















Zelos Tech is a high-tech company focused on autonomous driving and unmanned delivery technologies, possessing independent R&D and large-scale deployment capabilities for autonomous driving systems and AI chips. Our core products have been widely deployed in 200+ cities across China, with a vehicle sales market share exceeding 90%. We maintain a leading position in the Chinese L4 urban autonomous delivery sector.
As our application expanded rapidly, our data volume grew from terabytes to petabytes. The original Ceph-based storage solution faced high costs and maintenance pressures, while performance bottlenecks gradually emerged in handling small files, metadata, high concurrency, and latency. This impacted simulation and training efficiency.
Furthermore, accelerated algorithm iteration and cross-regional application deployment increased the frequency of data transfer and resource scheduling needs across multi-cloud environments. Challenges included dispersed data, high migration costs, and complex scheduling. Limited community support and slow response times for some storage tools increased the operational complexity.
Facing these challenges, we needed to build a cloud-native storage architecture with high cost-effectiveness, strong scalability, and easy maintainability. After evaluating solutions like Alluxio and CephFS, we chose JuiceFS as our unified storage infrastructure. Currently, we’ve fully migrated critical data—including production, simulation, training, and inference—to JuiceFS, establishing an efficient, flexible, and unified storage foundation that comprehensively supports massive data processing requirements for various autonomous driving scenarios.
In this article, I’ll share the storage challenges we faced at Zelos Tech in autonomous driving R&D, why we chose JuiceFS over Alluxio and CephFS, and how we use it effectively in multi-cloud environments.
Autonomous driving training process and storage challenges
We’re currently dedicated to the R&D of L4 autonomous driving technology, primarily focusing on urban intelligent delivery logistics. The training process for autonomous driving models generates vast amounts of data and involves complex processing steps. The basic steps are as follows:
- Data collection and upload: Data is collected from vehicles after calibration work and subsequently uploaded.
- Algorithm processing: The algorithm team extracts relevant data for model training or algorithm improvement and then passes the results to the simulation stage for scoring.
- Simulation verification and modification: If simulation fails, the process returns to the algorithm team for modification. If successful, it proceeds to the simulated environment verification stage.
- Test vehicle validation: After passing simulated environment verification, tests are conducted on test vehicles. If the test fails, the process returns to the modification stage. If successful, the model is released via over-the-air (OTA) technology.
Throughout this process, data volume increases dramatically. Each vehicle uploads 10+ gigabytes of data daily. As the vehicles grew, the total data volume reached petabytes. Efficiently extracting and utilizing this massive data, especially during model training, places extremely high demands on the storage system's performance, scalability, and stability.
To meet the data requirements of the entire autonomous driving R&D pipeline, we needed to establish a storage platform with the following characteristics:
- High-performance I/O: Capable of supporting high-concurrency reads and low-latency access for massive data during training and simulation.
- Elastic scalability: Able to flexibly scale to petabyte-level or higher storage needs as the vehicle scale grows.
- Multi-cloud compatibility: Supporting unified access across multiple clouds and self-built environments, ensuring data transfer and consistency.
- Ease of operation: Providing simplified management and monitoring capabilities to reduce operational complexity and ensure long-term stability.
- Cost-effectiveness: Controlling overall storage costs while guaranteeing performance and stability, maximizing resource utilization.
Storage selection: JuiceFS vs. Alluxio vs. CephFS
We tried various storage solutions, including Alluxio, JuiceFS, and CephFS.
Alluxio uses master nodes for metadata management, which has a steep learning curve. It requires separate deployment of master and worker clusters, increasing operational complexity. We encountered issues like hangs and I/O exceptions when using the community edition.
