















StepFun focuses on researching and developing multimodal large language models (LLMs). The company has developed 22 foundation models, 16 of which are multimodal, covering text, speech, images, video, music, and reasoning. To support the development and deployment of these multimodal models, the infrastructure team must handle the entire pipeline from data generation and cleaning to model pre-training, post-training, and inference deployment. This places extremely high demands on the storage system in terms of data throughput, access latency, and read/write efficiency.
As the application scale rapidly expanded, our early adoption of a commercial storage system revealed limitations in scalability, stability, and operational complexity, making it difficult to meet the growing storage needs of multimodal large models. Consequently, we began exploring lighter, more flexible, controllable, and cost-effective alternatives. We integrated JuiceFS with our self-developed object storage due to its excellent usability. It eventually evolved into a unified file system access layer, connected to high-performance and large-capacity storage while enabling automatic and transparent migration of cold and hot data.
Currently, we’ve deployed both the community and enterprise editions of JuiceFS in production environments, covering core scenarios such as model training and inference deployment.
In this article, we’ll share our team’s optimization practices based on the community edition and our first-hand experience in enterprise-level multimodal large model deployment.
Storage requirements for LLMs
Data collection and cleaning
In the data collection and cleaning phase, our company has a dedicated data team responsible for processing backflow data and cleaning tasks. These operations place high performance demands on the storage system, particularly for high bandwidth and QPS. In practice, data collection often requires terabyte-level bandwidth, nearly saturating system bandwidth while maintaining high concurrent access.
In addition, big data processing is another critical scenario. Whether using frameworks like Spark, Ray for task scheduling, or various data analysis workflows, all heavily rely on the underlying storage system. This demands high throughput, stability, and scalability.
Model training
During model training, the storage system’s core requirement lies in efficient dataset reading. Read latency must typically be controlled at the microsecond to millisecond level; otherwise, training progress slows significantly. For example, a pre-training task that originally takes two months could extend by at least a week if the storage read speed drops by 10%.
Different data organization methods also lead to different I/O access patterns:
- Packaged datasets face high-concurrency random read challenges.
- Unpackaged datasets involve handling numerous small files, placing higher demands on the file system’s metadata performance.
Another critical challenge is checkpoint read/write performance. Checkpoint operations during training are primarily sequential, and LLM checkpoints can reach terabyte scale. This requires not only high-speed write capabilities but also fast recovery reads during failures, demanding extremely high bandwidth.
Model inference
The inference phase also imposes high performance requirements on storage. Although quantized models are smaller, terabyte-scale models still shrink to hundreds of gigabytes. GPU resources from major cloud providers often experience tidal load fluctuations, requiring dynamic scaling during traffic spikes. Model loading frequently becomes the bottleneck in scaling, so the storage system must support high-concurrency access and large-bandwidth reads to ensure rapid model loading.
Summary of LLM storage requirements:
- Metadata: Support for tens to hundreds of billions of files to manage massive small files in data processing and training.
- High capacity: Single file system capacity must scale from petabytes to tens of petabytes to accommodate long-term training data and model archives.
- Low latency: Microsecond-to-millisecond response for random small I/O and small file access to ensure low-latency data loading.
- High bandwidth: Sequential reads/writes for checkpoints often reach hundreds of gigabytes, requiring sustained bandwidth.
- POSIX compliance: Standard POSIX semantics to allow algorithm engineers to access data as local files, reducing engineering overhead.
- Cost efficiency: Support for data tiering between high-performance low-capacity and low-performance high-capacity media to reduce overall storage costs.
Why JuiceFS?
We introduced JuiceFS into our LLM development pipeline for several reasons:
- Flexible adaptation: Seamless integration with multi-cloud environments and self-built data centers. Storage follows compute resources, enabling data mobility wherever computing is available.
- Minimal development overhead: JuiceFS’ codebase (about 80k lines) is far simpler than traditional storage systems (like C++ solutions), making customization easier.
- Full-stack compatibility: Excellent POSIX semantics support ensures stability across diverse workflows. Seamless HDFS and S3 Gateway integration simplifies internal data flows. This makes data exchange and management more efficient.
