















The demand for inference services is rapidly growing in the market and has become a key application of widespread interest across various industries. With the continuous enhancement of model inference capabilities through techniques like chain-of-thought and slow thinking, their application scope keeps expanding, holding significant importance for enterprises deploying AI infrastructure.
Inference services impose higher requirements on storage systems. There is a need not only for high-performance, low-latency data access capabilities but also for features like elastic scaling, resource isolation, and multi-cloud deployment. Choosing the right storage solution has become a crucial issue enterprises must address when building AI infrastructure. JuiceFS has been widely adopted in various inference service scenarios, serving different types of customers including foundational model platforms, multi-modal applications, and enterprise-grade AI services. Based on in-depth analysis of these practical cases, we’ve summarized a series of representative storage requirements and challenges.
This article is divided into two sections:
- The first section focuses on the storage access patterns in inference services, combining JuiceFS application practices to outline key requirements and common problems in inference scenarios.
- The second section compares the advantages and limitations of several mainstream storage solutions, helping users make more informed selection decisions when building inference systems.
Storage requirements of inference services
JuiceFS is already widely used in inference scenarios. Through collaboration with customers, we’ve identified several typical storage requirements for inference workloads:
- More complex multi-modal I/O patterns: Inference is rapidly evolving towards multi-modal directions, involving extensive small file management, mmap-style random reads, and other access patterns. These scenarios are extremely sensitive to - I/O throughput and latency, directly impacting model response speed and user experience.
- Cloud-native deployment needs: Inference traffic typically has distinct peaks and troughs, requiring the underlying storage to quickly respond to sudden requests and coordinate with cloud-native scheduling systems to achieve scaling within minutes.
- Clear trend towards multi-cloud/multi-region architectures: To enhance service availability and disaster recovery capabilities, more customers deploy inference services across multiple clouds or regions. The storage system needs to possess strong cross-region consistency and cost-control capabilities.
- Emphasis on both resource sharing and isolation: Inference tasks prioritize resource reuse, especially in clusters shared by multiple tenants or application lines. Balancing effective isolation and data security with high resource utilization becomes fundamental for stable system operation.
Model loading performance challenges
We can analyze file access requirements through the various stages of an inference service. The main stages of an inference service include:
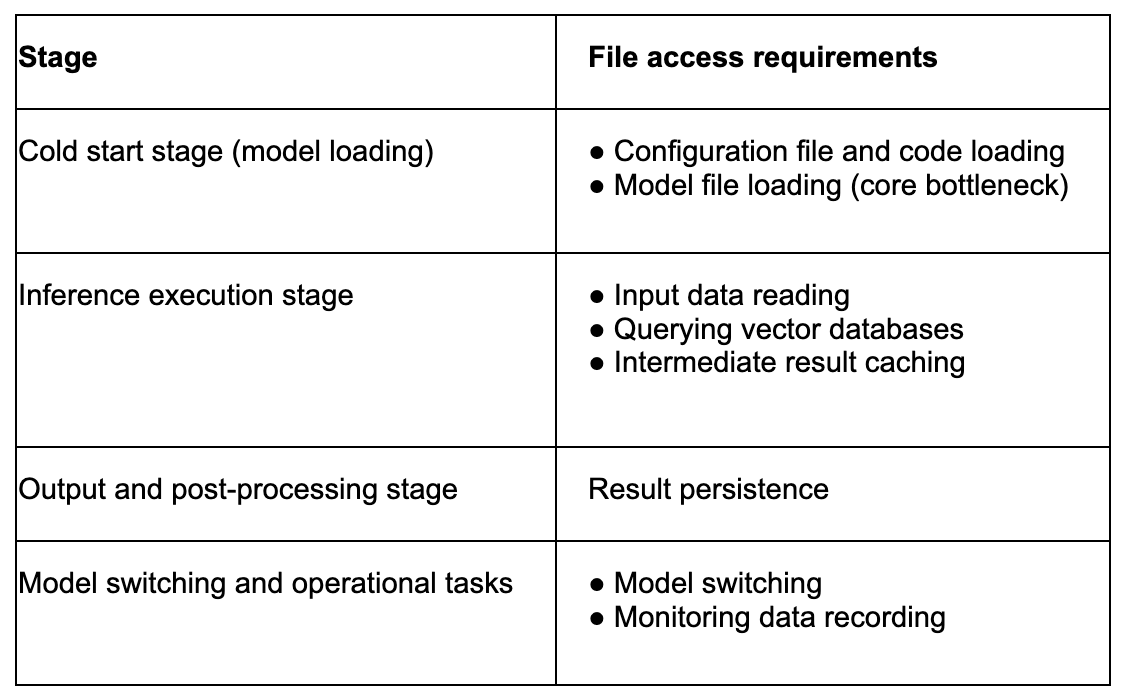
As mentioned, file access requirements are different at each stage. I/O bottlenecks are primarily concentrated during the cold start phase (model loading) and runtime model switching, especially concerning how to efficiently read model files.
Solution 1: Packaging model files into container images
In small-scale inference scenarios, many users package model files, code dependencies, and extension packs into container images and start them via Kubernetes. While this method was once simple, it exposes several issues as inference scale increases:
- Oversized image files: As model files grow larger, container images also become massive, leading to timeouts during image pulls.
- Slow extraction: Container images use layered storage; unpacking each layer is a serial operation. With large models, this unpacking process becomes slow and inefficient.
- Resource waste: If multiple inference services need the same model, sharing the model efficiently is difficult. This leads to frequent download and unpack operations, wasting significant resources.
- Frequent model switching: This approach is even less efficient in scenarios requiring frequent model changes.
Solution 2: Storing model files in object storage
Each inference instance fetches model files from object storage upon startup. While this avoids image pull timeouts, it still faces challenges:
- Bandwidth competition: In large-scale clusters, when multiple inference instances pull models simultaneously, bandwidth contention can occur. This prolongs startup times and affects user experience.
- Inefficiency: Many model file formats (like Safetensors) use mmap for lazy loading. However, object storage doesn't support mmap. This forces the system to download the file locally before reading. This wastes local storage space and reduces read efficiency.
