MySQL backup, verification and recovery solution based on JuiceFS
MySQL usually contains the company's most important product and user information and is the company's core asset. Once lost or damaged, it can cause disastrous losses (even bankruptcy). To ensure data security make sure to do multiple backups. We'll show you how to use JuiceFS to considerably simplify MySQL's backup, verification, and recovery processes to ensure data security.
JuiceFS is excellent for storing backup data for MySQL because of the following reasons:
- It is a POSIX-compliant file system that can write backup data directly to JuiceFS or running MySQL on JuiceFS without having to go through local disk transfers (including verifying and restoring data), which saves a lot of time, usually hours or a few days, these times are invaluable in data recovery.
- It supports transparent data compression and storage encryption, avoiding the hassle of manual compression and encryption, effectively reducing storage costs and ensuring data privacy, as well as saving a lot of backup and recovery time.
- It supports directory-based snapshots, making backup verification and recovery easy.
- It supports all regions of all public clouds and can be easily backed up offsite.
- Its capacity is elastic and scalable, you only need to pay as you go according to the actual usage, no need to make a capacity planning and expansion.
Logical Backup
Logical backups store data in MySQL in a plain text format (the most robust format). Common tools include mysqldump and mydumper. Mysqldump is MySQL's native backup tool, stable and easy to use, but slower. Mydumper supports multi-threaded export, which is faster, and recommended.
There is currently no tool for incremental logical backup. In theory, you can compare the data difference between two full backups, and use diff to generate a difference file as an incremental backup.
Logical backups are slow. If the database is too large, it is recommended to do a logical backup every weekend or every month. If the database is small, you can also do logical backups every day or every hour. For RDS that already has backup function in the public cloud, different product backup strategies are different. It is also recommended that you do another logical backup to avoid the risk caused by RDS backup failure.
Backup
Logical backup data can be written directly to the JuiceFS mount directory (assumed to be /jfs ), such as using mydumper to export data:
mydumper -B <db_name> --outputdir /jfs/<db_name>_data
The text data of the logical backup is very easy to compress. JuiceFS will use the current state-of-the-art Zstandard compression algorithm to compress and save the data by default. It has very good write performance (up to 300MB/s) and is much faster than mydumper's compression function.
Verification
Timed backup does not mean peace of mind, because backup can also be a problem, verifying backup is very necessary. For MySQL backups, whether the backup is really available is only known once recover a backup.
To verify the logical backup, you can enable an empty MySQL instance to recover, and then do some integrity checks on the restored MySQL, such as checking the size of data.
Recovery
When restoring data from a logical backup, start an empty MySQL instance and then import the data using myloader:
myloader -B <db_name> --directory /jfs/<db_name>_data
Physical Backup
Physical backup refers to backing up the data files actually used by MySQL. The industry usually uses the open source tool XtraBackup provided by Percona to directly read MySQL data files for backup, without the need for logic analysis by MySQL, which is much faster.
XtraBackup supports full backup and incremental backup, and it is recommended to alternate between them in a certain period. For example, do a full backup every weekend, and do an incremental backup every day for 6 days, and saved the backup data for more than 4 weeks.
Backup
To do a physical backup with xtrabackup, it is recommended to back up all the databases of the entire instance instead of specifying some databases.
Make a full backup of the data for the entire MySQL instance
xtrabackup --backup --target-dir=/jfs/base/
You can then do incremental backups to reduce the size of data and backup time, such as:
xtrabackup --backup --incremental-basedir=/jfs/base --target-dir=/jfs/incr1
After the incremental backup, you can continue to use the full backup as the baseline, or you can use the previous incremental backup as the baseline, for example:
xtrabackup --backup --incremental-basedir=/jfs/base --target-dir=/jfs/incr2
It is recommended to use a full backup as a baseline for incremental backup. Although the size of data will be larger, the recovery process will be simpler and robust.
