















Since last year, the field of large language models (LLMs) has been growing rapidly, with foundational models like LLaMA seeing significant increases in numbers. Many companies have also started performing post-training on these foundational models to develop specialized models tailored to specific vertical applications.
As AI models continue to grow exponentially in parameter size, some reach hundreds of billions or even trillions of parameters. Such large models are imposing significant challenges on companies in terms of storage cost and planning. For example, the latest Llama 3 model offers versions with 405 billion, 70 billion, and 8 billion parameters. The continuous increase in model size and the complex development and data management processes of LLMs are pushing the limits of traditional storage systems. This directly affects workflow efficiency.
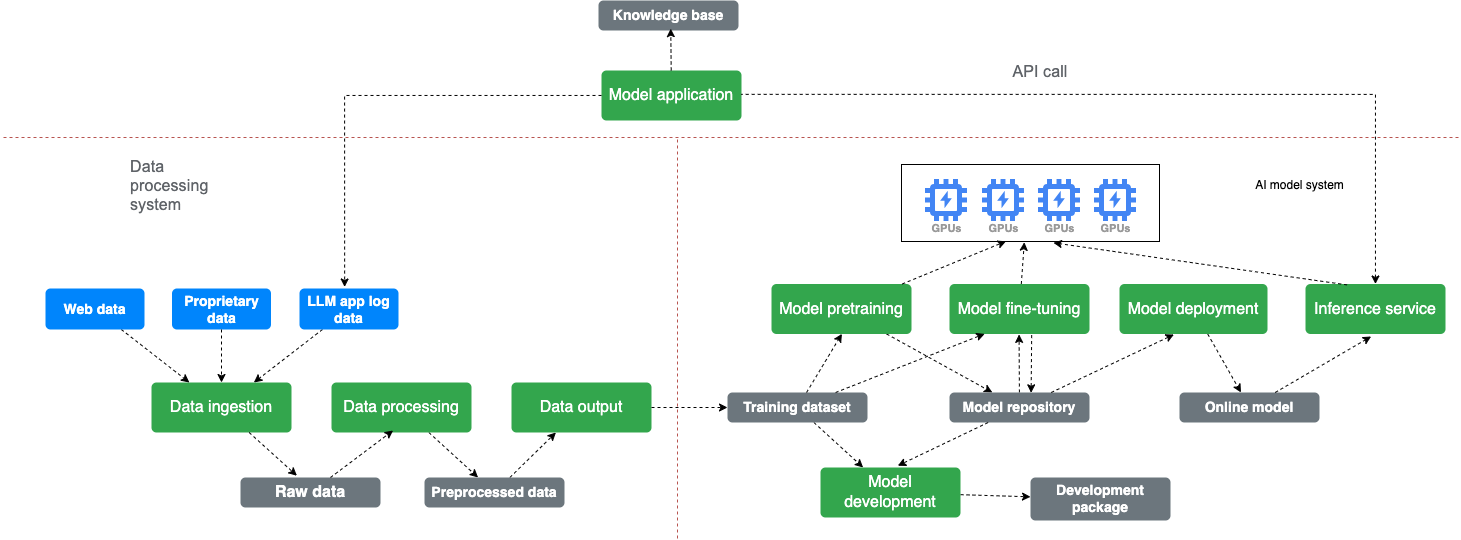
In addition, the demand for distributed GPU computing resources in large-scale training and inference scenarios has shifted towards multi-cloud and multi-region setups. This introduces new challenges for users in distributing, synchronizing, and managing datasets and models across different regions, with consistency being a critical concern.
In this article, we’ll share our considerations for selecting storage solutions for LLMs and discuss the varying workloads during different development phases, covering cost, performance, and functionality. We'll also explore how JuiceFS, an open-source, high-performance distributed file system, helps optimize key aspects of this process.
Key factors for selecting a file system for LLMs
To address the challenges of massive datasets and complex data flows, one common solution is to establish a unified data management system, or a data lake. A data lake provides a unified namespace that stores various types of data on the backend while offering diverse data access methods on the frontend. This reduces the complexity and cost of managing data pipelines.
While this approach is ideal in theory, designing a unified technology stack or product that achieves these goals is challenging in practice. From the perspective of supporting frontend data processing frameworks, a fully POSIX-compliant file system seems to be the best solution.