Solution 3: Using a high-performance file system like JuiceFS
Compared to object storage and container images, storing model files in a high-performance file system is a more effective solution. JuiceFS, as an implementation of this solution, offers the following advantages:
- On-demand configuration: Unlike traditional high-performance file systems, JuiceFS allows flexible configuration of performance and capacity independently, avoiding the tight coupling of performance and capacity.
- Multi-cloud data distribution capability: Traditional cloud file systems often lack support for efficient data distribution across cloud environments. JuiceFS possesses cross-cloud distribution capabilities, enabling efficient data distribution across multiple cloud environments, enhancing flexibility. We’ll explain later how JuiceFS is used in multi-cloud architectures.
The figure below shows the improvement in the model file loading process after introducing JuiceFS. When building the container image, we separate the model files from the image, storing them in JuiceFS, while the container image only contains the application code and the basic runtime environment.
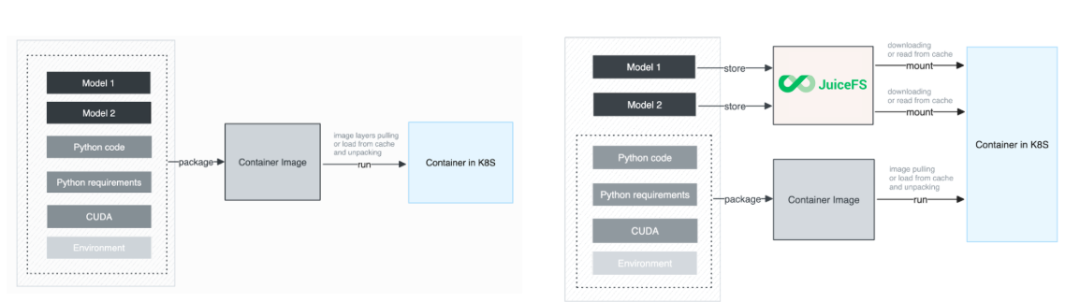
This approach brings significant benefits:
- Model files are decoupled from the image cold start process. This avoids the need to unpack large model layers locally.
- Compared to the object storage solution, during cold start with JuiceFS, there's no need to download the complete model file to the local node, nor load the entire model file (such as Safetensors files). Inference instances can complete cold starts quickly. This on-demand loading mode is particularly critical in elastic scaling scenarios, ensuring new instances start rapidly and begin serving requests promptly. Although the first inference might experience slight latency due to on-demand model loading, the speed for subsequent inference requests is significantly improved.
Beyond these optimizations, JuiceFS further enhances inference service performance through its powerful caching capabilities. In addition to the local cache functionality provided in the Community Edition, JuiceFS Enterprise Edition further offers distributed cache functionality. This allows the construction of large-scale cache pools, centrally storing frequently used model files in the cache, thereby significantly boosting read performance.
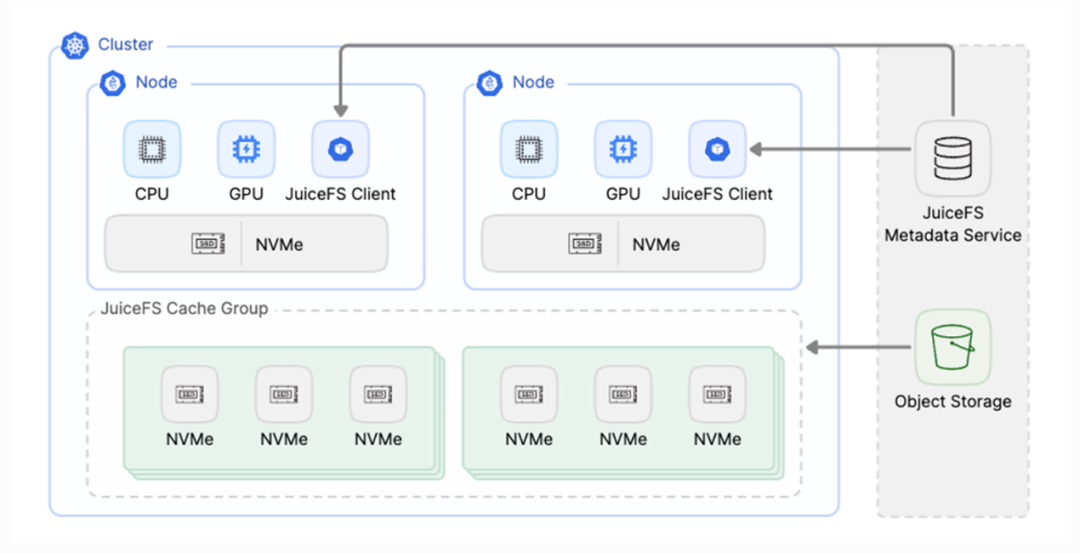
Especially in scenarios involving large-scale instance startups or scaling, such as applications like Stable Diffusion that require frequent model switching, the distributed cache cluster can substantially reduce model loading times. This markedly improves the front-end user experience. The figure below shows the JuiceFS distributed cache architecture. After deploying the inference service, we mount JuiceFS to the inference nodes. When a node reads a model file, it first attempts to retrieve the data from the cache cluster.
Since the cache cluster consists of high-speed media and communication occurs over high-speed internal networks, data retrieval performance is excellent. On a cache miss, the respective cache node fetches the data from the object storage, returns it to the node, and fills the cache. We can also use the warmup command to pre-fill the cache, loading the required model files into the cache layer before nodes start. When inference instances start, all instances hit the model files directly from the cache cluster. This eliminates the need for each instance to pull files individually from object storage and thus avoids bandwidth competition issues on the object storage during high-concurrency file pulls.
Multi-region model file synchronization and consistency management
An increasing number of enterprises are adopting multi-cloud architectures to deploy inference services, flexibly scheduling resources across different cloud providers to optimize cost structures. As shown in the figure below, in a typical inference service deployment case, a customer built infrastructure spanning multiple cloud service providers and data centers to support high-concurrency, low-latency inference requests. A multi-cloud architecture not only effectively mitigates the risk of application interruption from single points of failure but also supports dynamically selecting the most suitable compute nodes based on factors like regional network conditions, resource pricing, and computing power, thus achieving optimal cost control while ensuring performance.
