















We are one of China's leading research institutions specializing in computer science and technology. When building a large language model (LLM) training and inference platform, we encountered exponential growth in both model sizes and dataset volumes. Initially, we adopted a bare-metal storage solution, but we soon encountered challenges including data silos, storage redundancy, management chaos, and uneven resource utilization. Therefore, we upgraded to a Network File System (NFS).
However, as workload intensity increased, NFS bottlenecks became apparent: severe training task delays or complete stalls during peak hours, performance degradation under multi-user concurrency, difficult storage scaling, and inadequate data consistency guarantees. These issues significantly impacted our researchers' productivity, and we needed a more advanced storage solution.
After evaluating multiple open-source storage systems, we adopted JuiceFS, a high-performance distributed file system. Our architecture uses Redis for high-performance metadata management and a self-built MinIO cluster as underlying object storage. This solution effectively resolves critical challenges in model training scenarios—data read/write bottlenecks, metadata access latency, and seamless storage interoperability across computing resources.
In this article, we’ll share our journey of building a high-performance storage platform for LLM workloads, covering:
- Our evolving storage requirements
- Why JuiceFS emerged as the optimal solution
- The benefits we've achieved
- Our roadmap for further optimization
Storage requirements for LLM training and inference platform
Our platform serves as an integrated training and inference solution for LLMs within our laboratory, with core functionalities centered on unified management of models, datasets, and user code. For resource scheduling, the platform employs Kubernetes (K8s) to centrally manage and allocate computing resources across all laboratory servers, significantly improving overall compute efficiency. In addition, the platform offers model-related services, such as built-in model evaluation metrics and one-click deployment of models as application services, facilitating seamless sharing and utilization among laboratory members.
Our storage requirements:
-
Model and dataset file storage with high accessibility
Our platform must provide fundamental storage capabilities for model and dataset files while ensuring rapid accessibility. During initial development, we experimented with an immature solution—cloning model files into containers (Pods) upon startup. However, given the massive size of LLM files, this approach proved inefficient for our primary use case.
-
Container Storage Interface (CSI) support
Since the platform is built on a Kubernetes architecture, the absence of CSI support would cause many Kubernetes features to be unusable. This may lead to operational challenges and potential manual configuration overhead.
-
POSIX protocol compatibility
Most deep learning frameworks (such as Transformer and TensorFlow) are based on the POSIX protocol. Without POSIX support, the platform would require custom storage protocol implementation, increasing development complexity and effort.
-
Storage quota management
Given limited laboratory storage resources, unrestricted user storage consumption could lead to rapid resource exhaustion by individual users. Moreover, the lack of quota management would hinder accurate forecasting and planning for future storage needs.
Challenges and optimization of platform storage
Early-stage storage architecture and its limitations
During the initial phase of the project, leveraging the underlying Kubernetes architecture, we adopted a storage versioning approach inspired by Hugging Face. We used Git for management—including branch and version control. However, practical implementation revealed significant drawbacks. Our laboratory members were not familiar with Git operations. This led to frequent usage issues.

The original storage design employed a simple approach: mounting local disks to Pods during startup via Kubernetes Persistent Volume Claims (PVCs). While this solution had speed advantages, its shortcomings were equally apparent. With multiple users operating concurrently, Pods could be distributed across different nodes. This required model file synchronization on each node—a process that resulted in substantial resource wastage.
NFS solution trial and its limitations
To address the challenges above, we implemented NFS as a replacement for the hard disk solution. As a mature technology, NFS offered easy deployment—a critical advantage given our laboratory's small operations team. Its official Kubernetes CSI support further enhanced its appeal.
During initial testing, the NFS solution performed well. At this early stage, platform usage was confined to a small research group with limited users, minimal training/fine-tuning tasks, and limited model data volumes.
However, as the project matured and entered lab-wide testing, three critical pain points emerged:
- Storage constraints
- Growing model file quantities caused increasing disk usage.
- Local disk expansion proved cumbersome and operationally complex.
- Management complexity
- NFS required manual storage administration.
- Administrative burden increased disproportionately with scale.
- Performance bottlenecks
- Model training and inference speeds degraded noticeably with more users.
- Example: Training jobs previously completed in dozens of hours began exceeding weekend-long durations.
- Architectural limitations
- NFS lacks distributed architecture support.
- Workarounds like NFS instance replication cannot address single-point-of-failure risks and may cause cluster storage crashes because of server downtime.
- No viable distributed solutions were identified within the NFS ecosystem.
Why we chose JuiceFS
To address the challenges above, we conducted an in-depth evaluation of JuiceFS and ultimately selected it as our new storage solution. JuiceFS employs an architecture that separates data storage from metadata management:
- File data is chunked and stored in object storage
- Metadata can be stored in various databases (like Redis, MySQL, PostgreSQL, TiKV, and SQLite), allowing users to select the optimal engine based on specific performance requirements and use cases.
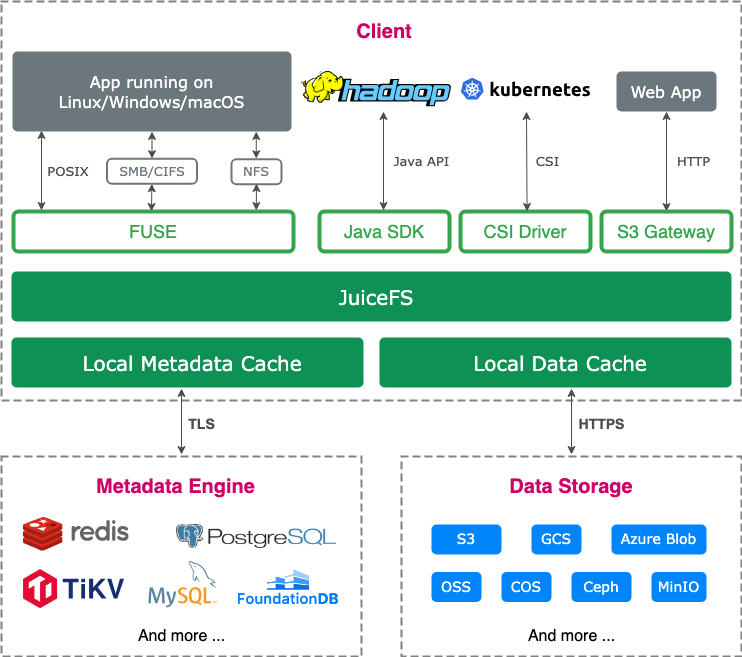
For the underlying object storage, we used our existing MinIO cluster. The operation and maintenance team was familiar with MinIO, so they adopted it without much research. Considering that Redis was easy to build and our laboratory already had a Redis cluster that could be directly reused, we chose Redis as the metadata engine.

However, in the subsequent use process, we found that maintaining object storage by ourselves faced many difficulties. The operation and maintenance team lacked experience in storage management, which led to frequent problems. In view of this, we planned to optimize and upgrade the storage architecture in the future: replacing the self-built MinIO cluster with a commercial object storage service to improve the stability and reliability of storage; upgrading Redis to TiKV to enhance distributed storage capabilities and performance.
JuiceFS’ advantages
We chose JuiceFS because it has these advantages:
- High performance and elastic storage: This was a critical deciding factor for our team. High-performance storage significantly accelerates model training and inference speeds, thereby optimizing overall operational efficiency and meeting the platform's demanding compute requirements.
- User-friendly distributed architecture: JuiceFS is easy to use, reducing the complexity of operation and maintenance. As a distributed file system, it effectively avoids the risk of single point failure. This ensures reliable storage infrastructure for uninterrupted operations.
- Kubernetes integration: Deeply compatible with the underlying Kubernetes architecture, JuiceFS is easy to deploy and manage in a containerized environment. This improves the flexibility of resource scheduling and application.
- POSIX compliance: Following with the POSIX protocol, JuiceFS is seamlessly compatible with most deep learning frameworks (such as Transformer and TensorFlow). This avoids the adaptation difficulties at the protocol level and simplifies the development process.
- Quota management: It provides refined storage quota management functionalities, which can reasonably limit user storage space. This prevents individual users from excessively occupying storage resources and ensures fair allocation and effective use of storage resources.
JuiceFS’ practical features
In our practical use of JuiceFS, we discovered several unexpectedly valuable features that significantly enhanced platform operations and user experience:
- Cache warm-up: During deployment, we used JuiceFS' cache warm-up feature to load frequently used LLM data into the cache of commonly used compute nodes. This allowed us to directly access data from the cache during model inference or training, drastically reducing data loading times and improving task execution efficiency.
- Fast cloning: JuiceFS supports rapid data replication through metadata cloning. Given our internal mechanism for synchronizing files from the file system to actual storage, this feature effectively met our need for quick data duplication, improving synchronization efficiency and reducing migration costs.
- Monitoring integration with Prometheus and Grafana: JuiceFS seamlessly integrates with Prometheus and Grafana, enabling easy incorporation into our existing monitoring system. Through a unified dashboard, we gained real-time visibility into storage performance metrics, system health, and potential issues, ensuring stable operations.
- Trash feature: Previously, when using NFS, our users occasionally accidentally deleted critical code with no way to recover it due to the lack of asynchronous backups. JuiceFS’ trash feature solves this problem—deleted files are temporarily stored and can be restored within a set period, preventing data loss and enhancing safety.
- Console management: The JuiceFS Console provides unified management of Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) across all regions. This allows administrators to easily monitor, manage, and optimize storage resources, streamlining operations.
- SDK support: We closely followed JuiceFS Enterprise Edition’s SDK release and plan to explore its potential applications in our application scenarios. This will further unlock JuiceFS’ capabilities and drive platform innovation.
JuiceFS deployment
In our development environment, we deployed JuiceFS using Helm. The Helm-based deployment proved very easy—simply modifying the values.yaml configuration file enabled one-click deployment, with no significant obstacles encountered during the process.
However, we did face a minor challenge. Since our laboratory’s server cluster operates in an internal network (no external internet access), we set up an internal container registry to store JuiceFS images. During deployment after adjusting values.yaml, the process failed. After troubleshooting, we found that the system encountered issues while attempting to pull the juicefs.mount image. We hypothesized that additional configuration was required for this specific image pull. By referring to the official documentation, we identified the relevant section on custom image configuration. Implementing a customized image successfully resolved the deployment issue.
Benefits of using JuiceFS
Cache and model warm-up
To accelerate model inference, we enabled JuiceFS' cache warm-up. Before executing inference tasks, relevant model data is loaded into the cache. When inference begins, the system reads data directly from the cache, eliminating performance overhead from frequent underlying storage access. This optimization improved inference efficiency.
Directory quota management
We implemented per-user storage quotas for all laboratory members. Through this refined quota management, the storage resource usage of each account is effectively controlled. This prevents individual users from excessively occupying storage space and ensuring fair allocation and rational use of storage resources. At the same time, based on directory quotas, we plan to build an internal billing system similar to computing resources and calculate fees based on the user's usage of storage resources to achieve refined resource management.
Read-only mode for critical models
We configured some official model files with read-only access to protect model integrity from accidental or malicious modifications and prevent data leakage risks.
Console-based monitoring
After enabling the JuiceFS Console, operators can monitor the status of all PVs and PVCs during training in real time. Through the console, operators can intuitively view storage resource usage, performance metrics, and other information. They can discover and solve potential problems timely and provide strong guarantees for the stable operation of the storage system.
Dynamic configuration and storage segmentation
In the storage architecture design, we first mount a large dynamic storage volume and then segment it into each laboratory member at the bottom layer. This dynamic configuration method can flexibly allocate storage resources according to actual needs, improve the utilization of storage resources, and also facilitate independent management and monitoring of storage usage of different users.
Future plans
Current storage architecture and challenges
Our existing infrastructure utilizes object storage with two S3 buckets:
- S3 Bucket 1: Stores Git and Git large file storage (LFS) files
- S3 Bucket 2: JuiceFS performs periodic synchronization from Bucket 1 to maintain data consistency.
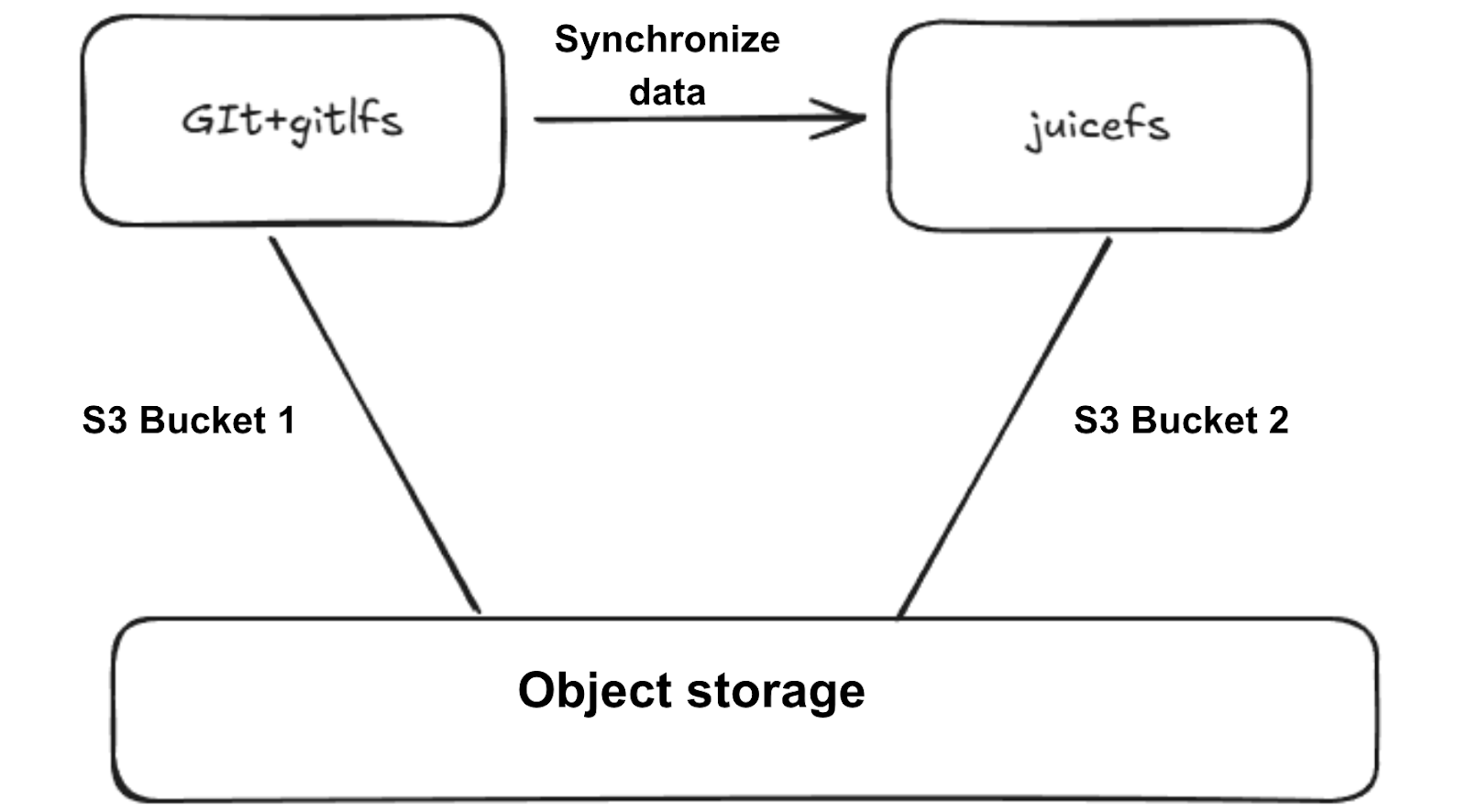
We had these pain points for this architecture:
- Storage redundancy: Dual copies of large files across systems consume extra capacity, increasing storage costs.
- Git repository scalability limitations: The open source GitLab repository used by our laboratory has poor scalability. For example, when creating a Git user, it’s necessary not only to create user information in its own user table, but also to create the user again in the open source GitLab. The operation process is cumbersome and increases management costs.
- Low efficiency of large file synchronization: In the previous architecture, JuiceFS used Git cloning to synchronize large files from the Git repository. This method was extremely inefficient when processing large model files, resulting in a slow synchronization process and affecting the overall application processing efficiency.
Planned optimizations for platform enhancement
To address the challenges above and improve platform efficiency, we’ve planned the following optimization strategies:
- Optimized file synchronization mechanism: To address the problem of low efficiency in large file synchronization, we plan to customize the open source Git server and build a unified file processing middle layer. In this middle layer, JuiceFS’ metadata cloning feature is used to achieve file synchronization. Compared with the traditional Git cloning method, metadata cloning can significantly increase the synchronization speed, quickly complete the synchronization task of model files, and improve the efficiency of the overall application process.
- SDK custom development: To further improve user experience, we plan to customize the SDK, focusing on optimizing the Git client or Transformer library. By integrating the fast cloning feature of JuiceFS, laboratory members can quickly obtain and use model files and dataset files on their own servers even if they use their own computing resources.
- Enhanced permission management: At present, JuiceFS Community Edition does not seem to support permission management of stored files. To meet the laboratory’s strict requirements for data security and management, we hope to conduct secondary development of JuiceFS in the future to achieve more complete permission management functionalities. Through refined permission control, we ensure that different users' access and operations on storage resources are in line with their permission scope and ensure data security and privacy.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.