We use both JuiceFS Enterprise and Community Editions, as detailed below.
JuiceFS Enterprise Edition usage and optimizations
Model distribution and cache optimization for multi-cloud inference
For inference deployment, we built a multi-cloud model synchronization and caching system using JuiceFS Enterprise Edition. Our goal was to achieve efficient cross-cloud distribution and fast loading warm-up of models to cope with dynamic inference requirements under multi-cloud resource scheduling.
The operational workflow: When users deploy models, the system performs targeted synchronization to destination cloud environments based on each cloud provider's resource utilization. Leveraging JuiceFS' distributed synchronization tool juicesync, we efficiently distribute 100 GB+ scale models to multiple data center deployments of JuiceFS, significantly reducing cross-cloud data transfer costs and complexity.
After model synchronization is done, the system executes warm-up operations to preload model files into cache nodes along the inference path via JuiceFS. This warm-up mechanism effectively mitigates cold-start latency caused by large model sizes, dramatically improving both response speed during scaling events and inference stability.
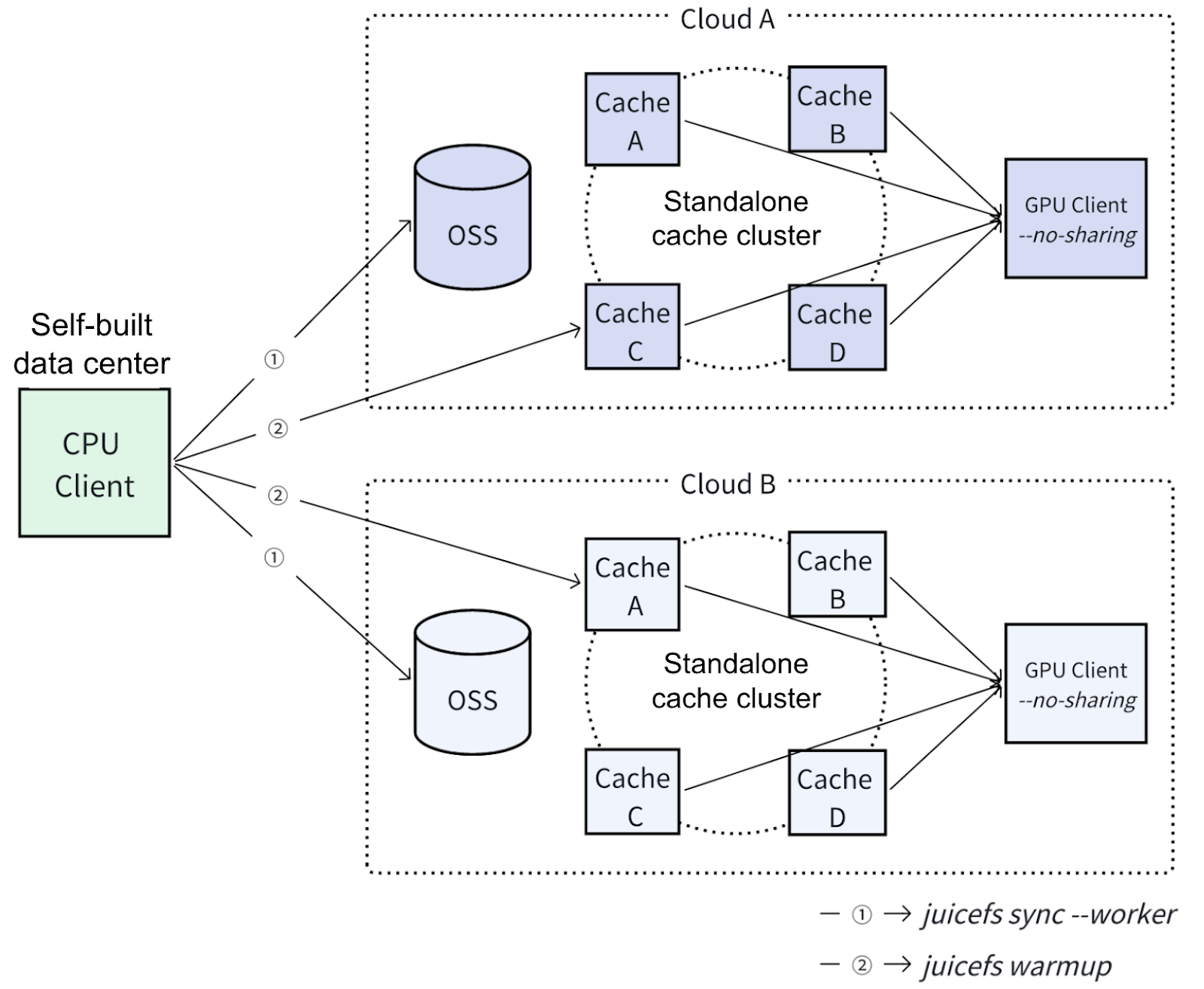
A critical consideration is that some cloud providers' GPU nodes lack local NVMe storage. Even if the GPU nodes have disks, they may be affected by resource fluctuations or hardware failures and may go online and offline frequently during operation. This makes them unsuitable for caching tasks. To ensure cache persistence and stability, we deploy caching services on a limited set of stable non-GPU general-purpose compute nodes. Using JuiceFS' flexible mounting mechanism, we achieve decoupled, independent cache management separate from compute nodes. This solution has been operating stably across multiple cloud platforms, becoming a foundational storage component of our multi-cloud architecture.