To ensure consistency of inference models and configuration files across different regions, customers typically use object storage in a primary site as a unified model repository, centrally managing model versions and configurations. During the inference task scheduling process, the system can select suitable computing resources based on availability, while model files need to be deployed as close as possible to the computing resources or within high-throughput network environments to improve cold start efficiency and service response speed.
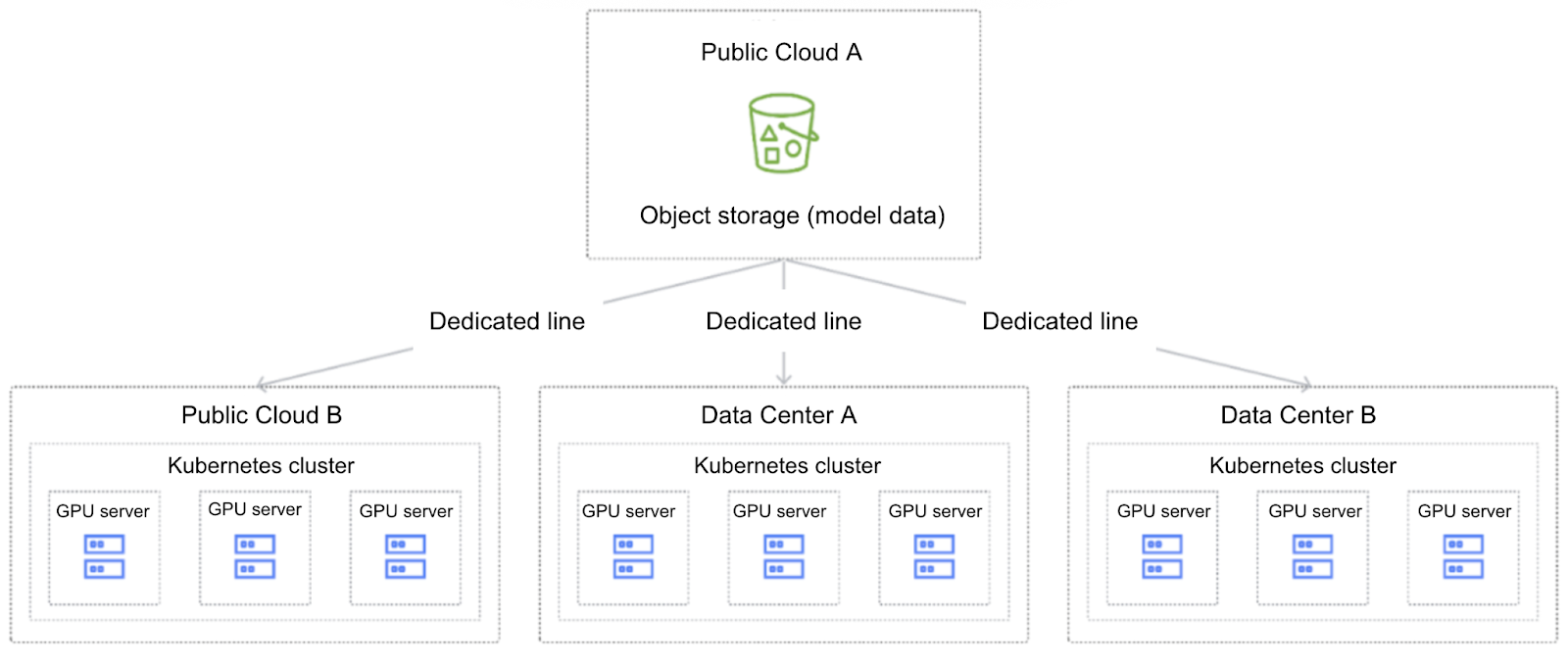
In traditional practice, model files often required manual migration to the scheduled computing cluster. As models iterate frequently, this leads to cumbersome operations and potential data inconsistency issues. Furthermore, inference clusters are typically large-scale. During cold start, concurrent model pulling by nodes can cause bandwidth contention. This creates performance bottlenecks, especially in multi-cloud architectures where model distribution and loading become a significant challenge.
JuiceFS addresses this by using a mirror file system to achieve real-time metadata synchronization from the primary site to various mirror sites. Clients local to each site see a unified file system view. For data files, it offers two schemes regarding whether to perform full synchronization or to cache and load on demand:
- Asynchronous replication: it copies the object storage data completely to multiple sites. Each site prioritizes reading from its local object storage.
- Deploying only a distributed cache layer at the mirror sites without persistent data storage. Required data is warmed up into the cache on demand, thereby improving local read performance.
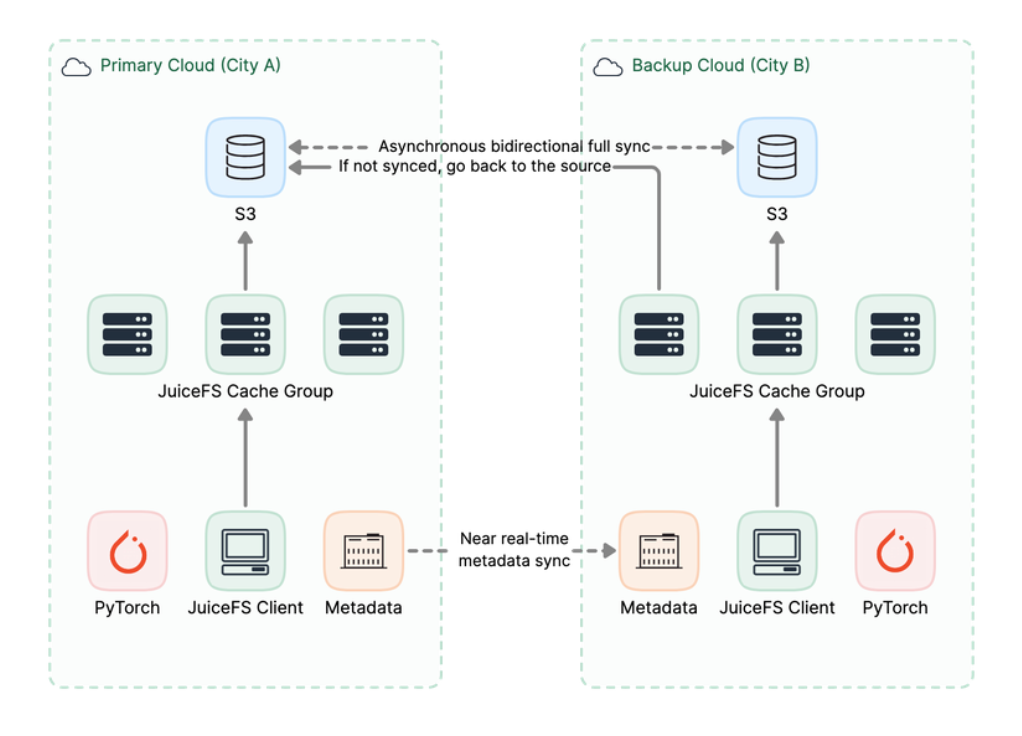
In large-scale inference services, considering cost-effectiveness, users often choose the second scheme, deploying distributed cache locally within the site. A pipeline task is added before node startup and scaling to warm up the required model files in one go into the local site's cache cluster where the computing resources are allocated. This stage essentially performs a single high-concurrency pull of the model files from the object storage.
