问题排查案例
这里收录常见问题的具体排查步骤。在排查之前,首先用 juicefs version 确认自己所使用的客户端版本,如果过于老旧(比如发布时间超过半年),推荐先升级到最新版本客户端,提前隔离旧版问题:
# 用 --restart 来顺便平滑重启挂载点
juicefs version --upgrade --restart
挂载失败 / 挂载时卡住
在挂载命令后面加上 --foreground --verbose 参数,让挂载进程运行在前台,方便阅读错误输出:
juicefs mount $VOL_NAME /jfs --foreground --verbose
常见的错误比如:
-
AK/SK 填写错误,导致调用对象存储 API 创建存储桶失败。
-
解析域名失败,无法连接元数据服务,那么需要确认上游 DNS 服务器正常运作,并刷新本地 DNS 缓存。
-
能够成功解析域名,但是无法与元数据服务器建立连接,很可能是由于防火墙限制了端口访问。需要确保挂载的机器能够访问外网
9300 - 9500TCP 端口使其能与我们的元数据服务器通信,以 iptables 为例:iptables -A OUTPUT -p tcp --match multiport --dports 9300:9500 -j ACCEPT如果你使用的是公有云平台的安全组,登录公有云的控制台进行相应调整。
-
私有部署 挂载命令成功执行,宿主机挂载点也能正常运行,但短暂过后,挂载点莫名消失。这种情况往往是由于宿主机存在遗留的挂载守护进程导致的。
JuiceFS 客户端运行时,会产生挂载进程(Go 二进制)和守护进程(Python)。如果集群发生了元数据节点迁移,迁移期间的特殊操作(比如强行卸载)会导致挂载进程丢失,但守护进程仍然正常运作。此时再次执行挂载,虽然挂载点能正常创建,但遗留的守护进程由于元数据服务配置变动,会不断尝试卸载挂载点,并反复尝试重连,并因配置过期而无法成功。这时用以下命令清理守护进程并重试:
# 定位遗留的 JuiceFS 客户端守护进程,守护进程由 Python 运行
ps -ef | grep juicefs
# 记录守护进程的 PID,用 kill 终结进程,然后重试挂载
kill $PID
读写失败
JuiceFS 的读写失败可能由多种多样的原因构成,无法一一列举。不过在发生读写错误时,你总能在客户端日志(默认 /var/log/juicefs.log,详见 mount 参数)里找到报错原因,在这里介绍一些常见故障和排查步骤。
无法与元数据服务通信
JuiceFS 客户端需要时刻与元数据集群保持畅通网络连接,才能高速访问元数据服务。如果运行途中网络访问中断,一般会看见大量类似下方日志:
<ERROR>: request 402 (40) timeout after 1.000603709s
<ERROR>: request 428 (3283870) failed after tried 30 times
以上日志中的 request 402 和 request 428 都是客户端与元数据服务通信的 RPC 命令代号,大部分属于文件系统的元数据操作。如果日志中大量出现此类 RPC 请求超时的错误,可以用下方命令进行排查:
# 在 TCP 连接里定位到客户端连接的元数据服务地址
lsof -iTCP -sTCP:ESTABLISHED | grep jfsmount
# 如果客户端已经卸载,找不到 TCP 连接,也可以直接在配置文件里找到元数据服务地址
grep master ~/.juicefs/$VOL_NAME.conf
# 确保对元数据服务端口访问畅通(假设元数据服务地址为 aliyun-bj-1.meta.juicefs.com)
telnet aliyun-bj-1.meta.juicefs.com 9402
# 如果没安装 telnet,也可用 curl / wget,但由于元数据服务并不是 HTTP 协议,只能给出空响应
curl aliyun-bj-1.meta.juicefs.com:9402
# curl: (52) Empty reply from server
# 如果域名无法解析,则需要检查 master_ip 是否能正常访问,master_ip 同样在配置文件中可获得
grep master_ip -A 3 ~/.juicefs/$VOL_NAME.conf
# 用上方的网络排查命令确认 IP 能正常访问
# 如果域名能正常解析,确认结果与配置文件中 master_ip 匹配
dig aliyun-bj-1.meta.juicefs.com
经历上方排查,可能出现的问题以及处理手段如下:
域名无法解析
在云服务中,元数据服务域名在公网就能顺利解析,如果客户端无法解析该域名,多半表明宿主机的 DNS 配置有问题,需要予以排查。
不过事实上,就算域名无法解析,只要客户端能顺利访问元数据服务节点的 IP(配置文件中的 master_ip),JuiceFS 客户端就能正常工作。因此在私有部署中,并不强求域名一定可以解析,域名的存在主要是为了灾备,如果元数据服务节点不会发生且不打算迁移,可以不设置域名解析(会产生一些 WARNING 日志)。但如果设置了,一定要设置正确,不要为了避免 WARNING 日志而「乱加域名解析」,否则客户端万一需要重连元数据服务节点,通过错误的域名解析结果拿到了无法连接的地址,也会直接报错导致挂载无法使用。
master_ip 无法正常访问
在云服务中,客户端一般通过公网 IP 连接元数据服务,如果 IP 无法正常访问,作如下排查:
- 如果
curl、ping等探测命令发生 timeout,往往是安全组、防火墙设置有误,导致丢包,应予以排查。 - 私有部署 如果对元数据服务端口(默认 9402)探测结果为
Connection Refused,则可以认为访问畅通,但元数据服务没有在正常运行。 - 私有部署 如果已经为元数据服务设置了域名解析,可以按照上方排查示范命令,检查域名解析的结果与配置文件中的
master_ip匹配,如果二者不相同,根据实际情况修复域名解析,或者重新挂载。
元数据请求超时
通常而言,元数据请求只占用很少带宽。如果确认网络畅通,却频频发生类似 <ERROR>: request 402 (40) timeout after 1s 的超时日志,没有明确的文件系统访问报错,只伴随着读写性能不稳定,那么从以下角度进行排查:
- 在监控确认与元数据节点的 ping 延迟,如果存在延迟波动,并且时间点与 timeout 日志吻合,那么很可能是网络抖动所致;
- 在监控确认客户端节点的 CPU 用量,与宿主机实际 CPU 用量进行比对。对于容器,则需要确认资源声明,以及宿主机实际资源用量,确定没有因为超售资源而发生挤兑。如果客户端资源不足,发生了 CPU Throttle,也有可能出现请求 timeout,同时伴随着性能下降;
- 私有部署 在 Grafana 中打开 JuiceFS Meta info 监控面板,重点关注 CPU 面板。正常情况下,
syscpu用量应该偏低(3%-20%),如果syscpu接近 100%,意味着元数据服务已经面临性能问题,容易导致客户端请求超时; - 私有部署 如果通过类似跨区域网络专线(例如 AWS Direct Connect、Azure ExpressRoute)的方式访问元数据服务,发生带宽挤占时,元数据请求性能可能急剧下降,并在元数据服务日志中产生类似
outgoing queue of x.x.x.x:xxx (955107) is full, create a buffer (10240) for it的日志,这表示需要发送给客户端的流量大于实际网络带宽,因此只好暂存在缓冲区,然后重试。
与对象存储通信不畅(网速慢)
如果无法访问对象存储,或者仅仅是网速太慢,JuiceFS 客户端也会发生读写错误。你也可以在日志中找到相应的报错。
# 上传块的速度不符合预期
<INFO>: slow request: PUT chunks/1986/1986377/1986377131_11_4194304 (%!s(<nil>), 20.512s)
# 上传失败还可能伴随着打印堆栈信息,阅读出错的函数名,可推测是对象存储上传失败
<ERROR>: flush 9902558 timeout after waited 8m0s [writedata.go:604]
<ERROR>: pending slice 9902558-80: {chd:0xc0007125c0 off:0 chunkid:1986377183 cleng:12128803 soff:0 slen:12128803 writer:0xc010a92240 freezed:true done:false status:0 notify:0xc010e57d70 started:{wall:13891666526241100901 ext:5140404761832 loc:0x35177c0} lastMod:{wall:13891666526250536970 ext:5140414197911 loc:0x35177c0}} [writedata.go:607]
<WARNING>: All goroutines (718):
goroutine 14275 [running]:
jfs/mount/fs.(*inodewdata).flush(0xc004ec6fc0, {0x7fbc06385918, 0xc00a08c140}, 0x0?)
/p8s/root/jfs/mount/fs/writedata.go:611 +0x545
jfs/mount/fs.(*inodewdata).Flush(0xc0007ba1e0?, {0x7fbc06385918?, 0xc00a08c140?})
/p8s/root/jfs/mount/fs/writedata.go:632 +0x25
jfs/mount/vfs.Flush({0x2487e98?, 0xc00a08c140}, 0x9719de, 0x8, 0x488c0e?)
/p8s/root/jfs/mount/vfs/vfs.go:1099 +0x2c3
jfs/mount/fuse.(*JFS).Flush(0x1901a65?, 0xc0020cc1b0?, 0xc00834e3d8)
/p8s/root/jfs/mount/fuse/fuse.go:348 +0x8e
...
goroutine 26277 [chan send, 9 minutes]:
jfs/mount/chunk.(*wChunk).asyncUpload(0xc005f5a600, {0x0?, 0x0?}, {0xc00f849f50, 0x28}, 0xc0101e55e0, {0xc010caac80, 0x4d})
/p8s/root/jfs/mount/chunk/cached_store.go:531 +0x2e5
created by jfs/mount/chunk.(*wChunk).upload.func1
/p8s/root/jfs/mount/chunk/cached_store.go:615 +0x30c
...
如果是网络异常导致无法访问,或者对象存储本身服务异常,问题排查相对简单。但在如果是在低带宽场景下希望优化 JuiceFS 的使用体验,需要留意的事情就稍微多一些。
首先,在网速慢的时候,JuiceFS 客户端上传/下载文件容易超时(类似上方的错误日志),这种情况下可以考虑:
- 降低上传并发度,比如
--max-uploads=1,避免上传超时。 - 降低上传速率,比如用
--upload-limit=10限制上传速度为 10Mbps。 - 降低读写缓冲区大小,比如
--buffer-size=64或者更小。当带宽充裕时,增大读写缓冲区能提升并发性能。但在低带宽场景下使用过大的读写缓冲区,flush的上传时间会很长,因此容易超时。 - 默认 GET / PUT 请求超时时间为 60 秒,因此增大
--get-timeout以及--put-timeout,可以改善读写超时的情况。
做完相关调整以后,可以用 nethogs 查看每个进程使用网络的情况:
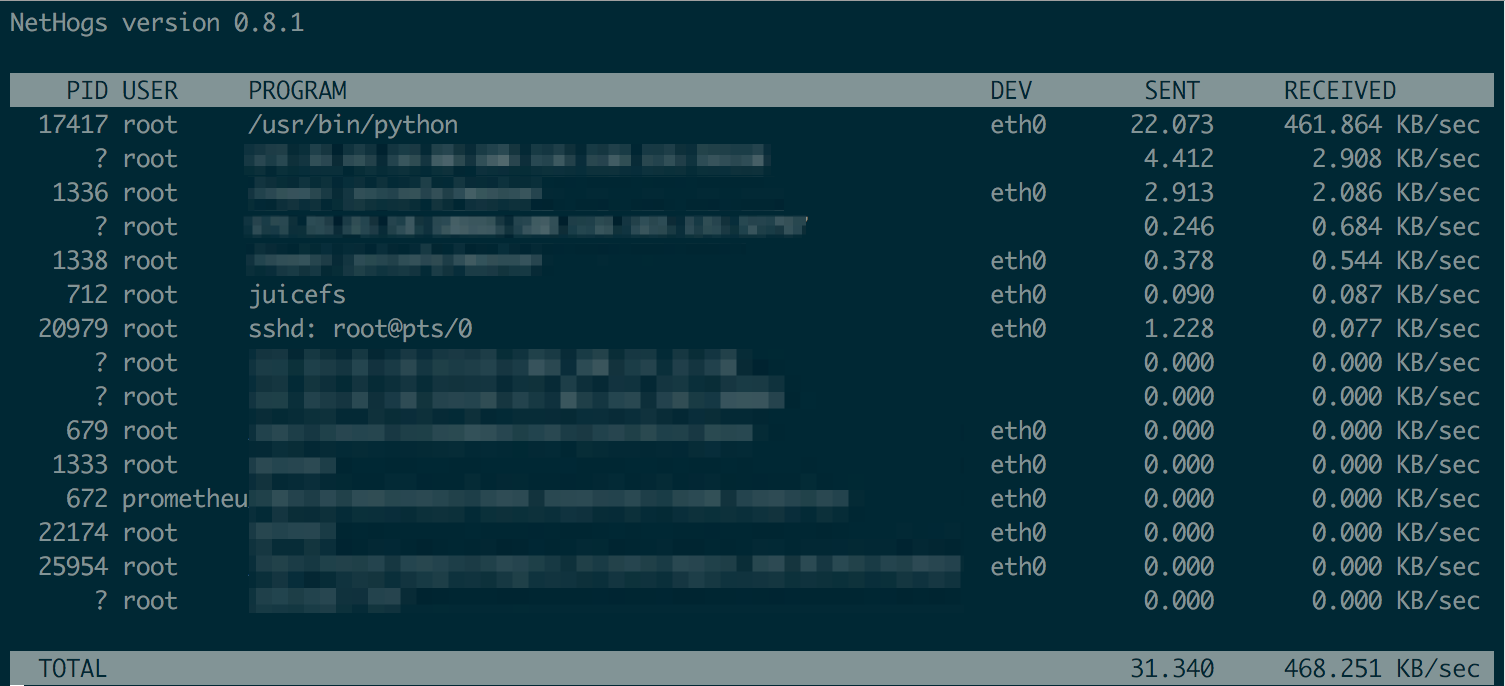
此外,低带宽环境下更要慎用「客户端写缓存」特性。如果在低带宽环境下同时开启了写缓存,极易引发碎片合并异常,导致读文件失败,参考下方的报错信息。
# 由于 writeback,碎片合并后的结果迟迟上传不成功,导致其他节点读取文件报错
<WARNING>: readworker: unexpected data block size (requested: 4194304 / received: 0)
<ERROR>: read for inode 0:14029704 failed after tried 30 times
<ERROR>: read file 14029704: input/output error
<INFO>: slow operation: read (14029704,131072,0): input/output error (0) <74.147891>
<WARNING>: fail to read chunkid 1771585458 (off:4194304, size:4194304, clen: 37746372): get chunks/1771/1771585/1771585458_1_4194304: oss: service returned error: StatusCode=404, ErrorCode=NoSuchKey, ErrorMessage="The specified key does not exist.", RequestId=62E8FB058C0B5C3134CB80B6
<WARNING>: readworker: unexpected data block size (requested: 4194304 / received: 0)
<WARNING>: fail to read chunkid 1771585458 (off:0, size:4194304, clen: 37746372): get chunks/1771/1771585/1771585458_0_4194304: oss: service returned error: StatusCode=404, ErrorCode=NoSuchKey, ErrorMessage="The specified key does not exist.", RequestId=62E8FB05AC30323537AD735D
为了避免此类问题,我们推荐在低带宽节点上禁用后台任务。你需要在控制台上的文件系统「访问控制」页面,创建新的「客户端访问令牌」,并取消勾选「允许后台任务」,最后用新生成的 Token 来挂载文件系统。
警告日志:找不到对象存储块
规模化使用 JuiceFS 时,往往会在客户端日志中看到类似以下警告:
<WARNING>: fail to read sliceId 1771585458 (off:4194304, size:4194304, clen: 37746372): get chunks/0/0/1_0_4194304: oss: service returned error: StatusCode=404, ErrorCode=NoSuchKey, ErrorMessage="The specified key does not exist.", RequestId=62E8FB058C0B5C3134CB80B6
出现这一类警告时,如果并未伴随着访问异常(比如日志中出现 input/output error),其实不必特意关注,客户端会自行重试,往往不影响文件访问。
这行警告日志的含义是:访问 Slice 出错了,因为对应的某个 Block 不存在,对象存储返回了 NoSuchKey 错误。出现此类异常的可能原因有下:
- JuiceFS 客户端默认会在后台任务运行碎片合并(Compaction),碎片合并完成后,文件与对象存储数据块(Block)的关系随之改变,但此时可能其他客户端正在读取该文件,因此随即报错。
- 某些客户端开启了「写缓存」,文件已经写入,提交到了元数据服务,但对应的对象存储 Block 却并未上传完成(比如网速慢),导致其他客户端在读取该文件时,对象存储返回数据不存在。
再次强调,如果并未出现应用端访问异常,则可安全忽略此类警告。
读放大
在 JuiceFS 中,读放大一般指代对象存储的下行流量,远大于实际读文件的速度。比方说 JuiceFS 客户端的读吞吐为 200MiB/s,但是在 S3 观察到了 2GB/s 的下行流量。这多半与预读和预取有关,可以先阅读对应的文档了解其设计。
影响读放大的因素有很多,一方面是应用程序的读取模式,另一方面则是 JuiceFS 客户端的相关设置,包括但不限于:
--buffer-size,更大的缓冲区能够允许更大的预读窗口和读并发;--initial-readahead,--max-readahead,--readahead-ratio这三个参数能够更细致地调节预读行为,大部分场景其实不需要用到,如果确实面临更复杂的读取模式,请先升级客户端至 5.1.18 或更新版本,再根据实际情况,在 Juicedata 工程师的指导下使用这些参数;--max-downloads也会间接影响预读窗口的大小,预读窗口最大不允许超过「块大小 * 下载并发」,按照默认的 4MiB 块大小和 200 并发,这个值是 800MiB。
在 5.1.18 以及之后的版本中,预读行为已经经过了很好的改善,能有效降低预期之外的读放大,因此阅读本节内容进行排查调优之前,建议先升级 JuiceFS 客户端,看是否有改善。
通过访问模式排查
结合先前问题排查方法一章中介绍的访问日志知识,我们可以采集一些访问日志来分析程序的读模式,然后针对性地调整配置。下面是一个实际生产环境案例的排查过程:
# 收集一段时间的访问日志,比如 30 秒:
cat /jfs/.oplog | grep -v "^#$" >> op.log
# 用 wc、grep 等工具简单统计发现,访问日志中大多都是 read 请求:
wc -l op.log
grep "read (" op.log | wc -l
# 选取一个文件,通过 inode 追踪其访问模式,read 的输入参数里,第一个就是 inode:
grep "read (148153116," op.log
采集到该文件的访问日志如下:
2022.09.22 08:55:21.013121 [uid:0,gid:0,pid:0] read (148153116,131072,28668010496,19235): OK (131072) <1.309992>
2022.09.22 08:55:21.577944 [uid:0,gid:0,pid:0] read (148153116,131072,14342746112,19235): OK (131072) <1.385073>
2022.09.22 08:55:22.098133 [uid:0,gid:0,pid:0] read (148153116,131072,35781816320,19235): OK (131072) <1.301371>
2022.09.22 08:55:22.883285 [uid:0,gid:0,pid:0] read (148153116,131072,3570397184,19235): OK (131072) <1.305064>
2022.09.22 08:55:23.362654 [uid:0,gid:0,pid:0] read (148153116,131072,100420673536,19235): OK (131072) <1.264290>
2022.09.22 08:55:24.068733 [uid:0,gid:0,pid:0] read (148153116,131072,48602152960,19235): OK (131072) <1.185206>
2022.09.22 08:55:25.351035 [uid:0,gid:0,pid:0] read (148153116,131072,60529270784,19235): OK (131072) <1.282066>
2022.09.22 08:55:26.631518 [uid:0,gid:0,pid:0] read (148153116,131072,4255297536,19235): OK (131072) <1.280236>
2022.09.22 08:55:27.724882 [uid:0,gid:0,pid:0] read (148153116,131072,715698176,19235): OK (131072) <1.093108>
2022.09.22 08:55:31.049944 [uid:0,gid:0,pid:0] read (148153116,131072,8233349120,19233): OK (131072) <1.020763>
2022.09.22 08:55:32.055613 [uid:0,gid:0,pid:0] read (148153116,131072,119523176448,19233): OK (131072) <1.005430>
2022.09.22 08:55:32.056935 [uid:0,gid:0,pid:0] read (148153116,131072,44287774720,19233): OK (131072) <0.001099>
2022.09.22 08:55:33.045164 [uid:0,gid:0,pid:0] read (148153116,131072,1323794432,19233): OK (131072) <0.988074>
2022.09.22 08:55:36.502687 [uid:0,gid:0,pid:0] read (148153116,131072,47760637952,19235): OK (131072) <1.184290>
2022.09.22 08:55:38.525879 [uid:0,gid:0,pid:0] read (148153116,131072,53434183680,19203): OK (131072) <0.096732>
对着日志观察下来,发现读文件的行为大体上是「频繁随机小读」。我们尤其注意到 offset(也就是 read 的第三个参数)跳跃巨大,说明相邻的读操作之间跨度很大,难以利用到预读提前下载下来的数据(默认的块大小是 4MiB,换算为 4194304 字节的 offset)。也正因此,我们建议将 --prefetch 调整为 0(让预读并发度为 0,也就是禁用该行为),并重新挂载。这样一来,在该场景下的读放大问题得到很好的改善。
通过 juicefs stats 排查
从 5.2 起,可以在 --schema 中加入 a 来额外打印预读相关的详细指标,用来指征「预读的数据未被实际读到」的浪费情况。
$ juicefs stats /jfsno -l 1 --schema="ao"
-------------readahead------------ ------------------------object-----------------------
used winvl wclup wshrk wfree wclos| get get_c lat put put_c lat del del_c lat
0 0 0 0 0 0 | 0 0 0 0 0 0 0 0 0
readahead 板块的每一列都代表一种预读数据被浪费的情况,阅读 juicefs stats 了解他们的具体含义。
写放大
在 JuiceFS 中,写操作本身并不会引起写放大,可以认为是「写多少、上传多少」。这也和 JuiceFS 本身的存储格式有关,如果不熟悉请先回顾相关话题。

如上图所示,写放大主要来源于碎片合并。不同的写模式,带来的碎片程度也有很大区别:
-
在上传带宽足够的前提下,连续的顺序写可以“一气呵成”以最为优化的分块方式上传到对象存储,所以不会产生碎片。
-
如果上传带宽不足,大文件的顺序写也会产生文件碎片。
这是因为 JuiceFS 默认每 5 秒将缓冲区中待写入的数据进行持久化,在带宽不足的情况下,写入速度也会变慢,然后频繁的
fsync在对象存储中形成大量连续的、不足一个数据块大小(默认 4M)的文件,也就是文件碎片。JuiceFS 为了优化这部分数据的读取效率,会对其进行碎片合并。碎片合并需要将这些小数据块合并、重新写入对象存储,其占用的带宽又会进一步加剧写放大的问题。
-
如果是高频小追加写(每一次追加都伴随着
fsync,需要上传对象存储)或者随机写,那么不可避免会产生大量碎片,需要进行碎片合并、导致写放大。
高频小追加写、随机写带来的写放大是不可避免的,这是 JuiceFS 为了读写性能所做的取舍。但是在低速顺序写场景下的碎片合并问题,我们可以用下方步骤进行甄别和优化:
- 进行大文件顺序写入时,期望不产生任何碎片,打开文件系统的监控页面,查看对象存储流量面板
- 如果发现碎片合并的流量太大,但是则可能是遇到了写入慢的碎片问题
- 定位到负责写入的 JuiceFS 客户端,调整挂载参数
--flush-wait=60,将默认 5 秒一次的持久化改为 60 秒,理应能够减少碎片量
分布式缓存、独立缓存集群相关问题
阅读「分布式缓存」。
资源占用过高
如果 JuiceFS 客户端的资源占用过高,我们建议通过调整挂载选项的方式主动降低资源占用,而不是为其设置资源边界,比方说:
- 用 systemd.service 来运行 JuiceFS 客户端
- 用容器来运行 JuiceFS 客户端(例如通过 JuiceFS CSI 驱动,不过 CSI 驱动则是另一个话题了,参考「CSI 驱动资源优化」)
JuiceFS 文件系统作为基础设施,强行限制其资源占用,可能会导致使用体验受影响:
- 设置 CPU 上限,则 JuiceFS 客户端进程的 CPU 用量可能受到限制(throttle),造成文件系统访问极慢甚至卡死
- 设置内存上限,则 JuiceFS 客户端可能因为 OOM(Out of Memory)而被强制退出,进而造成挂载点丢失。即便能自动重启恢复,应用也不一定能妥善处理这种情况,比如在
hostPath模式下使用 JuiceFS,如果 JuiceFS 客户端重启,则需要重启应用容器,才能恢复容器内的挂载点 - 设置网络带宽上限,则 JuiceFS 客户端下载对象存储数据时可能太慢导致超时,引发 I/O 错误,这点在「与对象存储通信不畅」中有详细介绍
因此如果资源占用过高,参考本节的优化手段,降低 JuiceFS 客户端资源占用。同时也要注意,资源优化势必不是免费的,也会影响性能,但相比设置资源上限,往往能获得更平稳的使用体验。
JuiceFS 客户端需要占用多少资源,不能一概而论,不同的资源占用对应不同的性能级别,按照「资源占用 vs 性能」的不同偏好选择,大致分成以下情况讨论。
JuiceFS 客户端是为高性能场景打造的,不推荐将其用于资源极其受限的环境。下方的运行示范仅仅作为参考,无法保证资源占用一定低于你的理想阈值。
如果你必须在严格的低资源场景下使用网络文件系统,推荐使用 NFS 或其他替代方案。
优先节约资源
如果不在乎性能差,但资源用量越低越好,那么可以配合下方参数尽可能降低客户端资源占用。
juicefs mount myjfs /jfs \
--cache-size=0 \
--buffer-size=32 \
--max-cached-inodes=10000 \
--max-uploads=5 \
--max-downloads=5
上方的参数含义如下:
--cache-size=0禁用本地缓存(常常搭配分布式缓存一起使用),也就是完全不占用磁盘空间。如果禁用了本地缓存,那么客户端会额外尝试分配 100MB 的内存空间用作缓存。因此如果希望避免这部分内存开销,可以使用--cache-size=1024,也就是仅使用低至 1GB 的本地磁盘空间。--buffer-size=32为读写缓冲区分配 32MB 内存,如此低的缓冲区大小会严重限制客户端的性能。同时注意,读写缓冲区仅仅是 JuiceFS 客户端的一部分开销,还有许多其他的内存占用,比方说元数据缓存。--max-uploads=5和--max-downloads=5手动限制客户端和对象存储的 I/O 并发。事实上,缓冲区的大小也会间接控制并发度,上方的例子中给予的 32MB 缓冲区,已经能够降低客户端的并发度,但此处为作为极端情况的示范,手动将并发限制为 5,让客户端在不用满缓冲区的前提下尽量提高并发。--max-cached-inodes=10000大大降低客户端允许缓存的 inodes 数量。这个参数的默认值是五百万,作用是缓存文件(目录)元数据,在资源极其有限不在乎使用体验的情况下,这部分也可以舍弃。
平衡性能和资源占用
如果希望性能和资源占用有较好的平衡,追求「性价比」。那么这是 JuiceFS 客户端最为广泛的运行场景,也是调优空间最大的情况,因此恕我们难以给出一个必定适合你场景的示范,而是只能列出一些关键的性能调优参数:
- 将
--buffer-size设置为 500 至 1024,也就是 500MB 至 1GB 的缓冲区大小,能够为绝大部分真实场景提供充足的性能空间。你可以用juicefs stats核实客户端的实际用量,并根据实际情况继续调优。经验上,一个在正常的资源区间(比如说 500MB~1GB 的缓冲区大小)运行的客户端,在高负载的情况下,内存占用大致是缓冲区的 4 倍。 --cache-size和--free-space-ratio根据实际环境进行调整。--max-uploads的默认值是 20,对于顺序写场景一般不需要继续调高,因为按照默认的 4M 分块大小,20 的并发已经能提供非常高的总写入带宽,继续增大容易让客户端资源占用过高,或者在大量客户端的高并发场景下,给对象存储服务带来过大压力。因此通常只有面对高频随机写的时候,才需要增大--max-uploads。--max-downloads的默认值是 200,一般不需要调整,原因类似--max-uploads。- 如果需要主动限制吞吐,或者降低 CPU 用量,可以降低
