读写请求处理流程
写入流程
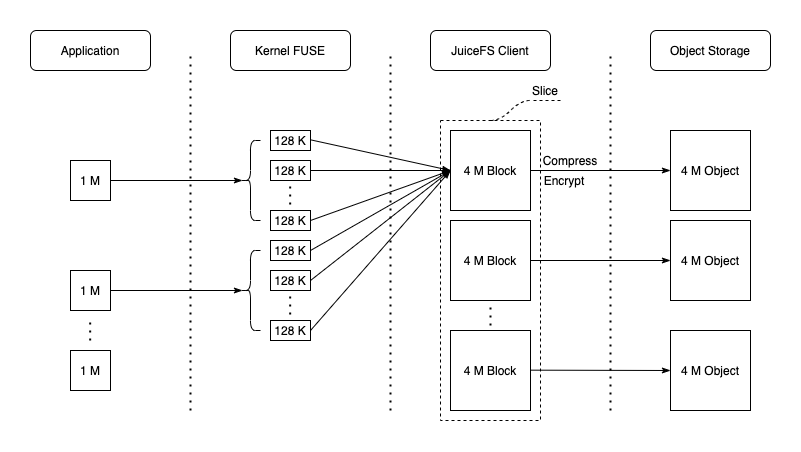
JuiceFS 对大文件会做多级拆分(JuiceFS 如何存储文件),以提高读写效率。在处理写请求时,JuiceFS 先将数据写入 Client 的内存缓冲区,并在其中按 Chunk/Slice 的形式进行管理。Chunk 是根据文件内 offset 按 64 MiB 大小拆分的连续逻辑单元,不同 Chunk 之间完全隔离。每个 Chunk 内会根据应用写请求的实际情况进一步拆分成 Slice;当新的写请求与已有的 Slice 连续或有重叠时,会直接在该 Slice 上进行更新,否则就创建新的 Slice。Slice 是启动数据持久化的逻辑单元,其在 flush 时会先将数据按照默认 4 MiB 大小拆分成一个或多个连续的 Block,并作为最小单元上传到对象存储;然后再更新一次元数据,写入新的 Slice 信息。
显然,在应用顺序写情况下,只需要一个不停增长的 Slice,最后仅 flush 一次即可;此时能最大化发挥出对象存储的写入性能。以一次简单的 JuiceFS 基准测试为例,使用 1 MiB IO 顺序写 1 GiB 文件,在不考虑压缩和加密的前提下,数据在各个组件中的形式如下图所示:
用 juicefs stats 命令记录的指标图,可以直观地看到实时性能数据:
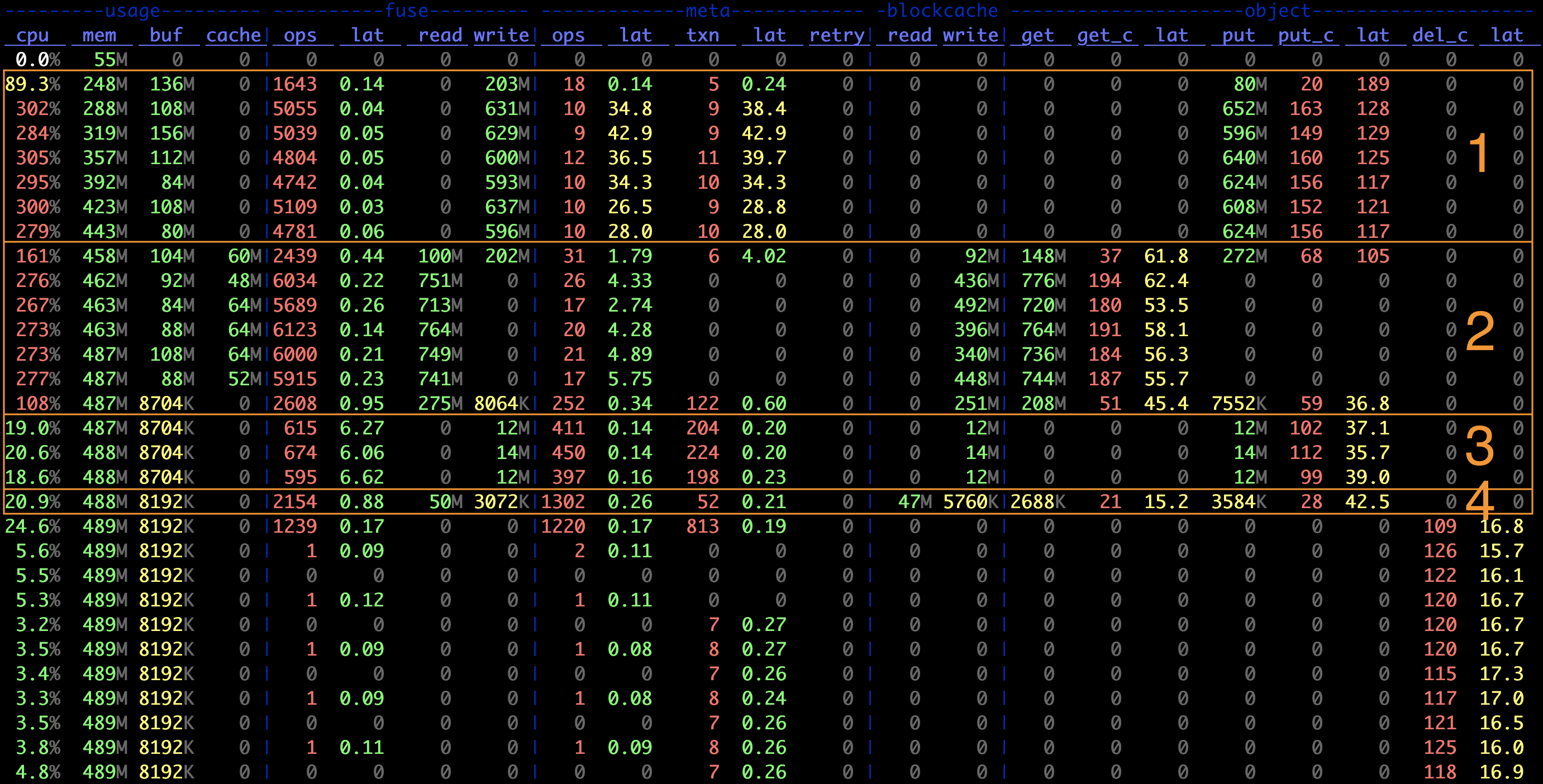
图中第 1 阶段:
- 对象存储写入的平均 IO 大小为
object.put / object.put_c = 4 MiB,等于 Block 的默认大小 - 元数据事务数与对象存储写入数比例大概为
meta.txn : object.put_c ~= 1 : 16,对应 Slice flush 需要的 1 次元数据修改和 16 次对象存储上传,同时也说明了每次 flush 写入的数据量为 4 MiB * 16 = 64 MiB,即 Chunk 的默认大小 - FUSE 层的平均请求大小为约
fuse.write / fuse.ops ~= 128 KiB,与其默认的请求大小限制一致
小文件的写入通常是在文件关闭时被上传到对象存储,对应 IO 大小一般就是文件大小。指标图的第 3 阶段是创建 128 KiB 小文件,可以发现:
- 对象存储 PUT 的大小就是 128 KiB
- 元数据事务数大致是 PUT 计数的两倍,对应每个文件的一次 Create 和一次 Write
对于这种不足一个 Block Size 的对象,JuiceFS 在上传的同时还会尝试写入到本地缓存,来提升后续可能的读请求速度。因此从图中第 3 阶段也可以看到,创建小文件时,本地缓存(blockcache)与对象存储有着同等的写入带宽,而在读取时(第 4 阶段)大部分均在缓存命中,这使得小文件的读取速度看起来特别快。
由于写请求写入客户端内存缓冲区即可返回,因此通常来说 JuiceFS 的 Write 时延非常低(几十微秒级别),真正上传到对象存储的动作由内部自动触发,比如单个 Slice 过大,Slice 数量过多,或者仅仅是在缓冲区停留时间过长等,或应用主动触发,比如关闭文件、调用 fsync 等。
缓冲区中的数据只有在被持久化后才能释放,因此当写入并发较大时,如果缓冲区大小不足(默认 300MiB,通过 --buffer-size 调节),或者对象存储性能不佳,读写缓冲区将持续被占用而导致写阻塞。缓冲区大小可以在指标图的 usage.buf 一列中看到。当使用量超过阈值时,JuiceFS Client 会主动为 Write 添加约 10ms 等待时间以减缓写入速度;若已用量超过阈值两倍,则会导致写入暂停直至缓冲区得到释放。因此,在观察到 Write 时延上升以及 Buffer 长时间超过阈值时,通常需要尝试设置更大的 --buffer-size。另外,增大上传并发度(--max-uploads,默认 20)也能提升写入到对象存储的带宽,从而加快缓冲区的释放。
随机写
JuiceFS 支持随机写,包括通过 mmap 等进行的随机写。
要知道,Block 是一个不可变对象,这也是因为大部分对象存储服务并不支持修改对象,只能重新上传覆盖。因此发生覆盖写、大文件随机写时,并不会将 Block 重新下载、修改、重新上传(这样会带来严重的读写放大!),而是在新分配或者已有 Slice 中进行写入,以新 Block 的形式上传至对象存储,然后修改对应文件的元数据,在 Chunk 的 Slice 列表中追加新 Slice。后续读取文件时,其实在读取通过合并 Slice 得到的视图。
因此相较于顺序写来说,大文件随机写的情况更复杂:每个 Chunk 内可能存在多个不连续的 Slice,使得一方面数据对象难以达到 4 MiB 大小,另一方面元数据需要多次更新。因此,JuiceFS 在大文件随机写有明显的性能下降。当一个 Chunk 内已写入的 Slice 过多时,会触发碎片清理(Compaction)来尝试合并与清理这些 Slice,来提升读性能。碎片清理以后台任务形式发生,除了系统自动运行,还能通过 juicefs gc 命令手动触发。
客户端写缓存
客户端写缓存,也称为「回写模式」。
如果对数据一致性和可靠性没有极致要求,可以在挂载时添加 --writeback 以进一步提写性能。客户端缓存开启后,Slice flush 仅需写到本地缓存目录即可返回,数据由后台线程异步上传到对象存储。换个角度理解,此时本地目录就是对象存储的缓存层。
更详细的介绍请见「客户端写缓存」。
读取流程
JuiceFS 支持顺序读和随机读(包括基于 mmap 的随机读),在处理读请求时会通过对象存储的 GetObject 接口完整读取 Block 对��应的对象,也有可能仅仅读取对象中一定范围的数据(比如通过 S3 API 的 Range 参数限定读取范围)。与此同时异步地进行预读(通过 --prefetch 参数控制预读并发度),预读会将整个对象存储块下载到本地缓存目录,以备后用(如指标图中的第 2 阶段,blockcache 有很高的写入带宽)。显然,在顺序读时,这些提前获取的数据都会被后续的请求访问到,缓存命中率非常高,因此也能充分发挥出对象存储的读取性能。数据流如下图所示:
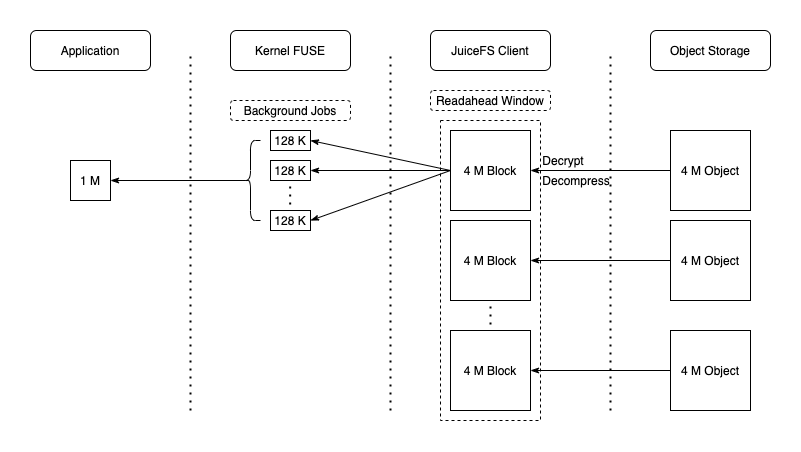
但是对于大文件随机读场景,预读的用途可能不大,反而容易因为读放大和本地缓存的频繁写入与驱逐使得系统资源的实际利用率降低,此时可以考虑用 --prefetch=0 禁用预读。考虑到此类场景下,一般的缓存策略很难有足够高的收益,可考虑尽可能提升缓存的整体容量,达到能几乎完全缓存所需数据的效果;或者直接禁用缓存(--cache-size=0),并尽可能提高对象存储的读取性能。
小文件的读取则比较简单,通常就是在一次请求里读取完整个文件。由于小文件写入时会直接被缓存起来,因此,之后的读性能非常可观。