The benefit is that when a large number of inference services perform cold start simultaneously, they only need to concurrently read the model files from the local domain's cache cluster, without repeatedly pulling from the object storage over the dedicated line. This solves the problem of dedicated line bandwidth bottlenecks caused by high-concurrency repeated pulls from object storage.
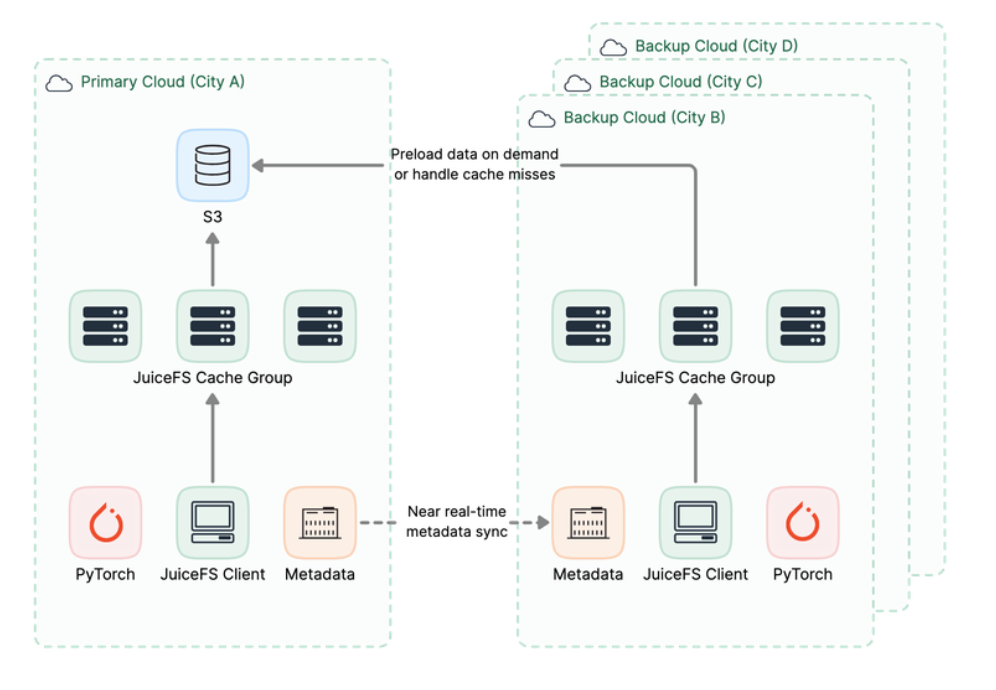
Model version iterations can also be handled through warm-up scripts, pre-loading new versions into the cache while removing expired versions. The entire data distribution and cache warming process is fully handled by the JuiceFS mirror file system feature. This is transparent to the user, avoiding a significant amount of manual data copy work. The benefits brought by the JuiceFS Mirror Filesystem include:
- Cost reduction: Each mirror site only needs to deploy an appropriately sized cache cluster, avoiding the need for excessive capacity configuration.
- Efficiency improvement: The distributed cache uses local high-speed media, providing excellent throughput performance. The network is the local region's internal network, offering good performance.
- Ease of use: No manual intervention in data copying. The unified data view automatically handles data distribution for the user. Even on a cache miss, data is automatically fetched from the object storage.
- Scalability and stability: Resolves bandwidth competition issues during concurrent model file pulls by multiple nodes, enhancing system performance and user experience.
Cloud-native support and cluster management
Inference services typically have bursty and intermittent load characteristics, so they demand high resource elasticity. As the scale of inference services expands, the number and node scale of compute clusters also increase. It often requires scheduling across clusters and regions. This demands that the storage system can easily support deployment in multi-cluster environments.
Furthermore, in elastic environments, the file system needs to ensure transparency to the application during resource expansion, upgrades, or failure recovery, without affecting the normal operation of applications. This means the file system must possess capabilities like automatic failure recovery, resource isolation, and seamless upgrades to ensure application continuity and stability.
JuiceFS provides a range of capabilities to support inference services in cloud-native environments.
- JuiceFS offers a standard Kubernetes CSI Driver. Users can conveniently use PVCs to access the JuiceFS file system in Kubernetes environments, supporting both static and dynamic provisioning. One of its advantages is multi-environment compatibility: to match the resource elasticity needs of inference services, JuiceFS offers multiple operational modes suitable for both standard and serverless Kubernetes environments. Regardless of the elastic load type used by the inference service, JuiceFS deployment is simple and easy.
- In terms of resource optimization, JuiceFS supports multiple applications using the same PVC to share the mounted volume and allows fine-grained definition of resources. This enables optimized resource utilization and isolation between tenants to ensure different tenants do not interfere with each other when using different PVs.
- For stability optimization, JuiceFS supports automatic recovery of mount points and smooth upgrades of Mount Pods. When a Mount Pod fails and needs restarting, or when an upgrade of the CSI Driver or Mount Pod image is required, the application Pod does not need to restart and can continue running normally.
- Regarding automated management, JuiceFS provides various Operators, including features for cache group management, warm-up, and data synchronization. Users can conveniently manage these resources via CRDs, enabling automated operations.
- For visualized monitoring, JuiceFS offers a complete visual management platform, supporting monitoring for both Mount Pods and application Pods. Users can also perform operations like smooth upgrades on the platform, all manageable through a unified interface.
