JuiceFS 性能数据参考
基准性能
顺序读
规格:48c|192G|36Gbps
软件系统:Ubuntu 22.04,FIO:3.7,JuiceFS 5.2
fio --name=seqread_bigfile --filename=/jfs/bigfile-10G --rw=read --bs=1M --size=10G --iodepth=1 --numjobs={thread_num} --group_reporting --direct=1 --time_based --runtime=120
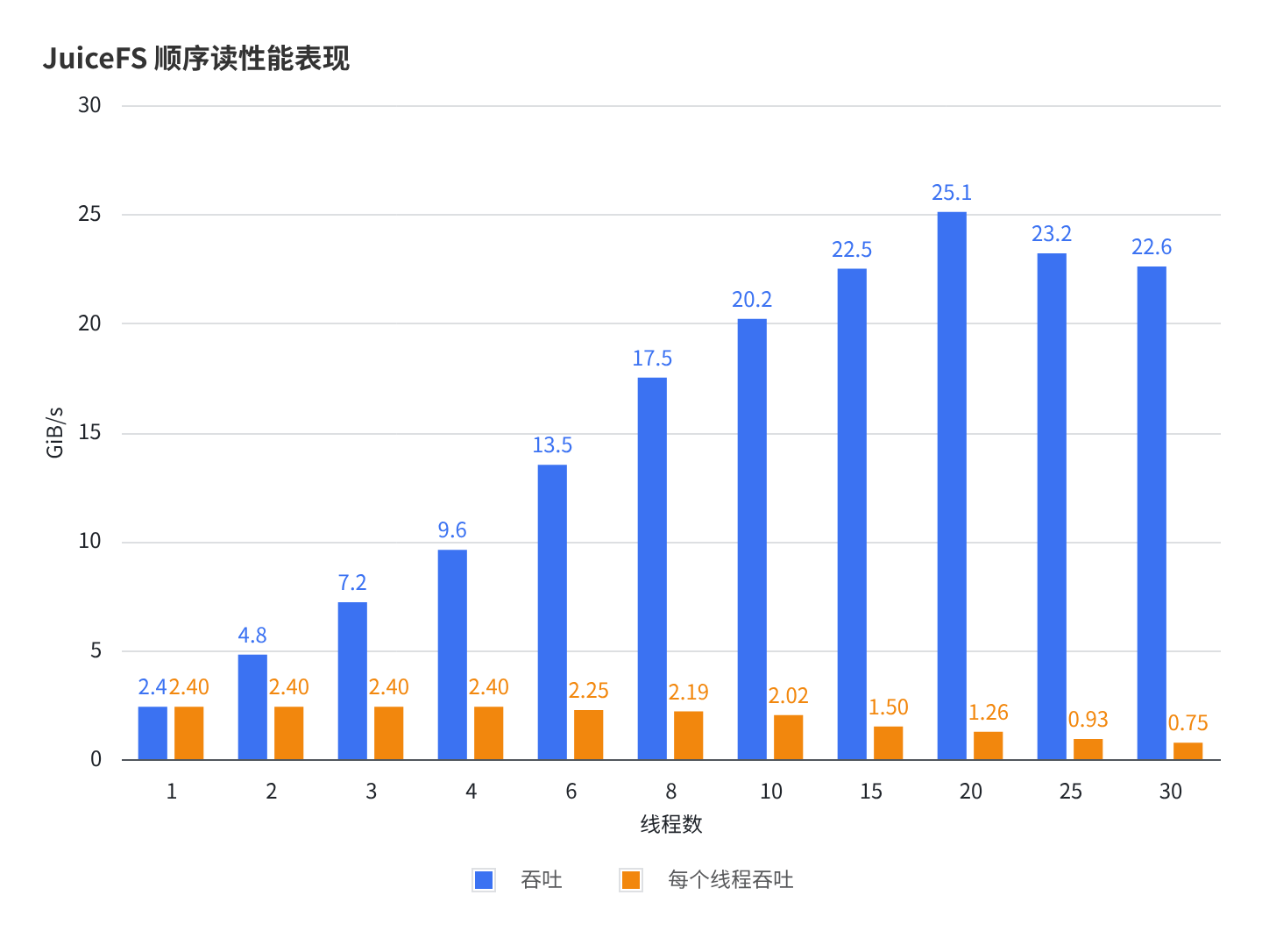
- JuiceFS 单线程带宽可以达到 2.4 GiB/s
- 随着线程的增加,带宽可以实现近线性增长,在 20 线程时达到了顶峰 25.1 GiB/s
- 缓存采用本地内存以规避磁盘吞吐瓶颈影响极值吞吐
- CPU 消耗在每 GB/s - 1~1.5 核左右,到达 25GiB/s 大概在 30~40 核之间波动。
随机读
