















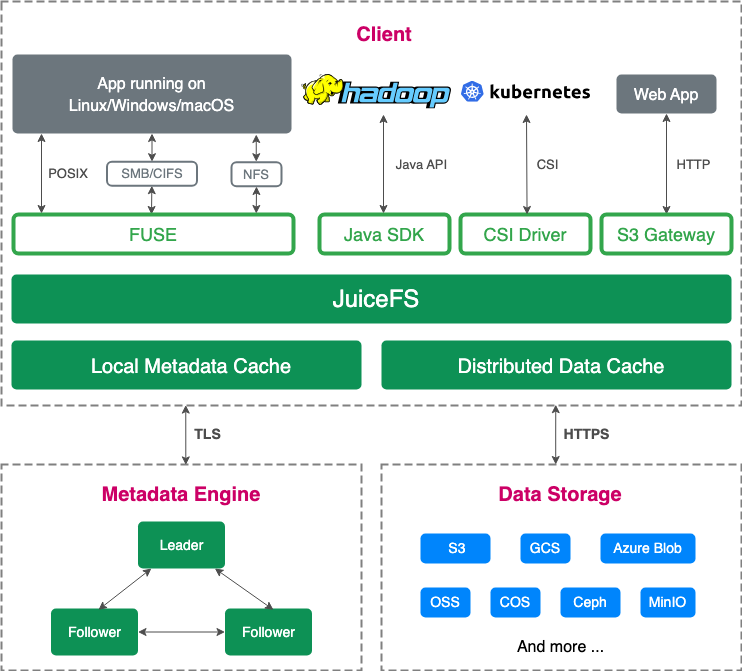
Gaoding Technology is a technology company dedicated to providing innovative visual content solutions for businesses and individuals. It aims to revolutionize design workflows, empowering users to effortlessly create and deliver value through design.
With the rapid advancement of artificial intelligence (AI) technologies, data storage and management have become critical infrastructure supporting our company’s innovation and growth. Initially, we relied on object storage and NAS services provided by public cloud vendors for AI training data. However, as business developed, the GPU resources from a single cloud provider could no longer meet demand, prompting us to adopt a multi-cloud architecture for greater flexibility in computing resources. This shift brought new technical challenges: how to uniformly manage training data across multiple cloud environments while enabling efficient, low-cost cross-cloud read/write access.
We introduced JuiceFS, an high-performance distributed file system, to address these challenges. Its robust multi-cloud compatibility, flexible mounting mechanisms, and comprehensive tools enabled us to seamlessly bridge data access across different cloud environments. Today, JuiceFS manages training datasets and model libraries, significantly simplifying multi-cloud data management. Its efficient caching mechanism accelerates data loading during training and improves mounting responsiveness for model inference, delivering performance and efficiency gains.
Storage challenges in training: data scale, performance, and multi-cloud issues
As AI services scaled, Gaoding’s operations team faced multiple storage challenges, particularly in model training, which involves five key steps—each heavily reliant on storage:
- Data collection: Collect and store raw data from various sources as needed
- Data cleaning and preprocessing: Clean, filter, and preprocess the collected data.
- Model training: Train the model based on the processed data and algorithm model.
- Model production and verification: After training is complete, the model is generated and subjected to basic performance and quality verification.
- Inference service: After the model is verified, it’s deployed and provided as an inference service.
Key storage pain points in training:
- Massive data volume: Training datasets range from tens of gigabytes to hundreds of terabytes, far exceeding typical workloads.
- High data read performance requirements: Model training requires expensive GPU resources. Poor data read performance leads to low GPU utilization, resulting in significant resource waste.
- Hot data management requirements: Model training often uses the same batch of data for multiple iterations. This means that currently used data is likely to be accessed again in the near future, so it’s desirable to cache this data to improve subsequent read speeds.
Using conventional storage solutions for training data storage has some challenges: For local disks, purchasing, and maintaining large-capacity disks is expensive, and the capacity of individual disks is limited, requiring multiple disks to support large-scale data storage. Furthermore, tight coupling of data and compute forces tasks to be scheduled on servers where data resides, limiting scheduling flexibility.