Moreover, a suitable file system must not only handle massive numbers of files—potentially tens of billions—but also ensure fast access at such scales. This requires highly efficient metadata management and multi-level caching mechanisms for optimal performance.
In addition, support for storage orchestration across container platforms, horizontal scalability, and multi-cloud data synchronization are all critical factors when selecting a data lake solution.
Below is a comparison of several commonly used file systems, evaluated across multiple dimensions, to assist with your storage selection process:
| Feature | Cloud NAS | CephFS | Lustre | s3fs | Alluxio | JuiceFS |
|---|---|---|---|---|---|---|
| Caching | N | N | N | N | Y | Y |
| Massive small files | < 500 M | < 500 M | < 500 M | / | 10 B | 100 B |
| POSIX and object storage | N | N | N | Partial | Partial | Y |
| Strong consistency | Y | Y | Y | N | N | Y |
| Capacity elasticity | Y | N | N | / | Y | Y |
| Multi-cloud data management | N | N | N | N | Y | Y |
| Cloud native | Y | N | N | / | N | Y |
| Cloud-hosting services | Y | N | N | N | N | Y |
Among the products commonly evaluated by JuiceFS users are CephFS, Lustre, and Alluxio. We’ll focus on highlighting the differences between these products.
For data processing framework support:
- To ensure optimal compatibility with the POSIX protocol, JuiceFS, CephFS, and Lustre all provide comprehensive POSIX support, ensuring strong consistency across various stages of the data lifecycle.
- Alluxio, designed as a data orchestration and acceleration tool, offers only partial POSIX support without guaranteeing strong consistency. This limits its application scenarios.
When handling large volumes of small files, the challenge lies in metadata management and performance:
- CephFS and Lustre store metadata on disk and use memory caching for performance acceleration. As the file count increases, so do the costs of managing and using metadata.
- Alluxio provides two metadata storage options: one based on RocksDB and another on in-memory storage. This allows users to choose based on their needs.
- JuiceFS uses object storage with a flat namespace for scalability and cost efficiency, making it ideal for storing large volumes of small files. JuiceFS Community Edition supports multiple open-source databases for metadata storage, while the Enterprise Edition uses an in-memory metadata engine optimized for file tree management, metadata access performance, and horizontal scalability.
In multi-cloud data management, a file system-level replication capability that is transparent to users is required:
- CephFS and Lustre do not natively support file system-level replication, relying instead on storage backends or third-party tools to achieve this functionality. This approach makes it difficult to ensure data consistency and adds extra management overhead.
- Both JuiceFS and Alluxio offer multi-cloud and multi-region data distribution capabilities that are transparent to users. In addition, JuiceFS provides writable file system support at mirror sites.
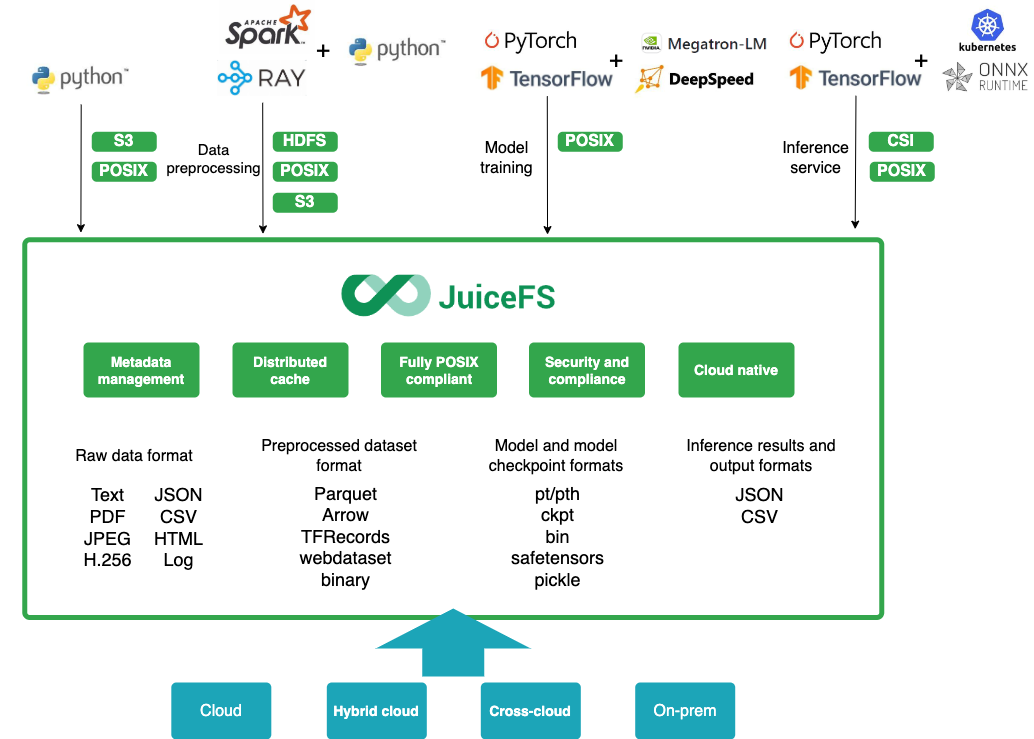
