















In I/O-intensive scenarios such as AI model training and high-performance computing (HPC), the architecture and performance of the underlying file system directly impact training efficiency, resource utilization, and overall costs.
Lustre, a traditional high-performance file system, is renowned for its industry-leading performance, while JuiceFS prioritizes cloud-native design and seamless integration with object storage, offering greater deployment flexibility and cost efficiency.
To help users understand the differences between these systems in terms of architecture, performance optimization, and operational complexity, we present this comparative analysis for technical evaluation.
Architecture comparison
Lustre
Lustre is a parallel distributed file system designed for HPC environments. Initially, it was developed under U.S. government funding by national laboratories to support large-scale scientific and engineering computations. Now it’s now maintained primarily by DataDirect Networks (DDN). Lustre is widely adopted in supercomputing centers, research institutions, and enterprise HPC clusters.
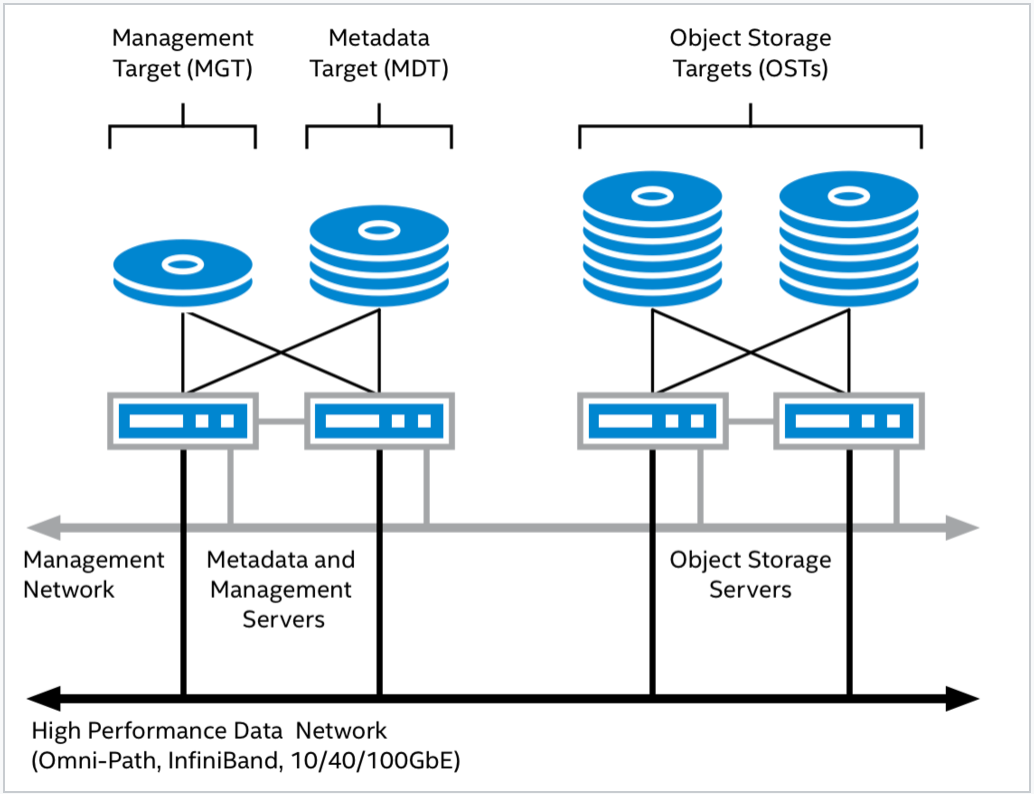
Core components:
- Metadata Servers (MDS): Handle namespace operations, such as file creation, deletion, and permission checks.
- Object Storage Servers (OSS): Manage actual data reads and writes, delivering high-performance large-scale read and write operations.
- Management Server (MGS): Acts as a global configuration registry, storing and distributing Lustre file system configuration information while remaining functionally independent of any specific Lustre instance.
- Clients: Provides applications with access to the Lustre file system through a standard POSIX file operations interface.
All components are interconnected via LNet, Lustre's dedicated networking protocol, forming a unified and high-performance file system architecture.
