















Artificial intelligence (AI) training and inference impose extremely stringent demands on storage systems, particularly in three areas: high throughput, high concurrency, and efficient handling of massive small files. While parallel file systems like Lustre or GPFS deliver excellent performance, their high cost and tight coupling between throughput and capacity often lead to hardware resource wastage. As data volumes grow exponentially, these issues become increasingly obvious.
In this article, we’ll explore a real-world case where a large language model (LLM) training company migrated from a parallel file system architecture to JuiceFS (an open-source distributed file system), using idle resources to build a 360 TB cache pool with 70 GB/s throughput. We’ll dive into how JuiceFS achieves efficient data processing, low-cost storage, and elastic scalability.
Early storage architecture: Underutilization and high costs
One of our customers is a company specializing in LLM training, with data stored on AWS S3. Initially, they accessed this data through AWS FSx for Lustre's parallel file system to ensure their compute resources could efficiently retrieve data from S3. FSx and similar parallel file systems typically provide three core features: protocol conversion, cache acceleration, and file lifecycle management.
To support large-scale data processing, the company deployed bare-metal servers with high-performance NVMe disks. However, these disks remained largely idle, resulting in significant resource waste.
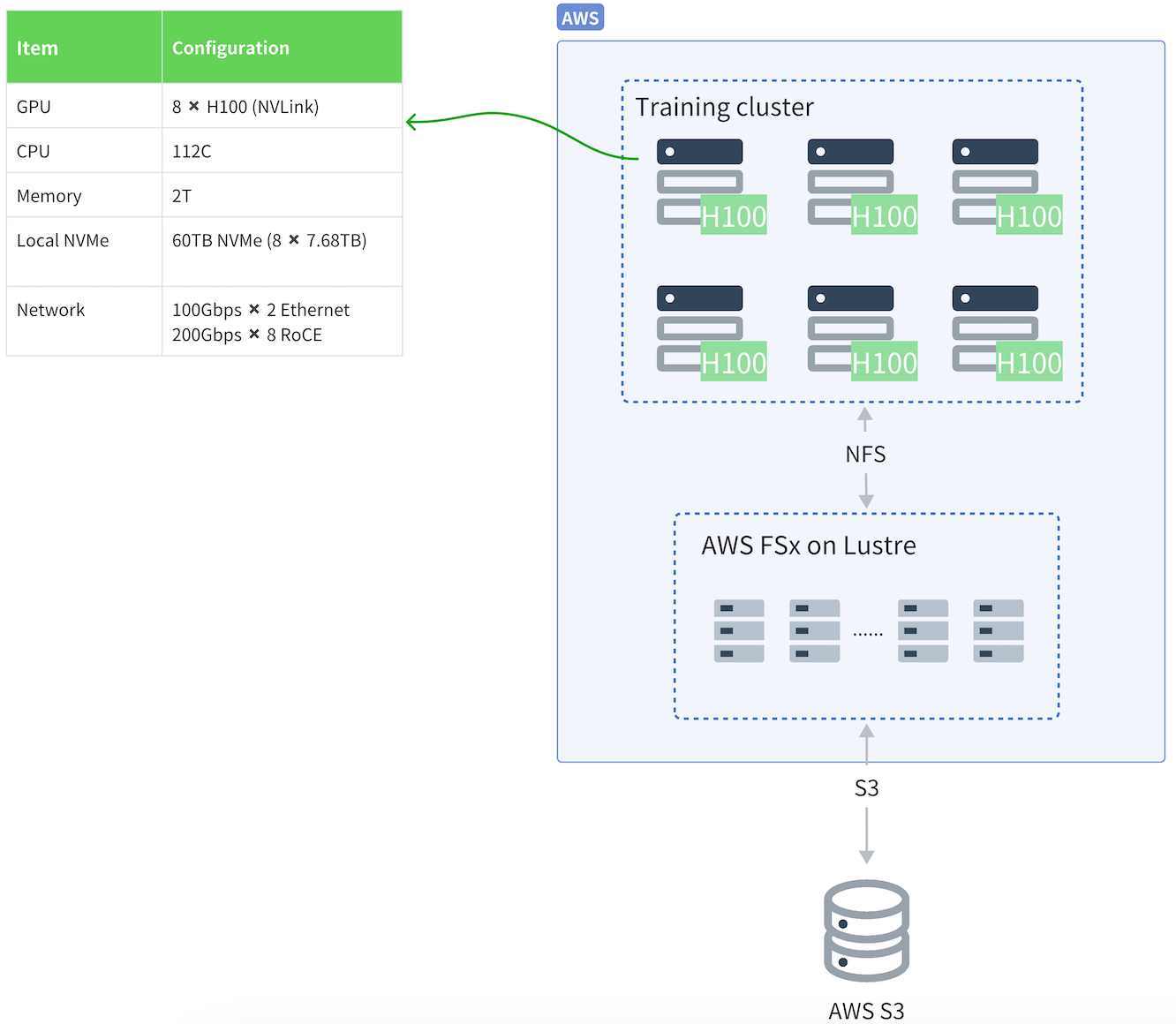
While parallel file systems delivered strong performance, their cost was high, and throughput was tightly bound to storage capacity. Scaling for higher throughput required purchasing additional storage, leading to higher expenses. Given the anticipated growth in data volumes, continued scaling of this system would impose substantial cost pressures.