Object storage's greatest advantage is its low storage cost, and the Container Storage Interface (CSI) provided by public cloud providers makes mounting it easier. However, despite its low cost, object storage suffers from poor read and write performance. This makes it unable to meet the high-performance storage requirements of large-scale data training.
Public cloud NAS is a common solution for storing training data, but it suffers from several issues:
- Low operational efficiency, particularly slow data deletion and copying
- Insufficiently granular permission management and control
- Difficulty in accurately calculating the amount of data in a directory
While advanced NAS services can improve performance, they come at a significant cost.
In addition to the limitations of the above-mentioned storage solutions, we faced an even greater challenge: a single public cloud provider could no longer provide sufficient GPU resources. Due to global chip supply constraints, obtaining high-performance GPUs has become increasingly difficult, forcing us to consider a multi-cloud strategy. However, a multi-cloud environment presents a new storage challenge: how to share training data across different cloud providers. NAS services vary significantly from one cloud provider to another, making data sharing and synchronization a complex and time-consuming task.
As a result, we had to re-evaluate and re-plan our storage architecture to meet the stringent requirements of AI training in a multi-cloud environment.
Why we chose JuiceFS
After a thorough evaluation process, we ultimately selected JuiceFS as our storage solution, primarily based on the following considerations:
- Multi-cloud architecture support: JuiceFS seamlessly integrates with most public cloud platforms. Its cross-region replication and mirror file system capabilities enable effortless data sharing across multiple clouds or regions, eliminating the complexity of cross-region data management and synchronization.
- Exceptional data read performance: Thanks to JuiceFS’ unique distributed multi-level caching mechanism, it delivers outstanding read performance. This is critical for AI training workloads that demand high IOPS and throughput.
- Critical data management capabilities
- Access control: Although JuiceFS’ permission model is token-based, it fully meets our daily operational requirements.
- Trash: The built-in trash feature allows quick recovery of accidentally deleted data, ensuring robust data protection.
- Comprehensive tools
- CSI support: Essential for our operations, JuiceFS’ CSI driver simplifies deployment and usage in Kubernetes environments.
- Monitoring system: JuiceFS provides rich monitoring metrics, enabling efficient troubleshooting.
