object storage, SeaweedFS also supports basic POSIX protocols, allowing it to function as a distributed file system. We deployed it in physical servers used for online services, with mechanical hard drives as the primary storage medium. Compared to BeeGFS, this system increased total capacity by tens of times. However, due to resource sharing with online services and performance restrictions to avoid interference, it faced I/O performance bottlenecks.
Through the combined deployment of these two systems, we implemented a tiered storage architecture: BeeGFS provided high-performance but limited-capacity storage, while SeaweedFS offered large-capacity but performance-constrained storage. This architecture could flexibly adapt to different types of training tasks, effectively supporting large-scale AI training.
Computing task management: Decoupling storage to improve GPU utilization
The following outlines some of our work in GPU computing resource scheduling for training tasks. In the early stage, GPU cards were often statically allocated by person or project, meaning certain cards were permanently assigned to specific users or projects. This approach proved inefficient in practice: some users who applied for cards did not utilize them fully, while others with urgent training needs had to rely on manual coordination, resulting in significant resource waste.
To address this issue, we introduced Slurm as the scheduling system for training tasks, enabling unified management of global GPU resources. Through task scheduling, we dynamically allocate GPUs across different tasks, improving overall resource utilization. The scheduling system is operated by a dedicated task scheduling team that continuously optimizes scheduling strategies to ensure fair resource allocation for training tasks.
By combining the above-mentioned distributed storage system with GPU scheduling, we initially achieved the decoupling of computing and storage. On one hand, task scheduling improved overall GPU utilization; on the other, the unified storage system eliminated the need for frequent large-scale data copying during task deployment, enhancing system efficiency and scalability.
New storage system requirements and architectural evolution
After running this system for some time, as application dataset sizes expanded rapidly, we had new requirements for the storage layer:
- POSIX compatibility: Engineers across application units used different algorithm training frameworks, some with custom programs, requiring storage systems with comprehensive POSIX interface compatibility. However, SeaweedFS, which we previously used, had limitations in this regard. It was fundamentally object storage-oriented, with incomplete POSIX support, leading to compatibility issues during training tasks.
- Unified access path management: BeeGFS, our high-speed storage solution, had limited capacity, and users preferred storing data there for better performance. This led to sustained pressure. To mitigate this, we frequently migrated data between BeeGFS and SeaweedFS. Despite implementing automated cache controls, large-scale dataset migrations remained time-consuming, inefficient, and labor-intensive.
- Balanced resource utilization: SeaweedFS was deployed on bare-metal servers shared with online services, and its I/O performance was limited to protect online resources. During high-concurrency training tasks, SeaweedFS often hit performance bottlenecks. In contrast, BeeGFS offered higher performance but suffered from low resource utilization due to capacity constraints. We needed a mechanism to dynamically balance cold and hot storage resources while maintaining performance.
Based on these requirements, we conducted further technical research and ultimately adopted JuiceFS as our new storage solution.
Rebuilding a storage system with JuiceFS and optimizing distributed cache
We rebuilt the storage system for training tasks using JuiceFS. The figure below shows JuiceFS’ architecture, which we adapted to our needs.
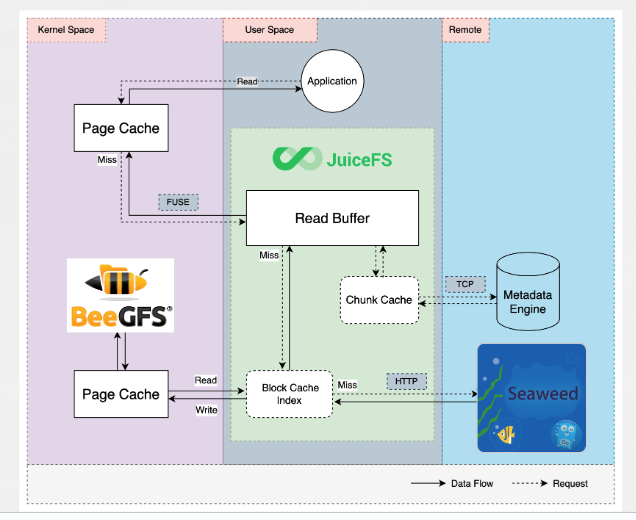
On the left side of the architecture, where JuiceFS originally labeled "local disk" for local caching, we instead point the cache directory to the BeeGFS file system. This adjustment allows us to use a shared, high-performance distributed file system (BeeGFS) as JuiceFS’ cache layer. In multi-GPU training scenarios, only one node needs to fetch data from remote storage, while others can read directly from the shared cache, avoiding redundant downloads.
This mechanism also makes cache warm-up more efficient. We only need to perform the warm-up task on one node, and then all nodes can read data from the shared cache that has been warmed up. This greatly improves training startup efficiency and overall bandwidth utilization.
On the right side, we retained SeaweedFS as the backend object storage but stopped using its POSIX mounting capability, treating it purely as object storage. This avoided SeaweedFS’ POSIX compatibility issues while using its storage capacity advantages.
Cache hit rate optimization for training tasks
With the layered storage architecture, efficient data scheduling between BeeGFS’ high-speed cache and object storage became critical for training performance. As multi-GPU and distributed training tasks scaled, we faced challenges beyond bandwidth and capacity—specifically, improving cache hit rates, reducing redundant loading, and accelerating training startup.
To address these challenges, we developed a comprehensive cache hit optimization mechanism centered on training tasks and data access behavior. This included:
- Automatic association modeling between training tasks and datasets
- Active and passive warm-up strategies
- Intelligent dataset prioritization based on access density and historical behavior
Through these mechanisms, we achieved efficient data scheduling with limited cache resources, prioritizing high-value data and significantly improving system resource efficiency and training responsiveness.
Long-term operational data showed a stable cache hit rate above 90%, with training task read performance reaching 80% of BeeGFS levels, greatly optimizing I/O efficiency and system stability.
Strategy 1: Automatic association between training tasks and datasets
To balance resource utilization between BeeGFS and object storage, we aimed to maximize cache hit rates, reducing repeated backend storage access. We optimized warm-up at the scheduling level by adding an acceleration parameter during task creation. Engineers submitting training tasks could specify one or more compressed directory paths as data directories. The system recorded these directories and periodically analyzed their historical usage frequency and size, using directory size as a warm-up priority factor.
This approach linked training tasks with datasets, improving the cache layer’s responsiveness to hotspot data and enhancing task startup efficiency and GPU utilization.
Strategy 2: Combined active and passive warm-up
We designed two warm-up mechanisms:
- Passive warm-up (triggered upon task submission)
- Active warm-up (executed during low-load periods based on historical usage)
In passive warm-up scenarios, when a user submits a training task, the task first enters the task scheduling queue to await GPU resource allocation. Simultaneously, the datasets required by the task are sent to the warm-up scheduling queue to prepare for cache loading.
To avoid redundant data loading, we implemented a deduplication mechanism in the warm-up queue, including:
- Merged warm-up when multiple tasks use the same dataset
- Path consolidation for hierarchical directory structures
During queue processing, each dataset is assigned a warm-up priority, and the scheduling system executes warm-up operations in priority order. This means the scheduling of training tasks and the warm-up of datasets are asynchronous and independently managed. For example, a user submits Task A, but the scheduler may prioritize running Task B first. Meanwhile, the warm-up system may be loading Dataset C for another pending task. The core premise of passive warm-up: Datasets are only warmed up after a dependent task is submitted.
In contrast, we designed an active warm-up mechanism to proactively load frequently used datasets during system idle periods (such as low object storage load or off-peak training hours).
Active warm-up does not depend on whether there are currently queued tasks. Instead, it automatically identifies frequently used datasets based on historical task execution data and proactively warms up tasks. By executing these tasks during low-load periods, we can effectively reduce reliance on passive warm-up during peak task hours, thereby improving overall training efficiency and preventing performance fluctuations caused by cache misses.
By combining passive and active warm-up, we built an intelligent cache warm-up system that balances resource efficiency and task responsiveness. This hybrid approach balanced resource efficiency and task responsiveness, improving overall training efficiency in shared cache environments.
Strategy 3: Dataset prioritization based on access behavior
During the cache warm-up process, multiple pending datasets may coexist in the warm-up queue. To rationally arrange their execution order, we established two core principles:
- We actively avoid evicting datasets that are currently being used by running tasks or those required by queued tasks. For this purpose, we maintain a cache status table that records the presence and occupancy ratio of each dataset in the cache. If a dataset already occupies significant cache space, we temporarily suspend new warm-up tasks targeting it to prevent inefficient data replacement.
- We prioritize warming up datasets with higher historical hit rates. Specifically, we observed that when engineers specify data paths for training tasks, they often reference higher-level directory structures while actually only using certain subdirectories during execution. Blindly warming up entire directories would not only waste storage resources but might also lead to accidental eviction of actively used data. Therefore, we implemented a more granular analysis mechanism.
We use task execution time windows and node distribution information recorded by the task platform, combined with JuiceFS' metadata monitoring capabilities, to analyze the actual access behavior of each dataset during task execution. This includes tracking the specific data paths accessed, read volumes, and their proportion within the entire data directory. Based on this analysis, we calculate cache density and hit rate metrics. Datasets with higher hit rates or those frequently accessed within individual tasks are consequently assigned higher warm-up priorities.
New architecture summary: Enabling large-scale hybrid computing
Through systematic transformation of both the storage and task scheduling layers, we built a unified infrastructure capable of supporting large-scale hybrid computing. This architecture flexibly accommodates diverse workloads—including AI training/inference and big data processing—while leveraging heterogeneous computing resources (CPUs and various GPU types) at the underlying layer. By orchestrating task scheduling flexibly, we enable time-shifted execution of different task types, achieving a "peak shaving and valley filling" effect that boosts overall resource utilization.
At the storage layer, we implemented a tiered hot/cold data management mechanism that fulfills the high-performance access requirements during training through cache acceleration and protocol adaptation. Concurrently, by establishing automated associations between training tasks and datasets, along with optimized scheduling of warm-up mechanisms, we significantly enhanced the system's responsiveness and stability under high-concurrency scenarios.
Considering the diverse training requirements across our company, including various model training needs such as NLP and CV, we architected JuiceFS as a unified shared storage platform. This solution provides all departments with stable, high-performance distributed file system support, ensuring both data access consistency and resource reuse capability in cross-team, large-scale training environments.
JuiceFS-based redundant data optimization
Preventing new duplicate files
After the system had been running for some time, we found a common usage scenario: some engineers habitually copied public datasets to their personal directories, made modifications, and then executed training tasks. This "copy-and-modify" approach led to significant data redundancy, particularly when multiple users made minor adjustments to the same dataset, causing storage costs to rise rapidly.
To address this issue, we guided users to adopt JuiceFS' juicefs clone command. This command enables snapshot-style data replication at the file system level, where multiple files exist as logically independent entities while sharing the same underlying data blocks in object storage. This dramatically reduces storage space waste.
This mechanism relies on several underlying system requirements:
- Using JuiceFS' native clone command
- OS kernel support for
copy_file_range cpcommand version 8.3 or higher in the toolchain
In the early stages, when these prerequisites weren't strictly enforced, the system accumulated many redundant data copies. Therefore, we implemented data management measures: educating engineers through documentation and training to use juicefs clone instead of cp, while upgrading system kernels and cp tool versions to natively support underlying data sharing and reduce redundant writes at the source.
Cleaning up existing duplicate files
To further reduce existing redundant data, we designed and implemented a duplicate detection and cleanup strategy for stored files. Our method was as follows:
We traversed the entire JuiceFS file system, performing initial partitioning based on file size byte suffixes (for example, grouping all files with sizes ending in 10240). This approach clustered potentially duplicate data files to minimize unnecessary comparison computations.
Within each partition, we further filtered files of the same size. Then, we performed content similarity verification in two stages:
- Fast prefix check: First comparing the initial 1 KB of files as a quick filter.
- Full byte-by-byte comparison: If prefixes matched, conduct a complete content comparison to confirm the same copies.
Using this method, we successfully identified about 10% of system files containing duplicate content. For larger redundant files, we prioritized using JuiceFS' tools for content merging and deduplication, redirecting them to share underlying objects and reclaiming wasted space.
For smaller duplicate files where deduplication costs might outweigh benefits, we typically retained them. Our overall strategy followed a "maximize space recovery" principle while ensuring data consistency during cleanup.
As large language model training and inference demands grew within our company, the original storage architecture revealed bottlenecks in performance, capacity, and scheduling efficiency. By introducing JuiceFS and continuously optimizing task scheduling, cache warm-up, and data management mechanisms, we built a training data storage system with excellent scalability, stability, and resource efficiency. This system has successfully supported concurrent operation of multiple application lines and diverse task types, laying a solid foundation for large-scale AI infrastructure. Moving forward, we’ll continue refining platform capabilities based on actual training requirements, further enhancing intelligent scheduling and resource management to provide stronger support for internal AI applications.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.