数据同步
juicefs sync 是强大的数据同步工具,可以在所有支持的存储之间并发同步或迁移数据,包括对象存储、JuiceFS、本地文件系统,你可以在这三者之间以任意方向和搭配进行数据同步。除此之外,还支持同步通过 SSH 访问远程目录、HDFS、WebDAV 等,同时提供增量同步、模式匹配(类似 rsync)、分布式同步等高级功能。
juicefs sync 功能的代码在社区版和企业版之间共享代码,因此即便交叉混用不同版本的 JuiceFS 客户端,sync 命令也能正常工作——除了一个特例,就是使用 jfs:// 协议头的情况。社区版和企业版客户端有着不同的元数据引擎实现,因此如果用到了 jfs:// 协议头,则不能混用不同版本的客户端。
juicefs sync 用法如下:
juicefs sync [command options] SRC DST
# 从 OSS 同步到 S3
juicefs sync oss://ACCESS_KEY:[email protected] s3://mybucket.s3.us-east-2.amazonaws.com
# 从 S3 直接同步到 JuiceFS
juicefs sync s3://mybucket.s3.us-east-2.amazonaws.com/ jfs://VOL_NAME/
# 拷贝所有以 .gz 结尾的文件
juicefs sync --match-full-path --include='**.gz' --exclude='*' s3://xxx jfs://VOL_NAME/
# 拷贝不以 .gz 结尾的所有文件
juicefs sync --match-full-path --exclude='**.gz' s3://xxx/ jfs://VOL_NAME/
# 拷贝所有文件,但忽略名为 tmpdir 的子目录
juicefs sync --match-full-path --exclude='**/tmpdir/**' s3://xxx/ jfs://VOL_NAME/
# 将 s3 的 /a 目录拷贝到 JuiceFS 文件系统,但是忽略 /a/b 目录下的内容
juicefs sync --match-full-path --exclude='b/**' s3://a/ jfs://VOL_NAME/a/
模式匹配
你可以通过 --exclude 和 --include 来包含或排除要同步的文件路径。如果不提供任何规则,默认会同步所有扫描到的文件(默认就是 --include='*')。但如果需要使用 --include 实现只包含特定命名模式的文件,则必须同时使用 --exclude 来排除其他文件,具体请参考上方的示范命令。
当提供多个匹配模式时,取决于你具体使用的「过滤模式」,对于判断是否要同步某个文件可能会变得很困难。此时建议加上 --dry --debug 选项提前查看要同步的具体文件是否符合预期,如果不符合预期则需要调整匹配模式。
匹配规则
在 --exclude,--include 过滤器中传入的路径,会和 SRC 中的路径进行拼接,比方说如果需要将 S3 桶的 /a 目录拷贝到 JuiceFS 文件系统,但是忽略 /a/b 目录下的内容,正确的写法是:
juicefs sync --match-full-path --exclude='b/**' s3://a/ jfs://VOL_NAME/a/
而不是:
juicefs sync --match-full-path --exclude='/a/b/**' s3://a/ jfs://VOL_NAME/a/
由于 SRC 中已经包含 /a/ 路径,过滤器中不能再重复 /a,否则将造成过滤不起作用。
过滤器中可以自由填写任意单词,可以使用下方特殊字符来实现更强大的模式匹配,类似 shell 通配符。
- 单个
*匹配任意字符,但在遇到/时终止匹配; **匹配任意字符,包括/;?匹配任意非/的单个字符;[...]匹配一组字符,例如[a-z]匹配任意小写字母;[^...]不匹配一组字符,例如[^abc]匹配除a、b、c外的任意字符。
此外,还有一些匹配规则需要注意:
- 如果匹配模式中不包含特殊字符,将会完整匹配路径中的文件名。比如
foo可以匹配foo和xx/foo,但不匹配foo1(无法前缀匹配)、2foo(无法后缀匹配)和foo/xx(foo不是目录); - 如果匹配模式以
/结尾,将只匹配目录,而不匹配普通文件; - 以