In summary, key benefits of JuiceFS in data lake storage:
- Unified namespace with multi-protocol access
- Full POSIX compatibility
- Support for tens of billions of files
- Strong data consistency
- High concurrency and shared access capabilities
- Performance optimization for different workloads
- Multi-cloud and multi-region data distribution and access
JuiceFS in LLM scenarios
Phase 1: Dataset loading
There are two key aspects when loading datasets for LLM training:
- The dataset needs to be traversed multiple times, which means through multiple epochs.
- Before each epoch begins, the dataset needs to be shuffled randomly to ensure the model can fully learn the data patterns and avoid overfitting. Once shuffled, the dataset is loaded into GPU memory in batches for processing.
Since this data processing mainly relies on CPU resources, the GPU is often idle during this phase. To minimize GPU idle time, users need to improve dataset loading efficiency, for example, by using caching. Datasets typically come in the form of structured large files (such as FFRecord, TFRecord, and Arrow) or a massive number of small files, such as uncompressed text, images, and audio.
The shuffling process requires random reads from data files. Based on the dataset file format, the data loading process typically involves random reads of large and small files. Such random read I/O demands high IOPS and low I/O latency from the file system, especially for handling the random read of massive small files, which puts a higher demand on the metadata engine’s performance. In addition, the dataset is read repeatedly during training. If the data can be cached in high-performance storage media, achieving a high cache hit rate can significantly enhance data reading performance.
JuiceFS is designed to help users find the best balance between performance and cost. By leveraging object storage as a backend for data persistence and combining it with a multi-level caching acceleration architecture, JuiceFS offers high IOPS and low I/O latency for dataset loading while remaining cost-effective. Here are some performance metrics for small I/O random reads using JuiceFS:
- When hitting the local cache, latency is between 0.05 and 0.1 milliseconds.
- When hitting the distributed cache (a feature of the Enterprise Edition), latency ranges from 0.1 to 0.2 milliseconds.
- Directly reading from object storage incurs latency above 30 to 50 milliseconds.
To achieve higher IOPS, users can use libaio, but this requires integrating specific framework extensions to support the libaio interface. In addition, JuiceFS Enterprise Edition provides a custom-built, fully in-memory metadata engine that ensures an average metadata request processing time of around 100 microseconds, even when managing massive file counts. This offers excellent performance for loading datasets with a large number of small files. The multi-partition architecture of the metadata engine also allows dynamic and linear scalability based on the file size.
Below is a set of random read test data for large files to help illustrate JuiceFS' performance. The test data is a single 1.8 TB file.
