问题排查方法
客户端日志
JuiceFS 客户端在运行过程中会输出日志用于故障诊断,日志等级从低到高分别是:DEBUG、INFO、WARNING、ERROR、FATAL,默认只输出 INFO 级别以上的日志。如果需要输出 DEBUG 级别的日志,需要在运行 JuiceFS 客户端时显式开启,如加上 --debug 选项。
不同 JuiceFS 客户端获取日志的方式不同,以下分别介绍。
挂载点
当挂载 JuiceFS 文件系统时加上了 -d 选项(表示后台运行),日志会同时输出到系统日志和本地日志文件,取决于挂载文件系统时的运行用户,本地日志文件的路径稍有区别。root 用户对应的日志文件路径是 /var/log/juicefs.log,非 root 用户的日志文件路径是 $HOME/.juicefs/juicefs.log,具体请参见 --log 选项。
取决于你使用的操作系统,你可以通过不同的命令获取系统日志或直接读取本地日志文件:
- 本地日志文件
- macOS 系统日志
- Debian 系统日志
- CentOS 系统日志
tail -n 100 /var/log/juicefs.log
syslog | grep 'juicefs'
cat /var/log/syslog | grep 'juicefs'
cat /var/log/messages | grep 'juicefs'
你可以使用 grep 命令过滤显示不同等级的日志信息,从而进行性能统计和故障追踪,例如:
cat /var/log/syslog | grep 'juicefs' | grep '<ERROR>'
Kubernetes CSI 驱动
根据你使用的 JuiceFS CSI 驱动版本会有不同的获取日志的方式,具体请参考 CSI 驱动文档。
S3 网关
S3 网关仅支持在前台运行,因此客户端日志会直接输出到终端。如果你是在 Kubernetes 中部署 S3 网关,需要查看对应 pod 的日志。
Hadoop Java SDK
使用 JuiceFS Hadoop Java SDK 的应用进程(如 Spark executor)的日志中会包含 JuiceFS 客户端日志,因为和应用自身产生的日志混杂在一起,需要通过特定关键词来过滤筛选(如 juicefs,注意这里忽略了大小写)。
文件系统访问日志
每个 JuiceFS 客户端都有一个访问日志,其中详细记录了文件系统上的所有操作,如操作类型、用户 ID、用户组 ID、文件 inode 及其花费的时间。访问日志可以有多种用途,如性能分析、审计、故障诊断。
日志格式
访问日志的示例格式如下:
2021.01.15 08:26:11.003330 [uid:0,gid:0,pid:4403] write (17669,8666,4993160): OK <0.000010>
其中每一列的含义为:
2021.01.15 08:26:11.003330:当前操作的时间[uid:0,gid:0,pid:4403]:当前操作的用户 ID、用户组 ID、进程 IDwrite:操作类型(17669,8666,4993160):当前操作类型的输入参数,如示例中的write操作的输入参数分别为写入文件的 inode、写入数据的大小、写入文件的偏移。不同操作类型的参数不同,具体请参考vfs.go文件。OK:当前操作是否成功,如果不成功会输出具体的失败信息。<0.000010>:当前操作花费的时间(以秒为单位)
