















On August 5, the global authoritative AI engineering consortium MLCommons released the latest MLPerf® Storage v2.0 benchmark results. This evaluation attracted numerous vendors, including those from categories such as cloud, shared file, fabric-attached block, and direct-attached block storage.
Due to differences in hardware configurations, node scales, and application scenarios among vendors, direct cross-vendor comparisons have limitations. Therefore, this article will focus on the shared file system category, analyzing their performance under the same testing standards.
JuiceFS is a high-performance distributed file system supporting both cloud and on-premises deployments. Across multiple AI training workloads, JuiceFS achieved excellent results, particularly leading in bandwidth utilization and scalability. In this article, we’ll analyze the specific test results and further introduce the key features underpinning this performance.
MLPerf Storage v2.0 and its workloads
MLPerf is a universal AI benchmark suite launched by MLCommons. MLPerf Storage simulates real AI workload access to storage systems through multiple clients. It replicates storage loads in large-scale distributed training clusters to comprehensively evaluate the practical performance of storage systems in AI training tasks.
The latest 2.0 version includes three types of training workloads, covering the most representative I/O patterns in deep learning training.
- 3D U-Net (medical image segmentation): This workload involves sequential and concurrent reads of large-volume 3D medical images. Each sample averages about 146 MB and is stored as an independent file. This task primarily tests the storage system's throughput in large-file sequential read scenarios and its ability to maintain stable responsiveness under concurrent multi-node access.
- ResNet-50 (image classification): This workload is characterized by highly concurrent random reads of small samples. Each sample averages only 150 KB, with data packaged and stored in large files using TFRecord format. This data organization leads to significant random I/O and frequent metadata access during training. It places extremely high demands on the storage system's IOPS. It’s a crucial test for measuring concurrent performance in small-file scenarios.
- CosmoFlow (cosmology prediction): This workload emphasizes concurrent small-file access and bandwidth scalability across nodes. Each sample averages 2 MB, typically stored as individual files in TFRecord format. As it involves distributed reading of massive numbers of small files, the system requires sufficient aggregate throughput and must demonstrate stability in metadata handling and tail latency control. Otherwise, as nodes increase, latency fluctuations will significantly amplify and slow down overall training speed.
| Task | Reference network | Sample size | Framework | I/O pattern |
|---|---|---|---|---|
| Image segmentation (medical) | 3D U-Net | 146 MiB | Pytorch | Simulates sequential/concurrent reads of large-volume 3D data |
| Image classification | ResNet-50 | 150 KiB | Tensorflow | Represents highly concurrent random reads of massive small images |
| Scientific (cosmology) | CosmoFlow | 2 MiB | Tensorflow | Highly concurrent reads of vast numbers of small files |
In addition, the 2.0 version introduces a new checkpointing workload to simulate checkpoint saving and recovery in large model training. This workload primarily involves concurrent sequential writes of large files. In the JuiceFS architecture, checkpoint data is written through JuiceFS to object storage. Its performance bottleneck depends on the bandwidth limit of the object storage serving as the persistent data layer.
Performance comparison: product categories, elastic scalability, and resource utilization
Numerous vendors participated in this MLPerf Storage v2.0 test, involving various types like block storage and shared file systems. However, due to significant architectural and application scenario differences, coupled with different hardware configurations and node scales used by vendors, a direct horizontal comparison has limited value.
