















With the explosive growth of data volume and model scale, scenarios where multiple clients frequently access the same data have become increasingly common. Distributed caching aggregates the local caches of multiple nodes to form a large-capacity cache pool. This improves cache hit rates, enhances read bandwidth and IOPS, reduces read latency, and meets high-performance demands.
However, data exchange between nodes heavily relies on network performance. Insufficient bandwidth can limit data transfer speeds and increase latency; high network latency can affect cache responsiveness and reduce system efficiency; meanwhile, the CPU resources consumed by network data processing can also become a bottleneck, constraining overall performance.
To address these issues, the recently released JuiceFS Enterprise Edition 5.2 introduces multiple optimizations for network transmission between cache nodes. This effectively resolves some performance-intensive aspects and improves network interface card (NIC) bandwidth utilization. After optimization, client CPU overhead was reduced by 50%+, and cache node CPU overhead dropped to one-third of pre-optimization levels. The aggregate read bandwidth reached 1.2 TB/s, nearly saturating the TCP/IP network bandwidth (based on a distributed cache cluster of 100 GCP 100 Gbps nodes).
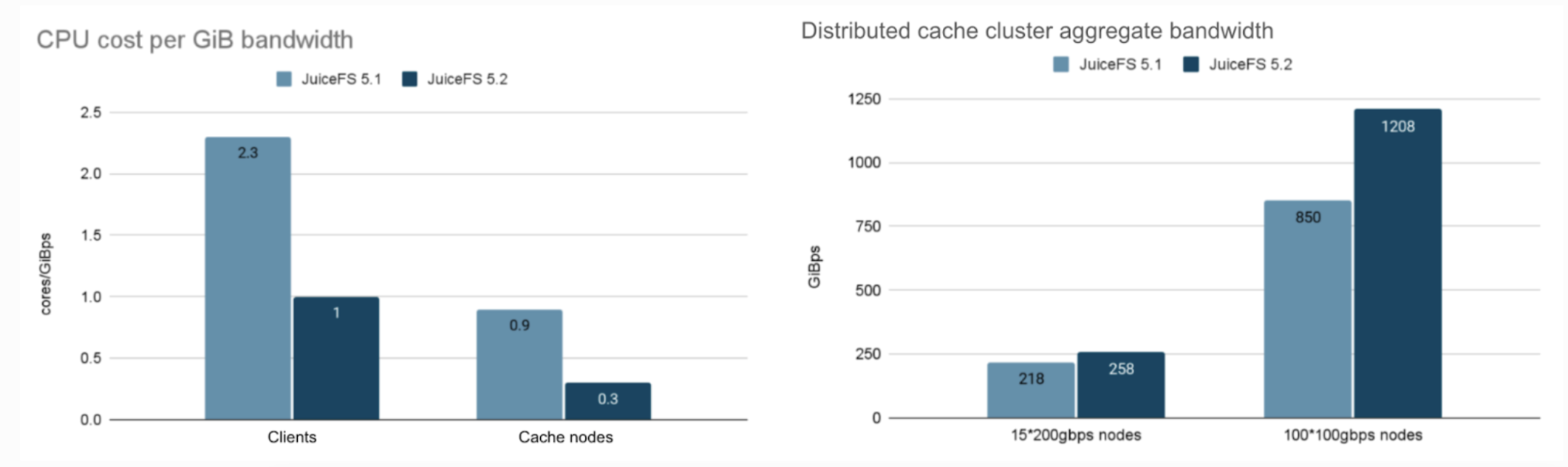
As the most widely supported network standard, the TCP/IP protocol can be used almost everywhere out-of-the-box. With built-in congestion control and retransmission mechanisms, it achieves sufficiently high performance and stability in complex networks. This makes it the preferred choice for distributed caching. Currently, JuiceFS can fully saturate 100 Gb NIC bandwidth under TCP/IP. In the future, we’ll also introduce RDMA to further unleash the potential of 200 Gb and 400 Gb NICs.
In this article, we’ll share the specific implementations of these TCP/IP network optimizations.
Golang network performance optimization
In large-scale environments, such as when thousands of clients access data from over 100 distributed cache nodes, the number of network connections to cache nodes increases significantly. This leads to substantial Golang scheduling overhead and reduced network bandwidth utilization.
