导入文件系统
不论是企业版还是社区版,JuiceFS 都支持用 juicefs [dump|load] 导出、导入文件系统的元数据。由于 JuiceFS 采用元数据与数据分离的架构,文件数据独立存储在你所选用的对象存储服务,因此导入文件系统,事实上就是导入元数据的过程——对象存储数据并不需要搬运。如果你还不熟悉这种分离存储的设计,阅读我们的架构介绍。
和 JuiceFS 社区版不同,你不需要特意用 juicefs dump 来备份 JuiceFS 企业版的元数据——我们的运维团队已经保证了所有元数据服务都在定期备份。简而言之,企业版用户不需要操心备份和恢复的工作。
因此对于企业版,导出和导入功能可以用来:
- 从企业版迁移到社区版,具体的操作步骤未在本章介绍,如有需要请联系我们的工程师
- 在企业版的不同服务区域之间进行迁移,本章介绍的流程需要停写,如果你的文件系统无法停写,请联系 Juicedata 架构师,制定平滑迁移方案
- 导出元数据,用于分析和排查问题
下面以从社区版迁移到企业版为例,介绍如何导入文件系统。
规划迁移
如果你希望从社区版迁移到企业版,那么在规划之初,就应和 Juicedata 架构师充分沟通,明确以下几点:
- 为什么决定采纳企业版,和我们的架构师充分讨论,确定企业版可以解决目前遇到的问题。如果不确定,请务必提前安排测试;
- 目前社区版的使用规模、应用场景,和我们一起讨论是否应采纳企业版的多分区架构;
- 兼容性注意事项:社区版和企业版的文件系统是兼容的、可以互相迁移,但需要注意:JuiceFS 企业版支持并默认开启「UID/GID 自动映射」,简单来说,JuiceFS 会将同名的用户和组映射成相同的 UID / GID。但由于社区版并未实现该特性,因此对于导入的文件系统,会自动禁用自动映射,防止产生权限错乱问题。
- 目前而言,迁移过程需要停写,导入和导出都应提前演练,按照演练时间的 1.5 到 2 倍来规划实际迁移操作耗时,留出充足冗余来应对沿途可能发生的状况。
演练
不论是多大的文件系统,我们都要求在迁移之前至少进行过一次全量的、完整的流程演练,最大程度排除沿途可能的状况。
演练的过程和标准步骤无异,直接参考本文的后续小节执行即可,但是由于是演练,过程中注意:
- 不需要停写,
juicefs dump命令运行时,文件系统并不受影响,业务可以继续使用。但由于导出的备份文件可能是业务持续写入的某个中间态,因此一般不直接用于最终的迁移操作; - 导入完成后,不要急着挂载 JuiceFS 企业版文件系统,先将挂载令牌(Token)改为「只读」并禁用「后台任务」,避免演练过程中,客户端篡改对象存储数据;
- 导入测试完毕、验证文件系统可以正常使用后,Juicedata 工程师会清空元数据集群,将其恢复至全新的状态(或者新建一套元数据集群)。
准备目标文件系统
如果迁移目的地是私有部署,必须提前将系统部署好,节约操作时间。
导入流程的目标集群必须是全新的空白元数据集群,不能存在任何已有的文件系统,请提前联系 Juicedata 工程师为你创建新的专有区域、部署元数据服务,确保在全新的集群操作导入。
登录控制台,点击右上角「创建文件系统」,但并不急着填写信息,而是继续点击对话框右上角的「导入文件系统」,在接下来的界面中仔细阅读各项设置,并按照源文件系统的情况进行填写。
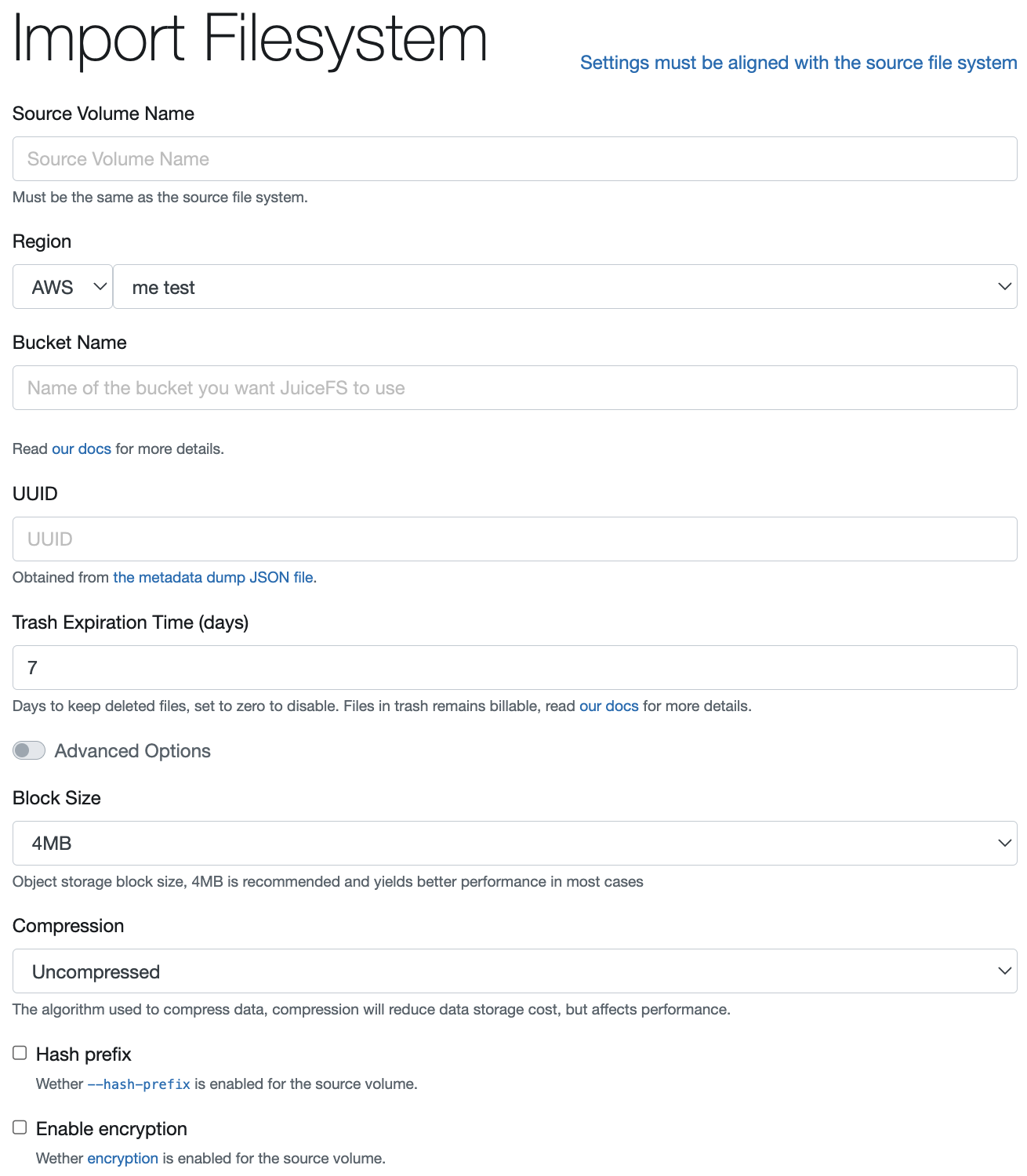
创建好文件系统后,还需要点击「访问控制」页面,取消访问令牌的后台任务权限,这十分重要,并且不论是演练,还是实际迁移过程,都应先禁用后台任务。仅当确认导入完成、目标文件系统可以正常使用、投产时,才重新开启后台任务。
停写
如果只是演练迁移流程,那么并不需要停写,请跳过本小节。
导出元数据之前,必须确保源文件系统已经停写、不会发生任何改动。确切地说,不光是需要提前停写,而且所有的非只读客户端都必须卸载,防止任何后台任务、碎片合并影响数据完整性。
为了保险起见,用 juicefs status 命令确保所有客户端均已下线(Sessions 字段为空),再进行后续步骤。
导出文件系统
导出之前,先将文件系统的配置记录下来,比方说 block size、压缩和加密设置,这些设置都需要在目标文件系统进行对齐,导入才能顺利运行。不难想象,如果源文件系统和目标文件系统使用不同的 block size,或者压缩设置,那么对象存储的数据是绝对无法交叉读取的。
在一个能够访问元数据引擎的环境,使用 status 命令就能打印这些信息:
$ juicefs status META-URL
{
"Setting": {
"Name": "myjfs",
"UUID": "6b0452fc-0502-404c-b163-c9ab577ec766",
"Storage": "s3",
"Bucket": "https://xxx.s3.amazonaws.com",
"AccessKey": "xxx",
"SecretKey": "removed",
"BlockSize": 4096,
"Compression": "none",
"TrashDays": 1,
"MetaVersion": 1
},
...