In this article, we’ll focus on results within the shared file system category. This category can be further subdivided:
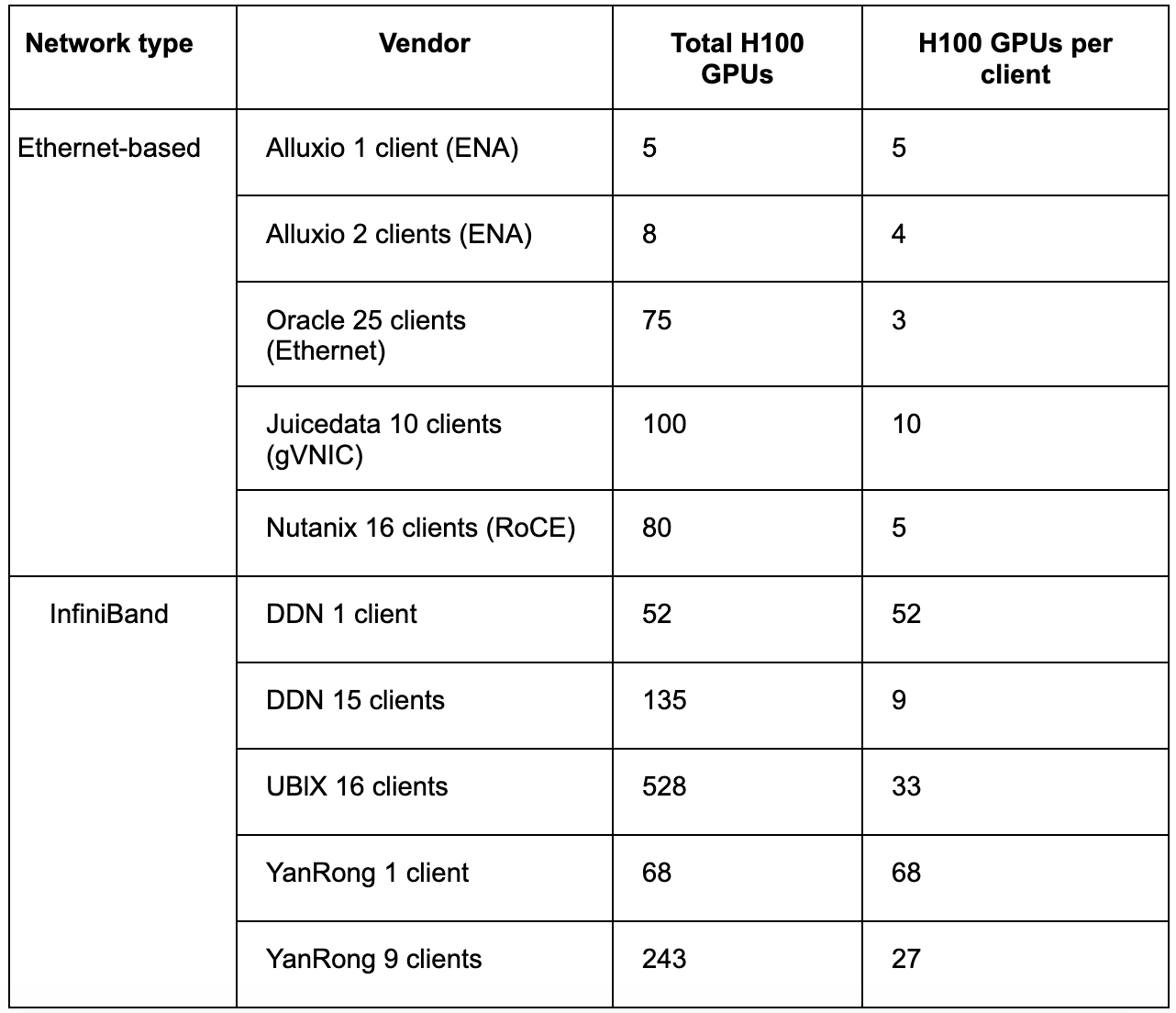
- Ethernet-based systems: This group includes Alluxio, JuiceFS, and Oracle. These cloud systems rely on Ethernet environments to provide distributed storage capabilities. Some vendors, like Nutanix, used RoCE-based Ethernet solutions, typically with higher-bandwidth NICs per instance.
- InfiniBand-based storage solutions: Vendors like DDN, Hewlett Packard, and Ubix offer complete storage appliances based on InfiniBand networks. These systems feature very high hardware specifications and overall cost, delivering extremely high bandwidth and performance.

Before we explain the results, let's clarify the evaluation criteria.
MLPerf Storage documentation requires submitted results to meet a GPU utilization threshold while maximizing the number of GPUs (scale). The thresholds are 90% for 3D U-Net and ResNet-50, and 70% for CosmoFlow. Given these thresholds are met, the key metric that truly differentiates performance is the maximum number of GPUs a storage system can support. This scale is essentially determined by the system's maximum aggregate bandwidth. A system supporting more GPUs indicates stronger scalability and stability in large-scale training scenarios, especially crucial in workloads like CosmoFlow which involve vast numbers of small files and are highly latency-sensitive.
Comparison should consider resource utilization. For software vendors, the key is whether the storage software can fully leverage the potential of the underlying hardware. As the network bandwidth is often the bottleneck for storage systems, we use NIC bandwidth utilization as a reference metric: higher utilization indicates greater software efficiency and implies higher performance and cost-effectiveness for a given hardware configuration.