JuiceFS 测试规格:32c|64G|40Gbps
软件系统:Ubuntu22.04,FIO:3.7,JuiceFS 5.4
GPFS 对比测试规格:96c|384G|400Gbps * 2 RoCE,I/O 节点上执行,全闪盘。
单进程
fio --name=jfs-randread --filename=/{mnt}/readfile --rw=randread --bs=4k --size=10g --time_based --runtime=20s --time_based --ramp_time=2s --verify=0 --group_reporting=1 --ioengine=libaio --direct=1 --numjobs=1 --iodepth={x}
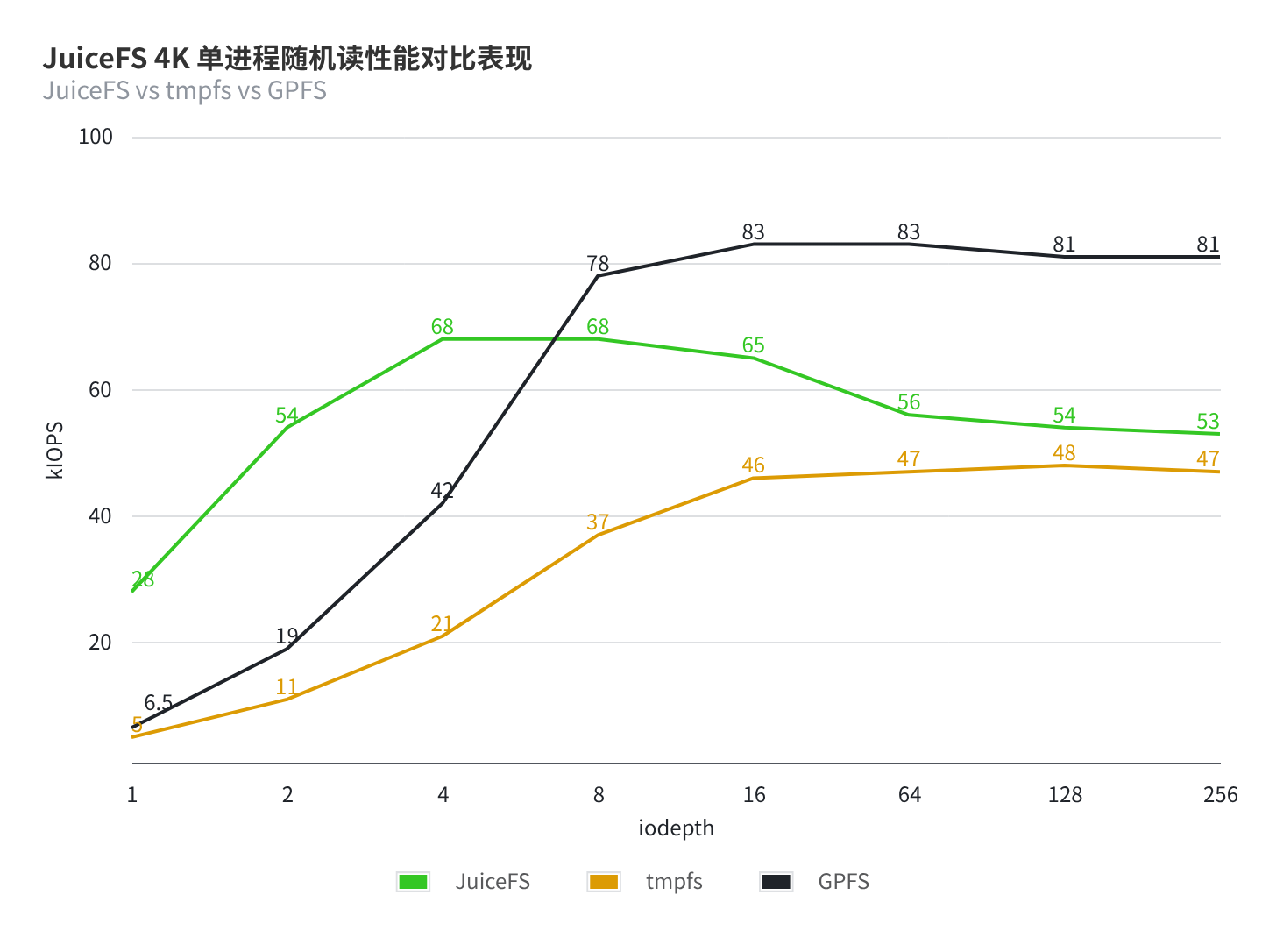
- 单并发情况下 JuiceFS 在
iodepth=8时达到最大为 68K IOPS,iodepth=16开始衰减并在iodepth=64逐渐企稳 - GPFS 在
iodepth=16表现最佳为 83K IOPS - tmpfs 的底层为云盘,采用本地 NVMe 的话性能会更好,此处仅为使用一个本地文件系统作为分布式/并行文件系统的随机读的对比参考
多进程(iodepth 固定为 8)
fio --name=jfs-randread --filename=/{mnt}/readfile --rw=randread --bs=4k --size=10g --time_based --runtime=20s --time_based --ramp_time=2s --verify=0 --group_reporting=1 --ioengine=libaio --direct=1 --iodepth=8 --numjobs={x}
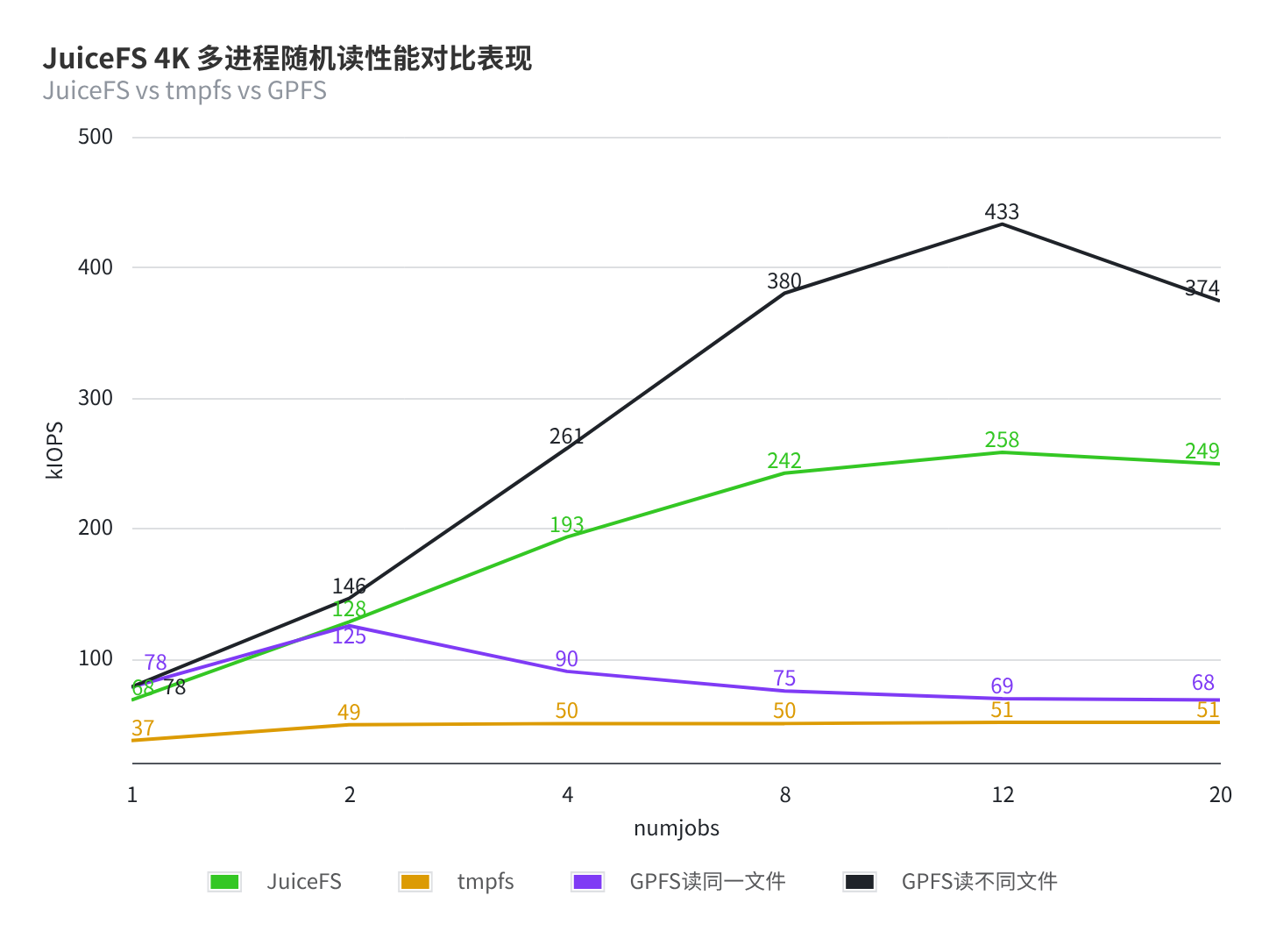
- 多进程随机读单一文件时 JuiceFS 表现优异,在 12 并发时出现瓶颈,最高 258K IOPS,延迟始终在 0.4ms 左右