- Many users integrate the Karmada multi-cluster management framework with JuiceFS CSI Driver to achieve unified management of resource scheduling and storage configuration in multi-cluster environments. Thanks to the simplicity of the JuiceFS architecture, the only background service that needs independent deployment is the metadata service. All other features are implemented within the client. Only the client needs deployment on the computing nodes. In complex multi-K8s cluster scenarios, users can use a multi-cluster management control plane like Karmada to distribute JuiceFS-related CRDs to different clusters according to policies. This enables simple storage volume deployment and efficient operations.
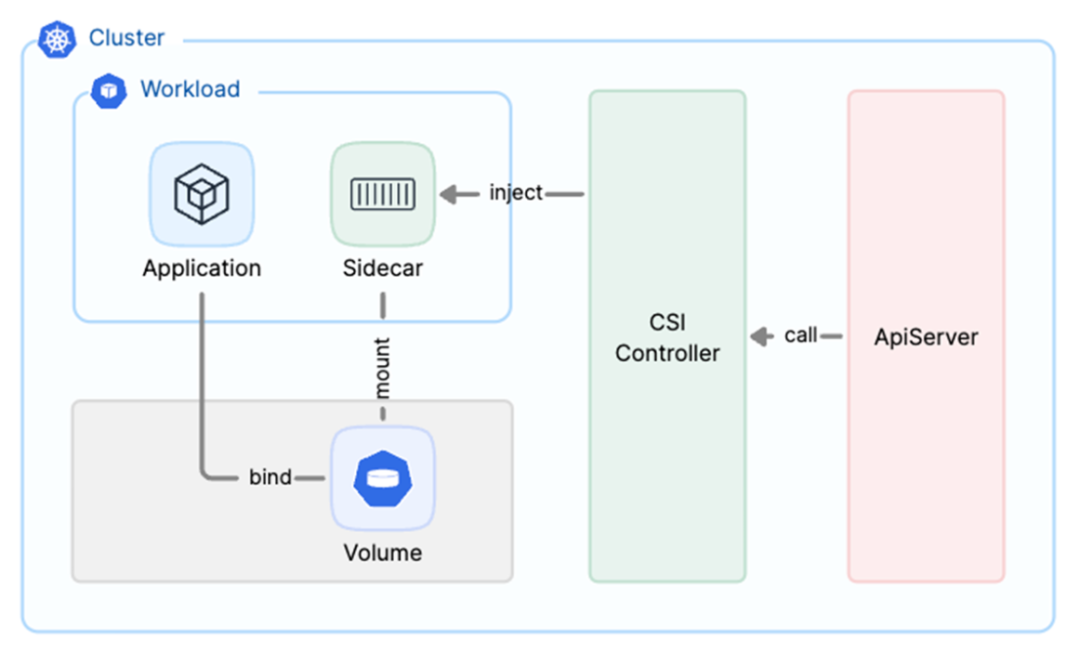
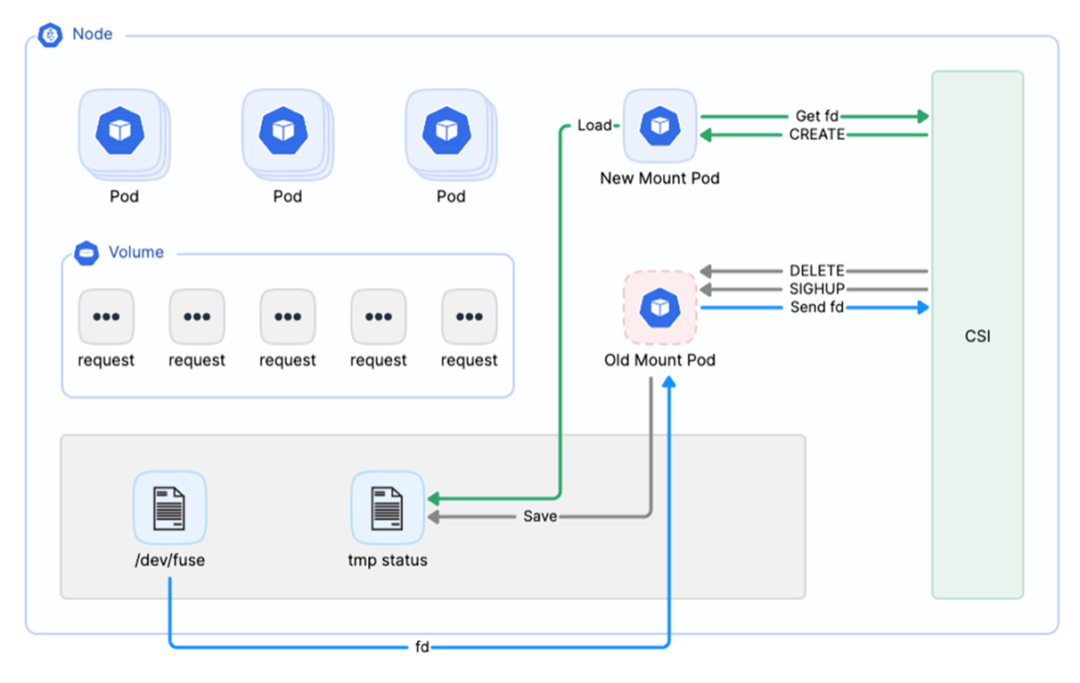
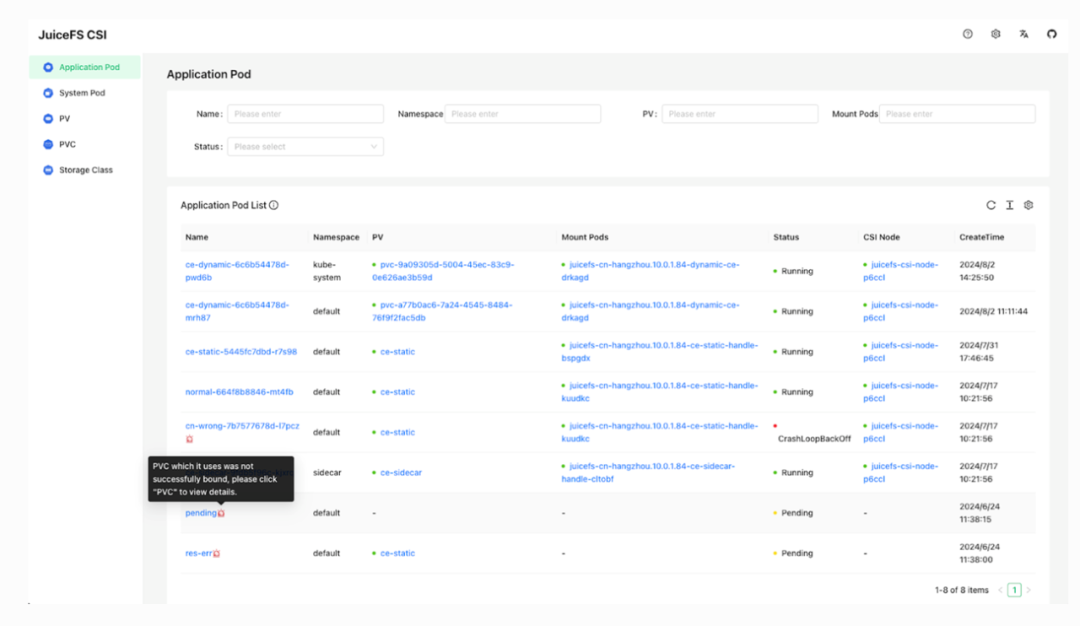
Multi-tenancy and data isolation
In AI inference service scenarios, the demand for multi-tenant data isolation is particularly pressing. On one hand, for AI foundational platforms and AI applications serving external users, requirements for data security and isolation are high. On the other hand, large enterprises also need data isolation and access control between different internal departments and project teams. Overall, requirements in multi-tenant environments mainly include:
- Data isolation & access control: Data needs to be isolated between different tenants, with user-specific access permission management.