We addressed two key points—connection reuse and epoll event triggering—by introducing multiplexing mechanisms and event trigger threshold optimizations. This effectively alleviated system pressure and improved data processing performance.
Multiplexing
If a connection can only handle one request at a time, the system’s overall concurrency capability will be limited by the number of connections itself. To improve concurrency, a large number of connections must be established. Therefore, we introduced connection multiplexing. It allows multiple request packets to be sent simultaneously over the same connection to the peer end. Through multiplexing, the throughput capacity of a single connection can be effectively improved. This reduces the need for numerous connections, thereby enhancing concurrent performance while lowering resource consumption and network burden.
Since single TCP connections have performance bottlenecks, we further introduced the ability to dynamically adjust the number of connections based on real-time traffic within the multiplexing architecture to achieve the best balance between performance and resources. This improved overall throughput and network efficiency. The system automatically increases or decreases the number of connections based on current network traffic:
- When user request volume is high, total traffic continues to rise, and existing connections can no longer meet bandwidth requirements, the system automatically increases the number of connections to improve bandwidth utilization efficiency.
- When requests become inactive and total bandwidth decreases, the system automatically reduces the number of connections to avoid resource waste and packet fragmentation issues.
Another advantage of multiplexing is support for small packet merging. Through efficient connection management, multiple small packets’ data streams can be transmitted together over the same physical connection. This reduces network transmissions along with the overhead from system calls and kernel-user space switching.
Specifically, on the sender side, the sending thread continuously retrieves multiple requests from the sending channel until the channel is empty or the cumulative data to be sent reaches 4 KiB before sending them together. This merges multiple small packets into a larger data block, reducing system calls and network transmissions. On the receiver side, data from the NIC is read in bulk into a ring buffer, from which upper-layer services extract segments one by one and parse out complete application-layer data packets.
Receive watermark setting (SO_RCVLOWAT)
In Golang’s network framework, epoll’s edge-triggered mode is used by default to handle sockets. An epoll event is generated when the socket state changes (for example, from no data to having data).
To reduce the additional overhead caused by frequent events triggered by small amounts of data, we set SO_RCVLOWAT (socket receive low watermark) to control the kernel to trigger epoll events only when the data volume in the socket receive buffer reaches a specified number of bytes. This reduces the number of system calls triggered by frequent events and lowers network I/O overhead.
For example:
conn, _ := net.Dial("tcp", "example.com:80")
syscall.SetsockoptInt(conn.(net.TCPConn).File().Fd(), syscall.SOL_SOCKET, syscall.SO_RCVLOWAT, 512*1024)
After testing, in high-concurrency connection scenarios, epoll events dropped by 90% to about 40,000 per second. Cache performance became more stable, with CPU overhead maintained at about 1 core per GB bandwidth.
Zero-copy optimization: reducing CPU and memory consumption
In Linux network communication, zero-copy is a technique that reduces or eliminates unnecessary data copying between kernel space and user space to lower CPU and memory consumption, thereby improving data transfer efficiency. It’s particularly suitable for large-scale data transfer scenarios. Classic products such as nginx, Kafka, and haproxy use zero-copy technology to optimize performance.
Common zero-copy technologies include the mmap system call, as well as mechanisms such as sendfile, splice, tee, vmsplice, and MSG_ZEROCOPY.
sendfileis a system call provided by Linux to read file data directly from disk into the kernel buffer and transmit it to the socket buffer via DMA without passing through user space.spliceallows direct data movement in kernel space, supporting data transfer between any two file descriptors (with at least one end being a pipe). Using a pipe as an intermediary, data is transferred from the input descriptor (e.g., a file) to the output descriptor (e.g., a socket), while the kernel only manipulates page pointers, avoiding actual data copying.
Compared to sendfile, splice is more flexible, supporting non-file transmission scenarios (such as forwarding between sockets), and is more suitable for high-concurrency network environments, such as proxy servers. sendfile can reduce the number of system calls but blocks the current thread, affecting concurrent performance. We used splice and sendfile in different scenarios to optimize data transmission flows for the best results.
Taking splice as an example, when a client requests file data, it sends a request to the cache node via distributed caching. We used splice zero-copy technology to optimize the data flow on the sender side. The specific data transmission path is as follows:
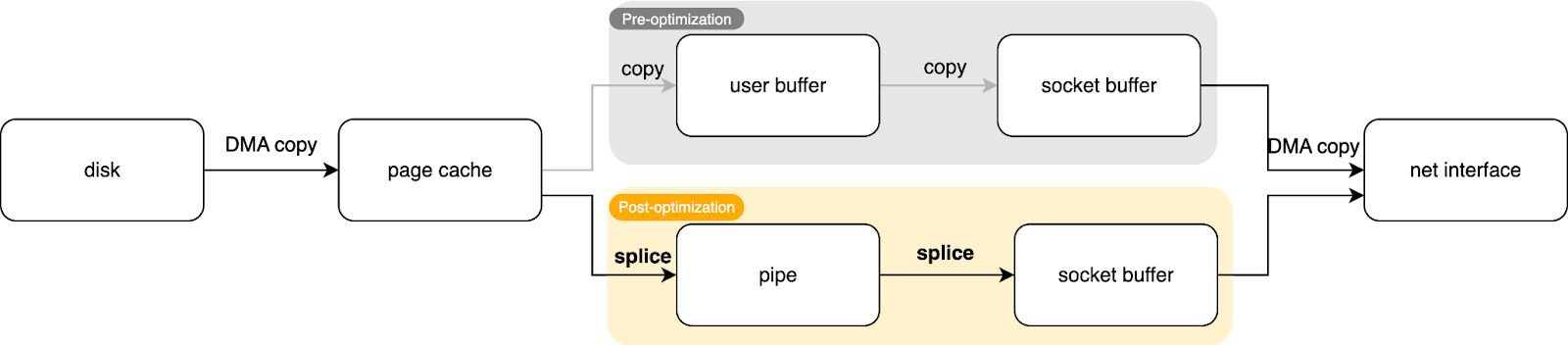
When cache data needs to be sent to the client, the process uses the splice interface to read data directly from the file into the kernel buffer (page cache). The data is then transmitted via splice to a pre-created pipe, and the data in the pipe is further transmitted via splice to the socket buffer. Since the data remains in kernel space throughout the process, only two DMA copies occur without any CPU copying, achieving zero-copy cache service.
Although there is also optimization potential on the receiver side, due to the high hardware and runtime environment requirements for zero-copy implementation and its lack of universality, we haven’t introduced related solutions in the current architecture.
Optimizing the CRC check process
In previous versions, reading a data block from distributed caching required two cyclic redundancy checks (CRCs):
- Disk loading phase: When loading data from disk into memory, to check if data on the disk has experienced bit rot.
- Network transmission phase: The sender recalculates the CRC and writes it into the packet header. The receiver recalculates the CRC after receiving the data and compares it with the value in the packet header to ensure the data has not been tampered with or corrupted during transmission.
To reduce unnecessary CPU overhead, the new version optimizes the CRC check process during network transmission. The sender no longer recalculates the CRC but instead uses the CRC value saved on the disk, merging it into a total CRC written into the packet header. The receiver performs only one CRC after receiving the data.
To support random reads, cached data blocks need to have CRC values calculated segmentally—every 32 KB. However, the network transmission process requires the CRC value for all transmitted data. Therefore, we efficiently merge segmented CRC values into an overall CRC value using a lookup table method, the overhead of which is almost negligible. This approach reduces one CRC calculation while ensuring data consistency and integrity, effectively lowering the sender’s CPU consumption and improving overall performance.
Summary
In scenarios such as large-scale model training and inference, data scale is growing at an unprecedented rate. As a critical component connecting computing and storage, distributed caching distributes hot data across multiple nodes, significantly improving system access performance and scalability. This effectively reduces the pressure on backend storage, and enhances the stability and efficiency of the overall system.
However, when facing continuously growing data and client access pressure, building high-performance large-scale distributed caching still faces many challenges. Therefore, JuiceFS’ distributed caching system, implemented based on Golang, has undergone in-depth optimizations around Golang’s I/O mechanisms in practice and introduced key technologies such as zero-copy. This significantly reduces CPU overhead, improves network bandwidth utilization, and makes the system more stable and efficient under high-load scenarios.
We hope that some of the practical experiences in this article can provide references for developers facing similar issues. If you have any questions or feedback for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.