















01- Challenges of Big Data Operations & Upgrade Considerations
Challenges
The big data cluster at China Telecom generates an enormous amount of data on a daily basis, with individual business operations reaching the PB level per day. The cluster is also burdened with a significant amount of expired and redundant data, which creates storage issues. Additionally, each provincial company has its own cluster, and there is a group big data cluster that collects business information from all provinces throughout the country. This leads to scattered and redundant data, and as a result, data between the provincial and group clusters cannot be shared. Consequently, cross-regional tasks experience significant delays.
Back in 2012, China Telecom started developing various clusters, with internal clusters being deployed by different vendors or internal teams. These clusters supported business operations managed by multiple vendors, who also provided the maintenance teams. Consequently, the clusters included a variety of versions such as Apache, CDH, HDP, and others. However, as the cluster size grew, the pressure on operations and maintenance intensified, and addressing issues often required vendor assistance, which is not a sustainable approach.
To address the current clusters' pain points, enhance cluster security, increase efficiency, and meet the demands of both internal and external stakeholders, China Telecom established a team dedicated to the development of the internal PaaS platform in 2021. Over the course of two years, the PaaS team has concentrated on refining the existing clusters, guaranteeing the stable operation of tens of thousands of machines within the current clusters.
In early 2022, the PaaS team started developing their own big data platform, called TDP (TelecomDataPlatform), with the aim of progressively replacing existing clusters. In the first half of 2022, two new clusters based on Hadoop 2 were deployed using TDP and brought into production. During the second half of 2022, the PaaS team developed TDP based on Hadoop 3 and started tackling the challenge of upgrading numerous Hadoop 2 clusters within the live network.
Thoughts on Upgrades
While upgrading the clusters, the goal is for the new cluster design to resolve current pain points, integrate cutting-edge industry features, and be prepared for future technological iterations.
The following are the issues we hope to address:
Divide into small clusters
We plan to split the large cluster into smaller ones for the following reasons:
From the standpoint of machine resources, it is impractical to use several thousand machines simultaneously for migrating existing businesses. Moreover, for some critical businesses that demand high SLA guarantees, It is not feasible to directly upgrade from Hadoop 2 to Hadoop 3 in the production environment.
Each cluster contains numerous business operations, and dividing the large cluster into smaller clusters enables us to separate them based on their respective operations. This minimizes the impact between operations and reduces the pressure and risk associated with business migration. Splitting into smaller clusters also enhances the overall cluster stability, preventing issues with a single task from causing instability in the entire cluster and allowing for better stability management.
For instance, some machine learning tasks might not use tools like Spark or Machine Learning libraries, but rather directly invoke Python libraries within their own programs. These operations have no thread usage limit. Consequently, even if a task requests only 2 cores and 10GB of memory, it may overload the machine's resources and generate a load of over 100. By dividing it into smaller clusters, we can minimize the impact between tasks, particularly when the platform needs to execute critical tasks. Additionally, with smaller nodes, managing operations and maintenance tasks become relatively easier.
Furthermore, dividing the cluster can prevent Namenode and Hive metadata from bloating and alleviate overall operational pressure. Therefore, our plan is to upgrade by splitting the large cluster into smaller ones, provided that it is feasible for the business.
Smooth Upgrade process
When splitting into smaller clusters, there are two dimensions to consider: data and computation. Data migration can be time-consuming, and for complex businesses, computation may also take a long time. As such, we need to find a way to separate the migration of data and computation, maximizing parallel processing between these two clusters.
Inter-cluster data access problem
Once we split the large cluster into smaller clusters, we need to address how to facilitate data sharing between these clusters. Furthermore, our internal system comprises tens of thousands of machines and a vast amount of data, leading to persistent challenges in managing data migration, redundancy, as well as hot and cold data.
Big data and AI integration Demands
Our PaaS platform is progressively taking on a wide range of AI demands, and one of the most prominent is the storage of unstructured data. The integration of this requirement with existing structured and semi-structured data storage is also at the forefront of industry trends.
Cost reduction and efficiency improvement
After splitting the large cluster into smaller clusters, resources may become scarcer, particularly since different clusters may have varying usage patterns. Some clusters may only be utilized during holidays, weekends, or daily batch computing. Thus, it is crucial to maximize the utilization of idle resources.
Our current machines are all high-performance, expensive devices with impressive storage, memory, and CPU capabilities. In the future, we hope to avoid purchasing these high-performance machines for every business need. And for smaller clusters, we can quickly set up a cluster and save on some storage and computing resource costs. Furthermore, during the upgrade process from Hadoop 2 to Hadoop 3, EC(Erasure Coding) can reduce storage resource requirements by up to 50%. We aim to reduce overall storage costs through this approach further.
Drawing from the above considerations, we can summarize the following four strategies:
- Separate storage and computation.
- Employ object storage to address the storage challenges of structured, unstructured, and semi-structured data.
- Leverage elastic computing technology to address the issue of underutilized resources following the division of small clusters.
- Utilize containerization technology to address deep learning computing and resource management challenges, resulting in improved cost-effectiveness and operational efficiency.
02- Design and Construction of Storage-Compute Separation Architecture.
Component Selection
During the initial phase of big data architecture, storage and computing were integrated into a single Hadoop 2.0 cluster, with both functions running on high-performance machines. However, the current architecture separates storage and computing, utilizing more disks for object storage and establishing an object storage pool with a corresponding metadata acceleration layer. All HDFS access will pass through the metadata acceleration layer to reach the underlying object storage layer.
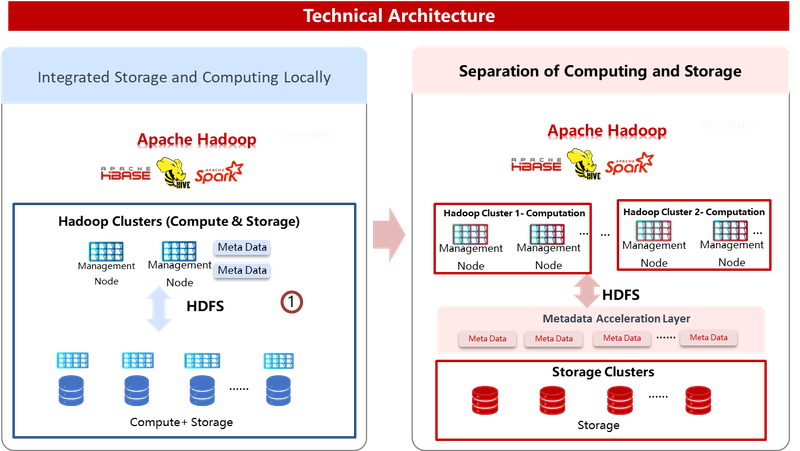
Technology Selection
Object Storage
When evaluating various object storage solutions, we primarily compared Minio, Ceph, and Curve, while cloud-based object storage was not included in our assessment. Among these options, we ultimately selected Ceph, which is widely utilized in the industry and supports various K8S containers, S3, and underlying block storage.
Integration with HDFS
The primary objective of separating storage and computation is to integrate object storage with HDFS. This effort has been incorporated into our self-developed Hadoop 2 and Hadoop 3. Initially, we utilized the S3 code developed by Amazon, and domestic cloud services providers such as Alibaba Cloud, Tencent Cloud, and Huawei Cloud also developed their own implementations, which were subsequently submitted to the Hadoop community. However, these solutions lacked support for metadata acceleration.
In recent years, metadata acceleration and data caching technologies have become more advanced, aimed at addressing the issue of the underlying data of Yarn not being able to be affinitized with local data after separating storage and computation. With this integration, our goal is not only to directly connect object storage with HDFS, but also to attain top-tier performance levels in the industry.
There are various ways in which object storage can be integrated with HDFS, including utilizing the native Hadoop interface, Ceph's CephFileSystem, or open-source tools like JuiceFS. Cloud service providers also offer comparable solutions, such as Alibaba Cloud's Jindo and Tencent Cloud's GooseFS. All of these products offer metadata acceleration and caching capabilities.
Although cloud service provider products have the benefits of maturity and scalability, they require binding with cloud resources and their source code is inaccessible. Consequently, we chose the open-source solution JuiceFS. It is currently the most mature open-source option with a high level of community activity and can also adapt to commercial Hadoop versions like CDH and HDP. Ultimately, we opted for a combination of Hadoop 3 + JuiceFS + TiKV + Ceph as our storage and computation separation solution.
The value brought by the storage and computation separation architecture
- Data Storage Redued in a Single Cluster and Alleviated Metadata Pressure Decoupling storage and computation enables elastic scalability and data sharing, which reduces the amount of data stored in a single cluster and alleviates overall pressure on metadata.
- Metadata Bottlenecks and Single-point Performance Issues SolvedThe pressure on metadata is handled at the metadata acceleration layer, which can be horizontally scaled to solve the bottleneck and single-point performance issues of the original metadata.
- The problem of Ceph layer federation imbalance solvedPreviously, there were issues with federation imbalance in the Ceph layer. For example, if a business uses namespace3 (ns3) in the Ceph layer, all its data may be stored on ns3, resulting in an overall imbalance of data and pressure across the federation compared to other namespaces.
- Bottleneck issues in whole-scale expansion solved
We can reduce storage costs by using erasure coding in the new cluster and improve the cluster's scaling capabilities through horizontal scaling of object storage.
Practice: Migration of Traffic Trace Project
The data in the traffic tracking project primarily consists of DPI data, which includes various types of user internet traffic data, such as 3G, 4G, and 5G data. Telecom customer service representatives can use a display page to check whether the user's traffic consumption over a period of time matches their deducted fees.
With the increasing number of 5G users, the existing cluster is continuously filled with 5G traffic data, leading to an increase in storage pressure. All data is collected through a collection system from 31 provinces, with the current data volume reaching PB level and continuing to grow in overall size. On average, the system processes around 800-900TB of data daily. Although it is a relatively simple business scenario, the challenge lies in the sheer volume of data.
We chose to migrate the flow tracking project because its SLA requirements were not very high, with a timeframe measured in hours. Therefore, if there was a one-hour outage, the impact would be relatively small.
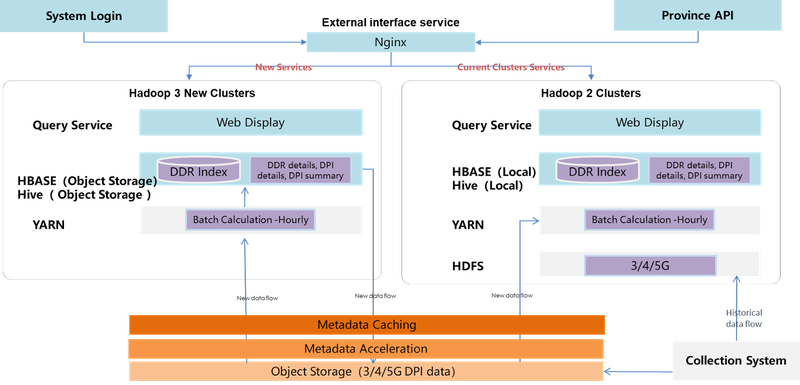
Due to the large volume of data, we chose to batch processing tasks at the hourly level. The goal was to process the overall computation by consuming a significant amount of resources, in order to calculate the hourly traffic consumption and distribution of users and store this data in HBase and Hive.
All existing data from the collection system was uploaded to the Hadoop 2 cluster for migration. To enable the integration of the Hadoop 2 cluster and object storage, JuiceFS played a critical role. With JuiceFS, there was no need to restart core components like Yarn and HDFS services to mount the object storage. As new data came in, the collection system could write it directly to the object storage. Computing tasks could then access the data by reading directly from the object storage. For existing tasks, only the file path needed to be modified, and all other aspects could remain unchanged.
Project Practice
The storage and computation separation project was implemented rapidly, with the entire project being completed within just two months. The ease of use of JuiceFS was a critical prerequisite for us to solve problems under enormous pressure and meet our goals on time. In practice, JuiceFS played a very important role in solving some critical problems.
Firstly, PB-level support capability
To address metadata storage and connection pressure, we initially tested JuiceFS with Redis as the metadata engine and found that the overall performance was excellent. However, as we scaled up to several hundred machines and each container accessed the metadata during Yarn task startup, Redis started to crash. Therefore, we replaced Redis with TiKV.
To address the issue of timestamp contention and competition in a large-scale cluster environment with consistent time windows, we applied patches to optimize time and competition and relaxed certain corresponding parameter configurations.
We found that the amount of data stored in Ceph continued to increase due to slow garbage collection. This was mainly due to the large volume of DPI business data, which was only stored for a few days. Therefore, PB-level data was written, consumed, and deleted every day, resulting in a bottleneck in garbage collection speed.
After deploying monitoring tools, we found stability issues with TiKV and Ceph at certain times. Upon investigation, we discovered that the issue was caused by a memory leak in the client-side garbage collection thread.
Secondly, Improving Performance under High Workload
During the trial phase of the Flow Tracking project, in order to meet the requirements of 32TB computing and 10PB storage, a subset of high-performance machines were selected. However, when evaluating Ceph, the memory and CPU resources consumed were not taken into account, leading to each machine's throughput, network bandwidth, and disk bandwidth being almost fully utilized, making the environment similar to a stress test. In such a high-load environment, it was necessary to adjust Ceph to address memory overflow and downtime issues, as well as optimize its compatibility with JuiceFS to accelerate Ceph's data deletion and writing performance.