/开头表示匹配绝对路径,因此/foo会直接匹配根目录下的foo文件。
以下是一些匹配模式的例子:
--exclude='*.o'将排除所有文件名能匹配*.o的文件;--exclude='/foo/*/bar'将排除/foo向下「两层」的目录中名为bar的文件,也就是说/foo/spam/bar会被排除而/foo/spam/eggs/bar不受影响;--exclude='/foo/**/bar'将排除/foo向下「任意层级」的目录中名为bar的文件。
sync 命令支持「完整路径过滤」和「逐层过滤」两种模式,这两种模式都支持使用 --include 和 --exclude 来过滤文件,但是解析的行为并不一样:默认情况下,sync 命令使用逐层过滤模式,这种模式的过滤行为无�论是理解还是使用都较为复杂,但是基本兼容 rsync 的 --include/--exclude 选项,所以只推荐已经习惯了 rsync 过滤行为的用户使用。对于大多数 JuiceFS 用户,推荐通过 --match-full-path 选项来使用完整路径过滤模式,他的工作流程更容易理解。
完整路径过滤模式(推荐)
从 5.0.18 开始,JuiceFS 企业版支持 --match-full-path 选项。完整路径过滤模式是指对于待匹配的对象,直接将其「全路径」与多个模式依次进行匹配,一旦某个匹配模式匹配成功将会直接返回结果(「同步」或者「排除」),忽略后续的匹配模式。
下面是完整路径过滤模式的工作流程图:

例如有一个路径为 a1/b1/c1.txt 的文件,以及 3 个匹配模式 --include 'a*.txt' --inlude 'c1.txt' --exclude 'c*.txt'。在完整路径过滤模式下,会直接将 a1/b1/c1.txt 这个字符串与匹配模式依次进行匹配。具体步骤为:
- 尝试将
a1/b1/c1.txt与--include 'a*.txt'匹配,结果是不匹配。因为*不能匹配/字符,参见「匹配规则」; - 尝试将
a1/b1/c1.txt与--inlude 'c1.txt'匹配,此时根据匹配规则将会匹配成功。后续的--exclude 'c*.txt'虽然根据匹配规则也能匹配上,但是根据完整路径过滤模式的逻辑,一旦匹配上某个模式,后续的模式将不再尝试匹配。所以最终的匹配结果是「同步」。
以下是更多示例:
--exclude '/foo**'将排除所有根目录名开头为foo的对象;--exclude '**foo/**'将排除所有以foo结尾的目录;--include '*/' --include '*.c' --exclude '*'将只包含所有目录和后缀名为.c的文件,除此之外的所有文件和目录都会被排除;--include 'foo/bar.c' --exclude '*'将只包含foo目录和foo/bar.c文件。
逐层过滤模式
逐层过滤模式的核心是先将完整路径按照目录层级拆分,并逐层组合成多个字符串序列。比如完整路径为 a1/b1/c1.txt,组成的序列就是 a1、a1/b1、a1/b1/c1.txt。然后将这个序列中的每个元素都当成完整路径过滤模式中的路径,依次执行「完整路径过滤」。
如果某个元素匹配上了某个模式,则会有两种处理逻辑:
- 如果该模式是 exclude 模式,则直接返回「排除」行为,作为最终的匹配结果;
- 如果该模式是 include 模式,则跳过本层级的后续待匹配的模式,直接进入下一层级。
如果某层的所有模式都未匹配,则进入下一层级。如果所有层级匹配完毕后都没有返回「排除」,则返回默认的行为——即「同步」��。
下面是逐层过滤模式的工作流程图:

例如有一个路径为 a1/b1/c1.txt 的文件,以及 3 个匹配模式 --include 'a*.txt' --inlude 'c1.txt' --exclude 'c*.txt'。在逐层过滤模式中,组成的序列就是 a1、a1/b1、a1/b1/c1.txt。具体匹配步骤为:
- 第一层级的路径为
a1,根据匹配模式,结果是全部未匹配。进入下一层级; - 第二层级的路径为
a1/b1,根据匹配模式,结果是全部未匹配。进入下一层级; - 第三层级的路径为
a1/b1/c1.txt,根据匹配模式,将会匹配上--inlude 'c1.txt'模式。该模式的行为是「同步」,进入下一层级; - 由于没有下一层级了,所以最终返回的行为是「同步」。
上面的例子是到最后一层才匹配成功,除此之外可能还有两种情况:
- 在最后一层之前匹配成功,且匹配模式是 exclude 模式,则直接返回「排除」行为作为最终结果,跳过后续的所有层级;
- 所有层级都已经匹配完毕,但都未匹配上,此时也将会返回「同步」行为。
如果你已经熟悉上一小节的“完整路径过滤模式”,那么逐层过滤其实就是按路径层级由高到低依次执行完整路径过滤,每层过滤只有两种结果:要么直接得到「排除」作为最终结果,要么进入下一层级。得到「同步」结果的唯一方式就是执行完所有过滤层级。
以下是更多示例:
-
--exclude /foo将排除所有根目录名为foo的文件或目录; -
--exclude foo/将排除所有名为foo的目录; -
对于
dir_name/.../.../...这种多级目录来说,将按照目录层级匹配dir_name下的所有路径。如果某个文件的父目录被「排除」了,那即使加上了这个文件的 include 规则,也不会同步这个文件。如果想要同步这个文件就必须保证它的「所有父目录」都不要被排除。例如,下面的例子中/some/path/this-file-will-not-be-synced文件将不会被同步,因为它的父目录some已经被规则--exclude '*'所排除:--include '/some/path/this-file-will-not-be-synced' \
--exclude '*'一种解决方式是包含目录层级中的所有目录,也就是使用
--include '*/'规则(需放在--exclude '*'规则的前面);另一种解决方式是为所有父目录增加 include 规则,例如:--include '/some/' \
--include '/some/path/' \
--include '/some/path/this-file-will-be-synced' \
--exclude '*'
存储协议
凡是 JuiceFS 支持的存储系统,都可以使用 sync 命令来同步数据。特别一提,如果其中一端是 JuiceFS 文件系统,那么建议优先使用无挂载点同步方式。
无挂载点同步
在两个存储系统之间同步数据,如果其中一方是 JuiceFS,推荐直接使用 jfs:// 协议头,而不是先挂载 JuiceFS,再访问本地目录。这样便能跳过挂载点,直接读取或写入数据(该过程依然需要读取客户端配置文件,可以使用 juicefs auth 命令提前做好认证、生成配置文件),在大规模场景下,绕过 FUSE 挂载点将能节约资源开销以及提升数据同步性能。当使用 jfs:// 协议头时,可以传入 juicefs mount 的挂载参数来帮助提升传输性能,比如 --max-downloads, --max-uploads, --buffer-size 等。
juicefs sync s3://ABCDEFG:[email protected]/movies/ jfs://myfs/movies/
当使用 jfs:// 协议头时,可以传入 juicefs mount 的挂载参数来帮助提升传输性能,比如 --max-downloads, --max-uploads, --buffer-size 等,比方说在带宽充裕的情况下拷贝大文件,可以启用更大的读写缓冲区来提升性能:
juicefs sync s3://ABCDEFG:[email protected]/movies/ jfs://myfs/movies/ --buffer-size=1024
对象存储与 JuiceFS 之间同步
将对象存储的 movies 目录同步到 JuiceFS 文件系统:
# 挂载 JuiceFS
juicefs mount myjfs /mnt/jfs
# 执行同步
juicefs sync s3://ABCDEFG:[email protected]/movies/ /mnt/jfs/movies/
将 JuiceFS 文件系统的 images 目录同步到对象存储:
# 挂载 JuiceFS
juicefs mount myjfs /mnt/jfs
# 执行同步
juicefs sync /mnt/jfs/images/ s3://ABCDEFG:[email protected]/images/
对象存储与对象存储之间同步
将对象存储的全部数据同步到另一个对象存储桶:
juicefs sync s3://ABCDEFG:[email protected] oss://ABCDEFG:[email protected]
本地及服务器之间同步