New architecture with JuiceFS: enhanced throughput and scalability
After thorough technical evaluation, the company migrated from their legacy architecture to JuiceFS to better meet their high-throughput and scalability requirements.
JuiceFS architecture features
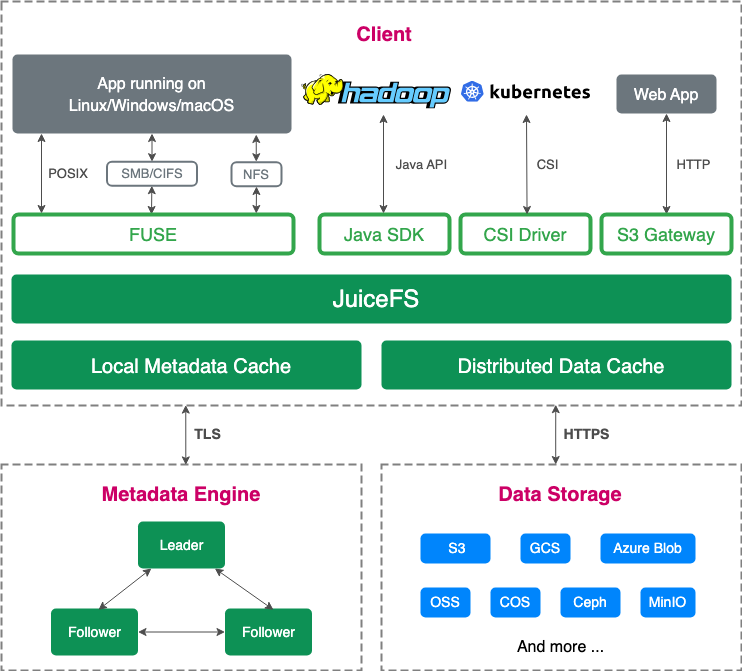
JuiceFS adopts a decoupled architecture separating data and metadata:
- Data: Stored in object storage
- Metadata:
- JuiceFS Enterprise Edition: Raft-based clustered metadata engine
- JuiceFS Community Edition: Supports databases such as Redis and TiKV
To optimize performance, JuiceFS divides data into 4 MB blocks (minimum update unit), significantly reducing write amplification and improving object storage efficiency. New users may worry about whether the data block affects the file availability, or whether the block format cannot be read normally without JuiceFS, resulting in a strong binding of the product. In fact, JuiceFS treats object storage as a local disk, avoiding close coupling with the file system, and solving the bottleneck of random write efficiency of object storage. In addition, JuiceFS provides an interface to support easy migration of data back to S3 object storage. This avoids dependence on specific storage products.
Deployment plan
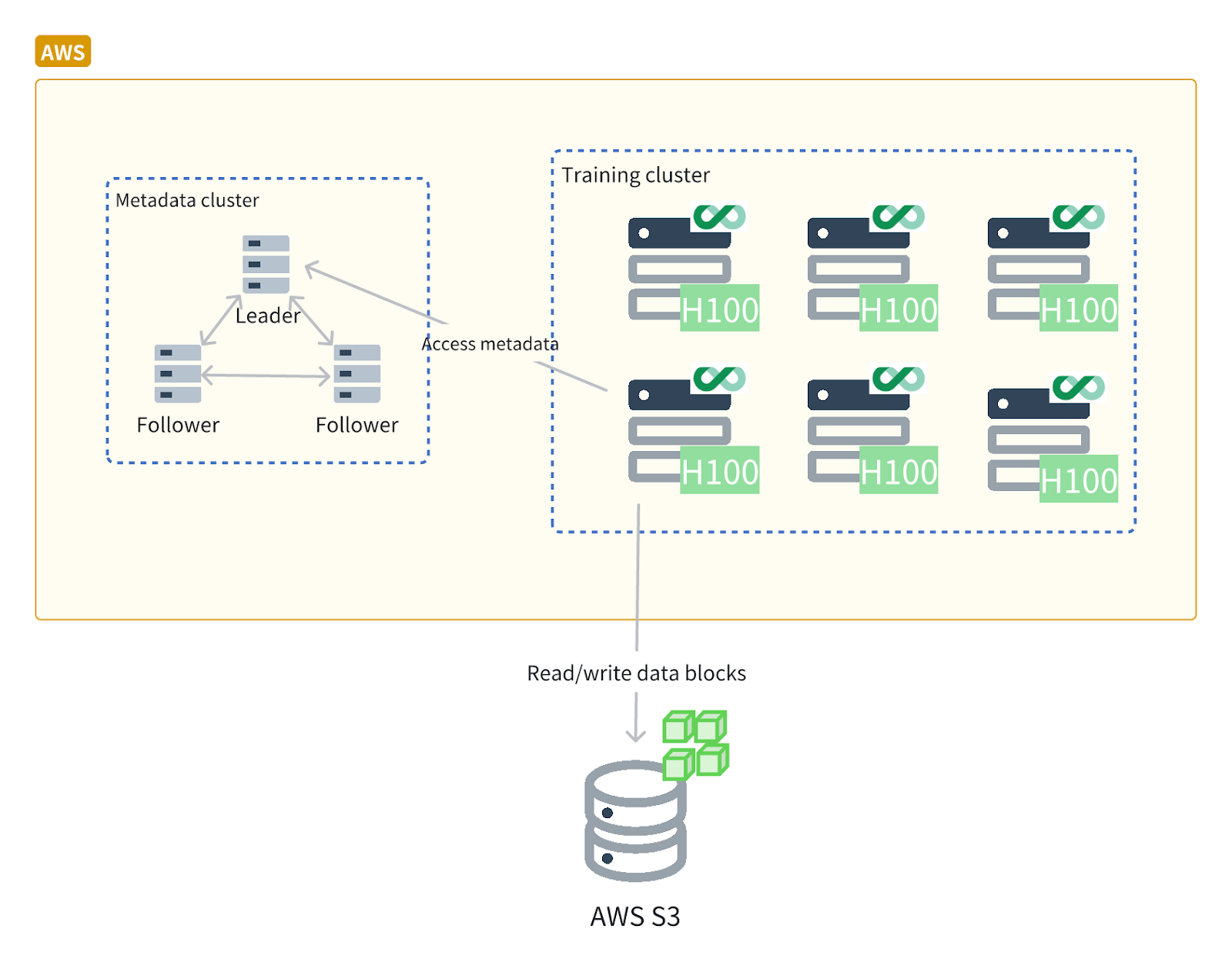
Unlike the previous centralized architecture of hosted file systems, the new architecture based on JuiceFS utilizes clients on each application node to provide protocol conversion and cache acceleration capabilities. Whether integrated with Kubernetes through JuiceFS CSI or accessed directly through the host, after deployment, application nodes can efficiently access metadata and object storage, greatly improving the performance and flexibility of the storage system. The advantage of this architecture is that it can flexibly scale the system, avoid single points of failure, and improve the utilization efficiency of storage and computing resources.
Furthermore, JuiceFS can fully utilize idle hardware resources, such as NVMe local disks and memory. JuiceFS consolidates these idle disks into a distributed cache pool, improving cache performance and throughput. Community Edition users can set the cache directory to a distributed file system, such as BeeGFS, to build a distributed cache layer.
Using JuiceFS, the company built a 360 TB distributed cache pool. With 600 Gbps of aggregate bandwidth provided by six servers, the cache pool achieved an instantaneous throughput of 10 GB/s. JuiceFS also demonstrates excellent TCP network utilization, achieving 95% utilization for bandwidths under 100 Gbps. If GPU nodes lack additional disk resources, the cache pool can also be built using memory.
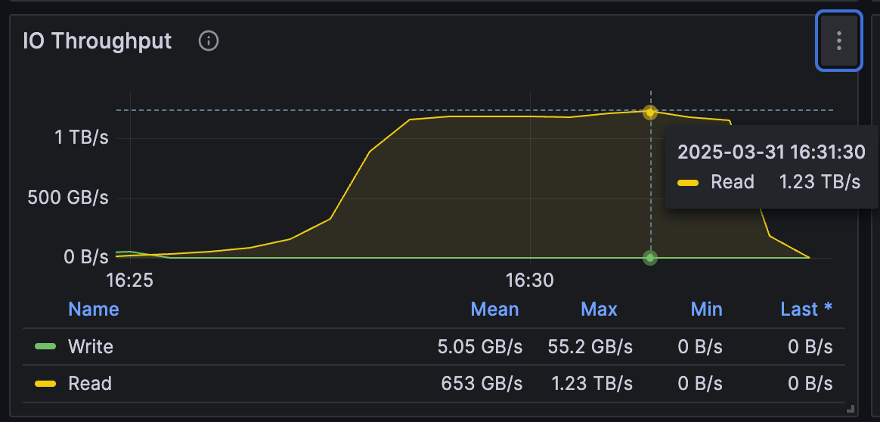
JuiceFS read performance test
To evaluate and demonstrate the read performance of JuiceFS after using distributed caching, we conducted internal testing using JuiceFS Enterprise Edition 5.2 to test large file sequential read performance.