访问日志量很大,直接阅读难以把握系统性能情况,推荐使用 juicefs profile 直接基于日志进行性能可视化分析。
不同 JuiceFS 客户端获取访问日志的方式不同,以下分别介绍。
挂载点
在 JuiceFS 文件系统挂载点的根目录中有一个名为 .accesslog 的虚拟文件,通过 cat 命令可以查看其中的内容(命令不会退出),例如(假设挂载点根目录为 /jfs):
cat /jfs/.accesslog
2021.01.15 08:26:11.003330 [uid:0,gid:0,pid:4403] write (17669,8666,4993160): OK <0.000010>
2021.01.15 08:26:11.003473 [uid:0,gid:0,pid:4403] write (17675,198,997439): OK <0.000014>
2021.01.15 08:26:11.003616 [uid:0,gid:0,pid:4403] write (17666,390,951582): OK <0.000006>
Kubernetes CSI 驱动
请参考 CSI 驱动文档及根据你使用的 JuiceFS CSI 驱动版本来找到 mount pod 或者 CSI 驱动 pod,在 pod 内的 JuiceFS 文件系统挂载点根目录查看 .accesslog 文件即可。Pod 内的挂载点路径为 /jfs/<pv_volumeHandle>,假设 mount pod 的名称叫 juicefs-1.2.3.4-pvc-d4b8fb4f-2c0b-48e8-a2dc-530799435373,<pv_volumeHandle> 为 pvc-d4b8fb4f-2c0b-48e8-a2dc-530799435373,可以使用如下命令查看:
kubectl -n kube-system exec juicefs-1.2.3.4-pvc-d4b8fb4f-2c0b-48e8-a2dc-530799435373 -- cat /jfs/pvc-d4b8fb4f-2c0b-48e8-a2dc-530799435373/.accesslog
S3 网关
需要在启动 S3 网关时新增 --access-log 选项,指定访问日志输出的路径,默认 S3 网关不输出访问日志。
Hadoop Java SDK
需要在 JuiceFS Hadoop Java SDK 的客户端配置中新增 juicefs.access-log 配置项,指定访问日志输出的路径,默认不输出访问日志。
使用 debug 子命令收集各类信息
juicefs debug 子命令可以自动搜集指定挂载点的各类信息,方便进行故障诊断。
juicefs debug <mountpoint>
该命令会收集以下信息:
- JuiceFS version
- 操作系统版本与内核版本
- JuiceFS .config 内部文件内容
- JuiceFS .stat 内部文件的内容并且在 5s 后再记录一次