对于本地计算机上的目录之间拷贝文件,直接指定数据源与目标端的路径即可,比如将 /media/ 目录同步到 /backup/ 目录:
juicefs sync /media/ /backup/
如果需要在服务器之间同步,可以通过 SFTP/SSH 协议访问目标服务器,例如,将本地的 /media/ 目录同步到另一台服务器的 /backup/ 目录:
juicefs sync /media/ [email protected]:/backup/
# 指定密码(可选)
juicefs sync /media/ "username:password"@192.168.1.100:/backup/
当使用 SFTP/SSH 协议时,如果没有指定密码,执行 sync 任务时会提示输入密码。如果希望显式指定用户名和密码,则需要用半角引号把用户名和密码括起来,用户名和密码之间用半角冒号分隔。
同步行为
增量同步与全量同步
juicefs sync 默认以增量同步方式工作,对于已存在的文件,仅在文件大小不一样时,才再次同步进行覆盖。在此基础上,还可以指定 --update,在源文件 mtime 更新时进行覆盖。如果你的场景对正确性有着极致要求,可以指定 --check-new 或 --check-all,来对两边的文件进行字节流比对,确保数据一致。
如需全量同步,即不论目标路径上是否存在相同的文件都重新同步,可以使用 --force-update。
目录结构与文件权限
默认情况下,空目录不会被同步。如需同步空目录,可以使用 --dirs 选项。
另外,在本地、SFTP、HDFS 等文件系统之间同步时,如需保持文件权限,可以使用 --perms 选项。
符号链接
在本地目录之间同步时,支持通过设置 --links 选项开启遇到符号链时同步其自身而不是其指向的对象的功能。同步后的符号链接指向的路径为源符号链接中存储的原始路径,无论该路径在同步前后是否可达都不会被转换,注意:
- 符号链接自身的
mtime不会被拷贝; --check-new和--perms选项的行为在遇到符号链接时会被忽略。
数据同步与碎片合并
对于顺序写场景,一定要尽力保证每个文件的写入都有最少 4M(默认块大小)的缓冲区可用,如果写并发太高,或者缓冲区设置太小,都会导致原本高效的“大块写”退化为“碎片化缓慢写”。叠加上 JuiceFS 的碎片合并,可能会带来严重的写放大问题。
碎片合并流量可以通过 juicefs_compact_bytes 这个指标来观测,JuiceFS Web 控制台的监控页面,以及私有部署环境的 Grafana 的对象存储流量板块,均将该指标画图呈现。如果在 sync 期间碎片合并流量很高,说明需要进行相关调优。推荐实践和调优思路如下:
- 如果对象存储的写带宽不足,慎用高并发(
--threads),最好从默认值甚至更低的并发开始测起,谨慎增加到满意的速度; - 当目的地是 JuiceFS 文件系统的时候,推荐使用
jfs://协议头,这种方式不需要 FUSE 挂载点,能减少资源开销,并且还提前针对碎片合并导致的写放大问题进行了优化(持久化间隔已经设置为每 60 秒一次,阅读下一点详细了解原理); - 如果必须使用 FUSE 挂载点来同步数据,那么对于大文件同步场景,建议调整挂载参数
--flush-wait=60s,将默认 5 秒一次的持久化改为 60 秒,减少碎片量导致的写放大。详细阅读写放大的排查以了解更多; - 如果目的地是 JuiceFS 文件系统,确保该文件系统的 JuiceFS 客户端有着充足的读写缓冲区,按照每个文件的写入都必须起码预留 4M 的写入空间,那么
--buffer-size起码要大于等于--threads参数的 4 倍,如果希望进一步提高写入并发,那么建议使用 8 或 12 倍的并发量来设置缓冲区。特别注意,根据写入目的地使用的协议头不同,设置缓冲区的方法也不同:- 目的地是
jfs://协议头的文件系统,客户端进程就是juicefs sync命令本身,此时--buffer-size参数需要追加到juicefs sync命令里; - 目的地是本地的 FUSE 挂载点,那么客户端进程是宿主机上运行的
juicefs mount命令,此时--buffer-size参数追加到该挂载点的juicefs mount命令里。
- 目的地是
- 如果需要施加限速,那么加上了
--bwlimit参数后,需要降低--threads,避免�过高的并发争抢带宽,产生类似的碎片化问题。每个对象存储的延迟和吞吐不尽相同,再次无法给出细致的调优计算流程,建议从更低的并发开始重新测试。