- GPFS 多进程读单一文件因锁竞争消耗多,在 2 进程以上开始出现明显衰减。所以加测一种方式,为每个 FIO 读不同的文件以规避锁竞争及元数据 token 争抢问题。JuiceFS 在这两种方式下性能表现一致所以无需调整。
- tmpfs 应是达到了云盘的吞吐上限(200MB/s),一直在 50K IOPS 徘徊
顺序写
规格:48c|192G|36Gbps,5 台。
软件系统:Centos7.9,FIO:3.7,JuiceFS 5.2
对象存储最大写带宽 200Gbps
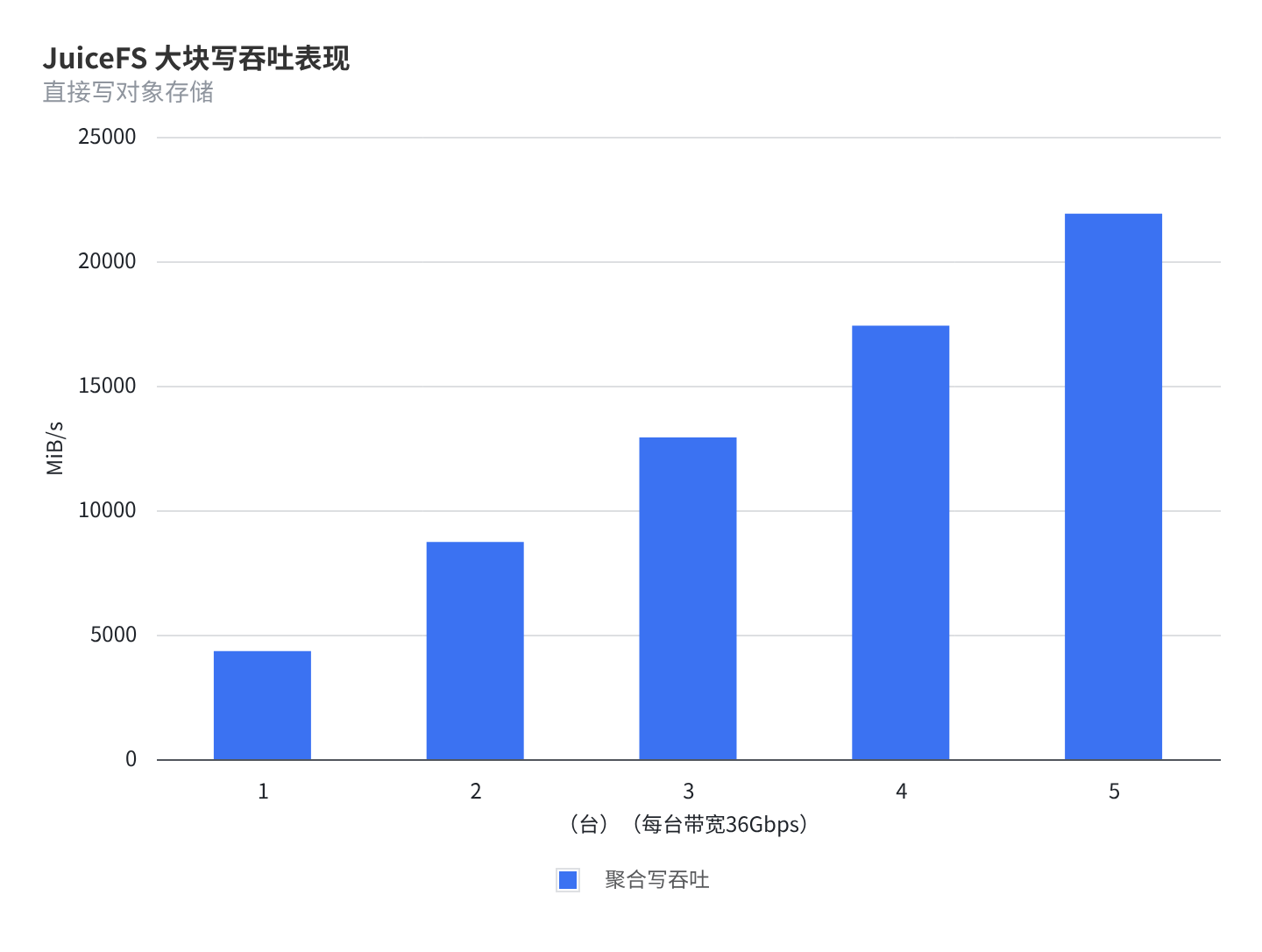
- JuiceFS 直接写对象存储,依赖对象存储提供带宽,多并发情况下可以轻松打满网络带宽
- 多机情况下聚合吞吐呈线性增长,5 台节点聚合到 21.4GiB/s 的写带宽
随机写
规格:64c|128G|40Gbps。
软件系统:Ubuntu 22.04,JuiceFS 5.2
GPFS 测试规格:96c|384G|400Gbps * 2 RoCE,I/O 节点上执行,全闪盘。