Verification
When verifying an incremental backup, you need to attach the incremental data to the full backup. In this case, you can use the snapshot function of JuiceFS to quickly copy a full backup for verification, and then delete it after the verification is completed.
Create a snapshot based on the full backup just created, because the data file will be modified when MySQL is running. If it is run directly on the backup data, the backup will be destroyed.
juicefs snapshot /jfs/base /jfs/base_snapshot
Because xtrabackup does a lot of random writes when doing apply log, it is recommended to add the --writeback parameter when mount JuiceFS to optimize the performance of random writes.
Prepare data
xtrabackup --prepare --apply-log-only --target-dir=/jfs/base_snapshot
If you are verifying the incremental backup, you need to do the overlay processing on the full backup data (there are explanations in the next section of recovery), such as:
xtrabackup --prepare --apply-log-only --incremental-dir=/jfs/incr1 --target-dir=/jfs/base_snapshot
Start a new MySQL instance and set the data directory to /jfs/base_snapshot. If it starts successfully, the backup is correct. In a production environment, you can also make this MySQL instance as a slave and synchronize with master instance to verify that the backup is correct.(Detailed code and description in our user case)
Recovery
When rebuilding a database from a physical backup, you need to find a full backup and copy it to the MySQL data directory that will be running:
rsync -avP /jfs/base/* /var/lib/mysql
a) If you only need to restore with a full backup, do the following:
xtracbackup --prepare --target-dir=/var/lib/mysql
b) If you need to recover from an incremental backup, you need to add the --apply-log-only parameter:
xtracbackup --prepare --apply-log-only --target-dir=/var/lib/mysql
Then apply the incremental backup:
xtrabackup --prepare --incremental-dir=/jfs/incr1 --target-dir=/var/lib/mysql
Note: If there are other incremental backups, you also need to add the --apply-log-only parameter.
After that, you need to modify the file attributes to make the MySQL instance can read and write, and then start the MySQL service to complete the recovery operation.
The above is a simple process for full and incremental backup and data recovery. For more details, please refer to the official documentation of xtrabackup.
Transaction Log Backup
Both logical and physical backups can only be performed in a certain period. The data changes between the two backup tasks can be recorded and restored using the transaction log binlog. So backing up the binlog is also very important.
First turn on the log-bin option in the MySQL configuration file and restart MySQL for the changes to take effect. Then do a scheduled task and synchronize the binlog to the mount directory of JuiceFS.
rsync -au --append /var/log/mysql/mysql-bin.* /jfs/backup/binlogs/
Note that in the MySQL production configuration, log-bin and datadir should set to different disks to avoid a tragedy in which one disk is broken and the two pieces of data are lost together.
When using binlog logs for recovery, simply copy them to the MySQL log directory and follow the MySQL instructions to replay the binlog to the specified location.
Fast Recovery
When we completed physical and logical backups, and also prepared a binlog backup, if an accident occurs and data needs to be recovered, it is important to confirm the status point (Pos) or time point to be restored.
Select the most recent full backup and incremental backup according to the state (time point) to be restored, and then play the binlog between them.