--upload-limit和--download-limit,限制上传、下载速度(默认无限制)。 - JuiceFS 挂载客户端是一个 Go 程序,因此也可以通过降低
GOGC(默认 100)来令 Go 在运行时执行更为激进的垃圾回收(将带来更多 CPU 消耗,甚至直接影响性能)。详见「Go Runtime」。 - 私有部署 如果你使用自建的 Ceph RADOS 作为 JuiceFS 的数据存储,可以考虑将 glibc 替换为 TCMalloc,后者有着更高效的内存管理实现,能在该场景下有效降低堆外内存占用。
可以看到,不论是资源有限,还是资源相对富裕的情况,最重要的调优参数都是 --buffer-size。如果缓冲区很小,并发度和吞吐都会随之降低,因此通常不需要再继续调整 max-uploads|upload-limit|max-downloads|download-limit。
卸载错误
卸载 JuiceFS 文件系统时,如果某个文件或者目录正在被使用,那么卸载将会报错(下方假设挂载点为 /jfs):
# Linux
umount: /jfs: target is busy.
(In some cases useful info about processes that use
the device is found by lsof(8) or fuser(1))
# macOS
Resource busy -- try 'diskutil unmount'
# 在 Kubernetes 集群中,卸载失败表现为 Mount Pod 无法删除,卡死在 Terminating 状态
# 此时 kubelet 会产生如下错误日志
Failed to remove cgroup (will retry)" error="rmdir /sys/fs/cgroup/blkio/kubepods/burstable/podxxx/xxx: device or resource busy
如果并不关心已经打开的文件,只想要尽快卸载,也可以运行 juicefs umount --force 来强制卸载,不过注意,强制卸载在 Linux、macOS 上的行为并不一致:
-
对 Linux 而言,
juicefs umount --force意味着umount --lazy,文件系统会被卸载,但已打开的文件不会关闭,而是等进程退出后再退出 FUSE 客户端。因此用这种方式卸载后,宿主机上可能仍有 JuiceFS 客户端残留,如果希望强制退出,可以使用以下命令找出所有客户端进程并强行终止:ps -ef | grep -P '(/juicefs |juicefs -mountpoint|mount.juicefs|jfsmount)' | grep -v grep | awk '{print $2}' | xargs kill -9 -
对 macOS 而言,
juicefs umount --force意味着umount -f,文件系统会被强制卸载,已打开的文件会强制关闭。相同的功能也可以用diskutil umount force实现。
如果需要排查出到底是哪些应用还在访问 JuiceFS,导致无法卸载,那么可以用类似 lsof /jfs 的命令,找出该文件系统下正在使用的文件,然后按需处置对应的进程(比如强制退出),然后再次尝试卸载。
如果以上手段均不起作用,用类似 ps -eo pid,ppid,stat,command | grep ' D ' 的命令检查是否存在与 JuiceFS 相关的 D 状态(Uninterruptible Sleep)进程(比如正在访问 JuiceFS 挂载点的进程)。如果存在,需要用下方的步骤强行关闭 FUSE 连接:
# 本机只有一个 FUSE 挂载点的话,那么 /sys/fs/fuse/connections 下也只会包含一个目录,不会错杀
echo 1 > /sys/fs/fuse/connections/[device-number]/abort
# 如果存在多个挂载点,可以用下方手段检查卡死的 FUSE 请求数,来判断问题挂载点究竟对应哪一个 connection
tail -n +1 /sys/fs/fuse/connections/*/waiting
# 从上方的输出中找到 waiting 大于 0 的连接,将其 abort
echo 1 > /sys/fs/fuse/connections/[device-number]/abort