为规避多进程随机写同一文件的竞争锁问题,每个 FIO 进程都写自己单独的文件
fio --name=randwrite --directory=/{mnt} --filename_format=file.\$jobnum --size=512M --bs=4k --rw=randwrite --iodepth=1 --ioengine=libaio --direct=1 --time_based --runtime=20 --group_reporting --numjobs={x}
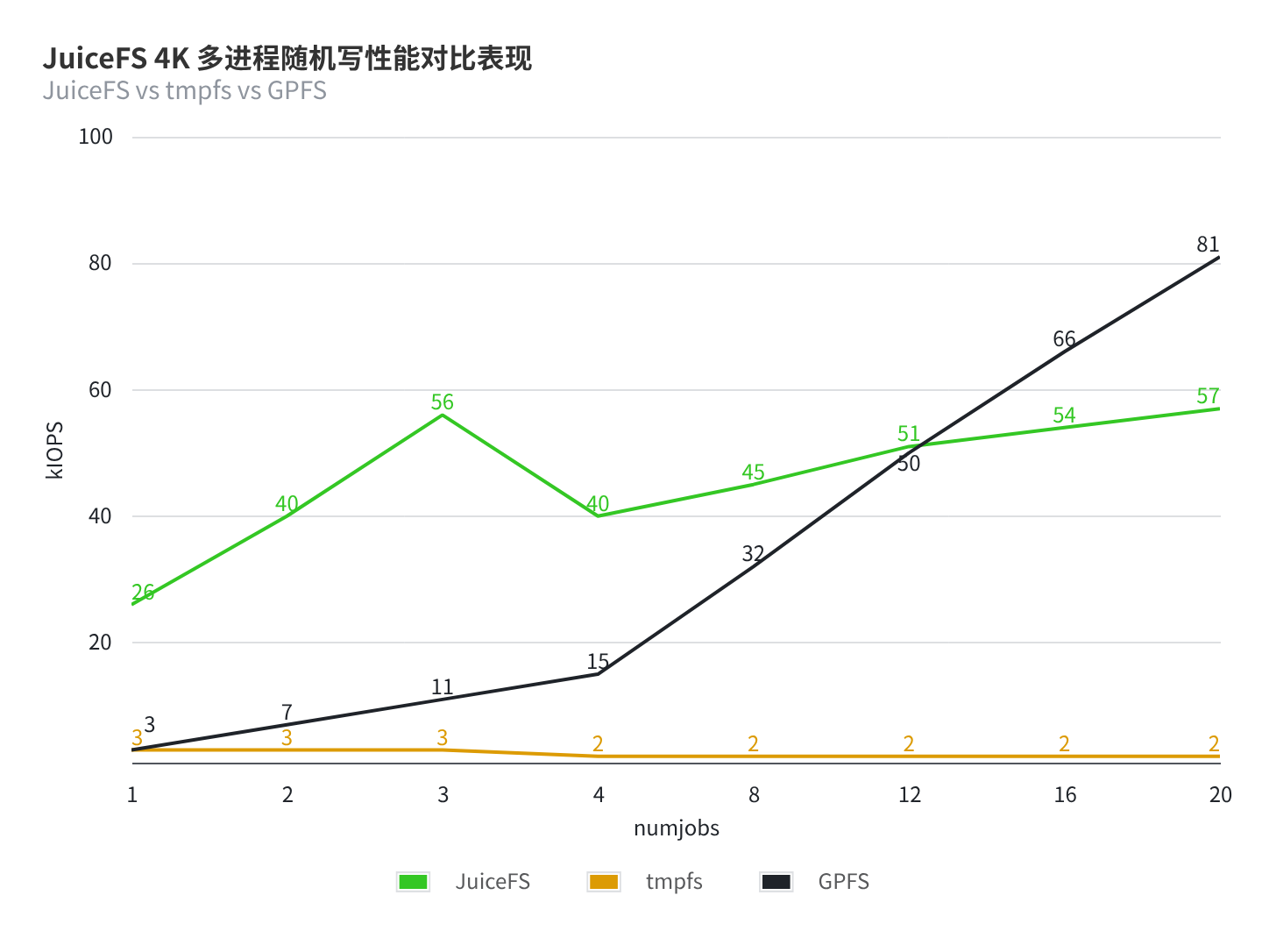
- JuiceFS 最高在 57K 的 4K 随机写性能
- JuiceFS 采用
writeback挂载,并且cache-dir设置为本地的 nvme 盘路径 - GPFS 在单并发时性能不高,但可以做到线性扩容,在 12 并发时追平并超过 JuiceFS
- JuiceFS 在随机写之后还会占用一定的时间和带宽资源做对象存储上的碎片整理
元数据基准性能
JuiceFS 企业版采用自研元数据引擎,基于 Raft 的纯内存无锁实现方案,利用多个分区提供极低请求延迟的同时可以做到容量的线性扩容,性能的近线性扩容。
服务节点规格:30c|120G|25Gbps
软件系统:Ubuntu 22.04,JuiceFS 5.3 元数据服务
| Operation | QPS (k/s) |
|---|---|
| getattr | 90 |
| lookup | 18.4 |
| setattr | 29 |
| mkdir | 60 |
| readdir | 3.7 |
| create | 54 |
| write | 48 |
| read | 182 |
| rename | 40 |
| hardlink | 37.5 |
- JuiceFS 企业版默认是单个 Raft 分区提供服务,以上是单分区的元数据性能
- 多台元数据节点可以混部多个分区,性能呈近线性增长(除了 readdir 和 lookup 之外)


