用 JuiceFS 备份 NGINX 日志
生产环境中的 NGINX 经常作为反向��代理,配置多台,用来对接后面的各种应用服务。日志主要有两类,访问日志 (access.log) 和错误日志 (error.log)。
日志是分散在每个 NGINX 节点的磁盘上的,每台机器自己的磁盘并不安全,而且分散的日志也难以维护和使用。所以,我们都会将日志汇总在一个更靠谱的存储系统中,一方面长期存储安全可靠,一方面也方便做分析使用。
在日志的存储上需要里,容量扩展性强,稳定安全,方便运维操作,价格便宜,最好按使用量付费是重点,对于存储性能的要求会低一些。目前常用的有 NFS、HDFS、对象存储等,把这些存储与 JuiceFS 做个比较:
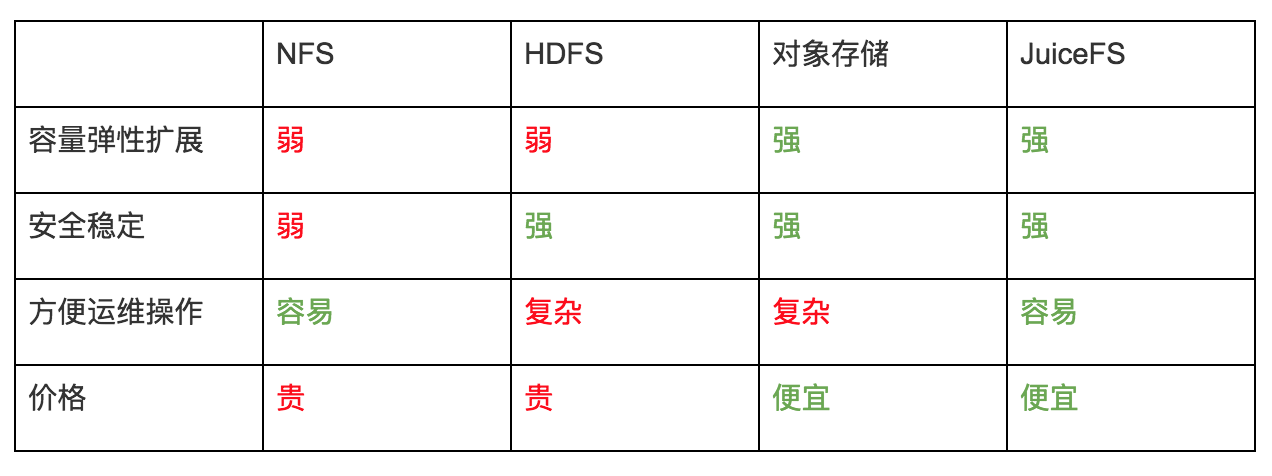
说到日志的收集方式,主要有两种:定时收集 和 实时收集,我们在下面分别说明。JuiceFS 使用客户自己的对象存储保存文件数据,所以也自然继承了对象存储的好处,在此之上,我们提供了高性能的元数据服务和完整的 POSIX 兼容,使用上又比对象存储便利的多。
定时收集
以 logrotate 为例,定时将 NGINX 日志拷贝到 JuiceFS,可以在每台机器上这样修改 /etc/logrotate.d/nginx:
# 假定 JuiceFS 挂载到 `/jfs`
/var/log/nginx/*.log {
daily # 每天滚动一次
compress
dateext # 把日期添加到文件名中
sharedscripts
postrotate
[ -f /var/run/nginx.pid ] && kill -USR1 `cat /var/run/nginx.pid` # 重新加载日志文件
endscript
lastaction
rsync -au /your/nginx-log/path/*.gz /jfs/nginx-logs/`hostname -s`/ # 把压缩好的日志同步到 JuiceFS
endscript
}
到此,NGINX 日志就可以每天 rotate 并保存到 JuiceFS 中了。增加 NGINX 节点时,只需要在新增节点上做同样的配置即可。
如果使用 NFS,在 logrotate 中的配置是基本一样的。但是 NFS 有几个不足之处:
- 大部分 NFS 存在单点故障,而 JuiceFS 是高可用的(专业版承诺 99.95% SLA)。
- NFS 协议传输不加密,所以你需要保证 NFS 和 NGINX 在同一个 VPC 中,如果还有其他要备份的服务,部署上就很麻烦。JuiceFS 传输有 SSL 加密,不受 VPC 限制。
- NFS 需要事先容量规划,JuiceFS 是弹性扩容,按容量付费的,更省心,更便宜。
- 如果使用 HDFS 或者对象存储,日后访问备份数据时,就比较麻烦。JuiceFS 就简单很多,比如可以直接用 zgrep 查询。
再分享几个 Tips:
- 执行
logrotate -f /etc/logrotate.d/nginx立即执行对 logrotate 配置做个验证。还可以用 -d 做调试。 - Logrotate 基于 cron 运行,无论你设置 weekly、daily 还是 hourly,具体的执行时间可以在 /etc/crontab 中修改。
