















Tomorrow Advancing Life (TAL) is a leading smart learning solution provider in China with global footprints. It was listed on the New York Stock Exchange in 2010. We actively apply large language model (LLM) research to our educational products and recently launched a large-scale model with over 100 billion parameters for mathematics.
In the LLM context, storage systems must handle massive amounts of data and complex file operations. This requires support for high concurrency and throughput. In addition, they must tackle challenges like version management, model training performance optimization, and multi-cloud distribution.
To address these challenges, our team developed a model repository based on JuiceFS, an open-source, high-performance, distributed file system. It supports storing model checkpoints during the training process and offers control-plane support for users to upload and manage models across different cloud environments. By using the JuiceFS CSI component, TAL has mounted the model repository onto multiple clusters. The mounting configuration for LLM files takes only 1–3 minutes. This makes AI application elasticity much easier.
By implementing strategies such as access control and backup cloning, TAL has effectively reduced the risks of user errors and improved data security. Currently, TAL has deployed two sets of metadata and data repository across multiple clouds and locations, with object storage reaching 6 TB and over 100 models stored.
In this article, we’ll deep dive into the model repository storage challenges, our decision to choose JuiceFS over alternatives like Fluid+Alluxio+OSS, GPFS, and CephFS, the architecture of our model repository, and our plans for future enhancements.
Model repository challenges in the LLM context
In traditional DevOps workflows, delivery items are typically container images. These images are built using Docker builder and pushed to a registry, such as Docker Hub. Clients then pull the images from a central repository, often using acceleration techniques to speed up the process.
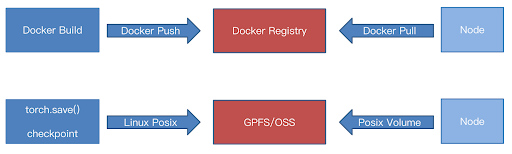
However, in AI scenarios, the situation is different. For example, during training tasks, serialized files are generated using methods like Torch Save, Megatron save_checkpoint, or others, and these files are written to storage via Linux POSIX file systems. The storage may be object storage or file systems (for example, GPFS or NFS). In essence, the training task writes models into remote storage via the file system to upload the model.
Unlike traditional IT delivery, which involves only pushing and pulling images, AI scenarios require handling much larger data volumes and more complex file operations, demanding higher concurrency and throughput from storage systems.
In the inference phase, containerized environments need to mount NFS, GPFS, or object storage systems via CSI to pull remote models into the containers. On the surface, this process seems straightforward and functional, but operational challenges do arise:
The primary issues are:
- Lack of version control: Traditional container images have clear delivery items and versioning information (such as uploader and size). In the model repository, models are often stored as Linux file systems (files or directories). This lacks version control and metadata (such as uploader and modifier).
- Lack of acceleration and multi-cloud distribution: Tools like Dragonfly can accelerate Docker workflows, but solutions like NFS, GPFS, or OSS lack effective acceleration methods. In addition, multi-cloud distribution is not feasible. For example, with NFS, it’s essentially limited to use within a single IDC and cannot support cross-IDC or cross-cloud mounting. Even if mounting is possible, the speed would be very slow, so we can consider it unsuitable for multi-cloud distribution.
- Security issues: During inference, the model repository is mounted to the container. If clients have overly broad permissions (for example, mounting a directory containing many models), this could lead to model leaks or accidental deletions, especially with read-write access.
These challenges highlight specific storage requirements for different scenarios:
Training scenario storage needs:
- Model download and processing: During algorithm modeling, various models (for example, open-source models, reference models, or custom-designed networks) need to be downloaded, converted, and split. This may include splitting models for tensor parallelism (TP) or pipeline parallelism (PP).
- High-performance reads/writes: The training phase requires a storage system with high read/write throughput to handle large checkpoint files, which can be as large as 1 TB per checkpoint.
Inference scenario storage needs:
- Model version management and deployment: When a model is updated to a new version, version release and approval processes are required. In the process of model deployment, GPU resources may frequently need to be expanded or contracted, often during the night for resource release and during the day for scaling.
- High read throughput: During the day, when models are frequently pulled to handle resource scaling, the storage system must support efficient read operations to ensure quick response to model retrieval requests.
Managerial storage needs:
- Team-level model management: The model repository should support isolation and management by team to ensure privacy and independence of models between teams.
- Comprehensive version control: The system should record clear metadata on model iterations, version usage, and more, and support model upload, download, auditing, and sharing.
Storage selection: Balancing cost, performance, and stability
Key considerations
When we choose storage solutions, we must consider the following issues:
- Reducing dependence on cloud providers is essential to ensure the technical solution remains consistent and uniform across self-built IDCs and multiple cloud providers.
- Cost is a significant factor. While sufficient funding can support more advanced solutions, cost-effectiveness analysis is equally important. We need to assess the total costs of various storage options, such as local disks, GPFS, and object storage.
- Performance is crucial. As previously mentioned, high read/write performance is required for the model repository. Therefore, we aim to create a closed-loop for model read/write traffic within a single IDC or cloud to ensure optimal performance.
- Stability cannot be overlooked. We want to avoid excessive operational complexity for managing the model repository, so simplicity and reliability of the components are needed.
Fluid+Alluxio+OSS vs. GPFS vs. CephFS vs. JuiceFS
Fluid+Alluxio+OSS
The solution of Fluid+Alluxio+OSS has been mature for several years. It combines cloud-native orchestration with object storage acceleration, achieving multi-cloud compatibility. This solution has extensive community adoption.
However, it has some drawbacks:
- It lacks integration with Ceph Rados, which is already part of our internal tech stack
- It has a high operational complexity with multiple components and significant resource consumption.
- Its performance with large file reads is not ideal.
- Its client stability needs further verification.
GPFS
GPFS is a commercial parallel file system that offers strong read/write performance and is already purchased by our company. It also has significant advantages for handling large volumes of small files.
However, it has distinct limitations:
- It’s unable to synchronize across multiple clouds. This constraint means that we cannot replicate the GPFS setup on other clouds, making it expensive.
- GPFS capacity costs are high, often several times those of OSS.
CephFS
Our company has some technical expertise with this solution. However, it cannot achieve multi-cloud synchronization, and it comes with high operational costs.
JuiceFS
JuiceFS has these advantages:
- It supports multi-cloud synchronization, has simple operations, fewer components, and excellent observability.
- It essentially incurs only the cost of object storage, with no additional costs aside from metadata management.
- JuiceFS can be used together with object storage in the cloud or Ceph Rados in IDCs.
Considering these factors, we selected JuiceFS as the underlying storage system for the LLM repository.
Our model repository design
Read/write design for training scenarios: Single cloud training
For training scenarios, we adopt a single-cloud training strategy, operating on a single cloud platform rather than across multiple clouds to enhance operational feasibility and efficiency.
Our approach for training read/write needs is as follows: we create a Ceph cluster using redundant NVMe disks across multiple GPU servers and integrate JuiceFS with Rados to enable read/write operations on the Ceph cluster. During model training, JuiceFS mounts a disk on the model repository as a CSI, allowing direct read/write access to Rados when storing or loading checkpoints. Tests show that checkpoint write speeds can reach 15 GB/s during LLM training.
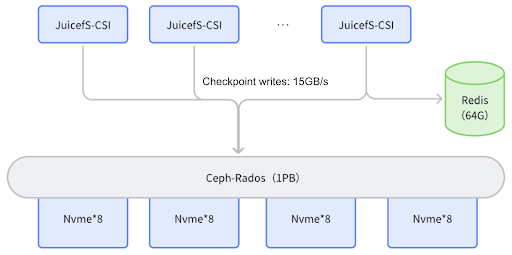
Metadata management: We chose Redis over more complex metadata management engines like OceanBase or TiKV. This is because we only store large files (potentially several GB each), resulting in a manageable data volume without the need for complex engines, thus reducing operational burden.
Read/Write design for inference scenarios: Multi-cloud inference
In contrast to training, inference resources are often spread across multiple clouds. On these platforms, we do not purchase large numbers of NVMe machines because cloud providers already offer object storage. Therefore, we use the classic JuiceFS mode—JuiceFS with Redis combined with the cloud provider’s object storage, forming a cluster. During inference, model files are mounted in read-only mode to prevent modifications by inference processes.
In addition, we designed an intermittent multi-cloud synchronization solution to ensure models are available on JuiceFS across all clouds.
When handling challenges such as daytime scaling of inference services, as in Horizontal Pod Autoscaler (HPA) scaling, many inference services can start simultaneously. This requires rapid access to large numbers of model files. Without local caching, bandwidth consumption would be enormous.
To address this, we implemented a “warm-up” strategy, preloading models expected to be accessed into the cache before scaling. This significantly improves scaling response, ensuring inference services can start quickly and operate smoothly.
Management: Model repository upload and download design
The management interface focuses primarily on upload and download features. We developed a client supporting S3 protocol uploads. It has an S3 gateway receiving and translating these requests and interacting with metadata systems such as Redis.
A notable design feature is deduplication for the same files, similar to Docker image repository. Each file’s MD5 hash is calculated, and duplicate files are not re-uploaded, saving storage space and improving upload efficiency.
When updating models, we also retain snapshots. With JuiceFS snapshot capabilities, copying files does not create additional files in OSS but instead records them in metadata. This makes model updates and snapshot retention more convenient and efficient.
Our future plans
On-demand synchronization for multi-cloud model repository
Currently, we rely on periodic batch synchronization to replicate JuiceFS cluster data across clouds. However, this approach may not meet future demands for higher synchronization granularity.
We plan to enhance this by implementing a tag-based synchronization system that identifies areas needing synchronization and automatically syncs data across clouds when a model upload event occurs. We’ll also use warm-up strategies to streamline synchronization, improving efficiency and accuracy.
Scaling cache from standalone to distributed cache
At present, we use a standalone cache with 3 TB of NVMe storage. This is adequate in the short term. However, to meet future storage and access demands, we’ll develop a distributed cache component based on consistent hashing principles. This will enhance capacity and hit rate, supporting larger-scale data storage and access.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.