- mount 命令行参数
- Go pprof
- JuiceFS 日志(默认最后 5000 行)
默认会在当前目录下创建 debug 目录,并将收集到的信息保存在该目录下。下面是一个示例:
$ juicefs debug /tmp/mountpoint
$ tree ./debug
./debug
├── tmp-test1-20230609104324
│ ├── config.txt
│ ├── juicefs.log
│ ├── pprof
│ │ ├── juicefs.allocs.pb.gz
│ │ ├── juicefs.block.pb.gz
│ │ ├── juicefs.cmdline.txt
│ │ ├── juicefs.goroutine.pb.gz
│ │ ├── juicefs.goroutine.stack.txt
│ │ ├── juicefs.heap.pb.gz
│ │ ├── juicefs.mutex.pb.gz
│ │ ├── juicefs.profile.30s.pb.gz
│ │ ├── juicefs.threadcreate.pb.gz
│ │ └── juicefs.trace.5s.pb.gz
│ ├── stats.5s.txt
│ ├── stats.txt
│ └── system-info.log
└── tmp-test1-20230609104324.zip
实时性能监控
JuiceFS 客户端提供 profile 和 stats 两个子命令来对性能数据进行可视化呈现。其中,profile 命令通过读取「文件系统请求日志」进行汇总输出,而 stats 则依赖客户端监控数据。
juicefs profile
juicefs profile 会对「文件系统访问日志」进行汇总,运行 juicefs profile MOUNTPOINT 命令,便能看到根据最新访问日志获取的各个文件系统操作的实时统计信息:
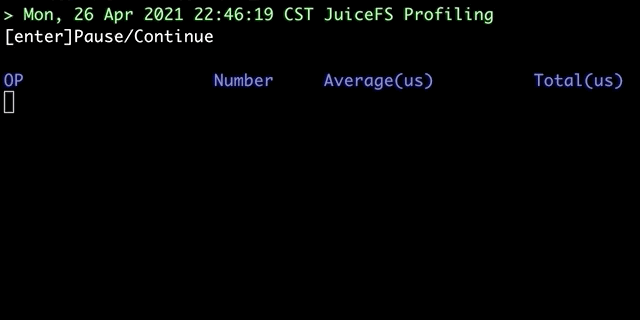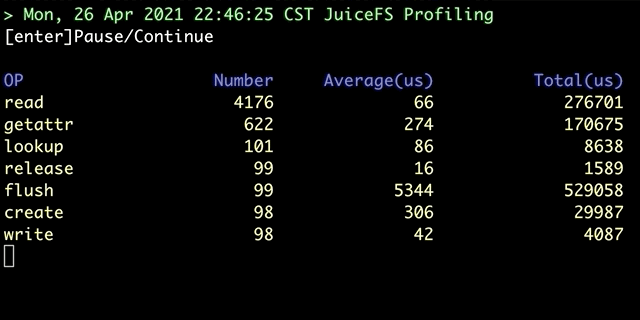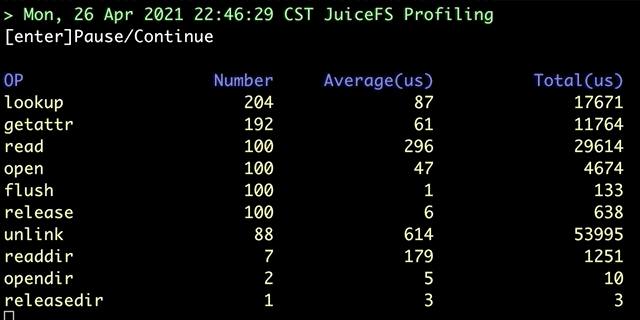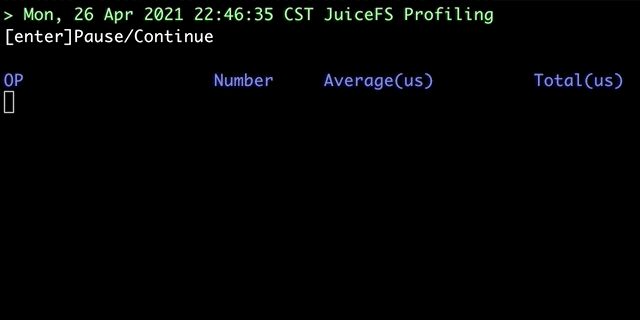
除了对挂载点进行实时分析,该命令还提供回放模式,可以对预先收集的日志进行回放分析:
# 预先收集日志
cat /jfs/.accesslog > /tmp/juicefs.accesslog
# 性能问题复现后,重放日志,分析各调用耗时,找出性能瓶颈
juicefs profile /tmp/juicefs.accesslog
如果认为回放日志的速度太快,可以用 Enter/Return 暂停/继续回放。如果太慢,则设置 --interval 0 来立即回放整个日志文件并直接显示统计结果。
如果只对某个用户或进程感兴趣,可以通过指定其 ID 来过滤掉其他用户或进程。例如:
juicefs profile /tmp/juicefs.accesslog --uid 12345
juicefs stats