- 如果你觉得日志文件太多,我们还提供了
juicefs merge命令可以快速合并 gzip 压缩过的日志文件。
说完定时汇总,下一节我们再说说日志实时收集。
实时收集
日志的实时收集已经有了很多开源工具,常用的有 Logstash、Flume、Scribe、Kafka 等。
在集群不是很大的时候,日志收集、分析、索引、展示有个全家桶方案 ELK,其中用 Logstash 做日志收集和分析。
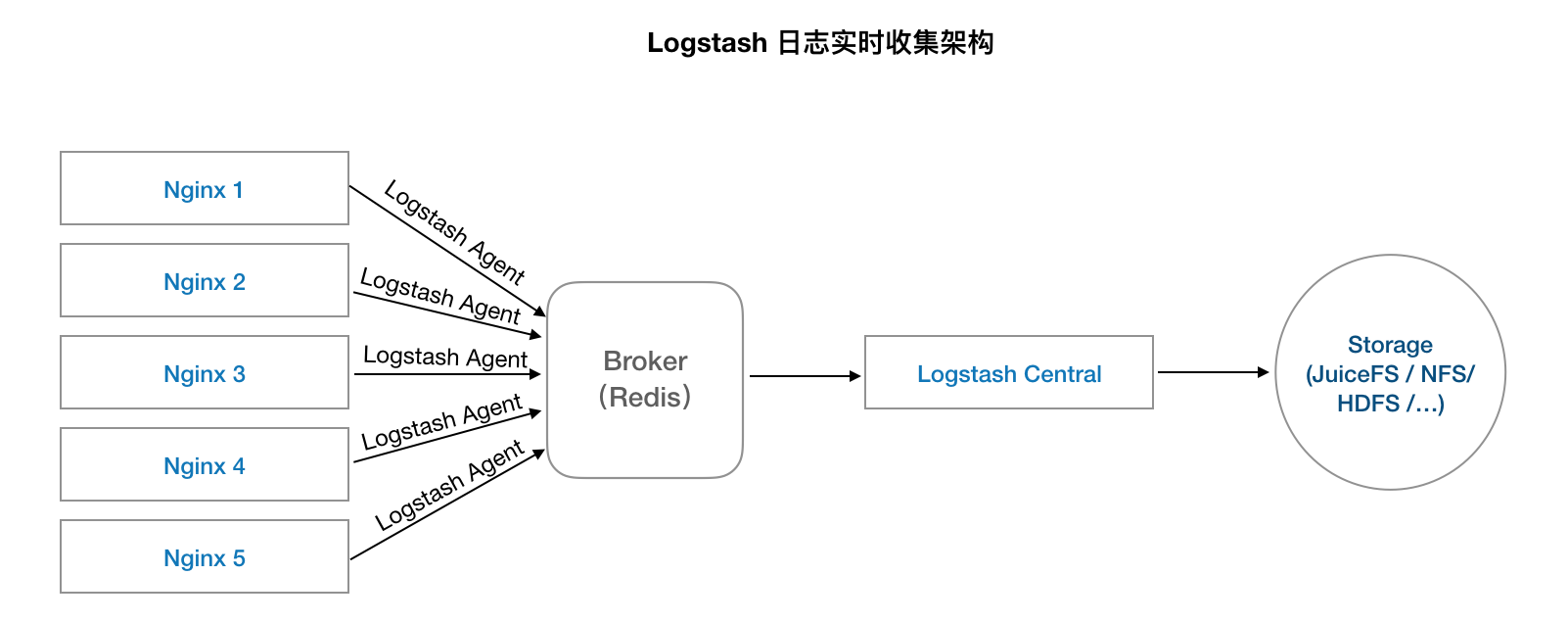
需要下面的部署方式:
- 在每台机器上部署一个 Logstash Agent(Flume 等其他工具同理);
- 部署一个 Logstash Central 做日志汇总;
- 部署一个 Redis 做整个服务的 Broker,目的是在日志收集和写入中间做个缓冲,避免 Central 挂了导致日志丢失;
- 然后再配置 Central 的落盘方式,将日志存储到 JuiceFS / NFS / 对象存储 / HDFS 等。
先看看架构图:
这里不讲 Logstash 在收集、分析、过滤环节的配置了,网络上有很多文章可查(比如:Logstash 最佳实践),说一下输出环节。
把 Logstash 收集处理好的日志保存到 JuiceFS 只要在配置的 output 部分设置一下:
output {
file {
path => "/jfs/nginx-logs/%{host}-%{+yyyy/MM/dd/HH}.log.gz"
message_format => "%{message}"
gzip => true
}
}
存储到 NFS 也可以用上面的配置,缺点和上文定时收集部分提到的相同。
如果要保存到对象存储、HDFS,需要再配置 Logstash 的第三方插件,大部分是非官方的,随着 Logstash 版本的升级,使用时可能需要折腾一下。
最简单的实时收集方案
其实还有更简单的实时日志收集方法,就是直接让 NGINX 把日志输出到 JuiceFS 中,省去了维护和部署日志收集系统的麻烦。使用这个方案可能会担心 JuiceFS 出问题时影响 NGINX 的正常运行,有两方面可以帮大家减少一些顾虑:
- JuiceFS 本身是一个高可用的服务,专业版承诺 99.95% 的可用性,应该跟你的数据库等服务在一个可用性级别;
- NGINX 的日志输出是使用异步 I/O 来实现的,即使 JuiceFS 出现暂时性的抖动,也基本不影响 NGINX 的正常运行(restart 或 reload 可能会受影响)。
如果不喜欢运维复杂的日志收集系统,这个方案值得一试。
给 NGINX 日志加一份异地备份
定时收集和实时收集都讲完了,在 super-backup 中存储的 NGINX 日志如何做个 异地备份 呢?
只要两步:
一、去 JuiceFS 网站控制台中,访问你文件系统的设置菜单,勾选 "启动复制",然后选择你要复制到的对象存储,保存。
二、在所有挂载 super-backup 的机器上重新挂载 super-backup 即可。之后新写入的数据会很快同步到要复制的 Bucket 中,旧的数据也会在客户端定时扫描(默认每周一次)时同步。
这样可以全自动的在另外一个对象存储中同步一份数据,有效防止单一对象存储的故障或者所在区域的灾难。