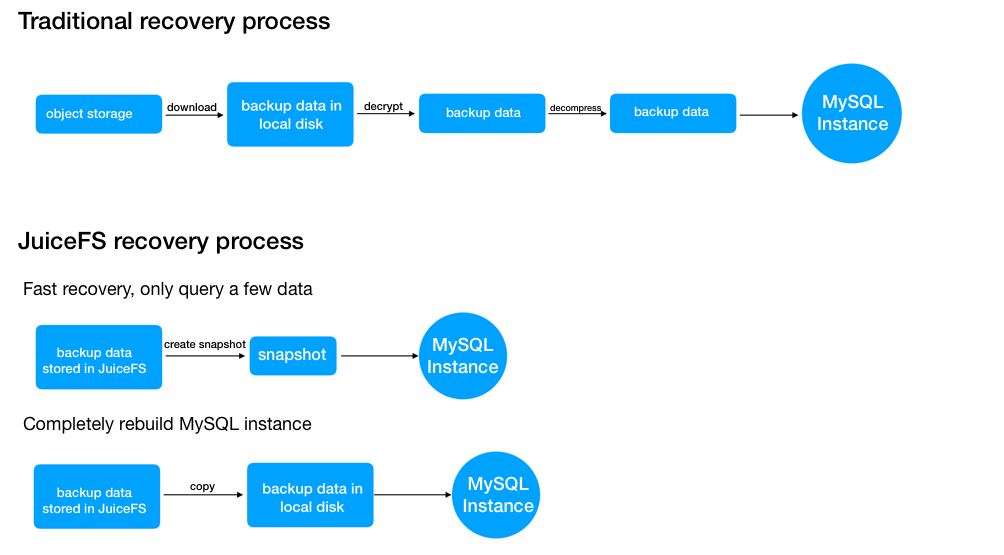
Depending on the purpose of the recovery, you can choose to restore in the JuiceFS or copy it to the appropriate local storage for restore: 1) If you do some simple queries after recovery, and there are not too many transaction logs to be replayed, you can restore them directly after taking a snapshot on JuiceFS, just like the backup verification method in the previous physical backup section. 2) If you want to restore an instance of the production environment, you need to copy the data from JuiceFS to the local disk, and then restore it.
Performance Advantage
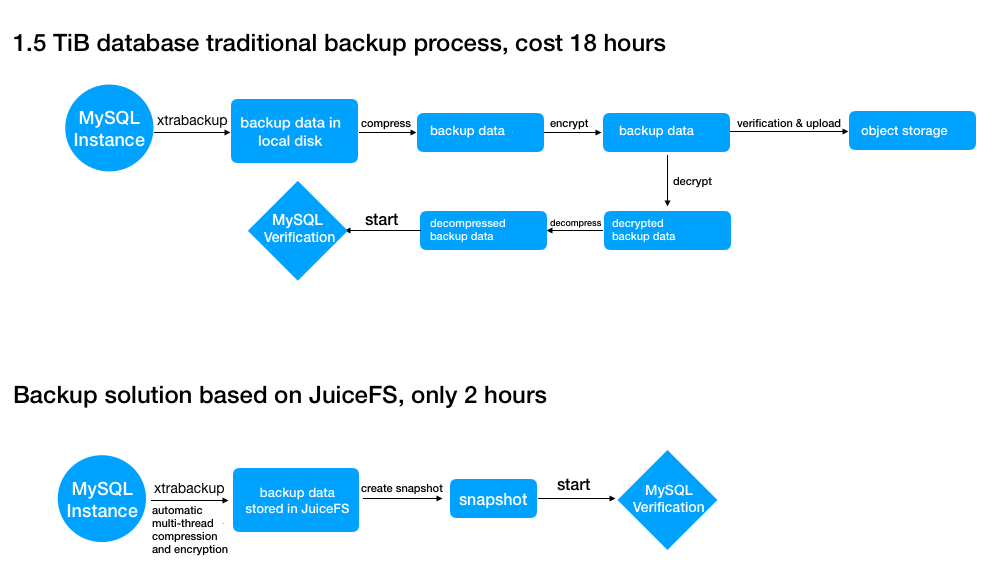
To save storage space and protect data security, backup data is usually compressed and encrypted before being stored. Verification and recovery require decryption and decompression. The whole process is very time-consuming and space-consuming. Because JuiceFS internally implements transparent data compression and encryption, we can considerably simplify the backup, verification, and recovery process while dramatically reducing backup and recovery time. Take a 1.5T database of MySQL data as an example, using JuiceFS's backup method can shorten the original 18 hours to about 2 hours, as shown in the following figure:
Time is more valuable when doing data recovery. If you are doing partial data recovery, you can start MySQL directly on JuiceFS for data recovery in a few minutes. Even if you rebuild a full database, it will be much faster than other methods, as shown in the following figure: