















In JuiceFS 1.3 Beta, we introduce a groundbreaking binary backup mechanism to efficiently handle backup and migration scenarios at the scale of hundreds of millions of files. Compared to the existing JSON-based approach, this mechanism significantly improves processing speed while reducing memory consumption during metadata import and export.
In this article, we’ll examine:
- The limitations of our legacy JSON backup mechanism
- Technical implementation of our binary backup
- Benchmark results across Redis, TiKV, and MySQL backends
JSON backup mechanism review
Since v0.15, JuiceFS has supported metadata import/export via JSON format. This functionality serves not only for routine disaster recovery backups but also enables migration between different metadata engines to accommodate changing application scales or data requirements. For example:
- Migration from Redis to SQL databases for enhanced data reliability
- Transition from Redis to TiKV when facing data volume growth
The primary advantage of JSON format lies in its exceptional human-readability. During backup operations, it:
- Preserves complete directory tree structures.
- Consolidates file object attributes, extended attributes, and data chunks into a unified view.
However, preserving this structure and output order during import/export operations requires the system to process contextual information. This introduces additional computational and memory overhead. Although previous versions have implemented targeted optimizations, processing large-scale backups still consumes a lot of time and memory resources. Moreover, as system scale continues to expand, the importance of readability diminishes. Users shift their focus toward overall backup statistics and data verification mechanisms.
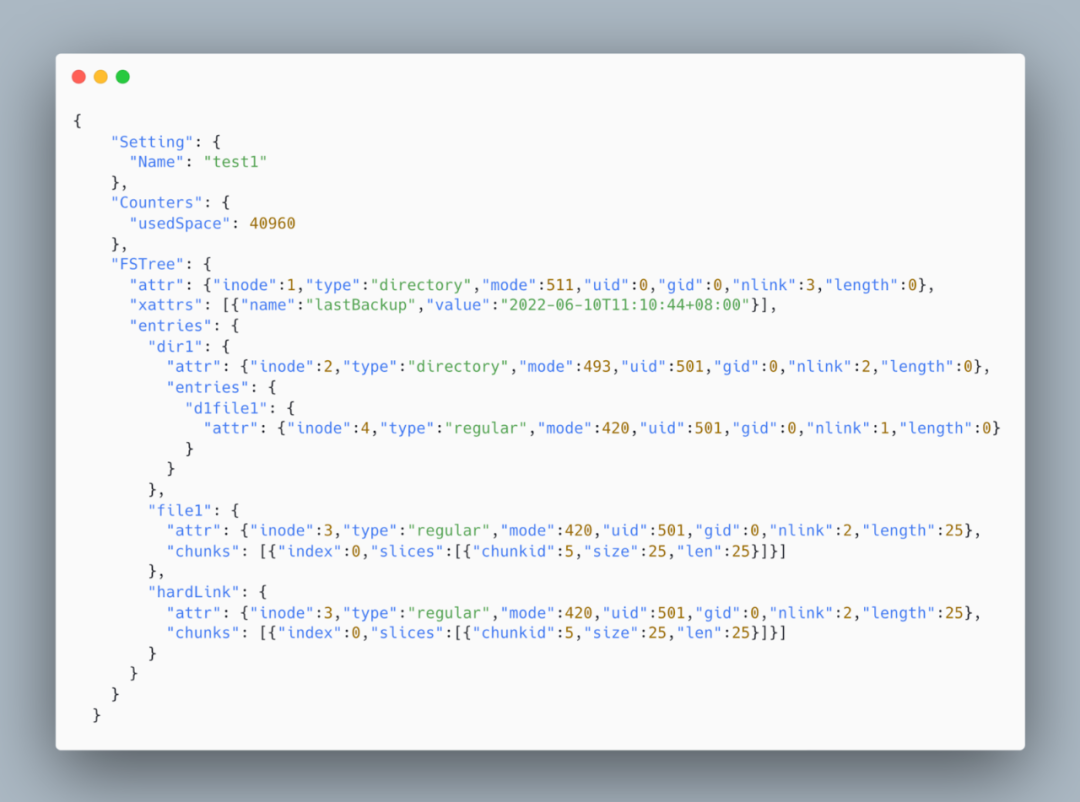
Previously, JuiceFS Community Edition provided two JSON backup methods:
- Standard export, with lower memory usage but poor performance.
- Fast mode. It uses snapshot caching to reduce random queries. This brings higher performance but excessive memory consumption.
Now, as many community file systems scale beyond 100 million files, the trade-off between performance and memory usage becomes critical. Both existing JSON backup approaches demonstrate significant performance bottlenecks and resource limitations in such large-scale scenarios.
In addition, while different metadata engines offer native backup tools, such as Redis RDB, MySQL's mysqldump, and TiKV Backup & Restore, that efficiently back up metadata, these solutions:
- Require extra handling for JuiceFS metadata consistency
- Lack cross-engine migration capabilities
Binary backup implementation
To significantly improve import/export performance and scalability, JuiceFS 1.3 introduces a binary backup format based on Google Protocol Buffers. Designed with performance-first principles, this format also balances compatibility, backup size optimization, and cross-scenario versatility. For benchmark data, refer to this page.
Unlike traditional JSON format, the binary solution adopts a flat storage structure, eliminating dependency on contextual information required for tree-like directory hierarchies. This breakthrough enables:
- No frequent random queries (pain point in standard mode)
- Zero reliance on heavy memory caching (pain point in fast mode)
As a result, this solution boosts performance and reduces resource consumption.
Storage structure design
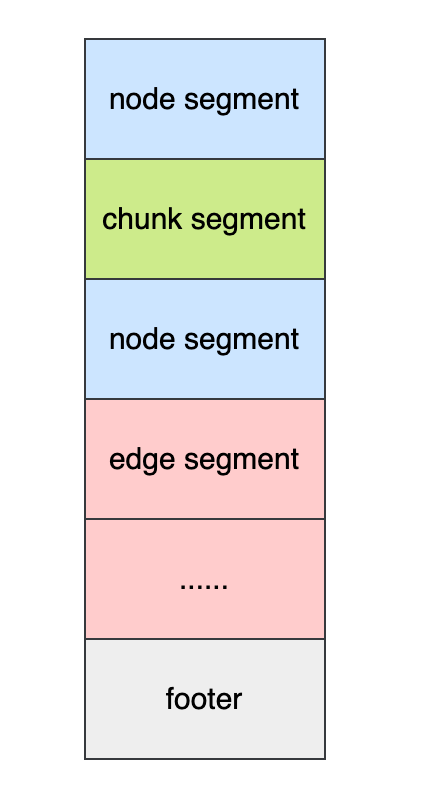
The architecture resembles that of SQL databases, where each metadata type (such as node, edge, and chunk) is stored independently without inter-dependencies, ensuring isolated processing during import/export operations.
The binary format consists of multiple segments. Same-type metadata may split across segments. Different-type segments can interleave. This enables concurrent batch processing during import/export.
A footer segment at the file tail contains version number and indexed metadata segment information (offsets + counts). This design enables random access to the backup file, type-specific processing of metadata segments, analysis, and verification.
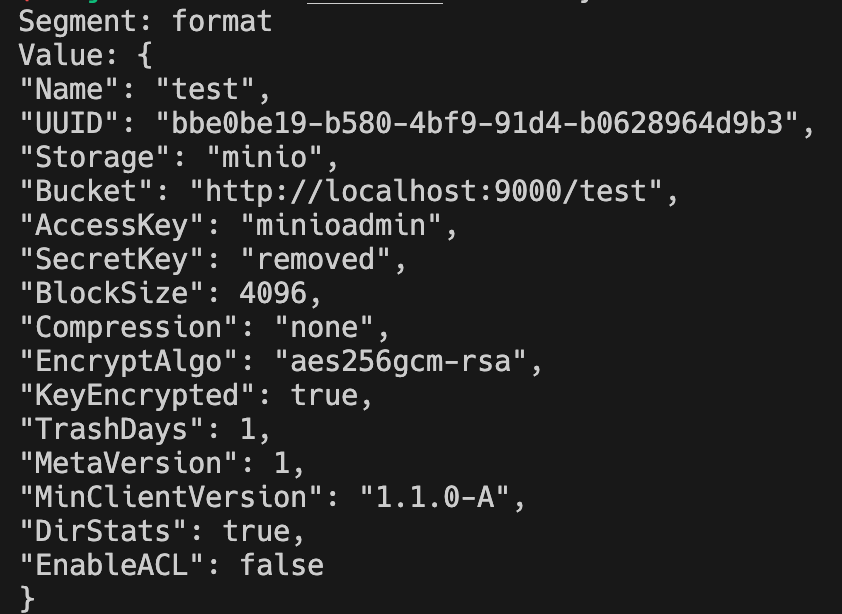
JuiceFS 1.3 introduces binary backup parsing in the load tool, enabling users to:
- Quickly view backup information.
- Develop custom backup analysis tools (thanks to Protocol Buffers format).
Usage examples:
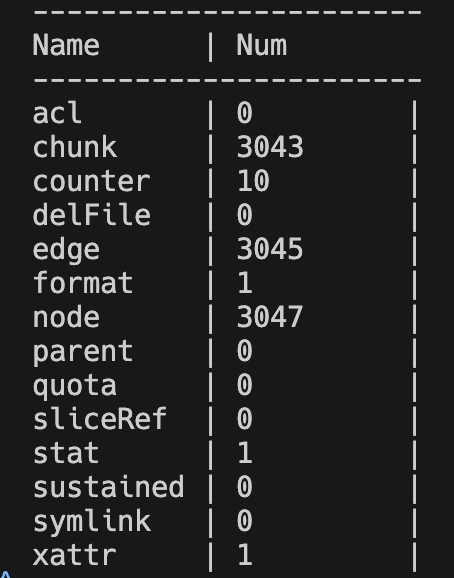
# View metadata type statistics.
$ juicefs load redis.bak --binary --stat
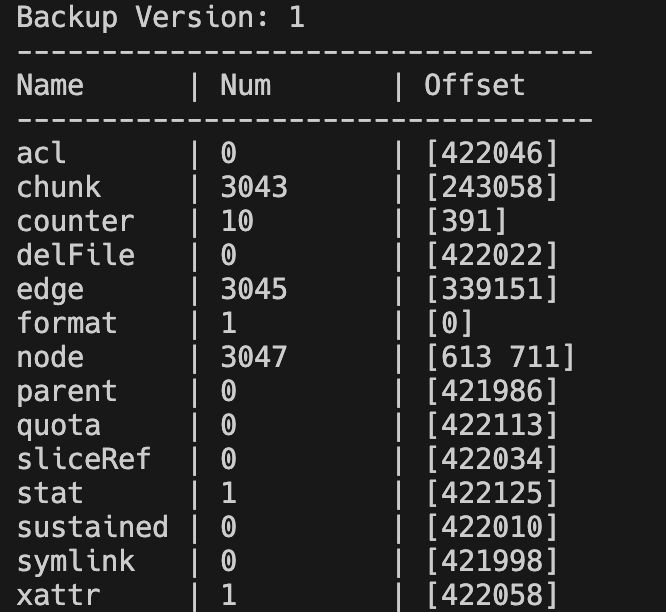
# View metadata segment information (retrieve offset).
$ juicefs load redis.bak --binary --stat --offset=-1
# View specific segment information (by offset).
$ juicefs load redis.bak --binary --stat --offset=0
Import and export process analysis
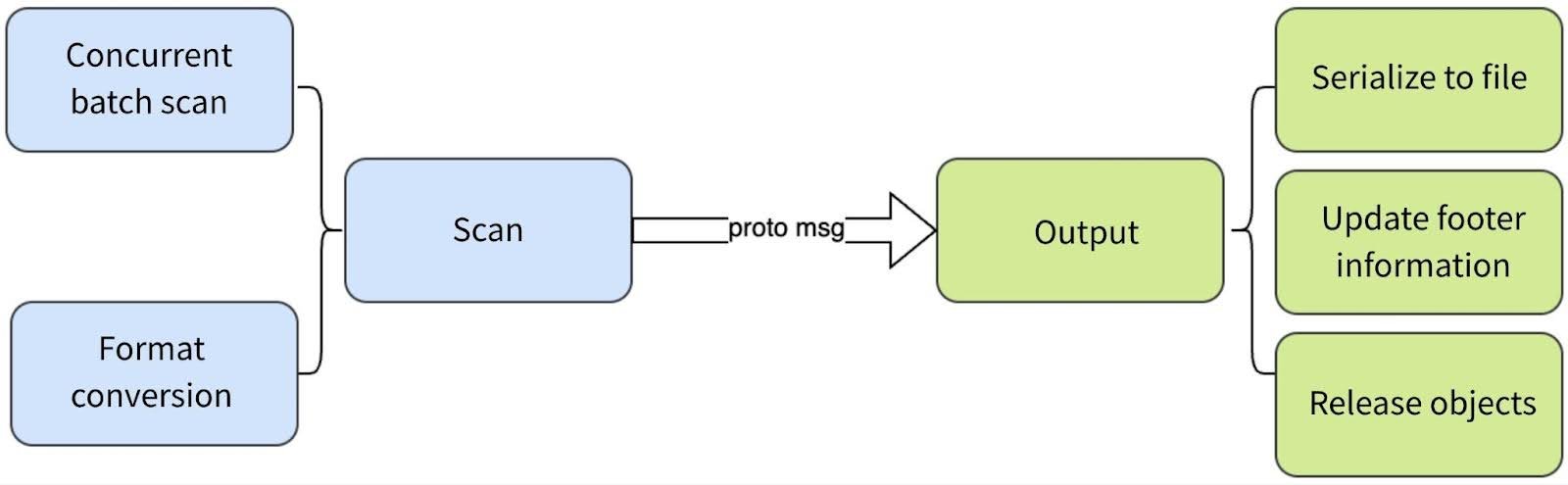
The export process consists of two phases: scanning and output. The output phase primarily handles backup file processing operations, while the scanning phase varies slightly depending on the metadata engine:
- For SQL databases: Different types of metadata are stored in separate tables. During export, the system scans these tables individually and converts the data to the target format. For extremely large tables (such as node, edge, and chunk), batch-based concurrent queries are employed to improve efficiency.
- For Redis and TiKV (key-value formats): Some key types use inode prefixes to optimize access to metadata belonging to the same inode. To avoid repeated access to the underlying engine, these metadata types are scanned once during export and then processed with internal differentiation.
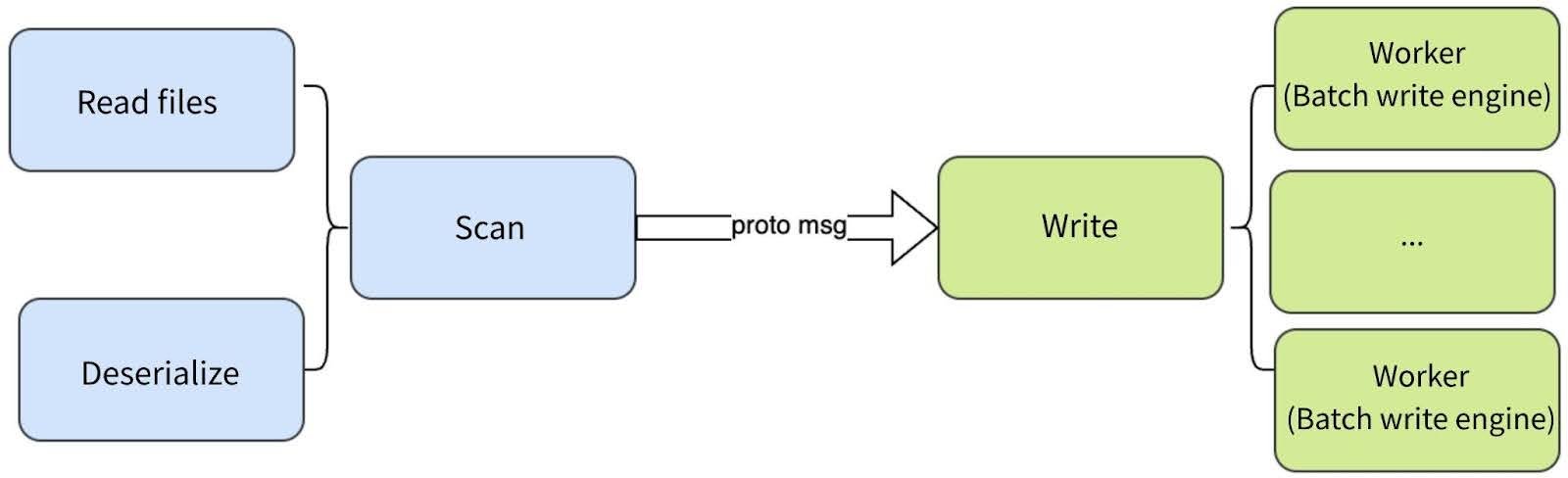
The import process divides into scanning (backup file reading/format processing) and writing (batch concurrent writes to metadata engines). For key-value engines like TiKV with LSM-tree storage, data is pre-sorted before concurrent writes to minimize overwrite conflicts.
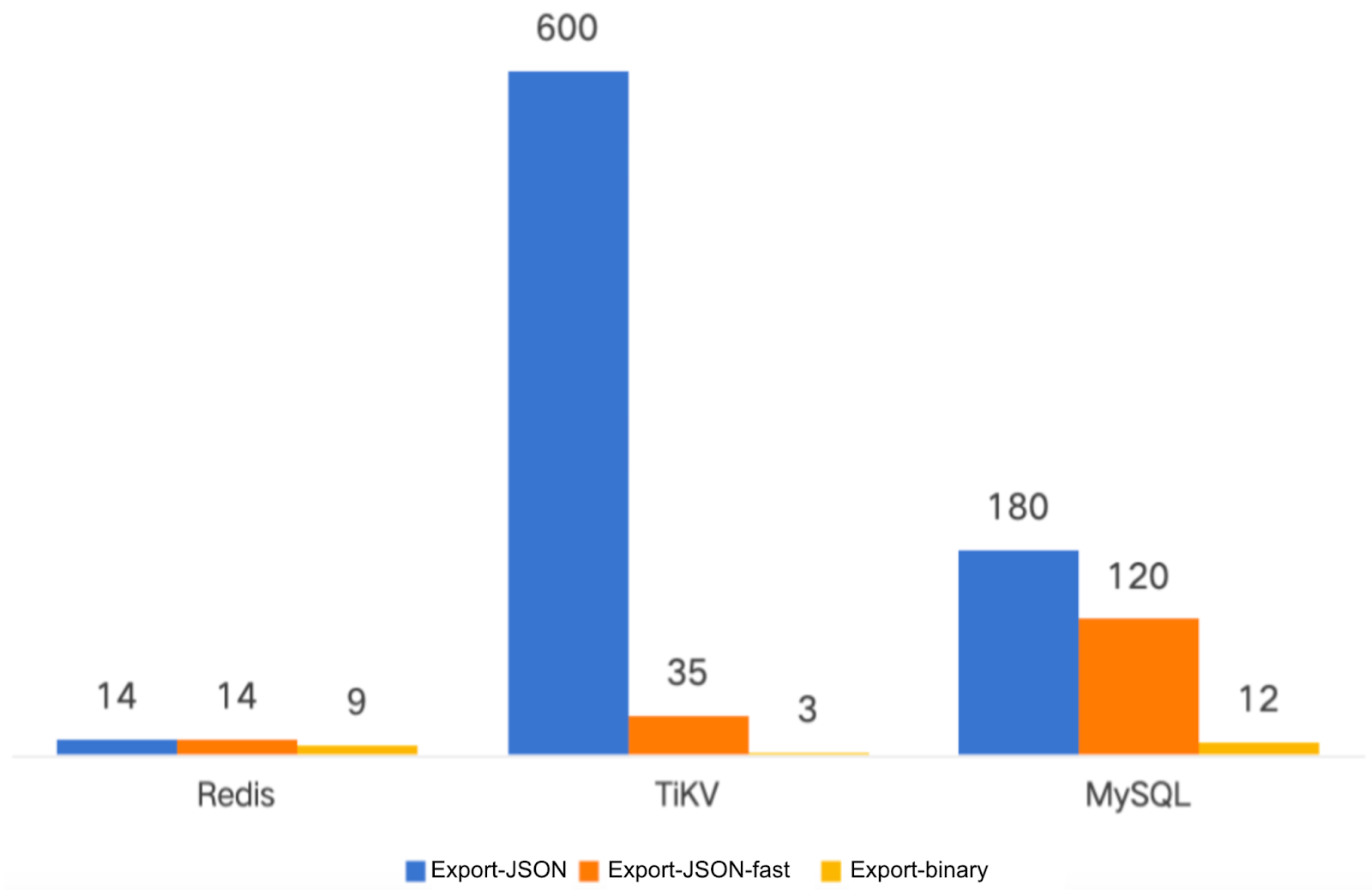
Performance benchmark
Size
The new PB format backups require only 1/3 the storage of JSON format (pre-compression).
Performance
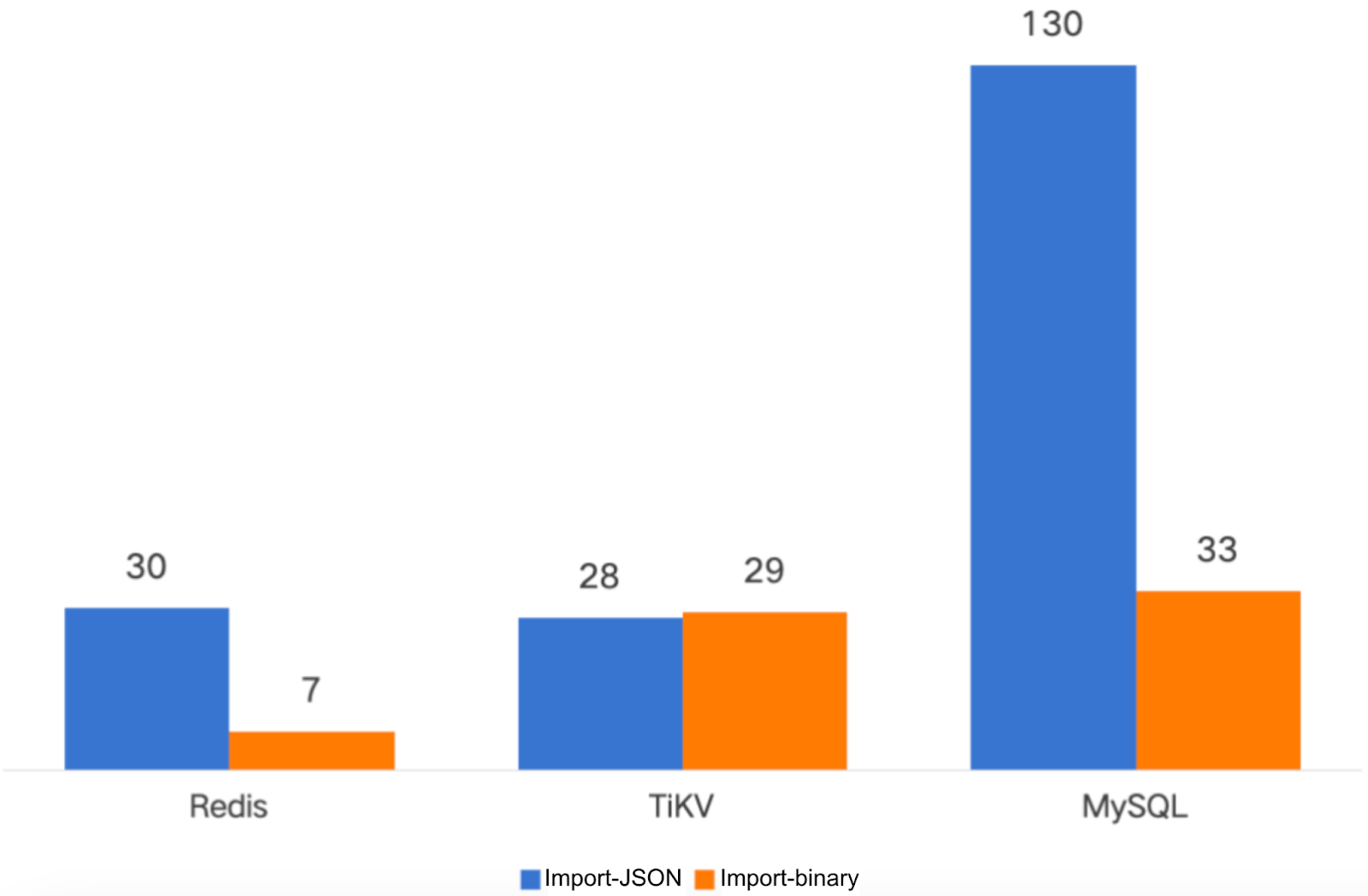
The figures below are the performance comparison of backup import/export for 100 million files:
- Backup time: Reduced to minutes
- Import time: Reduced by 50%-90% (10%-50% of original)
- Export time: Reduced by ~75% (~25% of original)
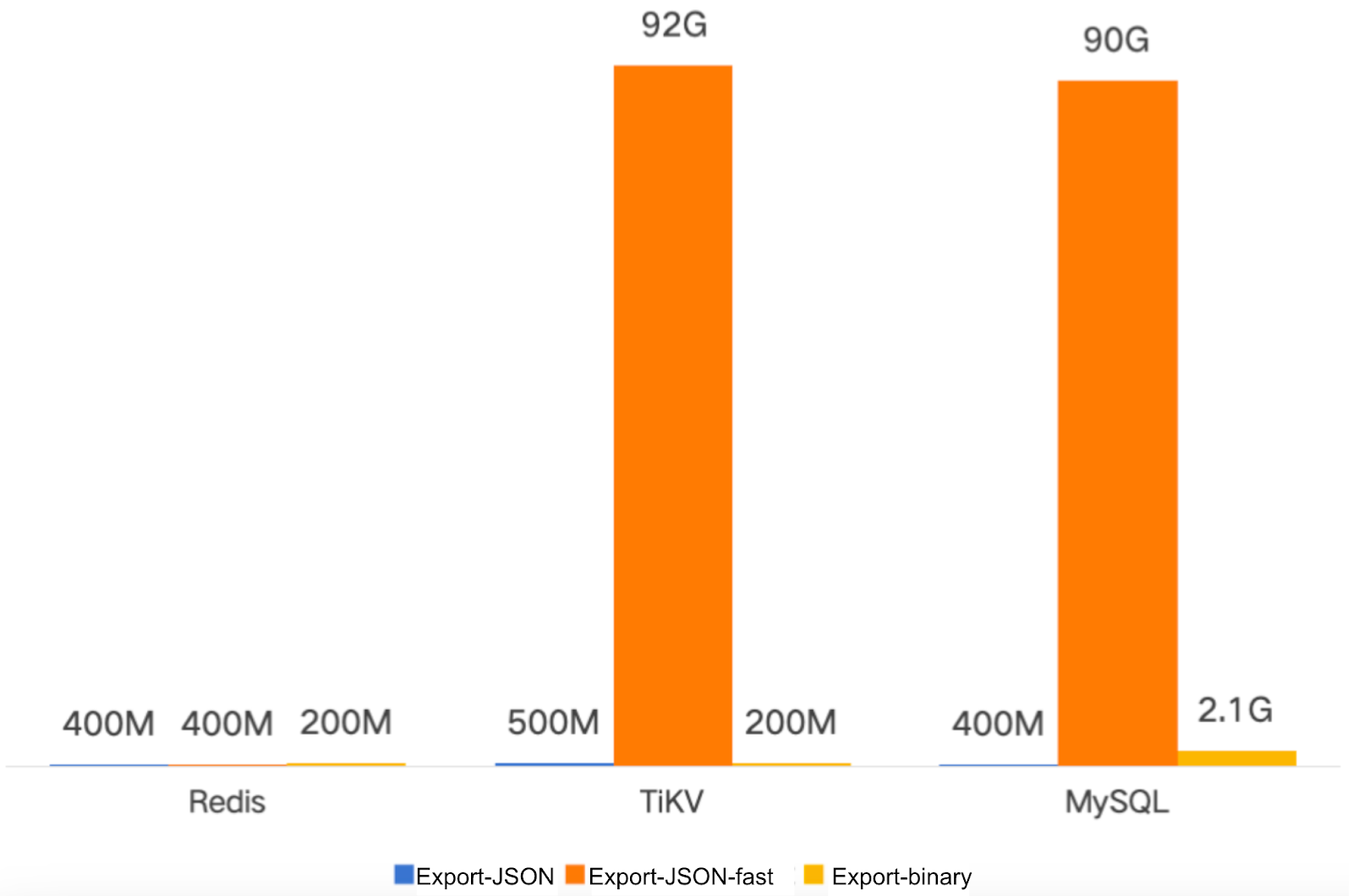
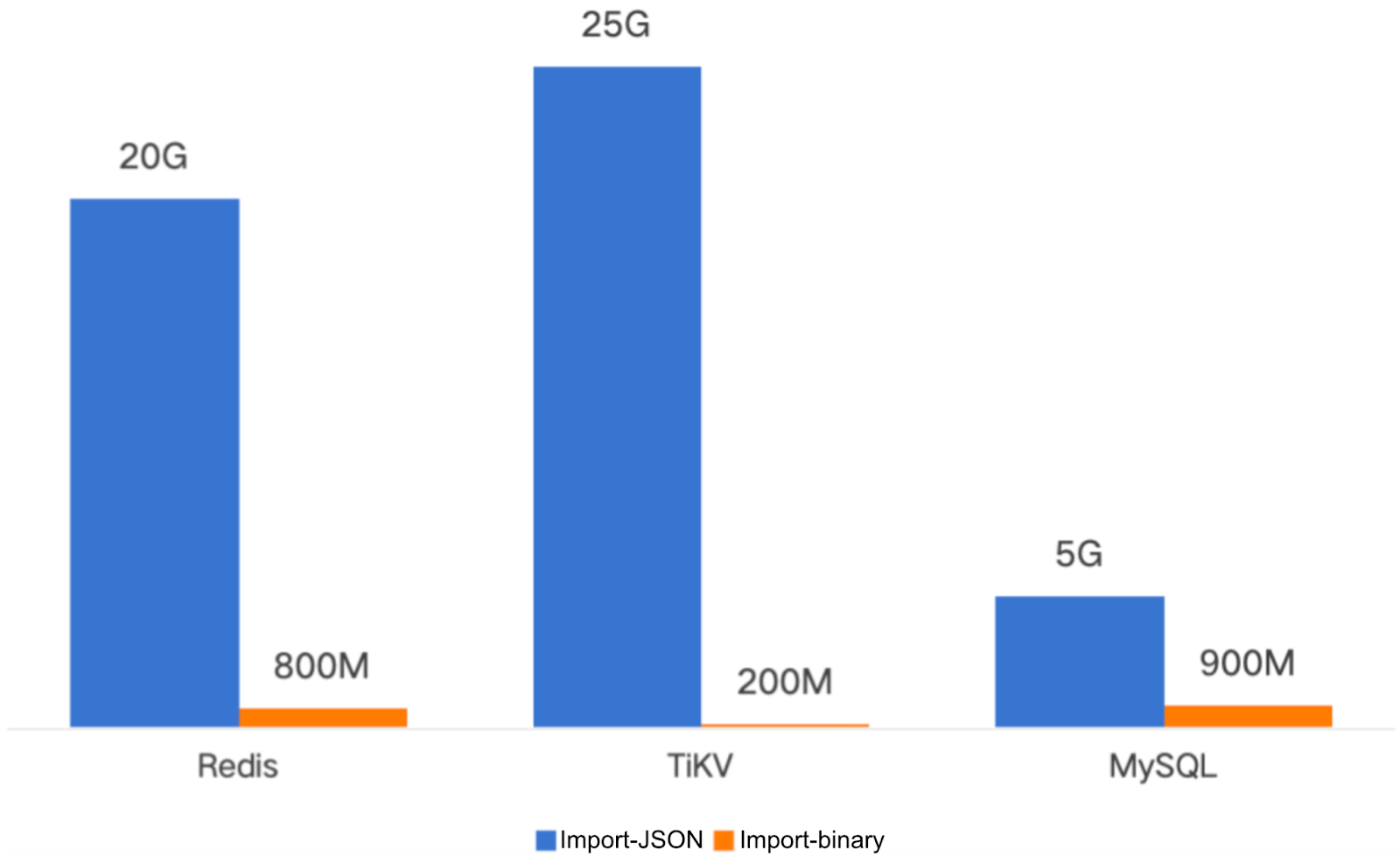
Memory
The new version demonstrates superior memory efficiency:
- Memory usage: <1 GiB (configurable)
- Tunable through:
- Concurrency settings
- Batch size adjustments
Summary
As more community users face the challenges of managing file systems at the hundred-million-file scale, backup mechanism performance, memory usage, and cross-engine compatibility have become critical requirements.
The binary backup format introduced by JuiceFS in version 1.3: By adopting Protocol Buffer and flat design, it significantly improves the efficiency of import and export, reduces resource consumption, and improves the flexibility and operability of the backup structure. In the future, we’ll continue to optimize data protection, disaster recovery migration, and tool chain improvement.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.