}
接下来,使用 dump 命令导出 JSON 格式的文件系统元数据:
# 在目标文件添加 gz 后缀以启用压缩
juicefs dump META-URL /tmp/meta.json.gz
# 如果速度太慢,可以启用 --fast 模式,将元数据全量加载到客户端内存中来提速
# 可想而知,如果要使用 --fast,必须保证客户端节点内存充足
juicefs dump --fast META-URL /tmp/meta.json.gz
# 如果回收站用量较大,并且可以丢弃,那么考虑导出时跳过回收站
# 为了避免泄漏,投产以后需要用 juicefs gc 命令清理对象存储
juicefs dump --skip-trash --fast META-URL /tmp/meta.json.gz
在导出结果中,同样也包含了文件系统的配置信息,如果在前序步骤中的 juicefs status 输出信息没有保存好,也可以直接从 JSON 文件中获取:
# 记录其他关键的文件系统配置,这些设置都记录在 JSON 文件的 Setting 字段中,此处不再一一列举
head -n 20 meta.json
导入元数据
导入元数据需要用 JuiceFS 客户端来执行,因此你需要先挂载好文件系统。如果你尚不熟悉如何安装 JuiceFS 客户端、挂载文件系统,可以阅读「快速上手」。
# 挂载文件系统
juicefs mount myjfs /jfs
# 导入元数据文件
juicefs load /jfs /tmp/meta.json.gz
如果两个文件系统的关键设置都正确对齐,那么导入命令会顺利完成(退出码为 0)。接下来用 ls 访问挂载点,就能够看到文件元数据已经顺利导入了。挑选一个有实际内容的文件来读取、确认一切运作正常吧。
验证
导入完毕以后,遵循下方步骤核实文件系统正确运行:
- 再次核实源文件系统已经彻底卸载所有客户端、没有任何写入。这非常重要,如果在导出以后,源文件系统仍有修改,则会造成不一致,使导入数据损坏;
- 读取一个很久以前创建或修改的文件(mtime 尽可能早),验证能够正常读取;
- 读取一个最近创建或修改的文件(mtime 尽可能晚),验证能够正常读取;
- 用类似
date > delete.txt的命令验证写入正常,请不要使用touch命令,��他是纯元数据操作,无法完整验证写入功能。
如果以上验证和测试均顺利通过,则认为导入成功,可以继续对接和使用。
如果不确定源文件系统是否彻底停写,或者读取测试果真出现问题,按照以下步骤排查:
-
如果源文件系统是社区版 JuiceFS,首先检查元数据引擎的数据库日志,核实导出以后是否仍有修改;
-
运行
juicefs fsck子命令,扫描损坏文件:juicefs fsck myjfs -
根据扫描结果评估损坏的范围和原因,以及是否需要重新导出。如果确实是源文件系统未彻底停写导致的,那么再次导出时,需要提前用
juicefs status命令核实所有客户端均已下线。如果无法确定损坏的原因,联系 Juicedata 工程师一起协查。
投产
验证完毕、确认一切正常工作,按照以下步骤来进行生产化梳理:
- 点击进入文件系统的「访问控制」页面,重新启用后台任务权限,让客户端正常运行后台任务;
- 如果在导出时启用了
--skip-trash,那么相应的,迁移完毕以后可能需要用juicefs gc来清理对象存储的残留文件。如果回收站用量特别小,可以按照实际情况跳过该步骤; - 根据目前文件系统的用量,选择合适的付费方案。云服务用户请前往这里操作,私有部署用户请联系 Juicedata 工程师获取对应的操作步骤;
- 对于私有部署集群,还需要对整个私有部署系统进行生产化梳理,在 Juicedata 工程师的帮助下一起完成。