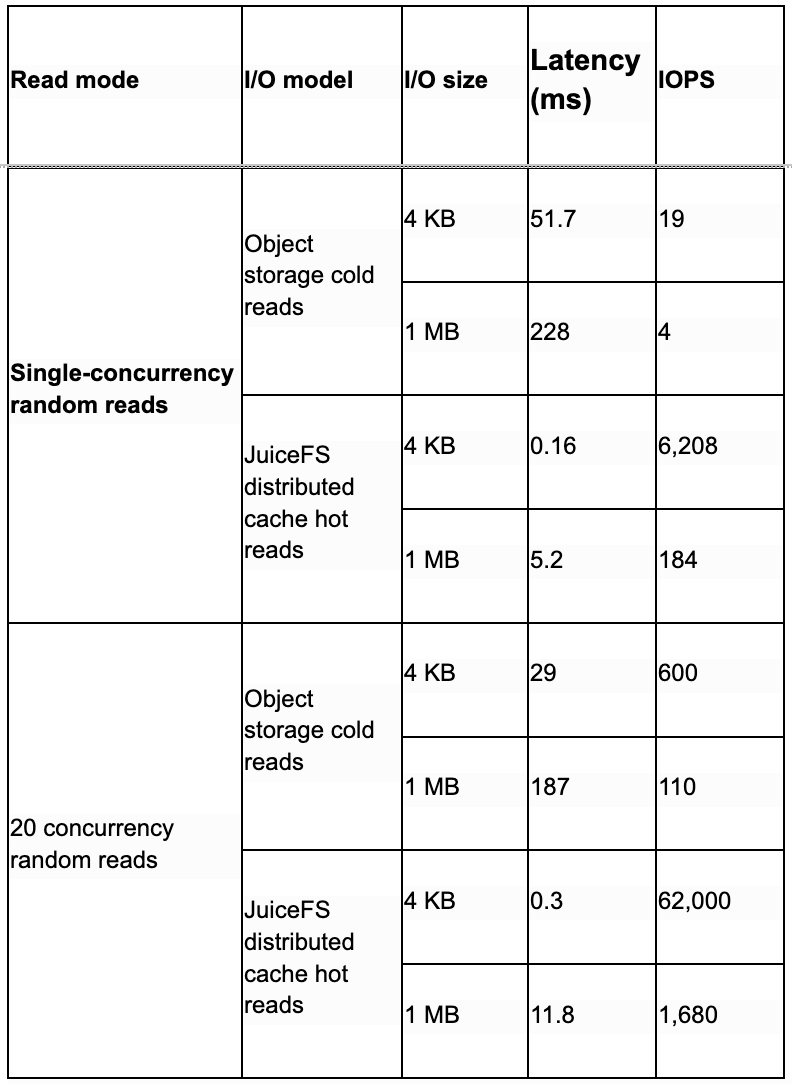
Phase 2: Checkpoint saving during training
Saving checkpoint files during training allows users to resume training from the most recent checkpoint in case of interruptions, thus saving time and computing resources. In synchronous checkpoint writing, GPUs remain idle during the checkpoint-saving window. Typically, checkpoint writes involve large files written sequentially. To minimize this time, the file system must provide high write throughput.
JuiceFS uses object storage as the data persistence layer, with the throughput limit depending on object storage bandwidth, dedicated line bandwidth, and the network card bandwidth of the node running the JuiceFS client. JuiceFS employs block storage design, and by increasing the level of concurrency with object storage, it can fully utilize object storage bandwidth to enhance the throughput of large file sequential writes.
In addition, JuiceFS offers a write caching feature. If the backend object storage encounters performance bottlenecks, users can enable writeback caching, using high-speed NVMe storage media on GPU nodes as local cache. Checkpoint files are first written to local storage and then asynchronously uploaded to object storage. This reduces write latency. It’s important to note, however, that enabling writeback caching may lead to inconsistent checkpoint files in some cases. This makes it impossible to load and resume training properly. In such cases, users need to load the previous checkpoint file and rerun some training epochs.
Based on user testing, when saving checkpoints using torch.save to JuiceFS, a single process writing a checkpoint on each GPU card can achieve a write throughput of 1.7 GB/s or higher. This meets performance requirements for this scenario.
Phase 3: Model loading during training and inference
Typical model loading scenarios include:
- Loading checkpoint files for training resumption: During the training recovery phase, parallel training nodes load only the shard checkpoint files relevant to their rank. The total file size to be loaded across all nodes is the sum of all shard checkpoint files. The efficiency of loading checkpoint files directly impacts GPU idle time, as it determines how quickly training can resume.
- Loading model files for inference: When deploying a trained model in an inference service, the entire model file typically needs to be loaded on the inference nodes at startup. When there are many inference nodes, such as thousands running simultaneously, each node needs to retrieve the full model file from storage. This creates significant read throughput demand. If network throughput becomes a bottleneck, model loading speed will be slow. If public cloud object storage is used, bandwidth and dedicated line bandwidth often become bottlenecks. Retrieving full model files for each node generates significant additional object storage bandwidth and call costs.