Safetensors random read performance optimization
In inference scenarios, we encountered a classic challenge: read amplification. When models are deployed, they are typically converted to the safetensors format. This triggers intensive mmap random reads during loading. While JuiceFS achieves 100% cache hit rates in these cases, this workload isn't its native strength. Practically, users still experience constrained read bandwidth, leaving system resources underutilized.
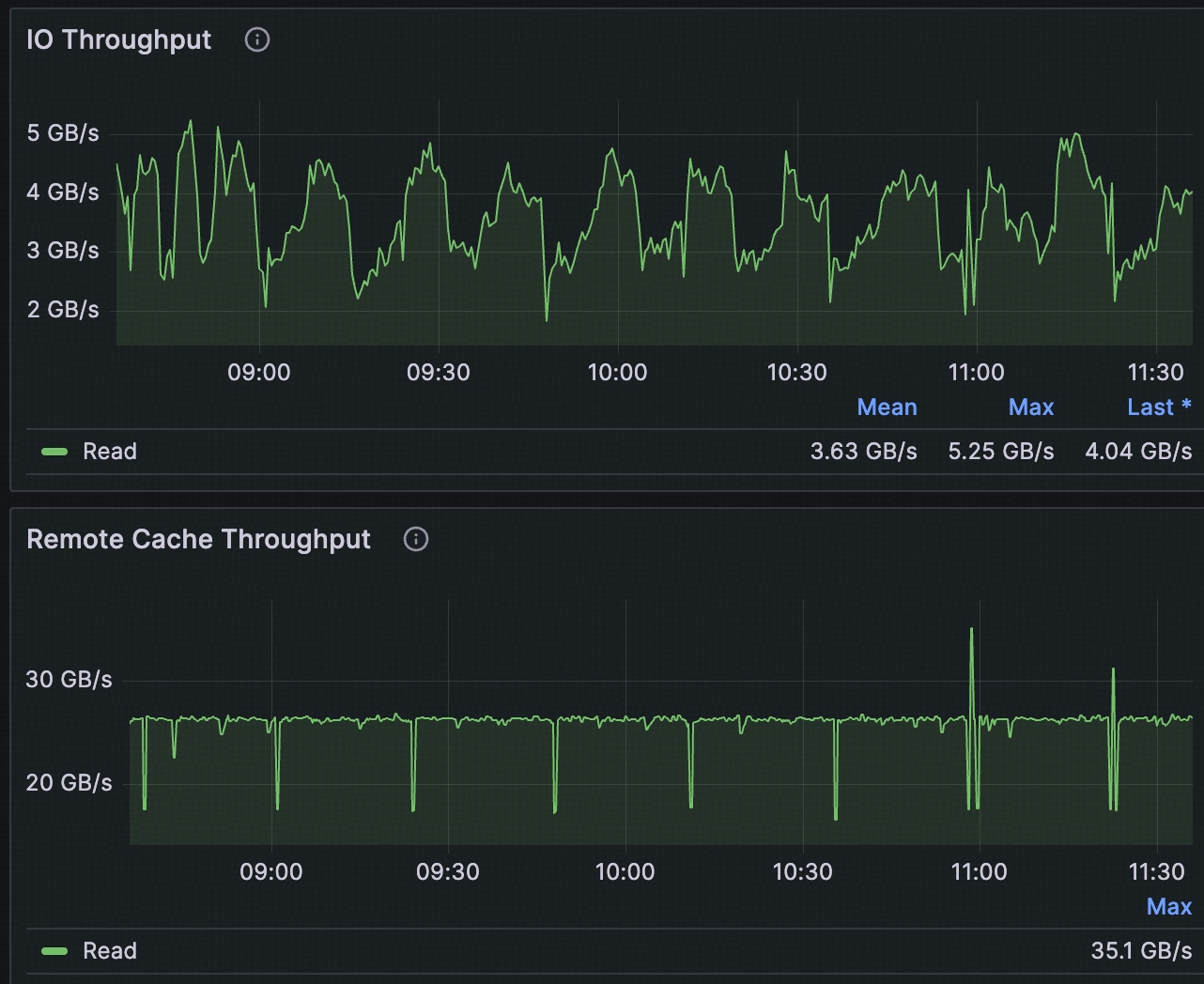
The monitoring data figure below shows:
- User observed bandwidth: Fluctuates between 3–5 GB/s
- Backend remote cache throughput: Steadily maintains about 25 GB/s
This performance gap primarily stems from JuiceFS' readahead strategy. The system prefetches substantially more data than actually required, causing severe read amplification and bandwidth waste. The system incurs multiple times the necessary cost to fulfill current read demands.
The figure below shows the system's read amplification changes before and after optimization. Before optimization, read amplification reached as high as 1042%. This means the system incurred over 10x the I/O cost to retrieve the actually required data. After optimization, read amplification dropped significantly and remained stable at about 300%, with obvious improvements in both read efficiency and bandwidth utilization.

We implemented the following optimization measures:
- We implemented a two-level caching mechanism where the primary cache utilizes GPU machine memory, effectively containing read amplification within local memory and eliminating pressure on remote bandwidth. This was achieved by configuring the parameters
cache-dir=memoryandcache-size=10240to fully leverage the substantial memory resources available on GPU machines. - We disabled JuiceFS' default readahead mechanism by setting
max-readahead=1, preventing the system from prefetching non-essential data and thereby significantly reducing overhead from random read operations. In JuiceFS Enterprise Edition 5.2, read amplification is optimized at the code level. Internal testing demonstrated that safetensors' read amplification could be maintained at about 1x.
JuiceFS Community Edition optimizations
JuiceFS Community Edition is more widely used within our infrastructure, supporting data collection, model training, and big data scenarios. As such, we've implemented numerous optimizations for the community edition. This section will focus on stability improvements for 10,000+ clients and writeback cache optimizations, while briefly mentioning other enhancements.
Stability for 10k+ clients
Early monitoring revealed that when clients grew to 2,000–3,000, TiKV nodes quickly hit performance limits. We found that:
- Each TiKV instance (bound to a single disk) reached nearly 6 GB/s read bandwidth, saturating NVMe throughput.
- Frequent Region splits and prewrite errors indicated severe transaction conflicts under high concurrency.
These issues became critical bottlenecks for large-scale JuiceFS deployments, impacting both system stability and horizontal scalability.
To address this issue, we implemented the following optimizations:
- We found that TiKV's bottleneck primarily stemmed from numerous high-frequency scan operations. Given the significant overhead these scans impose on TiKV, we extended the interval between background scan tasks and reduced their execution frequency. In JuiceFS versions prior to 1.3, certain scan jobs ran at minute-level intervals. As client connections increased, this design caused TiKV resource pressure to escalate rapidly.
- For read request paths, we implemented metadata caching to fully leverage the kernel's caching mechanism. The Linux kernel proves to be a reliable tool—once we explicitly mark data as safely cacheable, the kernel automatically activates appropriate caching strategies, significantly reducing pressure on the metadata engine.