JuiceFS
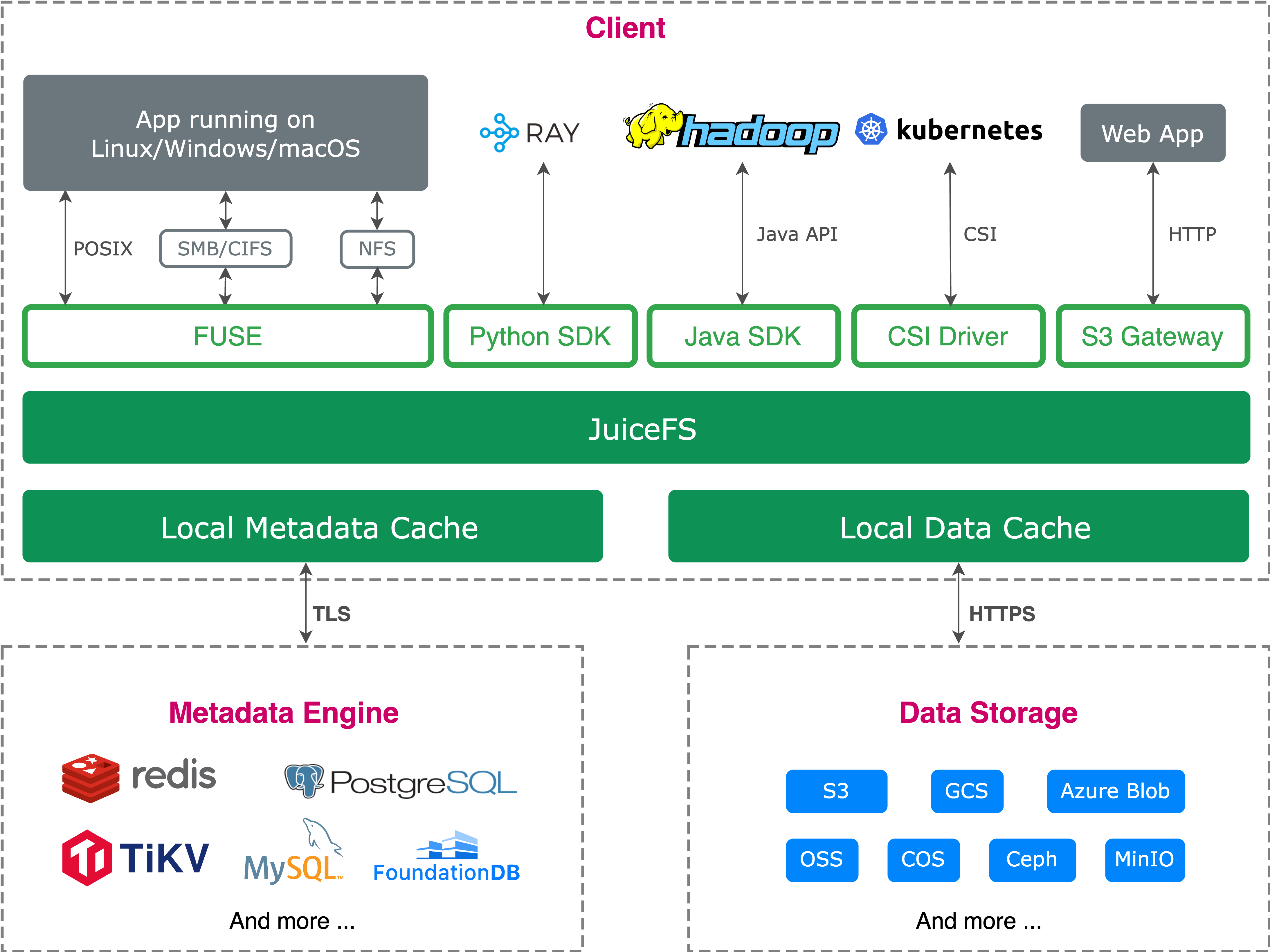
A cloud-native distributed file system that uses object storage to store data. The Community Edition supports integration with multiple metadata services and caters to diverse use cases. It was open-sourced on GitHub in 2021, now with 11.6k stars. Its Enterprise Edition is specifically optimized for high-performance scenarios, with extensive applications in large-scale AI workloads including generative AI, autonomous driving, quantitative finance, and biotechnology.