Project Plan
In the upgrade of Hadoop 3 in 2023, the following initiatives are being considered:
At the underlying level, we will rely entirely on JuiceFS for storing and accelerating metadata, and split the object storage into different pools or clusters based on different business needs.
At the computing resource layer, each cluster will have its own computing resource pool, but we will add an elastic resource pool for scheduling between multiple resource pools.
At the unified access layer, a set of unified management tools will be provided. Task submission will go through a task gateway and multiple clusters will be connected through metadata. The clusters will also be divided into different pods or clusters, such as the DPI cluster, location cluster, and texture cluster. Some clusters can also store hot data in their own HDFS and use databases and MPP to improve performance.
In addition, a unified cluster management toolset will be provided, including storage profiling, task profiling, cluster log collection, and log dashboard, to better monitor and manage clusters.
In summary, we aim to improve performance by dividing clusters into smaller ones and separating storage and computation. We will use JuiceFS to accelerate metadata and elastically schedule computing resources. Ultimately, we will simplify the operation and maintenance process through a unified management tool.
03- Experiences in Operations and Maintenance
How to deploy hybrid infrastructure using high-performance machines
In principle, heterogeneous machine types should be avoided when planning a cluster, and machines of the same type should be chosen wherever possible to ensure a consistent vcore-to-mem ratio. However, due to the company's cautious approach to machine procurement, the Traffic Trace project was only able to obtain around 180 older high-performance machines for replacement. While these machines are powerful, they are not suitable for large-scale computing or storage. To make the most of these resources, a mix of existing and new machines were used, which helped to address planning issues.
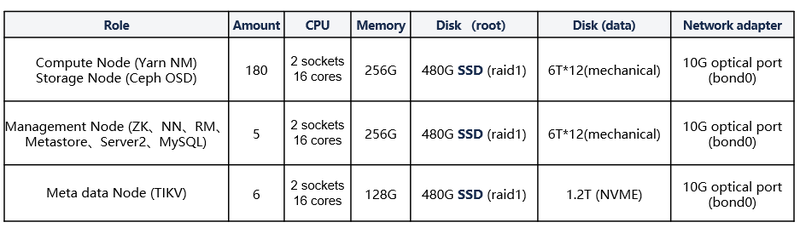
The infrastructure provides a total of 10PB storage, 8100 (45C180) Vcore, and 32TB (180G180) computing resources. Out of these, 48G (4G*12) computing resources are utilized by Ceph, while the remaining resources are dedicated to Yarn.
Inadequate planning of CPU and memory resources on machines.
During the planning phase, the CPU and memory usage of Ceph were not taken into account, leading to memory exhaustion and high machine loads, which caused server crashes and task failures. Ceph nodes shared a network card with the Hadoop cluster, and when a node went down, OSD data migration was triggered, causing both compute tasks and data migration to overload the network card. After practical optimization, the configuration was adjusted to address these issues.
- All nodes: Require two SSDs in RAID 1 mode as root disks to improve stability.
- Compute nodes: It is recommended to have a CPU thread-to-memory ratio of around 1:4 or 1:5, and to reserve resources for Ceph in a mixed deployment.
- Storage nodes: It is recommended to allocate 6GB of memory for each individual OSD (single disk), and to use high-performance servers with dual network planes if possible. If conditions permit, it is also recommended to separate the internal and external networks and divide the data synchronization for Ceph internally and external access into two different networks, which is an ideal state.
- Metadata nodes: It is recommended to use high-performance NVMe disks, which is the conclusion drawn after multiple discussions with PingCAP. The disk load, including TiKV, is quite heavy under the current usage of 180 high-performance computing nodes, reaching 70% to 80%.
- Ceph node operating system: CentOS-Stream-8
- Other node operating systems: CentOS-7.6+ and CentOS-Stream-8.
Unreasonable Local Directories of NodeManager
In high-load, PB-level scenarios, tasks require a large amount of disk space, so almost all disk space was allocated to Ceph, with HDFS only having one mechanical hard disk. However, during peak task periods, the middle data needed to be written to this mechanical hard disk, resulting in high disk IO latency, ultimately becoming a bottleneck for task execution.
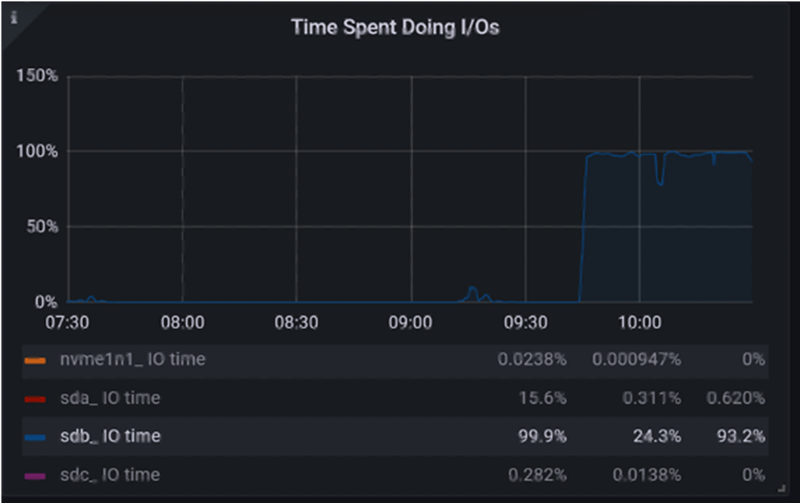
After optimization, under the constrained conditions of the machines, the local directory of Yarn was configured to the root disk (SSD), while all data disks were allocated to OSD, thus solving the performance issue caused by the disk.
Disable JuiceFS Pushgteway Metrics
To reduce the load on JuiceFS, all monitoring metrics from Pushgateway were turned off. Monitoring metrics requires continuous reporting through containers, and if the response time of Pushgateway is too long, it can cause HDFS callbacks to be stuck, thus preventing the task from ending. Although this approach may limit the visibility of some basic metrics, it is hoped that other means can be found to display monitoring metrics for JuiceFS in the future.
Limitation of Redis connection
When using Redis as the metadata engine, the number of connections is directly proportional to the number of Yarn containers. When the amount of data becomes too large and there are too many tasks, the maximum connection limit of Redis (4K) is quickly reached. Therefore, Redis or relational databases are recommended for handling cold data, while TiKV (with NVMe data disks) is recommended for high-performance computing. Currently, TiKV is being used, which can support approximately 100,000 parallel connections.
TiKV 6-hour Cycle busy
We previously encountered a problem where TiKV would experience 6-hour cycles of busyness. Through log analysis, we found that JuiceFS had enabled a large number of log cleanup threads. We initially attempted to solve the issue by disabling TiKV's reporting mechanism, but the problem persisted.
Upon further investigation, we discovered a thread overflow bug in JuiceFS that caused each nodemanager to open tens of thousands of log cleanup threads. Each thread triggered a cleanup operation when calling the file system. At 8 o'clock every day, these threads simultaneously executed cleanup operations, overwhelming TiKV and causing high spikes during peak periods.
Therefore, when choosing a storage garbage collection mechanism, it is necessary to choose between HDFS and JuiceFS. Although both mechanisms are available, it is more preferable to disable HDFS's garbage collection mechanism and let JuiceFS solely responsible for overall garbage collection.
JuiceFS deleting files slow
When using JuiceFS, file deletion operations are necessary for its garbage collection function. However, when initially using JuiceFS, it was found that even after adjusting the corresponding parameters in Ceph and setting the deletion and write weights to the highest values, PB-level data could not be deleted on a daily basis.
Since the deletion performance was low, it was necessary to use multi-threaded deletion. However, each deletion operation in JuiceFS requires the client to report metrics and then check which files in the recycle bin need to be deleted. If the number of files to be deleted is large, client-side processing is not feasible. Finally, the JuiceFS community provided a solution and corresponding patches to fix the multi-threading issue and meet the PB-level deletion requirements. The patches were mounted on several fixed servers for deletion, and the number of threads was adjusted to the maximum. Currently, these patches have not been merged into the official version, but they are expected to be merged soon in the future.
JuiceFS Write Conflicts
JuiceFS has been facing issues with write conflicts, and the problem has been partially alleviated by increasing the time interval for updating the modification time of parent folders and reducing frequent attribute modifications. However, the issue has not been completely resolved. Our team is currently actively discussing the problem with the JuiceFS team and plans to address it in version 1.0.4.
04-Plan
- Deploying Larger Scale Storage-Compute Separation Clusters
- Exploring Integration between Different Clusters and Object Storage Pools
- Exploring Single Cluster Access to Multiple Object Storage Clusters
- Exploring the Integration of Storage-Compute Separation and Data Lakes
- Building a Unified Storage Pool for Structured and Unstructured Data
Looking ahead, we hope that our storage and computing separation product will play a greater role in the upgrade process of tens of thousands of machines internally, and be validated in various scenarios. We aim to solve the stability issues caused by Ceph scaling, support Kerberos, improve security through range partitioning, and continue to enhance product stability, security, and ease of use. Additionally, we will continue to explore the development of cloud-native solutions.