- For simple read-only transactions, we adopted TiKV's point get optimization. This approach bypasses unnecessary distributed transaction processes, dramatically decreasing access to the Placement Driver (PD) while improving related operation performance by about 50%.
- For write requests, we addressed significant transaction conflicts. In TiKV, these conflicts were causing numerous write failures. While JuiceFS defaults to optimistic concurrency control for conflict resolution, we observed that this approach exacerbated issues in high-contention scenarios. We explored switching certain interfaces to pessimistic locking, but ultimately did not proceed with this change due to its substantial codebase impact.
Notably, all these optimizations have been merged into JuiceFS Community Edition. Users running version 1.3 or later can benefit from these improvements directly—a modest but meaningful contribution we're proud to have made to the JuiceFS community.
Compatibility in heterogeneous environments
As our servers come from different vendors and procurement channels, the hardware environment exhibits significant variability. For example, some nodes lack data disks entirely; others feature NVMe drives, but with varying quantities; certain systems operate without RAID configurations; even mount points are different across nodes.
These disparities introduced major challenges for unified system management and operations, making heterogeneous hardware compatibility a critical issue to resolve.
To address this, we developed an enhanced JuiceFS CSI Node solution for optimal adaptation. Specifically:
- CSI Node is deployed as a DaemonSet on each node.
- It dynamically detects node-specific hardware information, such as disk type, capacity, and memory.
- Based on these metrics, it automatically generates Mount Pod parameters.
- This enables hardware-aware flexible mounting per node.
This solution effectively simplifies storage management in heterogeneous environments and ensures system consistency and performance on heterogeneous hardware platforms.
Multi-tenant S3 Gateway support
This challenge originated from legacy tools with strict dependencies on the S3 protocol. While some tools could only access data via S3 interfaces, JuiceFS' native gateway was originally limited to processing requests for a single volume per instance. Given our internal environment with hundreds of independent volumes, deploying dedicated gateway instances for each volume would have incurred excessive resource overhead and created significant operational burdens.
To resolve this, we enhanced the gateway to support multi-volume request processing within a single instance. Now, users can access their respective volumes through a unified endpoint just like a standard S3 service, enabling efficient resource sharing in multi-tenant environments. This optimization dramatically improves both scalability and operational efficiency.
In addition, we integrated our corporate identity and access management (IAM) authentication system to reinforce security and tenant isolation capabilities.
Tiered data migration and warm-up between hot/cold storage
We currently operate a large-scale OSS cluster, with a smaller GPFS-based hot storage system (legacy infrastructure with petabyte capacity). Originally, user workloads—particularly checkpoint read/write operations—relied heavily on GPFS. However, rapid data growth has strained GPFS capacity, creating scaling challenges for our storage architecture. To maintain system stability and performance, we implemented optimized data tiering and warm-up between hot and cold storage layers.
To address this challenge, we implemented a series of optimizations:
- We configured JuiceFS'
cache-dirto point to GPFS mount points, leveraging JuiceFS' native cache management for automatic hot data migration. This enabled efficient segregation and transfer between hot/cold storage. - Through custom development, we preserved local disk support to establish a two-level caching hierarchy: data is first read from the local NVMe hard disk; if there is a local miss, it falls back to access GPFS or OSS. This strategy significantly improves read performance, especially in scenarios where data access is local, and effectively reduces access latency.
- In addition to read caching, we also support write caching capabilities. In particular, we enable writeback mode during the checkpoint data writing process. This makes the writing process more fault-tolerant and has higher throughput performance, thus improving the reliability and performance of data writing.
Through the optimizations above, we achieved efficient data migration and access acceleration between hot and cold storage. This ensures the stability of the system during scaling and meeting growing application needs.
Writeback cache and cross-datacenter access optimization
To enhance write performance, we heavily rely on JuiceFS' writeback mechanism. However, the default writeback implementation has two critical challenges:
- Data security: In the writeback mode, the system returns a success response to the user as soon as the data is written to the local disk. However, if the local disk is damaged or the process terminates abnormally, there is a risk of data loss.
- Data visibility: When data remains in the local cache and has not yet been uploaded to OSS, it’s inaccessible to other nodes. In cases of heavy accumulation, the visibility delay can even reach hours.
To address these two issues, we configured the writeback cache directory on GPFS, which provides disaster recovery capabilities, ensuring that cached data is directly written to stable shared storage. This not only guarantees data security but also enables real-time cross-node data visibility.
In addition, this design offers extra benefits. By adding a FUSE layer on top of GPFS, the writeback mechanism abstracts the heterogeneity of the underlying storage. This allows the system to seamlessly integrate with other high-performance storage solutions beyond GPFS, achieving unified and transparent storage access.
In cross-data center deployment scenarios, this solution still faces the two core problems of writeback: Since GPFS is not deployed across data centers, when data is written in one data center, other data centers cannot access it until the data is synchronized to OSS, resulting in persistent data visibility issues.
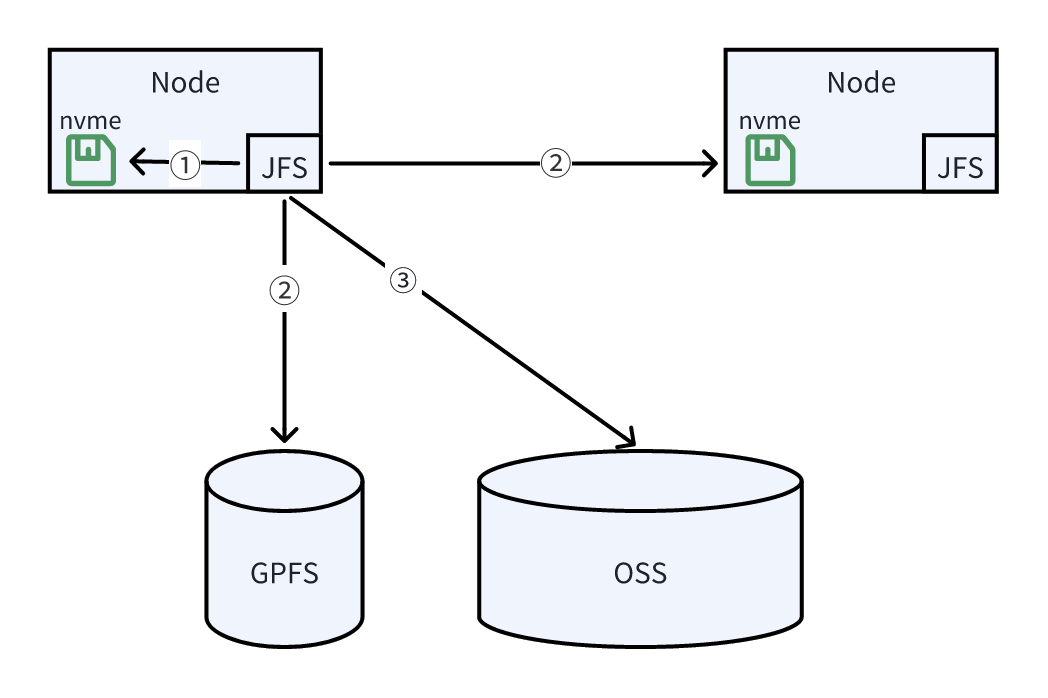
To address the data access latency across data centers, we introduced a P2P read feature, enabling cross-data center data sharing. The final data read workflow is as follows:
- Prioritize reading from the local disk: If the data exists locally, return it directly.
- Parallel querying of GPFS and P2P nodes: Simultaneously send requests to GPFS and remote peer nodes, using the first response received.
- Fall back to OSS: If neither of the above sources returns the data, retrieve it from OSS.
This mechanism ensures performance while improving data availability and access efficiency in cross-data center scenarios.
I’ve been following and contributing to the JuiceFS project since its open-source release in 2021. Initially introduced for inference scenarios, the system has gradually evolved into our internal unified file system access layer, covering critical stages of large-model development, including data generation, training, and inference. Its object-storage-based architecture significantly reduces our data storage costs, and its strong compatibility allows seamless integration into various systems across multi-cloud and heterogeneous environments. These features align perfectly with our key demands for flexibility, stability, and cost efficiency. I hope these practical insights can serve as a reference for peers in large-model infrastructure development.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.