- CLI tools: JuiceFS’ command-line utilities are powerful and user-friendly. Notably, its instant clone functionality dramatically improves efficiency—where traditional copy operations are slow, JuiceFS can clone large datasets (such as 1 TB or 2 TB) in seconds, improving our work efficiency.
The following table is a performance comparison test we conducted between JuiceFS and a specific NAS solution during the selection process, primarily simulating image data commonly used in daily AI training. We used 10,000 randomly generated files ranging in size from 200 KB to 3 MB.
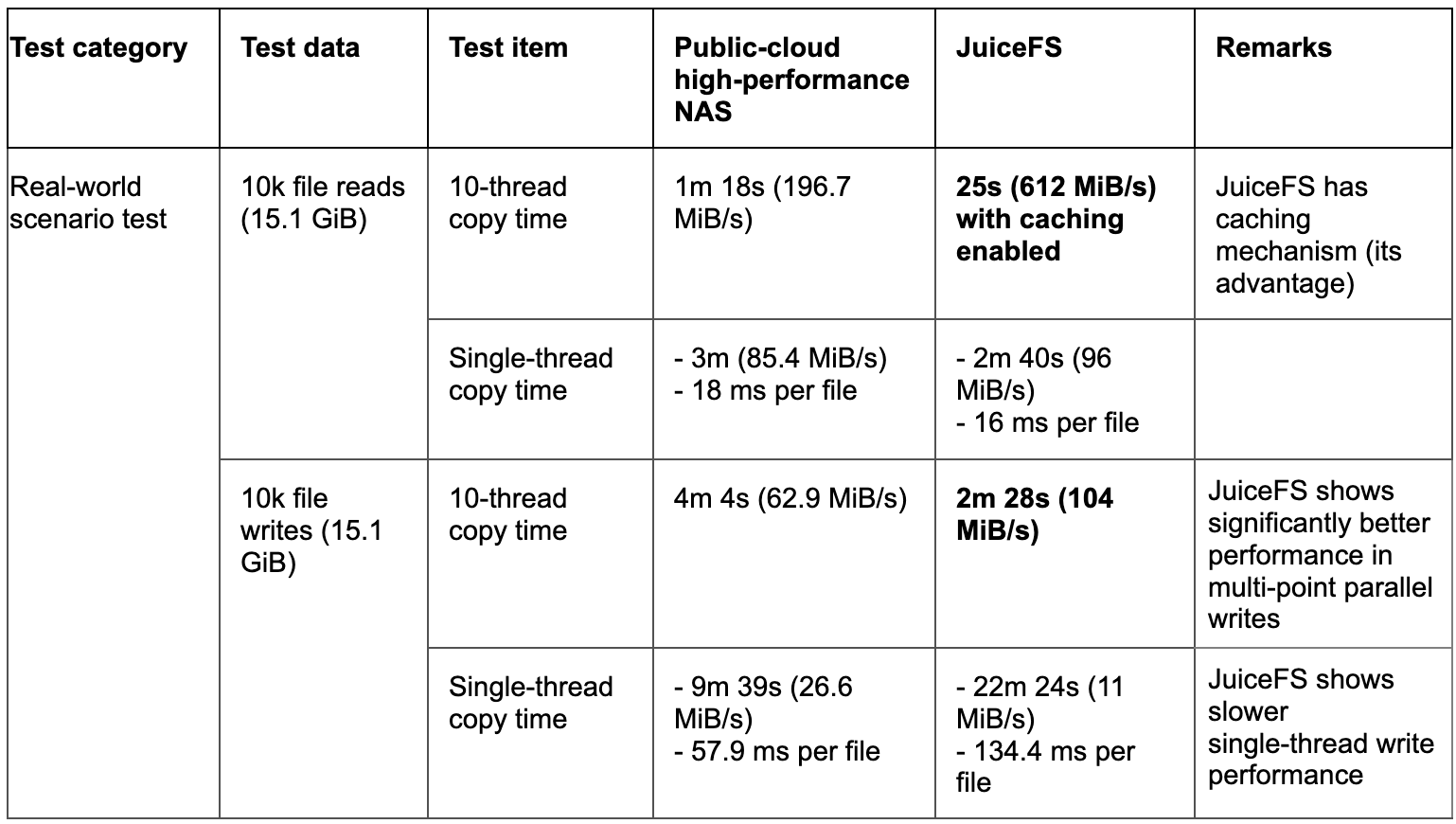
Key findings:
- With caching enabled, JuiceFS demonstrated significantly superior read performance.
- Without caching, JuiceFS performance was slightly lower than NAS.
In real-world AI training scenarios, datasets are typically known in advance. This allows us to preload data before training begins. This ensures all required data is properly cached. Under these conditions, JuiceFS' read performance advantages are fully realized. In addition, in multi-point parallel write scenarios, JuiceFS demonstrates superior performance compared to NAS.
Multi-cloud model storage practice
Multi-cloud capability was a critical requirement in our architecture, and we'd like to elaborate on our implementation journey. Initially, we employed two primary approaches for model data storage:
- Solution 1: Uploading the model to object storage. When packaging the image, one approach is to package the model directly into the image. Since some models are large, potentially reaching over 10 GB, this can increase the image size to over 20 GB. This slows down image pulls and even causes timeouts. Another approach is to retrieve the model through a link when the service container starts. If the service has multiple instances, download time increases significantly, potentially leading to inefficiencies. We once had a service using this approach, and rolling updates for over a dozen instances took over an hour. Regardless of the approach, multiple copies of model data are stored in the Kubernetes cluster, wasting storage resources.
-
Solution 2: Storing the model on NAS and mounting the service container on it. This solution has two issues:
- Since the application is deployed in multiple regions domestically and internationally and on different cloud providers, manual management of model data synchronization across multiple regions is required.
- NAS has poor model loading performance, which can easily cause application request timeouts.
Actual testing shows that the time required to load the model is roughly the same each time.
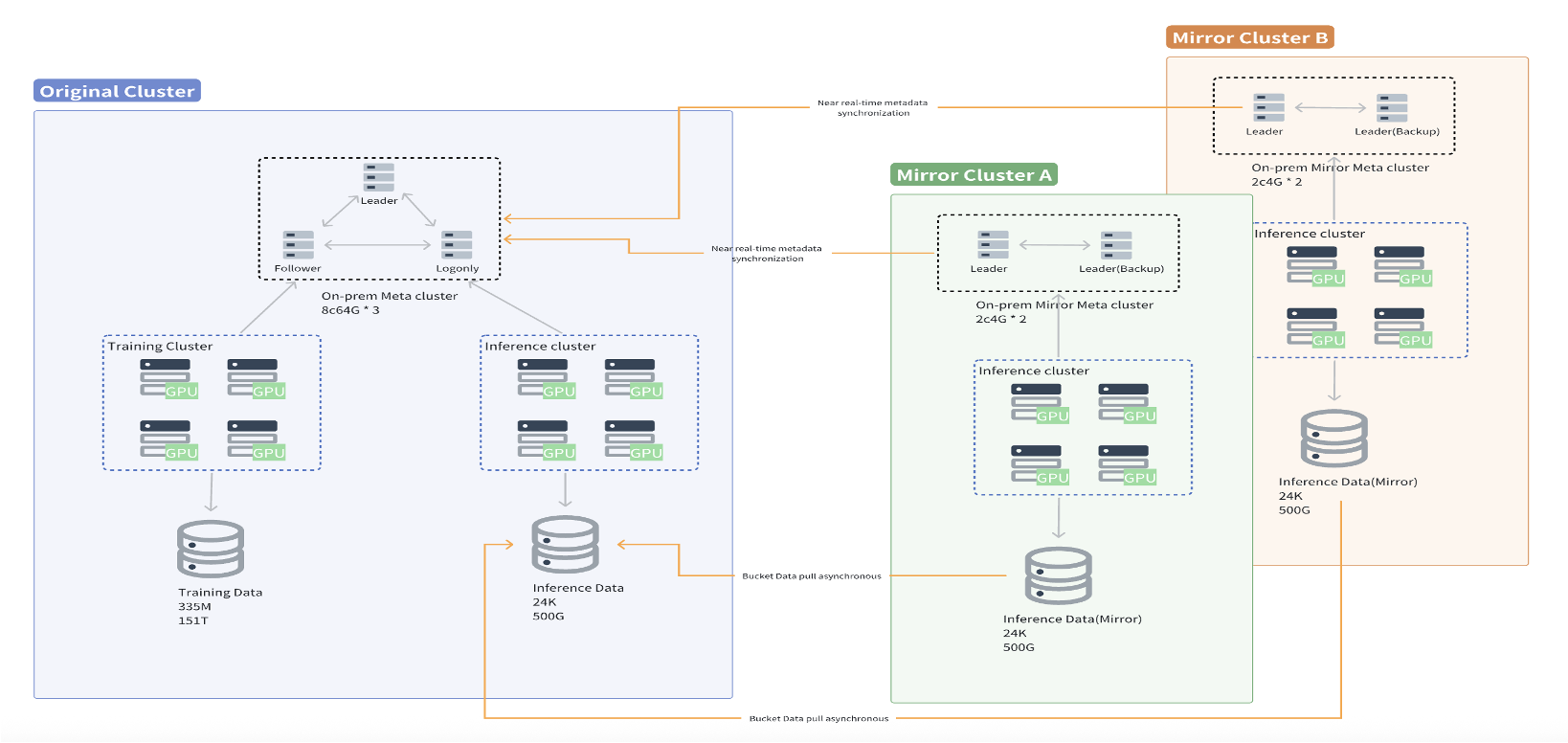
After introducing JuiceFS, we used its mirror file system feature to build a multi-region model storage architecture. As shown in the diagram below, the left side of this architecture represents the source file system, while the right side is multiple mirrored file systems. Simply import the model into the source file system, and the mirrored file systems in other regions will automatically synchronize the model data. Even if the model data hasn't been fully synchronized, it will automatically read back from the source when accessed. This greatly simplifies the entire data management process, and cached model data loads faster. JuiceFS shows approximately three times the loading performance of traditional NAS.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.