- Storage quota management: Storage capacity needs to be allocated and managed for different tenants.
- Resource isolation and performance management: Different tenants may require independent resource isolation, with managed and optimized performance (QoS).
To address these needs, JuiceFS provides three data isolation schemes:
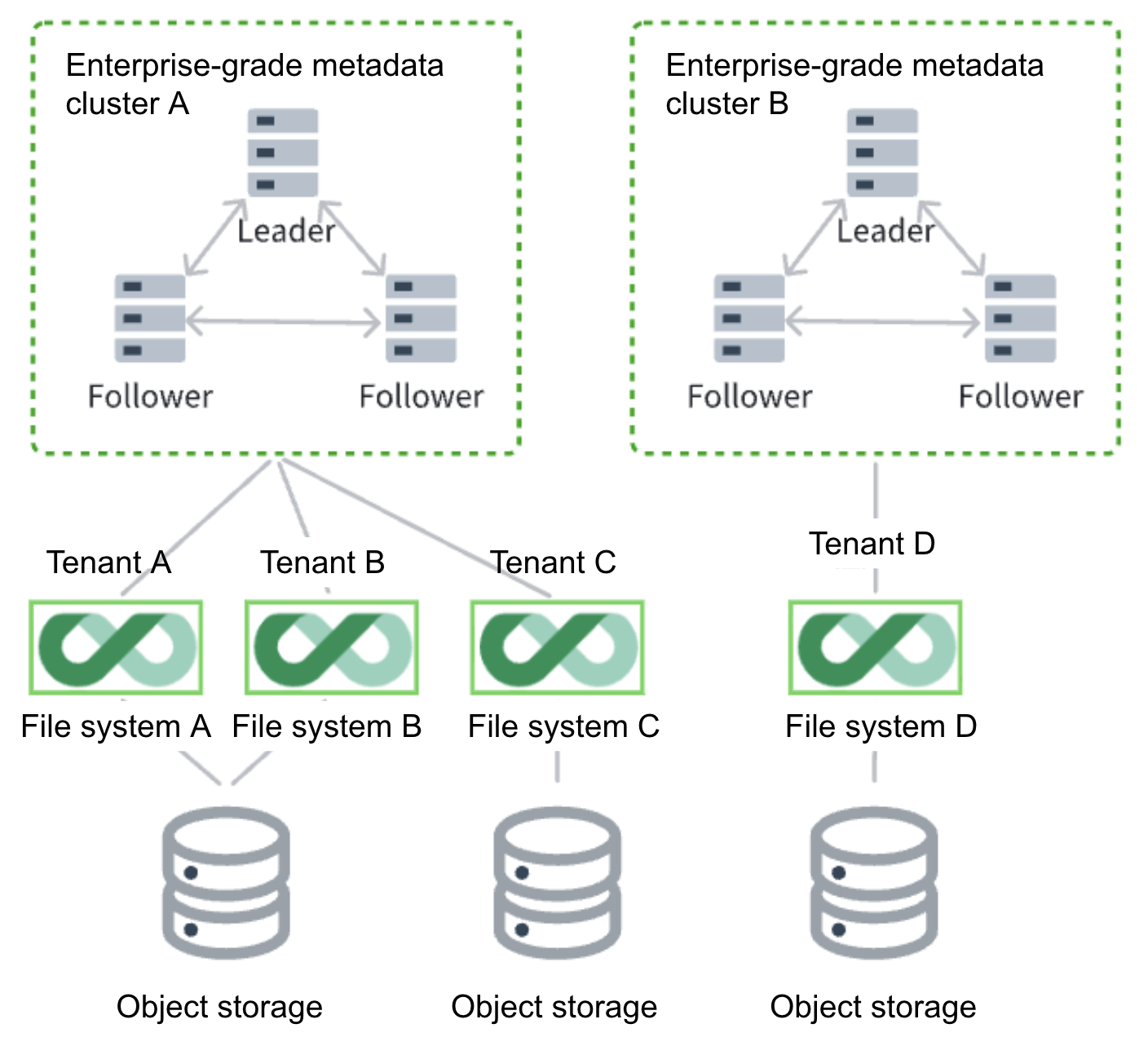
Scheme 1: Isolation via independent file systems
This method allocates different JuiceFS file systems to different tenants for strong data isolation. It means different tenants use their own separate JuiceFS file systems. If further resource and performance isolation is required, the metadata services for the file systems and the associated object storage buckets can be completely isolated. This scheme is generally applicable to tenant environments in AI foundational platforms serving business customers (toB). These tenants typically have large-scale application requirements and high demands for service quality. This scheme fully ensures the tenant's data access performance is unaffected by load from other tenants sharing resources. Furthermore, data is physically completely isolated, providing the highest level of security assurance.