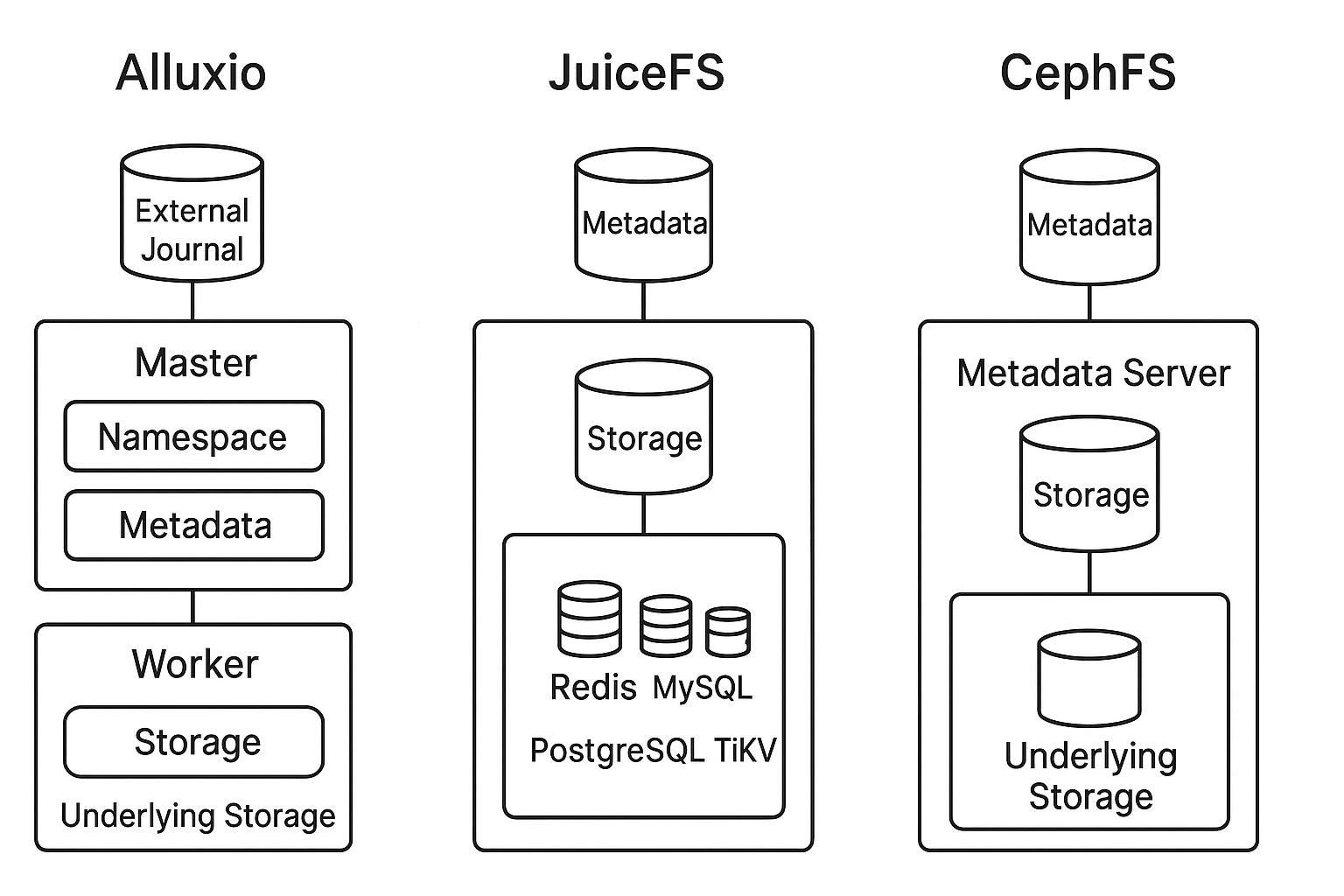
Regarding CephFS, its metadata is stored in its own Ceph Metadata Server (MDS), while data is stored in RADOS. In contrast, JuiceFS supports various backend storage options (like S3 and OSS) and can use external databases (like Redis and TiKV) for metadata management. This results in a more flexible architecture.
Furthermore, deploying and tuning CephFS is extremely complex, requiring deep involvement from specialized teams. When building our own Ceph cluster, we found that expanding OSDs and data rebalancing were time-consuming, small file write performance was poor, and tuning was difficult due to the complex architecture. Therefore, we abandoned this solution.
The table below compares key features of JuiceFS and CephFS. For a detailed comparison, see this document.
| Feature | CephFS | JuiceFS |
|---|---|---|
| Data storage | RADOS object storage | Object storage (S3/OSS/COS) |
| Metadata storage | Managed by MDS, metadata is stored within RADOS | External database (Redis/MySQL/PostgreSQL/TiKV) |
| Interface | POSIX, CSI (K8s) | POSIX, S3 API, HDFS API, CSI |
| Caching | Client cache (optional) | Client cache + configurable memory/SSD |
| Scalability | Depends on scaling MDS & OSD within the Ceph cluster | Independent scaling of metadata and data, high flexibility |
| Deployment complexity | High, requires a full Ceph cluster | Lightweight, requires only object storage + database |
| Data security | Supports replication/erasure coding, high reliability | Metadata can be persisted to the database; data reliability depends on the object storage |
| Performance characteristics | High throughput, low latency (depends on the Ceph cluster) | High throughput, especially with significant client cache acceleration for small file access scenarios |
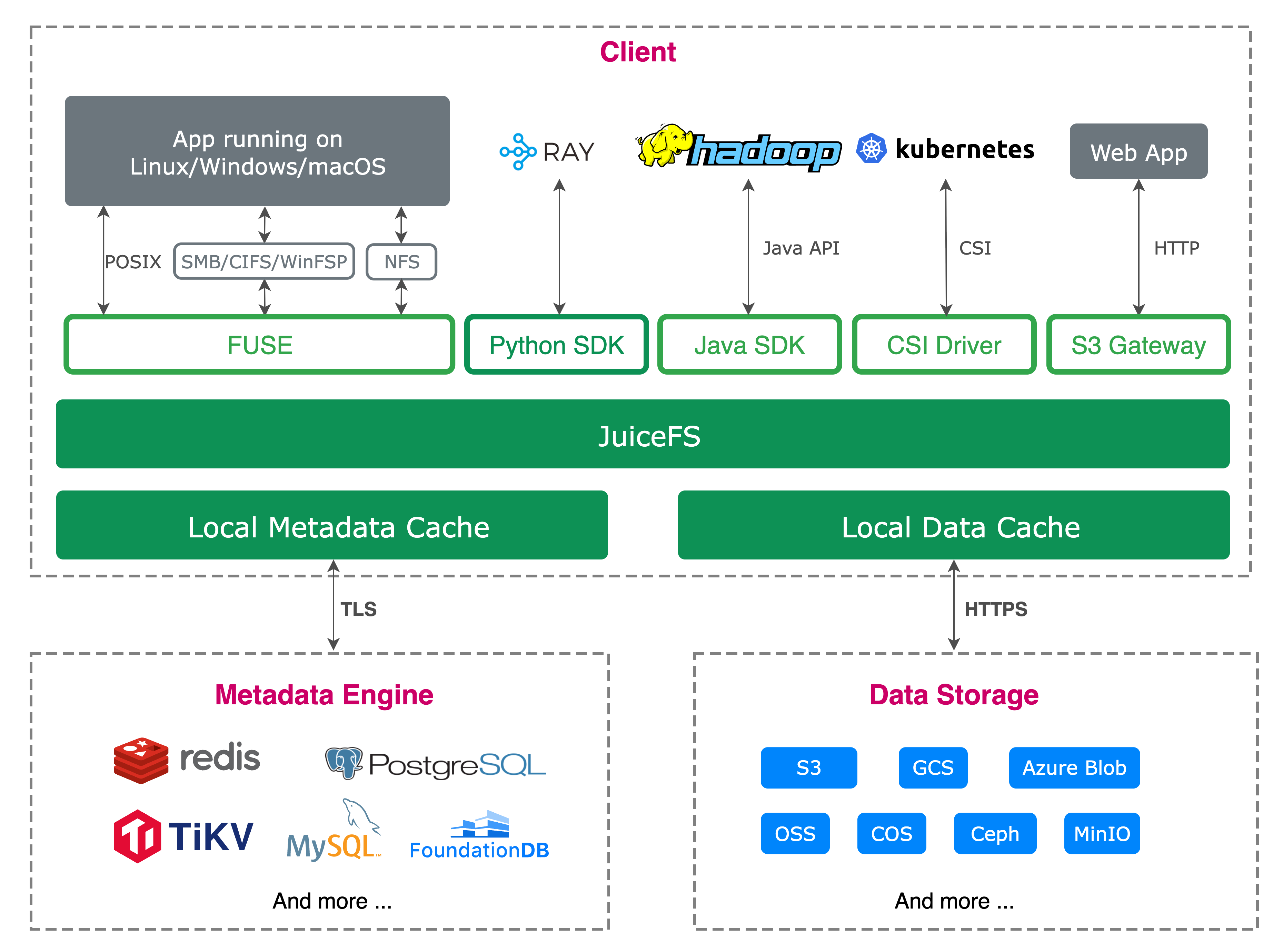
JuiceFS enables seamless integration of various object storage systems into local environments and supports multi-host concurrent reads/writes across platforms and regions. By separating data and metadata storage, it stores file data in object storage after splitting, while metadata is stored in databases like Redis, MySQL, PostgreSQL, TiKV, or SQLite. Users can flexibly choose based on actual scenarios and performance needs, greatly simplifying operational work.
In comparison, JuiceFS excels in multiple aspects—particularly in high-concurrency reads of small files, where its performance meets our requirements. Thus, we fully migrated to JuiceFS about a year ago and have widely adopted it in our multi-cloud architecture.
JuiceFS in multi-cloud environments
JuiceFS adopts a storage architecture that decouples metadata and data:
-
The metadata layer supports multiple database engines, such as Redis, MySQL, PostgreSQL, TiKV, and SQLite, allowing users to choose based on application scale and reliability needs.
-
The data layer uses mainstream object storage for seamless integration with diverse storage systems.
Currently, our system is deployed across multiple cloud platforms like AWS, with JuiceFS serving as the core storage component. In different environments, we flexibly pair backend storage with metadata engines:
- In self-built data centers, we use MinIO as object storage with Redis for metadata management.
- In public clouds, we combine OSS with Redis.
This architecture enhances flexibility and has remained stable over a year of operation, fully meeting application needs with excellent availability and user experience.
In Kubernetes clusters, we deploy JuiceFS using its CSI driver, ensuring strong compatibility with Kubernetes. We use the official Helm charts to create and manage JuiceFS storage volumes, configuring charts tailored to different applications to connect with backend Redis and OSS storage.
On the local node, we allocate NVMe SSDs for JuiceFS caching, mounted under the /data directory. As a cache layer, this significantly improves read performance. Once data is cached, subsequent reads for the same file are served directly from the local NVMe disk, achieving high read/write efficiency.
JuiceFS in the training platform
Our training platform architecture consists of multiple layers:
- The infrastructure layer includes storage, network, compute resources, and several data service instances and hardware devices.
- The upper layer is the containerization layer, built on a Kubernetes cluster, supporting various services. The platform provides deep GPU computing support, multiple development language environments, and mainstream deep learning frameworks.
On the deep learning platform, users can submit training jobs via Notebook or a VR interface. After submission, the system schedules and allocates resources through the Training Operator. For storage, we pre-provisioned storage resources based on Persistent Volume Claims (PVCs) and used JuiceFS to automatically associate and supply the underlying storage.
We integrated JuiceFS into the Kubeflow machine learning platform for model training tasks. When creating a training job in the Notebook environment, the system automatically associates with the StorageClass provided by the backend JuiceFS, enabling dynamic storage allocation and management. Simultaneously, a monitoring system deployed in the cluster observes storage performance in real time. Current monitoring shows read throughput about 200 MB/s, with low write requests—consistent with the read-heavy I/O pattern typical of our training and inference scenarios.
During performance tuning, we referenced JuiceFS community users’ sharing and compared Redis and TiKV as metadata engines. Test results showed that TiKV significantly outperformed Redis in read-intensive scenarios. Therefore, we plan to gradually migrate the metadata engine for some training clusters to TiKV to further improve read efficiency.
Currently, one of our storage buckets holds approximately 700 TB of data, comprising 600 million files. This includes a vast number of small files, typical for data organization in AI training tasks. In practice, JuiceFS has demonstrated excellent and stable performance under high-concurrency small file read/write operations, with no anomalies, fully meeting production demands.
In simulation scenarios, the data scale has reached petabyte levels, with storage buckets primarily containing large files. The underlying storage resources rely on a cloud object storage solution, mainly used for centralized storage of simulation data. This storage solution has also proven stable in practice, supporting the continuous operation of large-scale simulation tasks.
Data synchronization across multi-cloud environments with JuiceFS
To achieve data synchronization across multi-cloud environments, we deployed multiple dedicated lines between different cloud service providers and established cross-cloud network connectivity beforehand. For training data requiring consistency across clouds, we developed a synchronization tool that integrates the underlying juicefs sync command. It efficiently syncs the same dataset to multiple cloud environments. Although cross-cloud mounting is supported, we do not recommend this method due to its high dependence on network stability. The core challenge lies in network reliability; synchronization processes are susceptible to network fluctuations and must be used cautiously.
Summary
In key segments such as production, simulation, training, and inference, JuiceFS uses flexible metadata engine choices, diverse object storage backend options, and good compatibility with Kubernetes and Kubeflow to effectively support requirements for high-concurrency small file access, cross-cloud data flow, and performance scaling. Under large-scale data scenarios, JuiceFS operates stably. This significantly reduces operational complexity and overall costs, while meeting current application scale needs in terms of system scalability.
Looking forward, with the gradual adoption of metadata engines like TiKV and continuous optimization of cross-cloud synchronization mechanisms, JuiceFS' overall performance and adaptability still have room for improvement. It will continue to provide sustained support for Zelos' massive data processing needs in autonomous driving research and development.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.