It’s important to note that different model file formats place different demands on storage I/O. Model files might be saved as .pt or .bin using torch.save or as .safetensors files using the safetensors library. The safetensors files are unique and they are loaded using mmap, which requires a storage I/O model optimized for random reads of large files. In contrast, other file formats are loaded using sequential reads of large files.
Let’s explore JuiceFS optimization strategies for both scenarios:
- For Safetensors model files (random reads of large files): JuiceFS optimizes performance by preloading these files into the cache, achieving high IOPS and low latency. The final performance depends on the IOPS capacity of the cache media and the network environment of the JuiceFS client. To reduce potential read amplification from prefetching, users may consider disabling the prefetch feature. In addition, preloading files into the kernel's pagecache before model loading can significantly boost Safetensors file loading speed. This increases performance by an order of magnitude compared to reading from the JuiceFS cache.
- For other formats (sequential reads of large files): JuiceFS enhances sequential read performance via the prefetch feature. This anticipates future data requests and loads blocks into memory. By properly configuring the prefetch window size and increasing object storage access concurrency, JuiceFS can fully leverage object storage bandwidth. The read throughput limit is primarily affected by object storage bandwidth or dedicated line bandwidth. Warming up checkpoint or model files into the cache further improves performance. For example, when loading a checkpoint on a single server with 8 GPUs, and assuming sufficient network bandwidth, the throughput for warm reads can exceed 10 GB/s. This is more than enough to meet the performance requirements for this scenario. In addition, in the model file loading process during inference, by warming up the cache, the caching cluster only needs to fetch the complete model file from object storage once. After that, inference nodes can read from the cache, maximizing read throughput while also reducing bandwidth and operational costs associated with public cloud object storage.
Phase 4: Data distribution in hybrid cloud architectures
As LLMs become more popular, GPU resources are increasingly scarce. Users who need to conduct general model pretraining often face the challenge of collaborating across geographically distributed compute centers. This requires flexible data distribution in line with the location of computing resources.
JuiceFS addresses this through its mirror file system feature. It automatically synchronizes data from the primary site to other mirror sites. Metadata synchronization occurs within a defined time window, with intra-city latency as low as milliseconds and inter-city latency in the range of 10-30 milliseconds. Once metadata synchronization is complete, data can be accessed at all sites. If the actual data has not yet been fully replicated to a mirror site, the JuiceFS client will automatically route the request to the primary site's object storage to fetch the data. This ensures uninterrupted access, despite a potential performance decrease. This process is transparent to the user.