The JuiceFS file system architecture comprises three core components:
- The metadata engine: Stores file system metadata, including standard file system metadata and file data indexes.
- Data storage: Primarily utilizes object storage services, which can be a public cloud object storage or an on-premises deployed object storage service.
- Clients: Provides multiple access protocols, such as POSIX (FUSE), Hadoop SDK, CSI Driver, S3 Gateway.
Architectural differences
While Lustre and JuiceFS share similar modular architectures in terms of component organization and functional partitioning, their implementations are significantly different.
Client implementation
Lustre employs a C-language, kernel-space client architecture, while JuiceFS adopts a Go-based, user-space approach through Filesystem in Userspace (FUSE). Because the Lustre client runs in kernel space, there is no need to perform context switching between user mode and kernel mode or additional memory copying when accessing the MDS or OSS. This significantly reduces the performance overhead caused by system calls and has certain advantages in throughput and latency.
However, kernel-mode implementation also brings complexity to operation, maintenance, and debugging. Compared with user-mode development environments and debugging tools, kernel-mode tools have a higher threshold and are not easy for ordinary developers to master. Compared with C language, Go language is easier to learn, maintain, and develop, and has higher development efficiency and maintainability.
It’s worth noting that JuiceFS Enterprise Edition 5.2 introduces technical optimizations such as zero copy to reduce system call overhead and further improve performance.
Storage module
In terms of data storage, Lustre and JuiceFS use different implementation methods.
When deploying Lustre, one or more shared disks are usually required to store file data. This design stems from the fact that its early versions did not support file level redundancy (FLR). To achieve high availability (HA), when a node goes offline, its file system must be mounted to a peer node, otherwise the data chunks on the node will be inaccessible. Therefore, the reliability of the data depends on the high availability mechanism of the shared storage itself or the software RAID implementation configured by the user.
To ensure high availability and data consistency, detailed planning is usually required before deploying Lustre. Although the new version of Lustre supports FLR and a file can have multiple copies, the data consistency between the copies still needs to be synchronized and confirmed through manual commands. In addition, Lustre supports using ldiskfs or ZFS as the underlying local file system. Therefore, when using Lustre, you also need to understand and configure the corresponding local file system.
JuiceFS uses object storage as a data storage solution, thus enjoying several advantages brought by object storage, such as data reliability and consistency. The storage module provides a set of interfaces for object operations, including GET, PUT, HEAD, and LIST. Users can connect to specific storage systems according to their needs, including both object storage of mainstream cloud vendors and on-premises deployed object storage systems such as MinIO and Ceph RADOS. JuiceFS Community Edition provides local cache to cope with bandwidth requirements in AI scenarios, and the Enterprise Edition uses distributed cache to meet the needs of larger aggregate read bandwidth.
Metadata module
In terms of metadata services, both Lustre and JuiceFS provide unified namespace and file metadata management capabilities. To enable horizontal scaling of metadata access loads, Lustre introduced Distributed Namespace (DNE) starting with version 2.4. It allows distributing different directories across multiple MDS within a single file system. Lustre's MDS high availability relies on the coordinated implementation of software and hardware:
- Hardware level: The disks used by MDS need to be configured with RAID to avoid service unavailability due to single-point disk failure; the disks also need to have sharing capabilities so that when the primary node fails, the backup node can take over the disk resources.
- Software level: Use Pacemaker and Corosync to build a high-availability cluster to ensure that only one MDS instance is active at any time.
The metadata module of JuiceFS Community Edition, similar to the storage module, also provides a set of metadata operation interfaces. It can access different metadata services, including databases like Redis, TiKV, MySQL, PostgreSQL, and FoundationDB.
JuiceFS Enterprise Edition uses self-developed high-performance metadata services, which can balance data and hotspot operations according to load conditions to avoid the problem of metadata service hotspots being concentrated on certain nodes in large-scale training (such as frequent operations on metadata of adjacent directory files). At present, the data scale supported by the Enterprise Edition has reached hundreds of billions of files. For details, see this article.
