Shared Block Device
Due to JuiceFS' decoupled architecture, reads and writes generally involve metadata access and object storage access. The latter often has higher latency. This is why in JuiceFS, the performance of small files or large amounts of random reads/writes is significantly worse than sequential reads/writes. If you have higher demands for read/write performance (local disk level), upgrade to 5.2 or newer versions of JuiceFS Client, and then mount a block device to use as storage for JuiceFS.
Using the diagram below to understand the key design points:
- Set the slice size threshold (think of slice as a continuous write, with a length ranging from 0 to 64MB. For details, see our architecture). Slices below this threshold are written to the block device; otherwise, they are uploaded directly to object storage.
- You can configure the retention time on the block device. All data stored for longer than the specified time is automatically uploaded to object storage. Moreover, you can use slice size to determine wether data are persisted on the block device, or transferred to object storage. Users can plan with flexibility on how to balance storage allocation between fast & expensive block device, and slow but cheap object storage.
- Although the feature is named "shared block device," JuiceFS supports the use of any unformatted block device, not necessarily a multi-mount shared block device. Therefore, you can also use regular single-mounted cloud disks in conjunction with this feature, read single mount block device for more.

Typical scenarios for using shared block devices in JuiceFS include:
- Low-latency requirements for both reads and writes, using block devices for data storage, or even configuring block devices as permanent storage.
- Shared block devices offer good write performance and support multiple-node mounts. This makes them suitable for solving the pain point of write cache (
--writeback), where pending data is not visible to other clients. The specific usage is to mount the same shared block device on multiple client nodes, not enable write caching, and write data normally. This is because the write performance of the block device itself is good enough. In a shared block device scenario, there is no need for write caching. Data is written directly to the shared device which is visible to other clients.
Some important caveats:
- All clients must mount the block device at the same path, otherwise it cannot be detected and managed by JuiceFS. For clients without direct access to the block device, they can proxy I/O requests through those who actually mounted the block device (5.2 or newer versions are required), see single mount block device for more.
- You do not need to format the file system. JuiceFS' metadata engine directly manages raw block devices.
- You can scale out your shared block device online by adding disks or increasing capacity of existing disks.
- Currently, mirror file systems are not supported.
- Currently, the multi-zone approach is not supported. On a single zone, the storage limit is 500 million files.
The support for shared block devices is currently in the public testing phase. If you need it, contact Juicedata engineers for assistance.
Multi-Attach block device
Some of the public cloud service providers offers shared block devices, such as AWS Multi-Attach or Aliyun Multi-Attach, where a block device can be mounted to multiple hosts (up to 16 instances), so you can use the shared block device support with these providers. With a shared block device, the normal file systems cannot be used, and a dedicated file system is required to actually utilize the shared device. JuiceFS is one such file system, we can use a shared, unformatted raw disk as storage backend.
Under this mode, it is advised to mount shared block devices to clients that handle intensive, concurrent small file writes / random writes, such as exploratory data analysis (EDA), data processing before computer vision (CV) training, and performing tasks in Elasticsearch and ClickHouse.
Take into account that there's usually a limit of 16 instances that can simutaneously mount the block device, if other JuiceFS clients need to access the block device, you must upgrade to 5.2 which supports proxy access of the shared block device, so that even clients that do not mount the block device can still have access to files stored on the block device, read the next section for more.
Single mount block device
Before 5.2, a shared block device can only be accessed by JuiceFS clients that have actually mounted it, whereas others have no reach to this part of storage. This solution is only feasible in scenarios where only a small set of clients (less than 16) need to interact with the block device. 5.2 and newer versions do not have this restriction, all clients can access the shared block device, regardless of wether they have an actual mount point. Clients that do not have the block device mounted simply proxy their I/O requests through peers that have it mounted.

Block device as storage backend (Beta)
If your application suits our targeted scenarios, you may consider using only block device as the storage backend, without an actual object storage. Contact Juicedata engineers to configure this setup.
Tutorial
Contact a Juicedata engineer and send the name of the file system that you wish to use a shared block device with, as well as the device mount path, we will set it up for you in the JuiceFS Web Console. Navigate to the file system and hit the "Block device" tab to verify feature status, and then adjust the retention settings as needed.
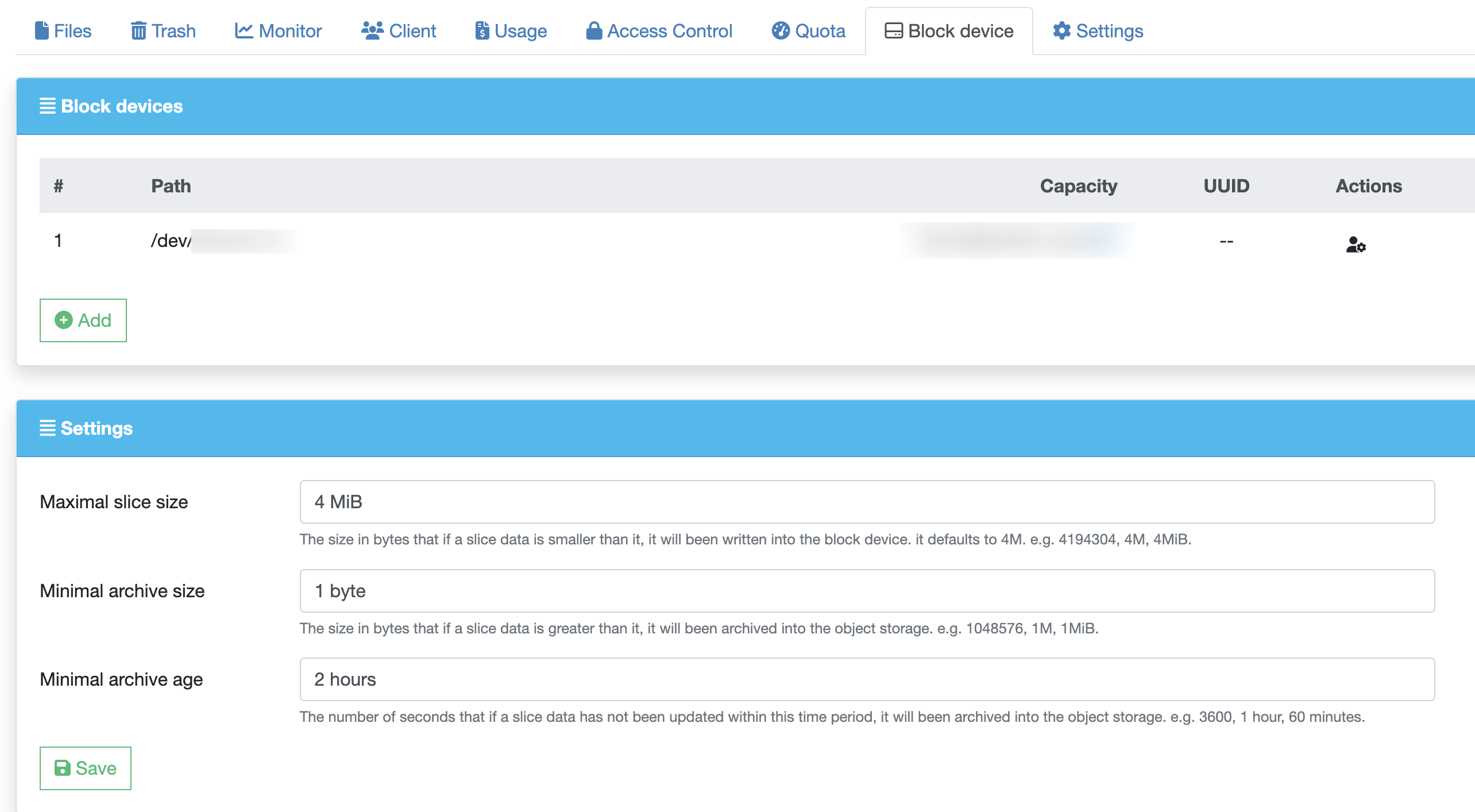
Mount the JuiceFS file system, note that after block device is enabled, pay attention to /var/log/juicefs.log output when mount for the first time, below log text indicates that your block device is correctly discovered:
Added device 0 (7d456ed7-1853-493e-ac12-52305368a819) at /dev/disk/by-id/virtio-bp18k7whb2xr01kgjkp0 with capacity 100 GiB
However, if you have already correctly mounted the block device (same path as the one displayed in our web console), but there's no above log text in juicefs.log, contact us to troubleshoot.
Mount the file system, using the retention settings shown above, any write under 4MiB will be stored inside the block device, which can be verified using the juicefs info command.
$ date >> /jfs/test.txt
$ juicefs info /jfs/test.txt
test.txt :
inode: 3
files: 1
dirs: 0
length: 2 Bytes
size: 4.00 KiB (4096 Bytes)
path: /a
objects:
+------------+---------------------------------------------+--------------+-----------+--------+
| chunkIndex | objectName | size | offset | length |
+------------+---------------------------------------------+--------------+-----------+--------+
| 0 | /dev/disk/by-id/virtio-bp18k7whb2xr01kgjkp0 | 107374182400 | 536870912 | 2 |
+------------+---------------------------------------------+--------------+-----------+--------+
Note the output above, if objectName starts with the block device mount point, this means data is written to the block device. As a comparison, if block device is not enabled, the output table simply contains the object storage block path, for example:
$ juicefs info /jfs/a
/jfs/a :
inode: 51
files: 1
dirs: 0
length: 2 Bytes
size: 4.00 KiB (4096 Bytes)
path: /a
objects:
+------------+-------------------------------+------+--------+--------+
| chunkIndex | objectName | size | offset | length |
+------------+-------------------------------+------+--------+--------+
| 0 | poc/chunks/B5/54/54450357_0_2 | 2 | 0 | 2 |
+------------+-------------------------------+------+--------+--------+