JuiceFS test results
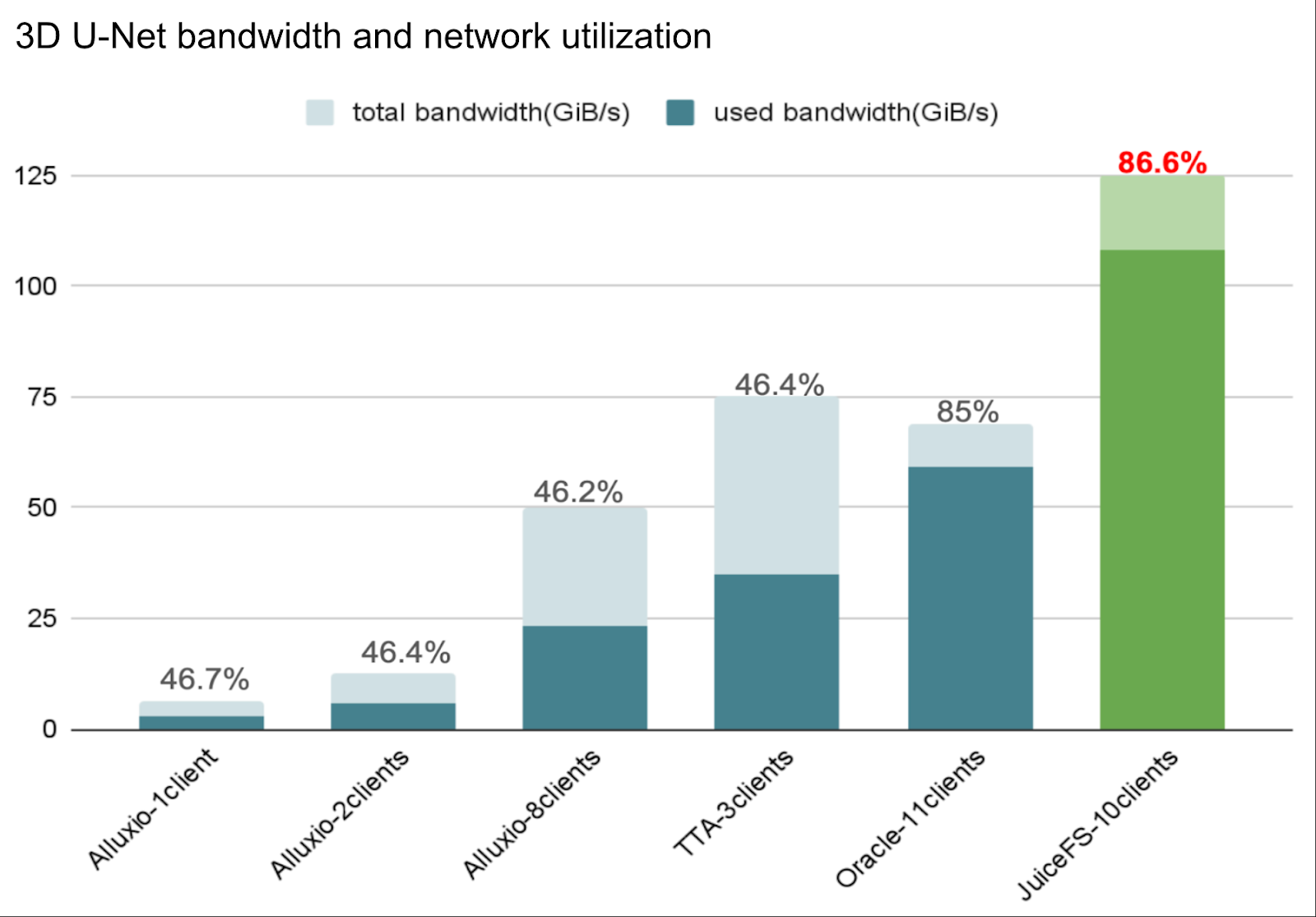
- 3D U-Net workload: JuiceFS achieved a data read bandwidth of up to 108 GiB/s, supporting a training scale of 40 H100 GPUs across 10 nodes. The network bandwidth utilization reached 86.6%, and the GPU utilization was 92.7%.
- CosmoFlow workload: JuiceFS supported a training scale of 100 H100 GPUs across 10 nodes, with a GPU utilization of 75%. This workload places extreme demands on storage latency stability and has lower network bandwidth requirements. The performance bottleneck is not bandwidth. Handling massive concurrent small-file access means that I/O latency and stability determine overall scalability and limit GPU utilization.
- ResNet-50 workload: JuiceFS achieved a data read bandwidth of 90 GiB/s, with a network bandwidth utilization of 72% and an overall GPU utilization of 95%.
Note: The maximum number of stable elastic instances available in a single zone on the chosen GCP instance type for this test was limited. Therefore, our submitted maximum scale was 10 nodes. This does not represent the maximum capacity of the JuiceFS system, which can provide higher aggregate bandwidth and support larger training scales with more nodes.
