















JuiceFS Enterprise Edition 5.1 is released! As a distributed file system designed for high-performance computing with massive files, JuiceFS Enterprise Edition is widely applicable in various AI and big data processing tasks, including generative AI, autonomous driving, quantitative finance, and biotechnology. Our customers include leading tech firms such as MiniMax and Momenta.
To better meet the demands of data management across multi-cloud and hybrid cloud environments and to enhance support for a broader range of AI applications, this release brings several new features and extensive optimizations. These updates improve multi-cloud and hybrid cloud data management, streamline AI workflows, and enhance file system access capabilities, boosting both system performance and observability.
Key new features
Write support to mirror clusters for efficiently managing multi-cloud and hybrid cloud architectures
As GPU computing resources become increasingly scarce with the rise of large language models (LLMs). Especially for users requiring general model pre-training, traditional strategies of “computing following storage” must shift to “storage following computing.” Consequently, enterprises often face challenges in cross-regional and multi-data-center computing collaboration.
To ensure data consistency and simplify management, companies typically choose public cloud object storage in specific regions as the central storage point for all model data. However, scheduling computing tasks often requires manual intervention, such as copying data in advance. This is because the scheduling system is unaware of which data centers need which data—often dynamically changing. Traditional methods of manual intervention, copying, and migration are not only costly but also complex to manage and maintain. Various issues, including access control, can be particularly challenging.
JuiceFS Enterprise Edition's mirror file system feature allows users to replicate data from one region to multiple regions, forming a one-to-many replication relationship. This ensures data consistency while significantly reducing manual operational efforts. In previous versions, the mirror file system client only supported read-only mode. In the new version 5.1, we’ve introduced write functionality, enabling applications to access a unified namespace in the same way from any data center. This ensures data consistency while providing local caching for accelerated performance.
Specifically, clients with enabled write functionality connect to both the primary cluster and the mirror cluster's metadata services. The system will separate read and write operations, with read requests going to the mirror metadata service and write requests directed to the primary metadata service. After receiving a response from the primary metadata service, the client's write request does not immediately return; it waits until the modification is updated in the mirror metadata service. This way, when the client reads from the mirror, it accesses the latest metadata information, ensuring consistency within the file system.
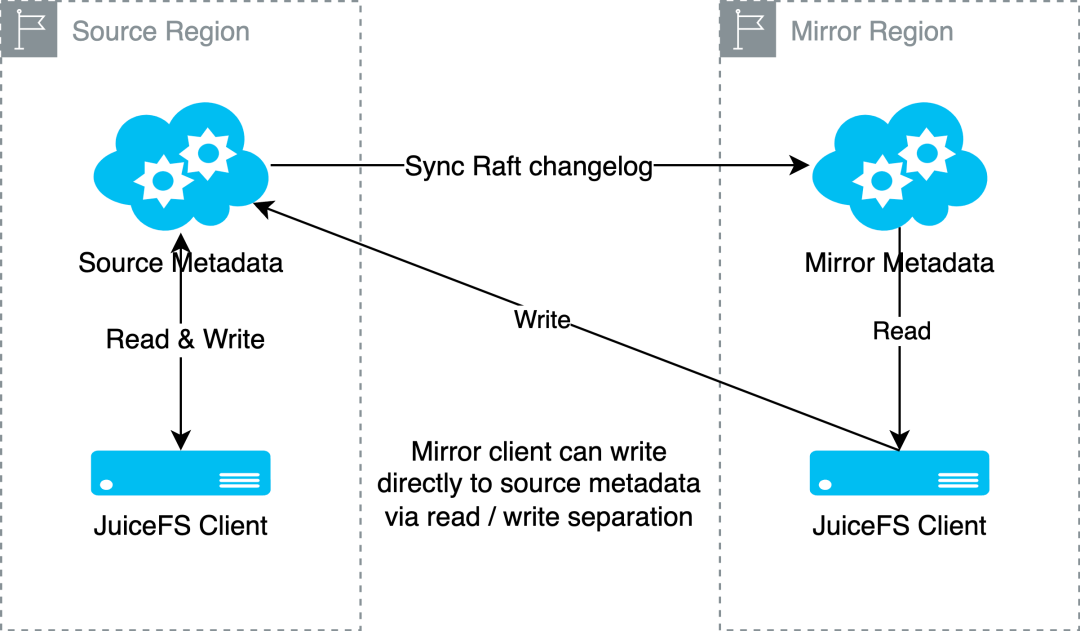
For example, in multi-site training scenarios, when each mirror site’s training cluster saves checkpoint files to its local JuiceFS instance, the system automatically writes to the primary site’s metadata and object storage, syncing to other mirror sites. This feature simplifies and accelerates the checkpoint recovery process for subsequent training tasks and model loading for inference services, while ensuring data consistency across mirror clusters during training and inference.
A Python SDK for enhanced file system access capabilities in AI scenarios
In the AI domain, data scientists and training frameworks widely use Python. While JuiceFS users typically access the file system via Portable Operating System Interface (POSIX) mount, some restricted environments (like non-privileged containers and most serverless setups) limit POSIX mounting due to the unavailability of FUSE modules. To address these limitations and better support AI scenarios, JuiceFS 5.1 introduces a Python SDK, allowing applications to access JuiceFS directly within processes. The JuiceFS SDK is designed to reference Python’s built-in functions and parts of the os package, making it easy for users to get started.
Here’s a sample code snippet:
import juicefs
# Create a JuiceFS client where 'testvol' is the user's file system name.
vol = juicefs.Client('testvol')
vol.makedirs('/dir')
with vol.open('/dir/file', 'w') as fd:
fd.write('helloworld')
with vol.open('/dir/file') as fd:
data = fd.read()
assert data == 'helloworld'
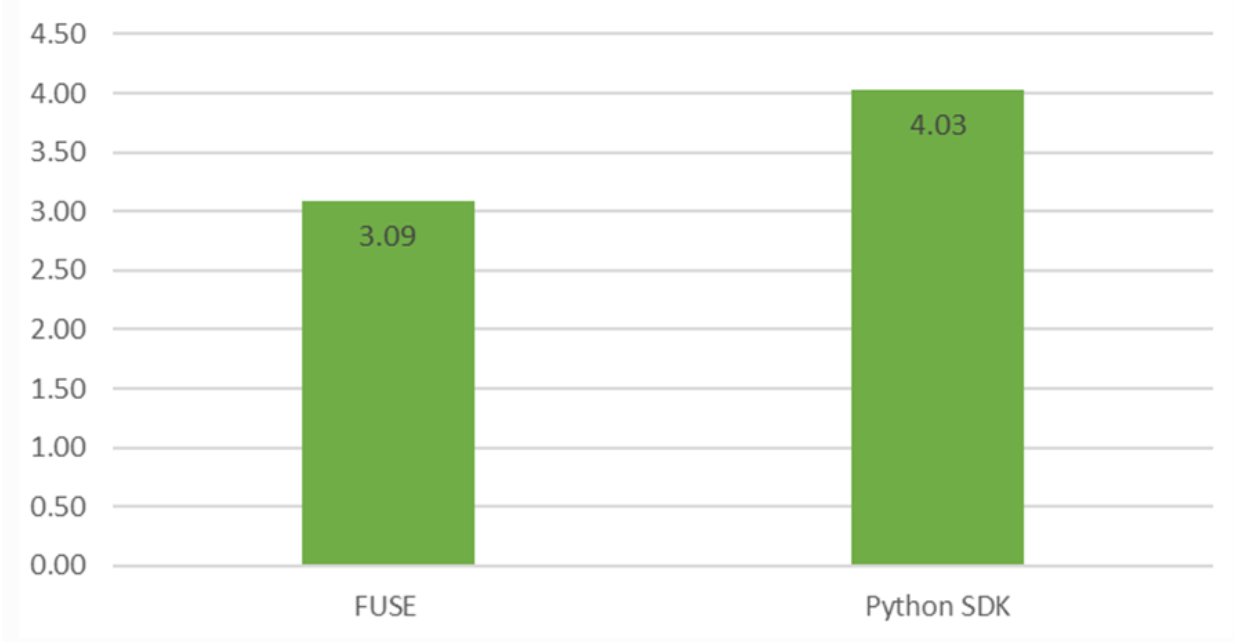
In addition, we aim to overcome FUSE’s performance bottlenecks in certain high-performance scenarios through the Python SDK and achieve more efficient data processing. In single-thread read performance tests, data reading speed using the Python SDK significantly outperformed FUSE, with speed improvements exceeding 30%.
S3 Gateway upgrade with more flexible multi-user permission management
JuiceFS stores files in chunks within underlying object storage and provides a POSIX interface for access. However, when users need to access these files via an S3-compatible interface, they use JuiceFS Gateway. In version 5.1, JuiceFS Gateway introduces advanced features like identity management and event notifications to accommodate multi-user environments and complex application requirements.
-
Identity and access management (IAM): This feature supports complex multi-user management and access control, including user addition, service account management and policy inheritance, issuance of temporary security credentials, and permissions configuration and customization. User group management and anonymous access control are also supported, effectively protecting data security and access flexibility in multi-user environments.
-
Event notifications: JuiceFS Gateway allows using bucket event notifications to monitor changes to objects within the storage bucket. Users can trigger automated actions based on events such as object creation, modification, access, or deletion. Supported event types include object creation, completion of multipart uploads, access header information, object deletion, as well as bucket creation and removal. Event notifications can be configured to publish to various targets, including Redis, MySQL, PostgreSQL, and WebHooks, further enhancing data management automation and real-time monitoring capabilities.
Group backup in distributed cache clusters for enhanced stability
Distributed cache clusters have always been a core feature of JuiceFS Enterprise Edition. When numerous clients frequently access the same dataset, this feature enables shared caching of the same batch of data, significantly improving performance.
In AI scenarios, model files often exceed hundreds of GB, posing performance challenges for file access. JuiceFS Enterprise Edition's distributed cache can construct large cache space, greatly enhancing data read speeds, especially when simultaneously launching thousands of inference instances. Furthermore, for AI applications requiring frequent model switches, such as Stable Diffusion’s text-to-image services, cache clusters can dramatically reduce model loading times to improve user experience.
In previous versions, the cache cluster only maintained a single copy of data. If a cache node failed, this could lead to a significant temporary increase in object storage access. To address this, JuiceFS 5.1 introduces the group backup feature. Users can choose additional cache space to store extra copies, ensuring high cache hit rates even when some nodes encounter issues.
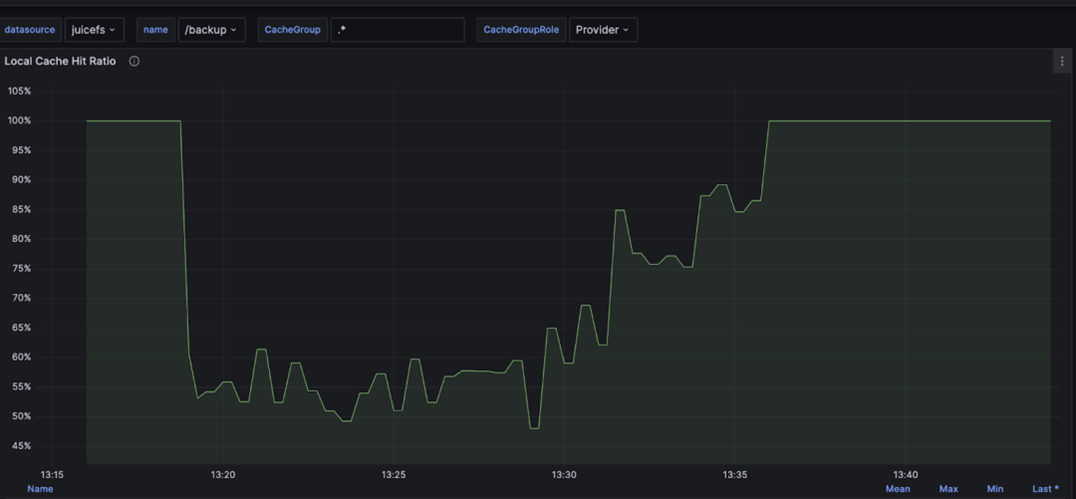
To illustrate the impact of this feature on cache hit rates, we took one of the two cache nodes offline. Without backup copies, the cache hit rate significantly dropped to about 55%.