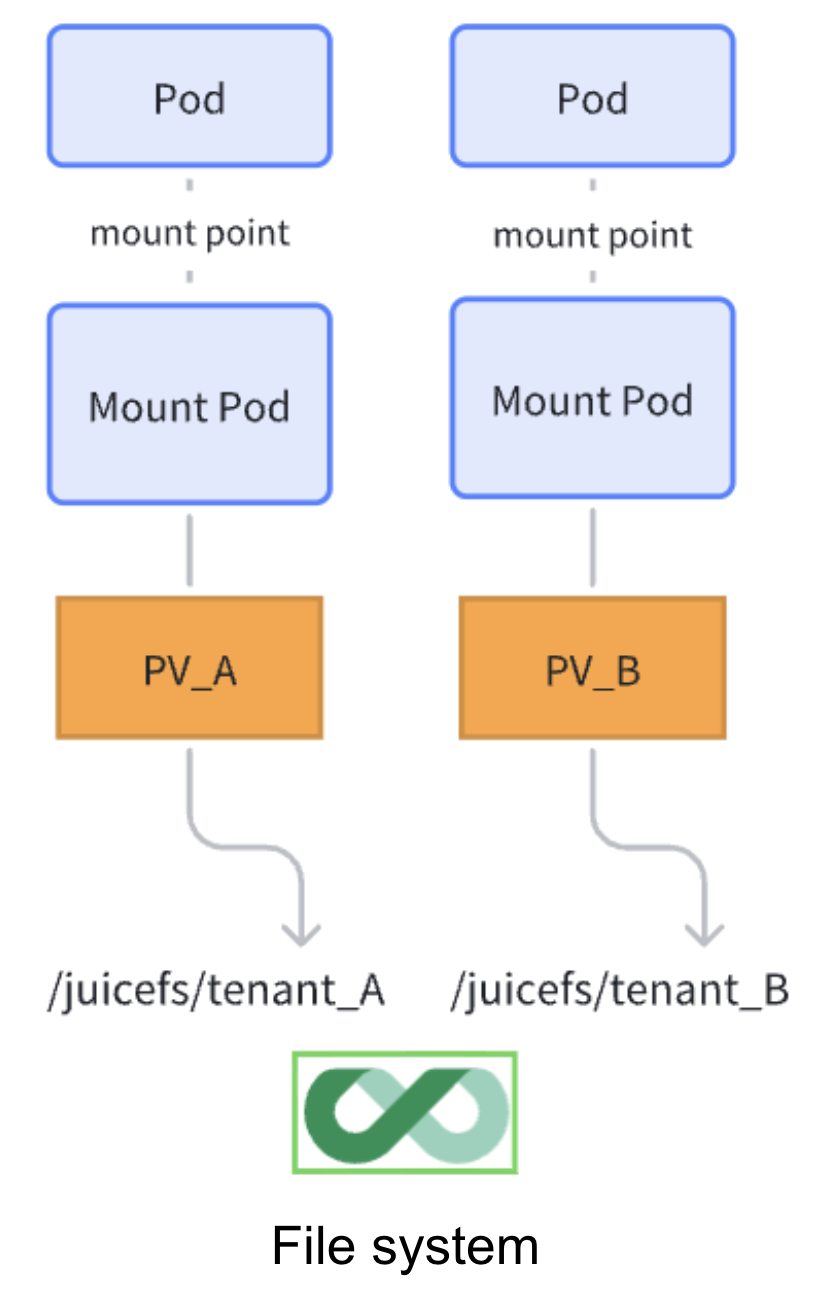
Scheme 2: Subdirectory isolation within the same file system
This scheme allocates different subdirectories on the same file system to different tenants. Subdirectories are invisible to each other. Access control for mounting subdirectories can be enforced using JuiceFS' tokens, strictly ensuring data isolation between subdirectories. This scheme is more commonly used in tenant environments like AI foundational platforms serving consumers (toC), or for data isolation needs between different project teams within an enterprise.
In K8s environments, JuiceFS CSI Driver, by default, allocates different subdirectories on the file system for dynamically provisioned PVCs, and different PVCs do not reuse the JuiceFS client by default. This achieves data isolation for different applications while allowing separate resource control and parameter optimization for each application client. Of course, in non-K8s environments, data security can also be ensured by using tokens to control client mounting permissions for subdirectories. In this scheme, the chunk data in object storage is not isolated, but these JuiceFS chunks cannot be read directly as original file content from the object storage, so there is no risk of data content leakage.
Scheme 3: Fine-grained access control based on POSIX ACL
Based on Linux ACL, JuiceFS Enterprise Edition extends group permission control capabilities. Each file can have permissions set separately for different groups. Combined with the UID/GID mapping feature, consistent ACL permission management can be achieved even across different nodes, as long as the usernames and group names are consistent. This scheme is suitable for small-scale users requiring fine-grained access control over individual directories or files. It has high configuration complexity and limited use cases.
Furthermore, JuiceFS Enterprise Edition provides two key features supporting multi-tenant management:
- Client access tokens: Used to authorize client access to the file system. It can control access IP ranges, read/write permissions, subdirectory mount permissions, and permissions for clients to perform background tasks. It can also limit object storage access traffic, implementing quota or rate limiting management.
- Quota management: Allows allocation of storage capacity and file count quotas for each subdirectory. Combined with the subdirectory data isolation scheme, this enables precise control over storage resource usage for each tenant.