删除特定文件
模式匹配还可以实现删除存储系统中特定文件。诀窍是在本地创建一个空目录,将其作为 SRC。
示范如下,谨慎起见,所有示范均添加了 --dry --debug 选项来空运行,不会实际删除任何文件,而是打印执行计划。验证成功后,去掉这两个选项便能实际执行。
mkdir empty-dir
# 删除 mybucket 中所有对象,但保留后缀名为 .gz 的文件
juicefs sync ./empty-dir/ s3://mybucket.s3.us-east-2.amazonaws.com/ --match-full-path --delete-dst --exclude='**.gz' --include='*' --dry --debug
# 删除 mybucket 中所有后缀名为 .gz 的文件
juicefs sync ./empty-dir/ s3://mybucket.s3.us-east-2.amazonaws.com/ --match-full-path --delete-dst --include='**.gz' --exclude='*' --dry --debug
加速同步
juicefs sync 默认启用 10 个线程执行同步任务,可以根据需要设置 --threads 选项调大或减少线程数。但也要注意,受限于有限的单机资源,一味增加 --threads 未必能持续提升同步速度,反而可能会导致 OOM。因此如果同步速度不足,还需要考虑:
SRC和DST的存储系统是否已经达到了带宽上限,如果其中一个存储已经到达带宽限制,同步的瓶颈就在这里,增加并发度也不会继续提升同步速度;- 单机资源是否吃紧,比如 CPU、网卡拥堵。如果同步受限于单机资源,那么可以考虑:
- 如果运行环境有硬件条件更好的节点(CPU、网络出口带宽等),可以换用该节点来运行
juicefs sync,通过 SSH 访问源数据,例如juicefs sync root@src:/data /jfs/data; - 使用分布式同步,在下方相关小节介绍。
- 如果运行环境有硬件条件更好的节点(CPU、网络出口带宽等),可以换用该节点来运行
- 如果同步的数据以小文件为主,并且
SRC的存储系统的listAPI 性能极佳,那么juicefs sync默认的单线程list可能会成为瓶颈。此时考虑启用并发list操作,在下一小节介绍。
并发 list
在 juicefs sync 命令的输出中,关注 Pending objects 的数量,如果该值持续为 0,说明消费速度大于生产,可以增大 --list-threads 来启用并发 list,以及用 --list-depth 来控制并发 list 的目录深度。
比方说,如果你面对的是 JuiceFS 所使用的对象存储服务,那么目录结构为 /<vol-name>/chunks/xxx/xxx/...,对于这样的目录结构,使用 --list-depth=2 来实现对于 /<vol-name>/chunks 的并发列表操作,是比较合适的选择。
分布式同步
在两个对象存储之间同步数据,就是从一端拉取数据再推送到另一端,同步的效率取决于客户端与云之间的带宽:
在同步大量数据时,单机带宽往往会被占满出现瓶颈,针对这种情况,考虑使用多机并发同步:
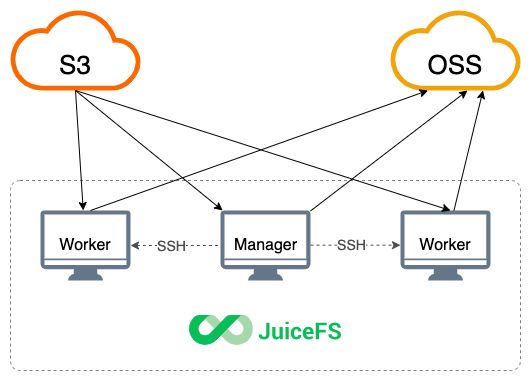
Manager 作为主控执行 sync 命令,通过 --worker 参数定义多个 Worker 节点(Manager 自身也参与同步),JuiceFS 会根据 Worker 的总数量,动态拆分同步任务并分发给各个节点并发执行,单位时间内能处理的数据量更大,总带宽也成倍增加。
在配置多机并发同步任务时,需要提前配置好 Manager 节点到 Worker 节点的 SSH 免密登录,如果 Worker 节点的 SSH 端口不是默认的 22,请在 Manager 节点的 ~/.ssh/config 设置其端口号。Manager 会将 JuiceFS 客户端程序分发到 Worker 节点,为避免兼容性问题,Manager 和 Worker 应使用相同类型和架构的操作系统。
举例说明,用分布式同步的方式进行对象存储间的数据同步:
juicefs sync --worker [email protected],[email protected] s3://ABCDEFG:[email protected] oss://ABCDEFG:[email protected]