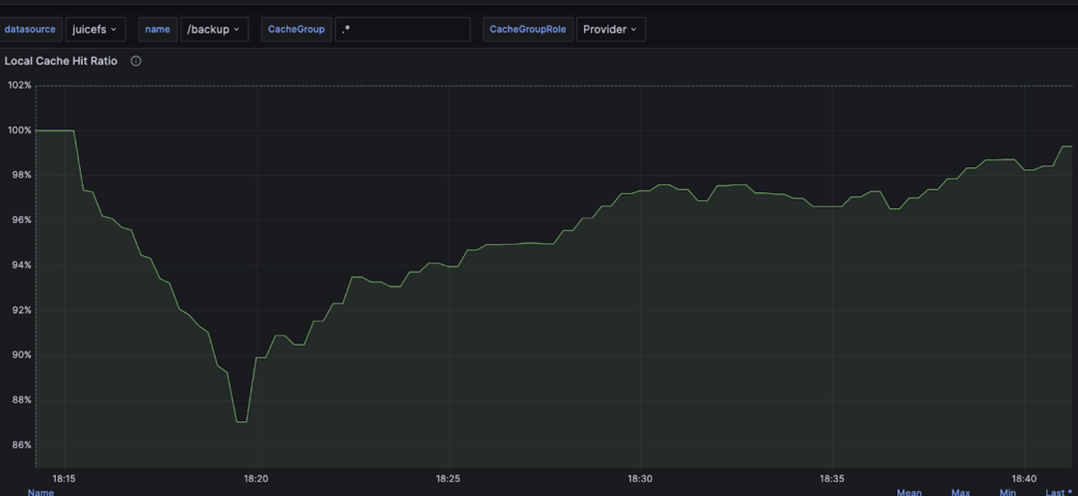
When we enabled the backup feature and performed the same failure simulation, we observed that the cache hit rate remained above 86%, with object storage penetration traffic reduced by 70%. Due to cache space and performance constraints, it cannot be guaranteed that backup copies will always exist.
In addition, when scaling out the cache cluster, users can configure backup copies for new nodes (typically pointing to existing cache nodes). This can effectively improve hit rates during the scaling phase and minimize impacts on online services.
Management feature optimizations
Data management and updates
In version 5.1, we improved file management and optimized storage efficiency in JuiceFS:
- Updating imported files (
--updateand--force-update): Allows users to update already imported files, resolving data synchronization and version update issues. - Automatic exclusion of chunk mode data objects: Automatically skips JuiceFS' own data objects (those starting with
{volname}/chunks/) during import without additional configuration. - Skipping trash for direct deletion (
--skip-trash): Admin users can directly clear data without waiting for the trash mechanism, allowing quick space reclamation. - Active data compression: The new
compactcommand enables users to trigger data compression proactively, cleaning up overwritten data in object storage to reduce storage usage, particularly in frequently modified file scenarios.
Cache management
In JuiceFS 5.1, we enhanced control over caching mechanisms, allowing for more flexible and efficient cache usage:
- Unlimited cache size (
--cache-size -1): Users can set the data cache size to unlimited, suitable for scenarios where the entire disk is used for caching. - Force cache object write (
--cache-large-write): Users can explicitly choose to build a cache when uploading objects. - Displaying cache location (
--check): Helps users understand the distribution of cached data, suitable for multi-node cache groups.
Security and privacy
In JuiceFS 5.1, these updates focus on enhancing encryption, monitoring, and latency tracking, providing users with improved security and detailed insights into system performance and cache operations:
- Enhanced key encryption (
--encrypt-keys): Adds stronger encryption for store access credentials, enhancing security for users with high data access security requirements. The new version provides users with detailed monitoring of system states across various operational stages, helping identify issues promptly and optimize performance. - Cache and error monitoring:
blockcache.errors: Tracks error (including timeouts) counts across all cache disks in the current process.remotecache.peers: Displays the number of cache group nodes connected to the current process.
- Latency monitoring: Added P50, P95, and P99 latency metrics, covering FUSE operations, metadata operations, and read/write latencies for remote caches.
warmup-related monitoring: Includes metrics for warming up directories, files, data blocks, chunk mode files, and objects after import, allowing users to gain insights into thewarmupexecution and cache usage.import-related monitoring: Covers the total number of successfully imported, failed, and skipped files along with their object sizes. This helps monitor the status of the import process and file updates.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.