Comparison of different storage solutions for inference services
In practical applications for inference services, different types of storage solutions have significant differences in performance, stability, scalability, and cost. The following section analyzes and compares several typical categories to help enterprises evaluate their suitability more comprehensively:
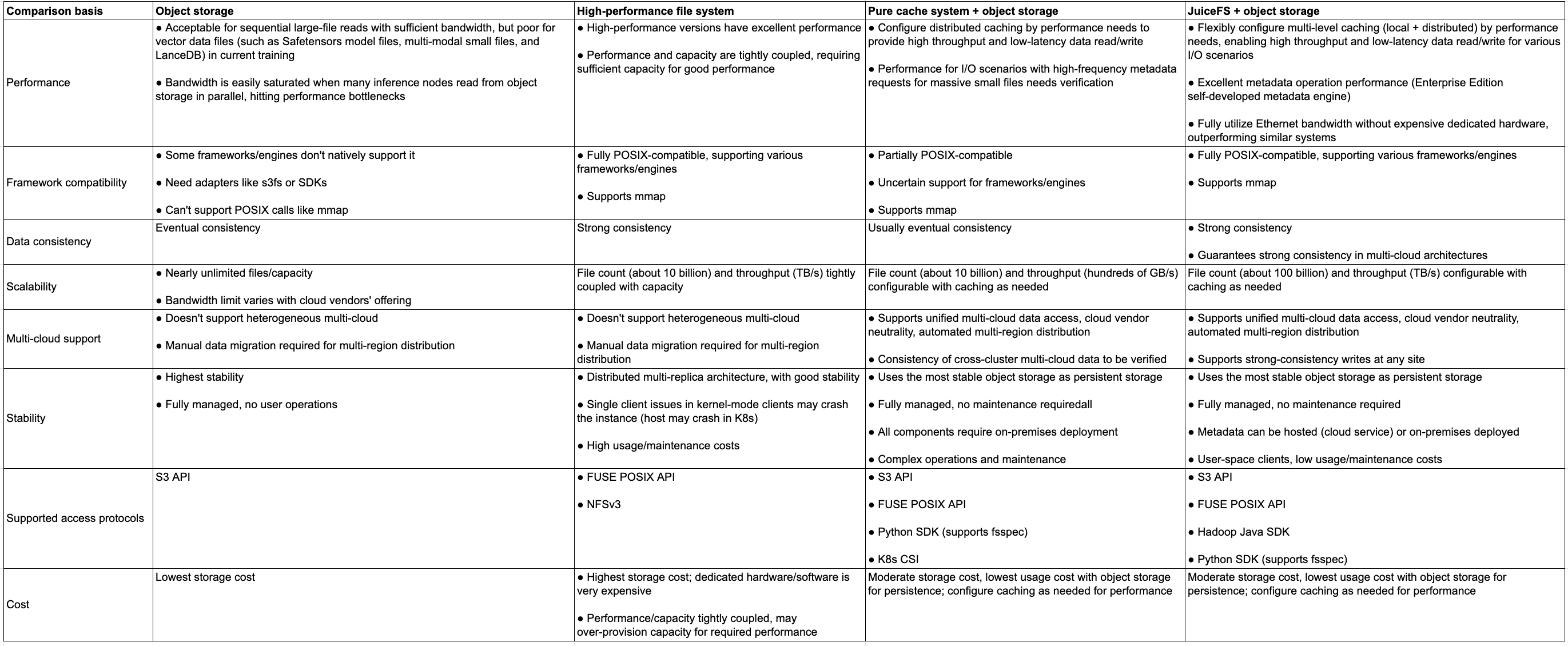
- Object storage is a low-cost solution suitable for scenarios involving sequential reads of large files. However, its performance is poor when handling small files, model files (like Safetensors format), and multi-modal data frequently used in inference tasks. When multiple inference nodes read data in parallel, the bandwidth of object storage can easily be exhausted. This leads to performance bottlenecks. While it supports eventual consistency and nearly unlimited storage capacity, it lacks optimization for high concurrency and small file access and does not support automated data distribution across heterogeneous multi-cloud environments.
- High-performance file systems offer higher performance, especially suitable for scenarios with high demands on computing resources and performance. They fully support POSIX-compliant frameworks and provide strong consistency. However, they often tightly couple performance and capacity, requiring large storage capacities to achieve optimal performance. While generally stable, because the client deploys in kernel space, a single client failure can potentially crash the entire system. Operational costs are also high.
- Pure cache systems + object storage is a compromise, configuring distributed cache to provide high throughput and low-latency read/write performance. However, their performance in scenarios involving massive small files and high-frequency metadata requests needs further validation. This type of solution is hard to guarantee strong data consistency in multi-cloud/multi-region architectures.
- JuiceFS + object storage provides a multi-tier caching architecture, allowing flexible configuration of local and distributed cache. It can deliver high throughput and low-latency data read/write performance, particularly suitable for the high-concurrency, low-latency demands of inference services. It not only supports efficient metadata operations but also fully utilizes Ethernet bandwidth without relying on expensive proprietary hardware, ensuring excellent performance among similar systems. JuiceFS also possesses strong consistency and supports automated data distribution in multi-cloud environments, guaranteeing consistency across regions and clusters.
- From a scalability perspective, JuiceFS supports up to 100 billion files and TB/s level throughput, configures cache on-demand, and scales massively. Object storage is suitable for scenarios with virtually unlimited file count and capacity, but its bandwidth is limited by the cloud provider's offerings. The scalability of high-performance file systems is often constrained by the tight coupling of performance and capacity.
The table below is a comparison summary of different storage solutions:
Summary
Compared to training tasks, inference services impose different and more stringent requirements on infrastructure. They especially emphasize low-latency response, high-concurrency access, resource isolation, and flexible scalability. Therefore, selecting an appropriate storage solution has become a key decision point for enterprises deploying AI inference systems.
This article has outlined the core storage requirements and typical practical challenges in inference scenarios, covering extensive random access during model cold starts, high-concurrency reads of small files, multi-modal data processing, resource sharing among multiple tenants, and complex scenarios like cross-region multi-cloud deployment. Based on JuiceFS' practical implementation experience with numerous inference users, we’ve proposed a series of optimization strategies to address these challenges.
The article also compared current mainstream storage solutions—including object storage, high-performance file systems, pure cache systems, and the architecture combining JuiceFS with object storage—helping users make more targeted selection judgments from multiple dimensions such as performance, stability, scalability, and cost.
With its elastically scalable architecture, excellent I/O performance, and strong cloud-native compatibility, JuiceFS has become a stable choice for inference services in many enterprises. We hope this article can provide practical selection reference and architectural insights for more enterprises building or expanding their inference capabilities, assisting them in moving forward robustly in the increasingly complex landscape of AI applications.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.