Background: GPU scale limited by storage network bandwidth capacity
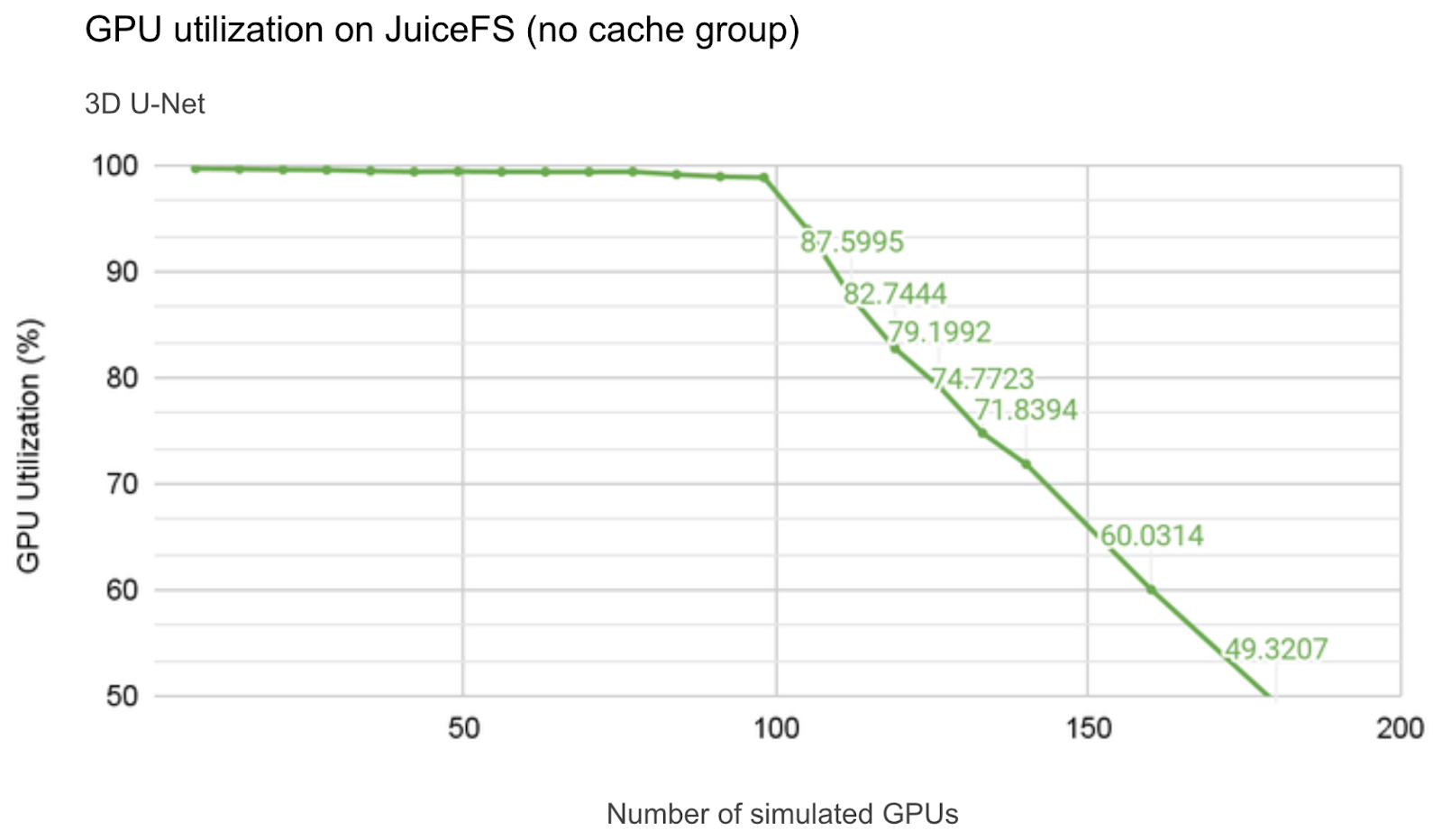
JuiceFS has been participating in MLPerf tests for three years. In the first year, based on the 0.5 version, we conducted full tests using V100 GPUs for simulation.
Because the per-GPU bandwidth requirement of V100 is low, the GPU utilization remained near 99% for a long interval. It slowly decreased to about 98% as the training GPU scale increased. Only when the total bandwidth approached the NIC bandwidth limit, the inflection point occurred. After that, utilization dropped rapidly with additional GPUs. For detailed analysis, see 98% GPU Utilization Achieved in 1k GPU-Scale AI Training Using Distributed Cache. According to the data in the figure below, at 90% GPU utilization, about 110 V100 GPUs could be supported. This scale limit is primarily constrained by the storage network's bandwidth capacity.