File distribution comparison
Lustre file distribution
Normal file layout
Lustre's initial file distribution mechanism, known as normal file layout (NFL), segments files into multiple chunks distributed across object storage targets (OSTs) in a RAID 0-like striping pattern.
Key distribution parameters:
stripe count: Determines the number of OSTs across which a file is striped. Higher values improve parallel access but increase scheduling and management overhead.stripe size: Defines the chunk size written to each OST before switching to the next OST. That is, after the write reaches the set stripe size, the data is written to the next OST, which also determines the granularity of each chunk.
By properly configuring these two parameters, users can make a trade-off between performance and resource utilization and optimize the I/O behavior of the file system to adapt to specific application scenarios.
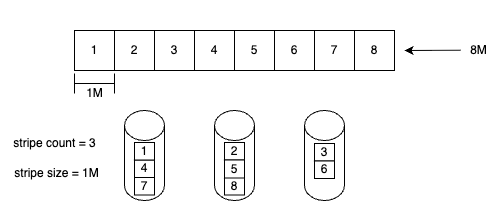
The figure above shows how a file with stripe count = 3 and stripe size = 1 MB is distributed across multiple OSTs. Each data block (stripe) is allocated to different OSTs sequentially via round-robin scheduling.
Key limitations of this layout:
The configuration parameters are immutable after file creation: Neither stripe count nor stripe size can be modified. However, file sizes often change dynamically in real-world scenarios (for example, through append operations). This inflexible layout strategy may lead to:
- ENOSPC (no space left): Since stripes are fixed to specific OSTs, write operations fail if any target OST runs out of space, even when other OSTs have available capacity.
- Storage imbalance: Even if the file data is evenly distributed between OSTs during the initial write, as different files are appended at different times, the usage growth rate of each OST is different. This results in unbalanced disk usage. Once an unbalanced state is formed, since the file distribution cannot be changed, this state will persist for a long time and continue to deteriorate.
Therefore, in large-scale, dynamically growing data scenarios, the static distribution strategy of NFL exhibits significant limitations in flexibility and resource utilization efficiency.
Progressive file layout
To address the constraints of NFL in handling dynamic data growth and resource allocation, Lustre introduced a new file distribution mechanism called progressive file layout (PFL).
PFL allows defining different layout policies for different segments of the same file, enabling adaptive distribution control based on file size or access pattern changes. By configuring multiple extents, users can assign different stripe counts and stripe sizes to specific file ranges, achieving more reasonable resource utilization and load sharing.
This mechanism offers the following advantages:
- Dynamic adaptation to file growth: Small files can use a smaller stripe count to reduce access overhead, while larger files can increase concurrency via higher stripe counts to improve bandwidth utilization.
- Mitigation of storage imbalance: By assigning different OST distribution policies to newly appended file sections, PFL helps alleviate disk load imbalance caused by appends.
- Improved space efficiency and flexibility: PFL supports automatic extent selection, allowing layout policies to adapt dynamically as files grow—without requiring manual user intervention.
Compared to traditional layout modes, PFL is better suited for high-performance access in large-file scenarios.
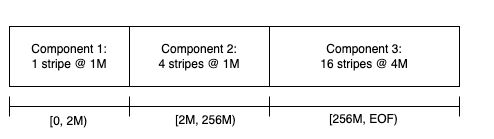
As shown in the figure above, this file adopts a progressive file layout (PFL), divided into three extents:
- The first extent
stripe size: 1 MBstripe count: 1- Purpose: Optimizes access efficiency for small files or initial file segments.
- The second extent
stripe size: 1 MBstripe count: 4- Purpose: Enhances concurrent I/O capability.
- The third extent
stripe size: 4 MBstripe count: 16- Purpose: Maximizes throughput for large-file access.
While PFL provides more adaptive layout strategies, it cannot fully resolve storage imbalance issues in practice. To address this, Lustre integrates lazy initialization technology for more efficient dynamic resource scheduling.
Lazy initialization is an allocation mechanism where physical storage locations are not assigned until the first write operation occurs. By integrating this approach, when the system detects uneven disk load, it can dynamically adjust distribution policies for unallocated file regions, redirecting new data writes to less-utilized OSTs.
Through the combined use of PFL + lazy initialization, Lustre achieves a more adaptive I/O distribution capability. This significantly alleviates storage imbalance caused by appending writing or file growth, while improving the maintainability of the system and the flexibility of data distribution.
File level redundancy
As previously mentioned, Lustre's traditional high availability (HA) implementation involves complex deployment and operational workflows. To simplify HA architecture and enhance fault tolerance, the community introduced file level redundancy (FLR).
FLR allows configuring one or more replicas for each file to achieve file-level redundancy protection. During write operations, data is initially written to only one replica, while the others are marked as STALE (outdated). Then, the system ensures data consistency through a synchronization process called Resync, which copies the latest data to all STALE replicas.
For read operations, any replica containing up-to-date data can serve as the data source, significantly enhancing both read concurrency and fault tolerance.
This mechanism provides Lustre with a more flexible and maintainable data redundancy solution without relying on shared storage or underlying RAID configurations. It’s particularly suited for large-scale distributed environments that demand higher availability requirements.
JuiceFS file distribution
JuiceFS manages data blocks according to the rules of chunk, slice, and block. The size of each chunk is fixed at 64 MB, which optimizes data search and positioning. The actual file write operation is performed on slices. Each slice is a specific chunk, which represents a continuous write process. It does not cross the chunk boundary, so its length does not exceed 64 MB. Chunks and slices are mainly logical divisions, while a block (4 MB by default) is the basic unit of physical storage. It implements the final storage of data in object storage and disk cache. For details, see the JuiceFS architecture document.
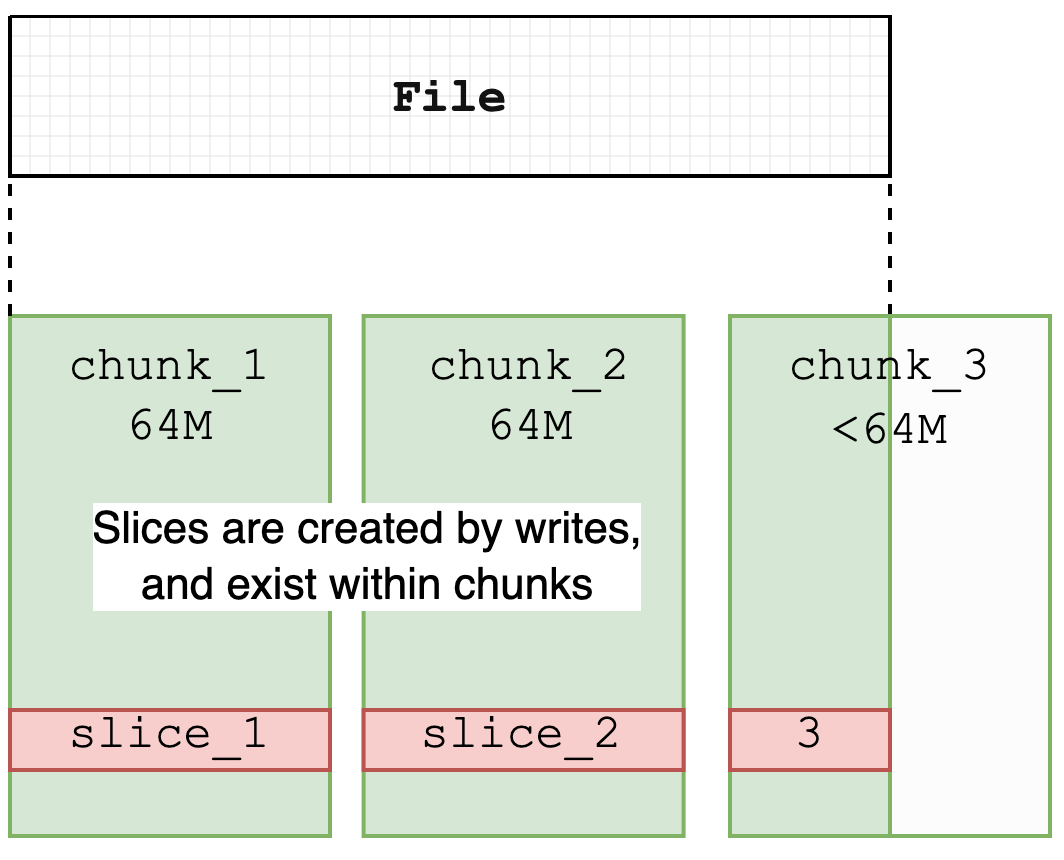
Slice in JuiceFS is a structure that is not common in other file systems. It records file write operations and persists them in object storage. Object storage does not support in-place file modification, so JuiceFS allows file content to be updated without rewriting the entire file by introducing the slice structure. This is somewhat similar to the Journal File System, where write operations only create new objects instead of overwriting existing objects. When a file is modified, the system creates a new slice and updates the metadata after the slice is uploaded, pointing the file content to the new slice. The overwritten slice content is then deleted from the object storage through an asynchronous compression process, causing the object storage usage to temporarily exceed the actual file system usage at certain moments.
In addition, all slices of JuiceFS are written once. This reduces the reliance on the consistency of the underlying object storage and greatly simplifies the complexity of the cache system, making data consistency easier to ensure. This design also facilitates the implementation of zero-copy semantics of the file system and supports operations such as copy_file_range and clone.
Feature comparison
| Comparison item | Lustre | JuiceFS Community Edition | JuiceFS Enterprise Edition |
|---|---|---|---|
| Metadata | Distributed metadata service | Independent database service | Proprietary high-performance distributed metadata engine (horizontally scalable) |
| Metadata redundancy | Requires storage device support | Depends on the database used | Triple replication |
| Data storage | Self-managed | Uses object storage | Uses object storage |
| Data redundancy | Storage device or async replication | Provided by object storage | Provided by object storage |
| Data caching | Client local cache | Client local cache | Proprietary high-performance multi-replica distributed cache |
| Data encryption | Supported | Supported | Supported |
| Data compression | Supported | Supported | Supported |
| Quota management | Supported | Supported | Supported |
| Network protocol | Multiple protocols supported | TCP | TCP |
| Snapshots | File system-level snapshots | File-level snapshots | File-level snapshots |
| POSIX ACL | Supported | Supported | Supported |
| POSIX compliance | Compatible | Fully compatible | Fully compatible |
| CSI Driver | Unofficially supported | Supported | Supported |
| Client access | POSIX | POSIX (FUSE), Java SDK, S3 Gateway, Python SDK | POSIX (FUSE), Java SDK, S3 Gateway, Python SDK |
| Multi-cloud mirroring | Not supported | Not supported | Supported |
| Cross-cloud/region replication | Not supported | Not supported | Supported |
| Primary maintainer | DDN | Juicedata | Juicedata |
| Development language | C | Go | Go |
| License | GPL 2.0 | Apache License 2.0 | Commercial software |
Summary
Lustre is a high-performance parallel distributed file system where clients run in kernel space, interacting directly with the MDS and OSS. This architecture eliminates context switching between user and kernel space, enabling exceptional performance in high-bandwidth I/O scenarios when combined with high-performance storage devices.
However, running clients in kernel space increases operational complexity, requiring administrators to possess deep expertise in kernel debugging and underlying system troubleshooting. In addition, Lustre's fixed-capacity storage approach and complex file distribution design demand meticulous planning and configuration for optimal resource utilization. Consequently, Lustre presents higher deployment and maintenance barriers.
JuiceFS is a cloud-native, user-space distributed file system that tightly integrates with object storage and natively supports Kubernetes CSI, simplifying deployment and management in cloud environments. Users can achieve elastic scaling and highly available data services in containerized environments without needing to manage underlying storage hardware or complex scheduling mechanisms. For performance optimization, JuiceFS Enterprise Edition employs distributed caching to significantly reduce object storage access latency and improve file operation responsiveness.
From a cost perspective, Lustre requires high-performance dedicated storage hardware, resulting in substantial upfront investment and long-term maintenance expenses. In contrast, object storage offers greater cost efficiency, inherent scalability, and pay-as-you-go flexibility.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.