The test results showed that, in a 10 Tbps network environment aggregated by 100 nodes, the aggregate throughput of JuiceFS distributed caching reached 1.23 TB/s. This demonstrates that under 100 Gbps TCP network conditions, network utilization can reach over 95%; even under 200 Gbps network conditions, utilization can reach approximately 70%. This test used a 100 Gbps NIC and successfully achieved a high overall aggregate throughput in a TCP environment.
During testing, we combined disk and memory resources to fully utilize the 100 Gbps NIC’s bandwidth ceiling, achieving 12.5 GB/s throughput.
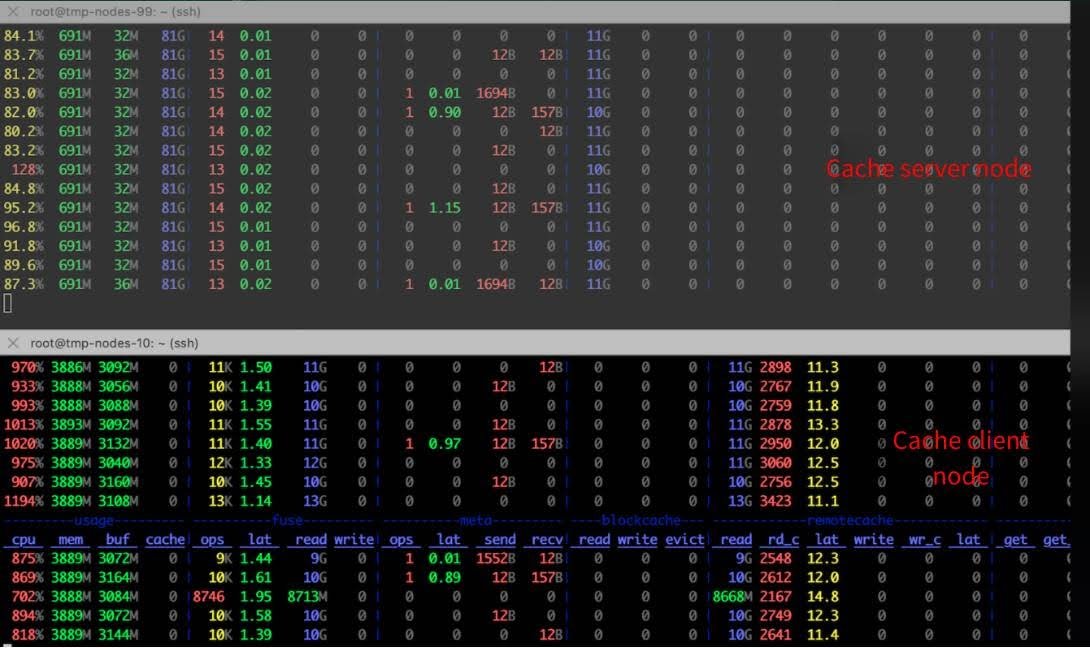
In the cache service node test, reading 11 GB of data per second from local disks and transmitting it over the network to a consumer node consumed less than one CPU core, consuming only one core for every 10 GB/s of bandwidth provided.
On client nodes, each GB/s read consumed only 0.8 CPU cores. To fully utilize a 100 Gbps NIC bandwidth, using JuiceFS FUSE client storage would require 10 CPU cores. TCP networks are more widely used, so optimization solutions based on TCP networks are widely applicable in various scenarios and meet different needs.
Summary
This article introduced the application of JuiceFS in AI training and inference scenarios. While latency and IOPS remain critical, throughput performance and cost-efficiency prove equally important. JuiceFS offers a cost-effective solution to the high costs and throughput-capacity coupling nature of traditional parallel file systems (PFS). Its architecture, which separates data and metadata, pools idle disk, memory, and network resources on application nodes to build a high-performance distributed cache cluster on demand, avoiding capacity constraints. As demonstrated in the case study, this solution reduces total storage costs to one-tenth of original levels while achieving throughput at TB/s scale, all with low client CPU overhead.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.