3D U-Net: JuiceFS leads peer systems with highest bandwidth and utilization
The 3D U-Net training workload involves large-file sequential reads, demanding high read bandwidth from the storage system.
The figure below clearly shows that among all storage systems based on conventional Ethernet, JuiceFS performed best: achieving 108 GiB/s data read bandwidth at a scale of 10 nodes (40 H100 GPUs), with a network bandwidth utilization of 86.6%, both the highest among comparable systems. This indicates JuiceFS not only provides higher total bandwidth but also utilizes network and hardware resources more efficiently, offering significant cost-performance advantages.
The following section shows results from participants using InfiniBand networks and RDMA over Converged Ethernet (RoCE). These vendors' hardware specifications are generally very high, with minimum total network bandwidth about 400 GiB/s, and the highest exceeding 1,500 GiB/s. Consequently, they can provide extremely high aggregate bandwidth for training workloads. It’s worth noting that JuiceFS can achieve similar bandwidth levels after elastically scaling the number of distributed cache nodes. In recent tests, an aggregate read bandwidth of 1.2 TB/s was achieved based on a distributed cache cluster of 100 GCP 100 Gbps nodes.
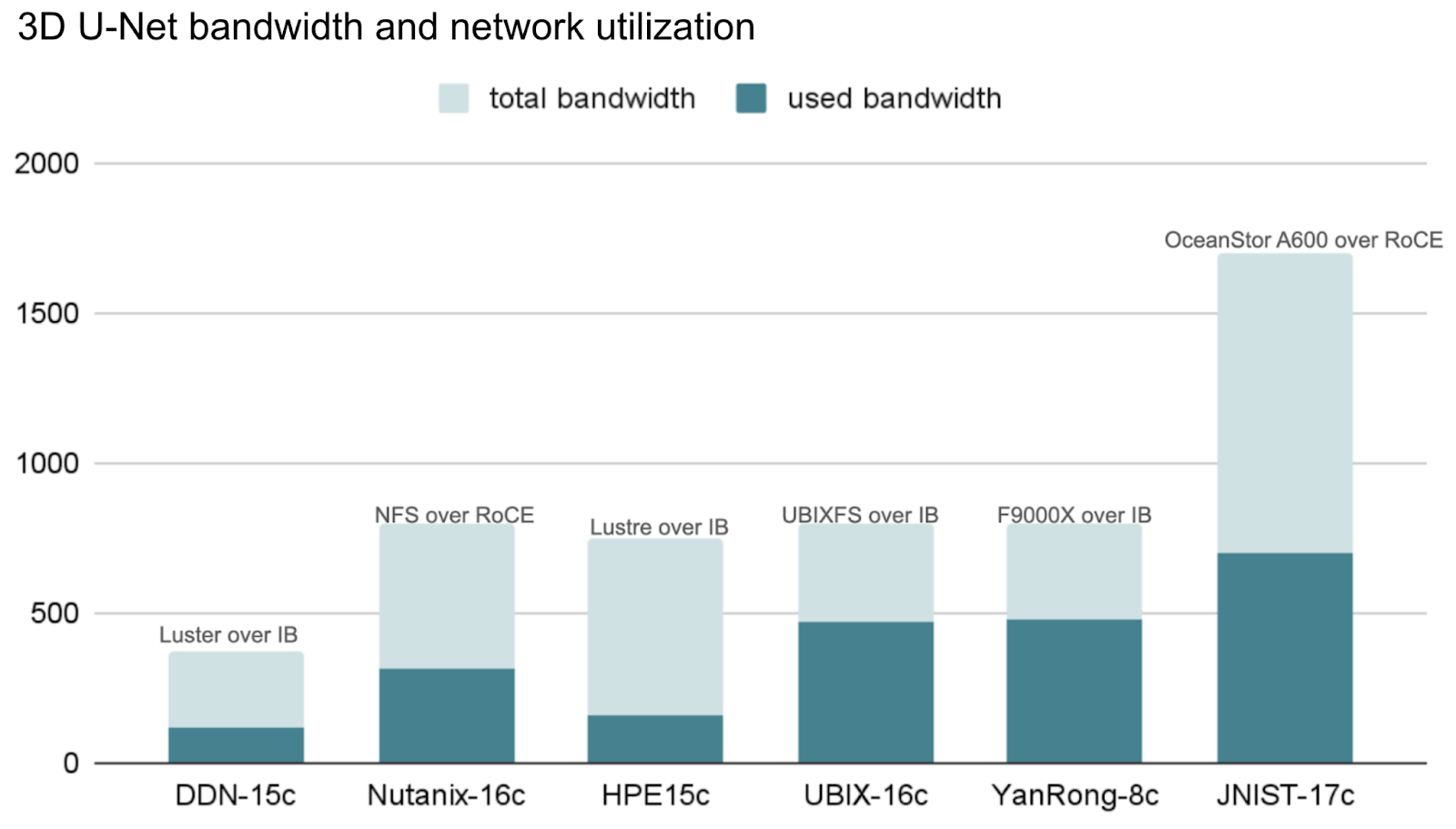
From a utilization perspective, as per-NIC bandwidth increases, achieving high bandwidth utilization becomes increasingly challenging. Achieving utilization close to 80% is very difficult with 400 Gb/s or higher NIC configurations.
CosmoFlow: JuiceFS supports hundred-GPU scale, leading in scalability
The CosmoFlow training workload requires reading vast numbers of small files. This places extreme demands on the storage system's metadata performance and read latency. The test requires GPU utilization to be above 70%. Due to the high latency sensitivity, as the number of H100s increases, the read latency variance in multi-node distributed training increases significantly, causing GPU utilization to drop rapidly and making horizontal scaling difficult. Compared to 3D U-Net, fewer total results were submitted for CosmoFlow. This reflects the greater optimization challenge this workload presents.
The chart's x-axis represents the total number of GPUs supported, that is, the number of H100 GPUs. JuiceFS continues to lead among comparable systems. Running simultaneously through 10 clients, it successfully supported the CosmoFlow training task with 100 H100 GPUs, maintaining GPU utilization above the required threshold.
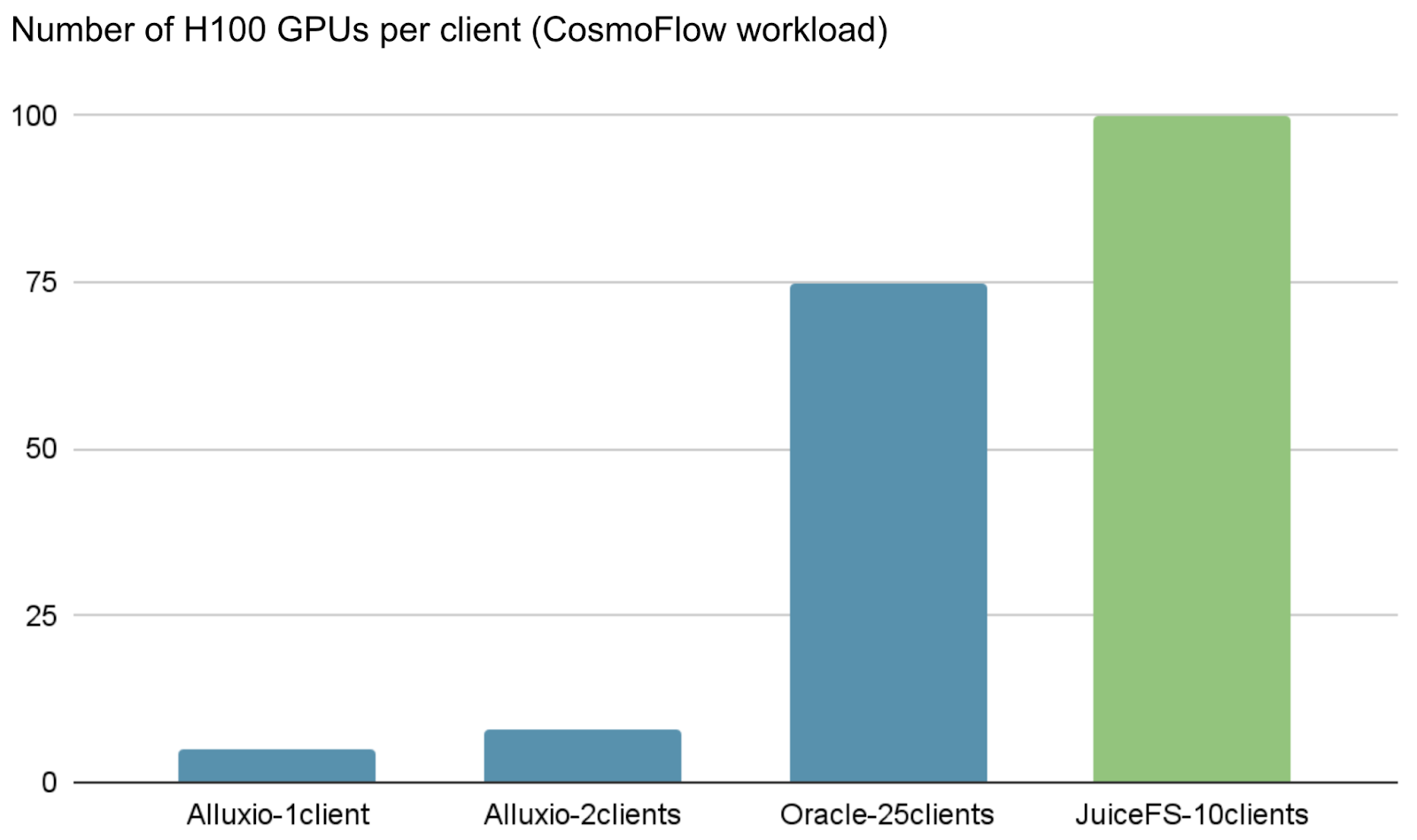
Systems based on InfiniBand networks performed particularly well in this workload. This benefits from the end-to-end extremely low and highly stable latency systematically provided by InfiniBand networks. Despite their higher cost, the performance advantage of InfiniBand networks is significant for latency-sensitive tasks.
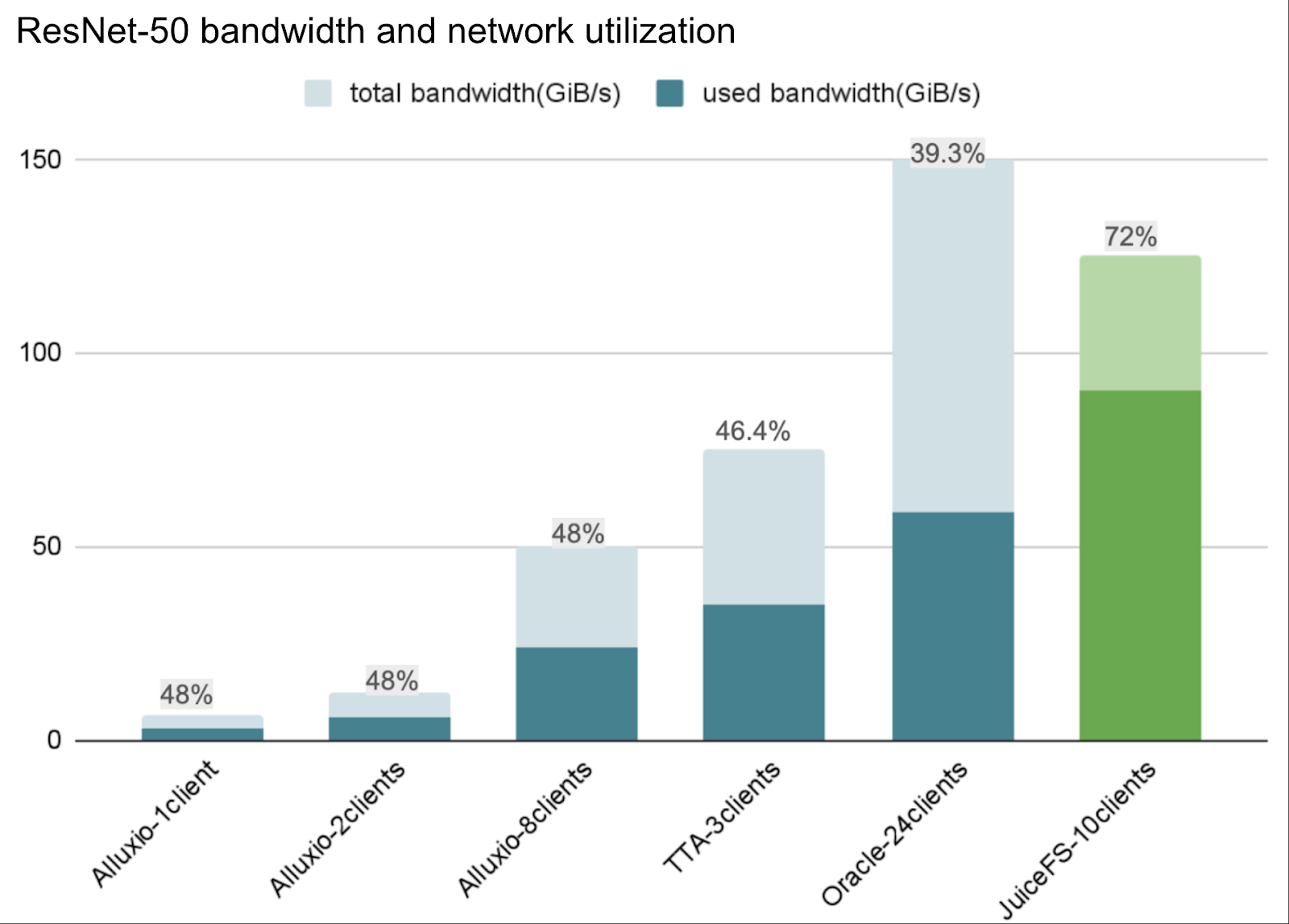
ResNet-50: JuiceFS supports the most H100s, achieving highest bandwidth utilization
The ResNet-50 training workload involves highly concurrent random reads within large files, demanding extremely high IOPS from the storage system and requiring GPU utilization to stay above 90%.
In this test, JuiceFS supported the largest number of 500 H100 GPUs among comparable systems and achieved the highest network bandwidth utilization (72%) among all Ethernet-based solutions, far exceeding the approximately 40% level of other vendors. Simultaneously, GPU utilization remained at 95%. This result demonstrates that under high-concurrency random I/O scenarios, JuiceFS can fully leverage its software optimizations to efficiently utilize hardware resources, exhibiting leading performance and efficiency.
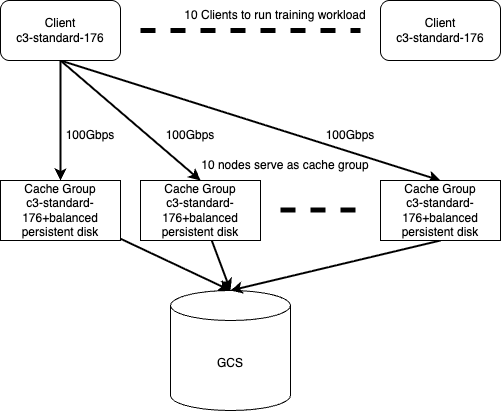
JuiceFS system configuration in the MLPerf test
The JuiceFS system topology in this test consisted of three main layers:
- The client layer: The top layer consisted of 10 client nodes, all running on the same GCP instance type, with the same bandwidth configurations per node. This ensures client-side balance.
- The cache cluster layer: The middle layer was the cache cluster, comprising 10 cache nodes. These nodes used cloud disks combined with local memory as cache to accelerate data access.
- The cold data storage layer: Data was ultimately stored in Google Cloud Storage (GCS).
Before training started, cold data was warmed up from GCS to the cache cluster. During training, clients read data from the cache cluster. This approach avoids accessing high-latency object storage during training, providing stable high bandwidth and low-latency access to meet the sustained data demands of large-scale AI training.
The MLPerf Storage v2.0 rules allowed for an additional "warm-up test" round. Thus, even systems without an active warm-up feature could load data into cache before the official test, ensuring fairness. In addition, all participants could benefit from performance gains offered by page cache. This is critical for latency-sensitive workloads like CosmoFlow.
In the current configuration, 10 clients and the cache cluster could support a training scale of about 40 H100 GPUs. If the training scale increases further, for example, doubling the number of GPUs, simply scaling the cache cluster nodes proportionally can match the new bandwidth requirements. This architecture demonstrates high flexibility and elasticity, adaptable to larger-scale training tasks.
The strong performance of JuiceFS in this test relies firstly on its high-performance metadata engine. This engine delivers very high IOPS and extremely low latency, with integrated metadata caching on the client, significantly reducing access latency. This capability is particularly critical for the CosmoFlow workload, which involves massive concurrent small-file access and is highly latency-sensitive. Stable low latency ensures high GPU utilization and overall scalability.
Another key advantage is the distributed cache. A test shows that the JuiceFS cache cluster can provide up to 1.2 TB/s of aggregate bandwidth (based on 100 GCP 100 Gbps nodes, scale limit constrained by instance availability in the selected GCP zone) and reduce access latency to sub-millisecond levels. The cache cluster supports elastic scaling, providing extremely high performance in bandwidth and allowing expansion of IOPS and bandwidth according to task needs. In the ResNet-50 workload, JuiceFS' high IOPS performance was decisive. JuiceFS stood out in the Ethernet-based comparison relying on its IOPS advantage, achieving 72% bandwidth utilization and maintaining 95% GPU utilization.
Summary
In this article, we analyzed the results of the MLPerf Storage v2.0 test. Before evaluating a storage product's GPU utilization, users must understand the product type, including its architecture, hardware resources, and cost. Assuming GPU utilization thresholds are met, the key difference among storage systems is the maximum number of GPUs they can support. A system supporting more GPUs indicates better scalability and stability in large-scale training scenarios. Furthermore, resource utilization must be considered—whether the storage software can fully leverage the potential of the underlying hardware.
JuiceFS demonstrated stable low latency and high resource utilization across different AI training workloads in these tests. As a fully user-space, cloud-native distributed file system, it utilizes a distributed cache to achieve high throughput and low latency, while leveraging object storage for cost advantages. It presents a viable option for large-scale AI training that does not rely on expensive proprietary hardware.