In a hybrid cloud architecture, to better manage costs, it’s recommended to deploy object storage at a single location and local cache clusters at each site that are large enough to store training data, aiming for a nearly 100% cache hit rate. Data is warmed up from shared object storage into the local cache clusters at each site, a deployment strategy widely adopted by users in AI scenarios.
The figure below shows a hybrid cloud compute cluster with one primary site and three mirror sites. Each site accelerates data access through a cache group.
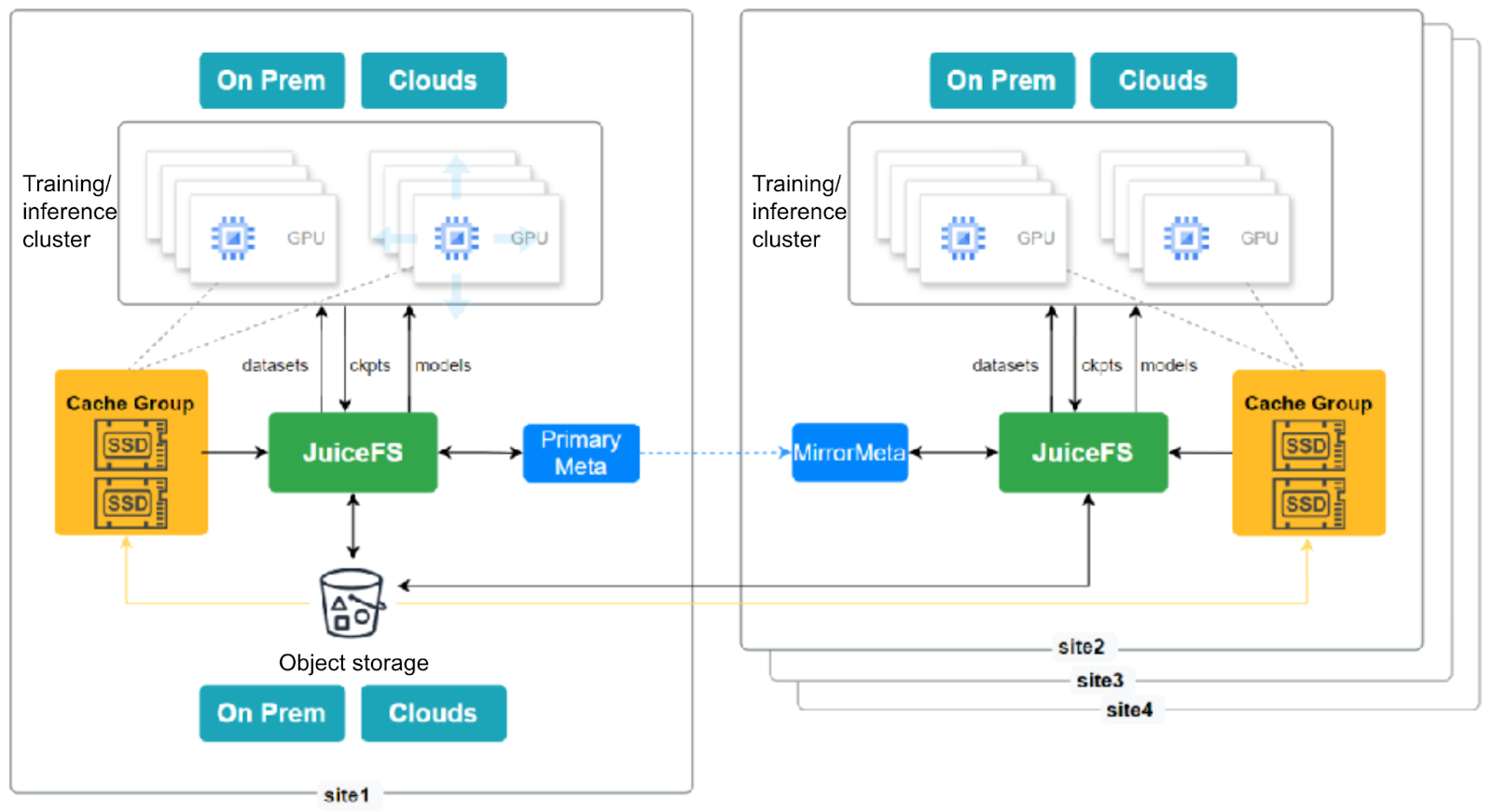
Notably, the latest Enterprise Edition of JuiceFS introduces writable capabilities for mirrored clusters. In multi-site training scenarios, when each mirror site’s training cluster saves checkpoint files and writes to the JuiceFS file system at its site, the data is automatically written to the primary site’s file system metadata and object storage and distributed to the other mirror sites. Metadata replication is synchronous, ensuring version consistency when writing data to mirrored clusters.
This feature simplifies and accelerates subsequent checkpoint recovery and model loading for inference services, ensuring data consistency across mirrored clusters for training and inference tasks. The write performance of mirrored sites is subject to dedicated line network conditions between the sites.
Summary
In response to the challenges posed by large-scale data and complex data flows, a common solution is to establish a unified data management system, often referred to as a data lake. This strategy uses a unified namespace to store different types of data on the backend, while offering diverse access methods on the frontend. This approach simplifies data movement within complex data pipelines, reducing both operational difficulty and cost.
When choosing a file storage system, users should consider several factors such as infrastructure, performance, compatibility, and ease of use to select the most suitable product. JuiceFS uses cost-effective object storage as the backend for data persistence and combines it with a multi-level caching architecture to offer a highly cost-effective storage solution.
In addition, this article discussed JuiceFS' practical use and optimization strategies across key stages:
- Checkpoint saving during training: The sequential writes of large checkpoint files require the file system to provide high-performance write throughput.
- Model loading during training and inference:
- For Safetensors checkpoint/model files, random reads of large files demand high IOPS and low I/O latency.
- For other formats (like checkpoint/model files), sequential reads of large files require the file system to provide high-performance read throughput.
- There are bandwidth bottlenecks to consider when many inference nodes load models concurrently.
- Data distribution in hybrid cloud architectures: JuiceFS supports consistent mirror read and write functionalities, addressing the needs for dataset distribution during multi-region collaborative training, checkpoint saving, and model deployment for multi-region inference services.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.