运行这个命令后,当前节点与两个 Worker 节点 [email protected] 和 [email protected] 将共同分担数据同步任务。
上方的示范中是对象存储 → 对象存储的数据同步,如果需要基于 FUSE 挂载点做数据同步,那么可以在所有节点挂载 JuiceFS,然后用类似下方的命令来进行分布式同步:
# 在所有节点挂载 JuiceFS,以 parallel-ssh 为例,需要将配置文件复制到所有节点,然后挂载
parallel-scp -h hosts.txt -r /root/.juicefs /root/.juicefs
# 源文件系统需要更好的读性能,因此增大 buffer-size
parallel-ssh -h hosts.txt -i juicefs mount jfs-src /jfs-src --buffer-size=1024 --cache-size=0
# 目标文件系统需要更好的写性能
parallel-ssh -h hosts.txt -i juicefs mount jfs-dst /jfs-dst --buffer-size=1024 --cache-size=0 --flush-wait=60 --max-uploads=50
# 挂载完毕后,用下方命令拷贝数据
juicefs sync --worker host1,host2 /jfs-src /jfs-dst
观测和监控
当 sync 命令的源端、目标端都是 jfs:// 协议头时,监控指标数值会产生错误,具体而言:源端的读(以及对象存储 GET 流量)会被计入目标端的统计值,目标端的写也会计入源端,因此阅读监控数据时需要尤其注意。这个问题会在未来的版本进行修复。
sync 假定了使用场景是拷贝大量文件,因此进度的计算也是针对多个文件设计的:每一个文件完成了拷贝后,进度会更新一次。因此如果面对的都是大文件,单个文件的拷贝速度太慢,进度条就会变化缓慢,或者呈现卡死的状态。如果目的地端协议不支持 multipart upload(比如 file、sftp、jfs 协议头),单个文件会单线程进行复制,无法对大文件进行并发上传。可想而知,大文件 + 不支持 multipart upload,将会更容易出现进度条卡死的情况。
因此,如果 sync 命令的输出已经无法满足观测需要,参考下列手段进行观测和排查:
-
为
juicefs sync添加--verbose或--debug参数,打印 debug 日志; -
如果数据同步的两方有任何一个是 JuiceFS 宿主机挂载点:
- 用
juicefs stats快速查看文件系统是否正在写入或读出 - 阅读客户端日志(默认
/var/log/juicefs.log),观察是否有慢请求或者超时错误日志
- 用
-
如果数据同步的目的地是宿主机本地盘,可以直接观察目录下是否存在名称中带
.tmp.xxx后缀的临时文件,sync过程中会将传输结果写入临时文件,待传输完成后进行重命名,才完成最终的写入。观察临时文件大小是否变化,就能确定当前的写入状况。 -
如果传输目的地均为对象存储,可以通过类似
nethogs�的命令,查看出入网流量,来判断传输进展。 -
以上手段均未能获得有效排查信息,则需要对
sync进程采集 goroutine,发给 Juicedata 工程师进行排查:# 将 <PID> 替换为卡死的 sync 命令的 PID,记下 pprof 监听端口
lsof -p <PID> | grep TCP | grep LISTEN
# pprof 端口一般是 6061,如果已经被占用,则需要递增,需要根据实际情况修改
curl -s localhost:6061/debug/pprof/goroutine?debug=1
如果需要监控 sync 命令的进度,可以使用 --metrics 参数指定监控指标地址,默认为 127.0.0.1:9567。用 Prometheus 抓取这些指标,就能进行监控。
场景应用
使用 S3 网关进行跨区域数据同步
通过 POSIX 方式访问 JuiceFS 时,会有频繁的元数据访问,跨区域访问元数据的延迟比较高会影响访问性能。如果需要跨区域传输大量小文件,这时元数据服务延迟高对性能影响更严重。

在这种情况下,可以通过跨区访问部署在源区域的 S3 网关来提升性能,它可以大幅减少跨区域访问的请求数。

阅读「S3 网关」学习如何使用和部署 S3 网关。