# 如果多个挂载点的 waiting 数量均大于 0,可以持续观察
# 如果观察到持续大于 0 的 FUSE 连接,则认为卡死,用类似上方的步骤进行 abort
watch -n 3 'tail -n +1 /sys/fs/fuse/connections/*/waiting'
关闭 FUSE 连接后,对应的挂载点就解除了卡死状态,再次尝试卸载、重新挂载。
透明大页内存碎片合并引发系统卡死
在生产环境中,内存较大的节点往往运行着各类复杂业务,负载较高。长时间运行后可能产生内存碎片化,导致应用程序申请透明大页(THP)的时候,系统长时间卡顿、进行碎片整理,可能严重影响应用程序性能。JuiceFS 也受到该问题影响,可能产生如下异常:
-
难以解释的网络卡顿、超时,不光是连接元数据服务会不断超时重试,对象存储的访问也会变慢,类似日志如下:
# 元数据网络异常
read header: read tcp 10.75.x.x:34258->10.74.x.x:9445: read: connection reset by peer [client.go:1298]
reconnect meta: read tcp 10.75.x.x:45444->10.74.x.x:9445: read: connection reset by peer, len=0 [client.go:975]
connect 10.74.x.x:9445: dial tcp 10.74.x.x:9445: connect: connection refused [client.go:453]
connected to meta 10.74.x.x:9445 after 211.232484ms [client.go:916]
read header: EOF [client.go:1298]
can't find request for packet 605226 (cmd: 429, size: 63733) [client.go:1328]
request 428 (604439) is timeout after 16m0.579282038s, restart it [client.go:667]
# 对象存储网络异常
slow request: GET chunks/0D/15/xxxxxxxx_4_4194304 RANGE(0,-1) (req_id: "", err: <nil>, cost: 3m40.315940825s) [cached_store.go:260]
fail to read chunkid xxxxxxxx (off:16777216, size:4194304, clen: 67108864): timeout after 1m0s: function timeout [data.go:469]
readworker: unexpected data block size (requested: 4194304 / received: 0) [readdata.go:319]
upload chunks/04/2481/xxxxxxxxxx_0_xxxxx: Put "http://xx.aliyuncs.com/ali%2Fchunks%2F04%2F2481%2Fxxxxxxxxxx_0_xxxxx": read tcp x.x.x.x:60184->x.x.x.x:80: read: connection reset by peer (try 1) [cached_store.go:674] -
挂载点卡死、无法提供服务,无法运行
df -h,ls等命令,甚至大量系统常见命令也会卡死,比如lsof或者ps。 -
大量 FUSE 请求阻塞,可以用上一小节中
tail -n +1 /sys/fs/fuse/connections/*/waiting命令来查看卡死请求数量。
从现象来看,内存碎片整理引发的卡死很容易被误认为是更底层的网络故障,排查和解决都很复杂,因此我们建议,当挂载点出现以上罗列的情况时,先不继续深入排查,而是直接先进行 THP 相关的系统参数调优:
# 调整内存回收的水位线,将 min_free_kbytes 设置为总内存 1% 左右
# 比如 1TB 内存机型可以设置 10G,让系统提前进行内存整理
sysctl -w vm.min_free_kbytes=10485760
# 调整 THP 策略,当系统分配不出透明大页时,转为分配普通的 4KB 页
# 同时唤醒后台进程以进行内存的后台回收,避免阻塞上层业务进程
echo defer > /sys/kernel/mm/transparent_hugepage/defrag
从 JuiceFS 5.2 开始,客户端挂载时会自动调整碎片合并为 defer 策略(也就是上述代码块第二条命令),来规避卡死的问题。但是仍需注意,Kubernetes 场景下,Mount Pod 无法直接修改宿主机系统参数,需要在你的集群配置 中启用 tuneTransparentHugePage 来在安装阶段通过初始化容器进行该项调优。
更多相关知识可以阅读站外文档:


