















With the rise of large language models (LLMs) and multimodal artificial intelligence (AI), the scale of unstructured data has grown exponentially. This places higher demands on data storage, retrieval, and analysis. LanceDB is an AI-native multimodal data lake that adopts the self-developed open-source data format Lance to address the limitations of traditional data formats in large-scale unstructured data scenarios. It has been adopted by several AI companies, such as Runway and Midjourney.
LanceDB offers multiple storage backend options to meet users' varying requirements in terms of cost, latency, scalability, and reliability. Recently, we conducted performance tests for LanceDB across different storage solutions, including JuiceFS, local NVMe, AWS EBS, EFS, and FSx for Lustre. The results show that JuiceFS outperforms AWS EFS and FSx for Lustre in performance, approaches EBS, and can stably support LanceDB queries.
LanceDB overview
LanceDB is a high-performance vector database designed for multimodal data, aimed at efficiently managing and searching large-scale vector data. It’s particularly suitable for AI/ML applications, especially in multimodal data scenarios (such as image and text embeddings).
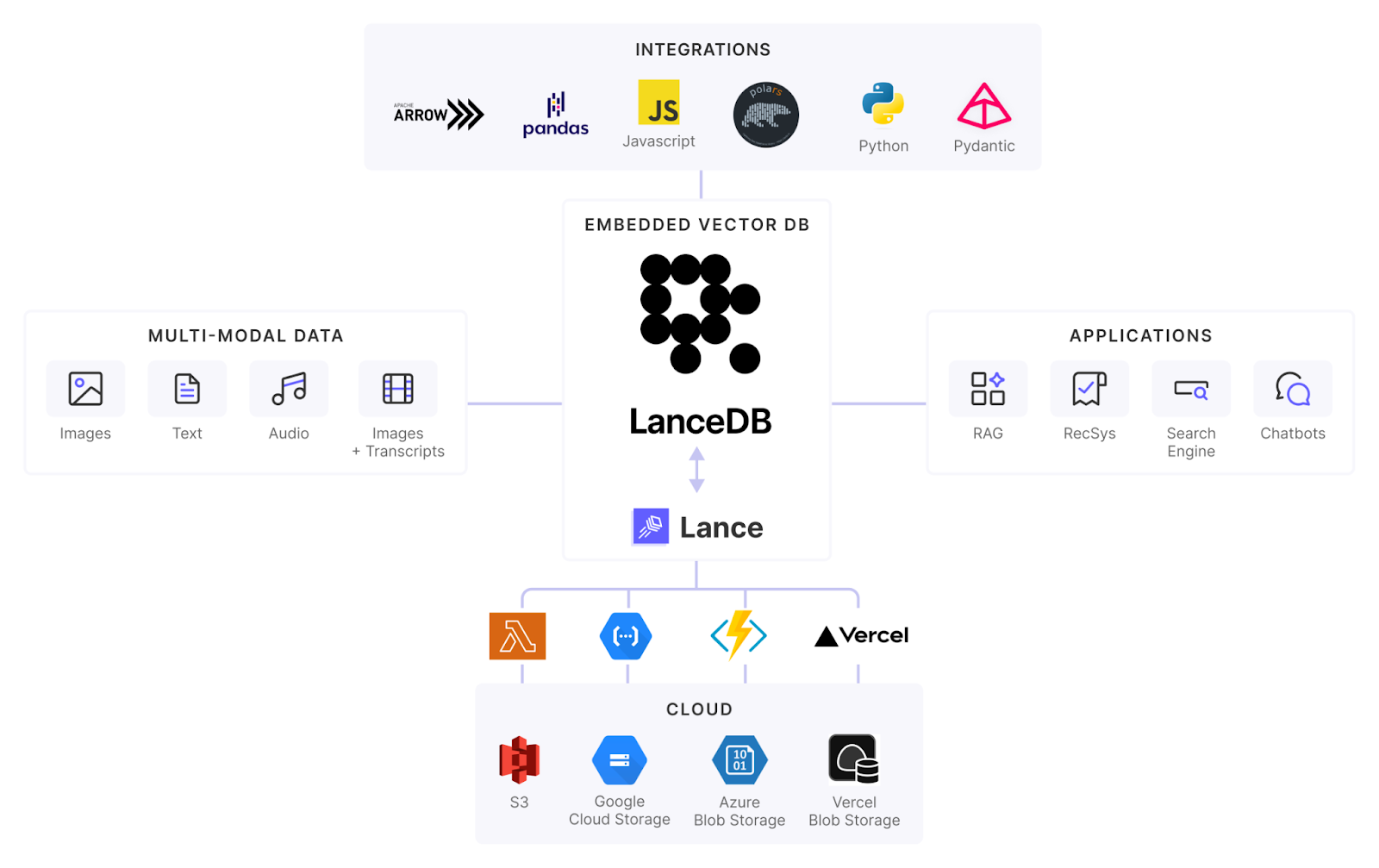
JuiceFS overview
JuiceFS is a distributed POSIX file system designed for cloud-native environments. It adopts a metadata-data separation architecture, enabling efficient management of large datasets across multiple storage backends. JuiceFS offers high scalability and is suitable for scenarios requiring parallel data access by multiple nodes, such as large-scale AI/ML workloads.
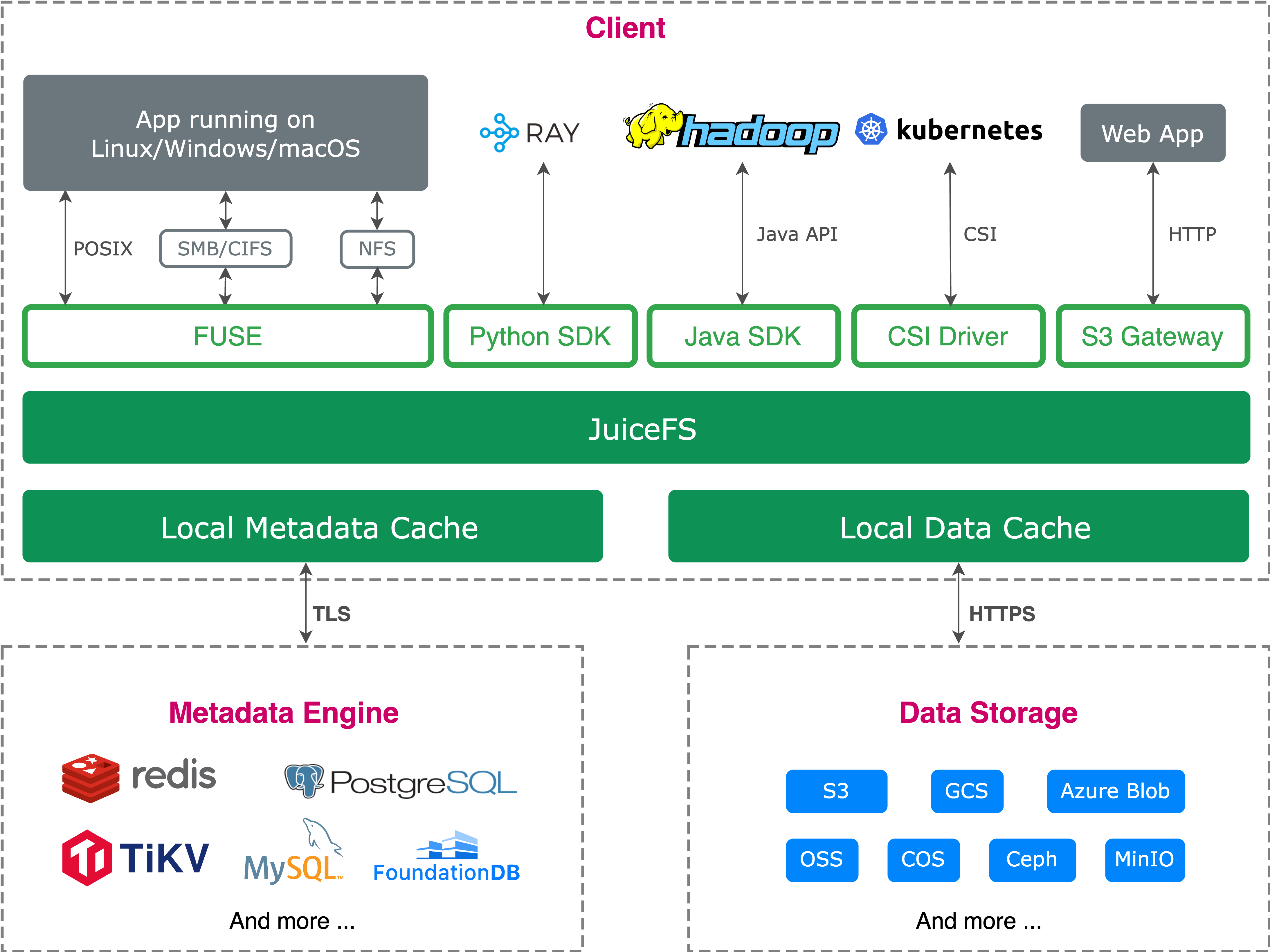
Multimodal dataset testing
In this test, we primarily evaluated the performance differences between JuiceFS and various storage media. The multimodal_clip_diffusiondb dataset we used contains approximately 5.8 GB of multimodal data (such as images and text embeddings). The test involved running 100 different query requests to compare query performance across different storage solutions. You can view the test code and data via this link.
The schema of the data table is as follows:
prompt: string
seed: uint32
step: uint16
cfg: float
sampler: string
width: uint16
height: uint16
timestamp: timestamp[s]
image_nsfw: float
prompt_nsfw: float
vector: fixed_size_list<item: float>[512]
child 0, item: float
image: binary
Testing steps:
- Update the dataset location to the local path of the test target (such as JuiceFS mount path, EFS, or FSx for Lustre).
- Launch
multimodal_clip_diffusiondbas an HTTP service, fetch 100 different prompts from the server, and save them as JSON files.
Here’s an example of a JSON file:
$ cat close.json
{
"data": [
"close"
],
"event_data": null,
"fn_index": 0,
"session_hash": "ejnrxozcc9l"
}
Use a script to call the full-text search API in parallel, executing 100 queries with different keywords. The actual effect is equivalent to running the logic in the code below.
$ cat run.sh:
#!/bin/bash
for i in data/*.json
do
curl 'http://127.0.0.1:7860/run/predict' -X POST -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:130.0) Gecko/20100101 Firefox/130.0' -H 'Accept: */*' -H 'Accept-Language: en-CA,en-US;q=0.7,en;q=0.3' -H 'Accept-Encoding: gzip, deflate, br, zstd' -H 'Referer: http://127.0.0.1:7860/' -H 'Content-Type: application/json' -H 'Origin: http://127.0.0.1:7860' -H 'Connection: keep-alive' -H 'Sec-Fetch-Dest: empty' -H 'Sec-Fetch-Mode: cors' -H 'Sec-Fetch-Site: same-origin' -H 'Priority: u=0' -H 'Pragma: no-cache' -H 'Cache-Control: no-cache' --data @$i
done
The access code behind the query service:
import lancedb
db = lancedb.connect('~/datasets/demo')
tbl = db.open_table('diffusiondb')
tbl.search('{query}').limit(9).to_df()
Test results
We copied the LanceDB dataset to multiple storage locations for testing:
- Local NVMe storage: Data stored on a local PCIe 4.0x4 NVMe SSD
- EBS (elastic block storage)
- JuiceFS
- AWS EFS (elastic file system)
- AWS FSx for Lustre: 1.2 TB, 3000 MB/s
Below are the query execution times for different storage configurations:
- Local NVMe performed the best at 129 seconds.
- JuiceFS performance was close to EBS: JuiceFS took 177 seconds, slightly higher than EBS’s 176 seconds.
- EFS and FSx for Lustre took 194 and 195 seconds, respectively, significantly slower than JuiceFS and EBS.

Summary
Through this test, we validated the actual query performance of LanceDB when paired with different storage solutions. JuiceFS demonstrated better performance compared to AWS EFS and FSx for Lustre.
JuiceFS offers excellent scalability and cloud-native adaptability, meeting the demands of distributed AI/ML applications for efficient storage and data access. For large-scale datasets, multi-node data sharing, and high-concurrency querying applications, JuiceFS + LanceDB is a solution worth exploring.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.