juicefs stats 命令通过读取 JuiceFS 客户端的监控数据,以类似 Linux dstat 工具的形式实时打印各个指标的每秒变化情况:
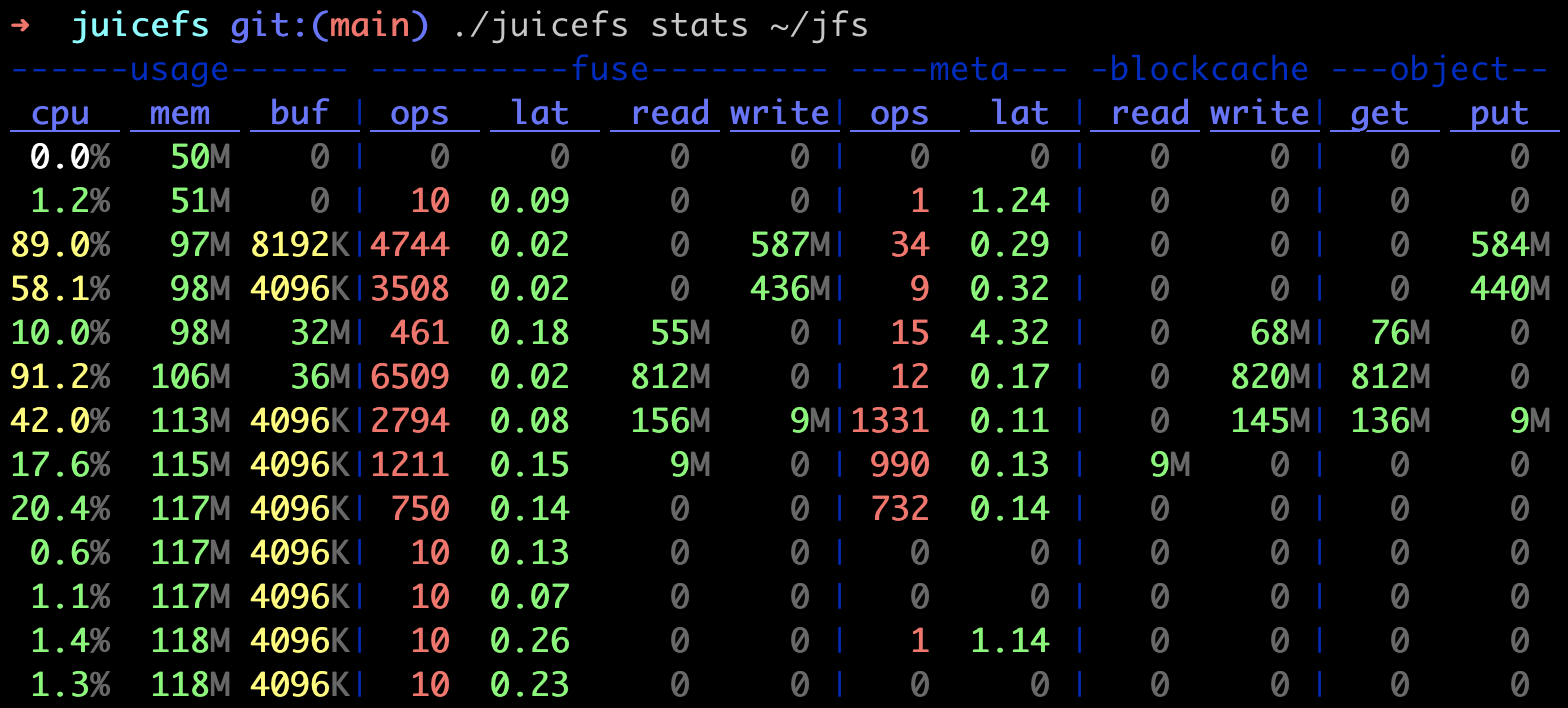
各个板块指标介绍:
usage
cpu:进程的 CPU 使用率。mem:进程的物理内存使用量。buf:进程已使用的读写缓冲区大小,如果该数值逼近甚至超过客户端所设置的--buffer-size,说明读写缓冲区空间不足,需要视情况扩大,或者降低应用读写负载。cache:内部指标,无需关注。
fuse
ops/lat:通过 FUSE 接口处理的每秒请求数及其平均时延,单位为毫秒。read/write:通过 FUSE 接口处理的读写带宽。
meta
ops/lat:每秒处理的元数据请求数和平均时延,单位为毫秒。注意部分能在缓存中直接处理的元数据请求未列入统计,以更好地体现客户端与元数据引擎交互的耗时。txn/lat:元数据引擎每秒处理的写事务个数及其平均时延,单位为毫秒。只读请求如getattr只会计入ops而不会计入txn。retry:元数据引擎每秒重试写事务的次数。
blockcache
blockcache 代表本地数据缓存,如果读请求已经被内核缓存,那么流量将不会体现在 blockcache 相关指标下。因此如果反复读取相同文件,却发现持续产生 blockcache 流量,说明文件始终未能被内核页缓存收录,考虑往该方向排查(比如内存吃紧,不足以缓存更多文件)。
read/write:客户端本地数据缓存的每秒读写流量。
object
object 代表与对象存储相关指标,在缓存场景下,读请求穿透到对象存储,将��会明显降低读性能,可以用该指标来断定数据是否完整缓存。另一方面,通过对比 GET 请求流量和 FUSE 读流量的关系,也能初步判断读放大的情况。
get/get_c/lat:对象存储每秒处理读请求的带宽值,请求个数及其平均时延(单位为毫秒)。put/put_c/lat:对象存储每秒处理写请求的带宽值,请求个数及其平均时延(单位为毫秒)。del_c/lat:对象存储每秒处理删除请求的个数和平均时延(单位为毫秒)。
用 pprof 获取运行时信息
JuiceFS 客户端默认会通过 pprof 在本地监听一个 TCP 端口用以获取运行时信息,如 Goroutine 堆栈信息、CPU 性能统计、内存分配统计。你可以通过挂载点下的 .config 文件查看当前 JuiceFS 客户端监听的具体端口号:
# 假设挂载点是 /jfs
$ cat /jfs/.config | grep 'DebugAgent'
"DebugAgent": "127.0.0.1:6064",
默认 pprof 监听的端口号范围是从 6060 开始至 6099 结束,从上面的示例中可以看到实际的端口号是 6064。在获取到监听端口号以后就可以通过 http://localhost:<port>/debug/pprof 地址查看所有可供查询的运行时信息,一些重要的运行时信息如下:
- Goroutine 堆栈信息:
http://localhost:<port>/debug/pprof/goroutine?debug=1 - CPU 性能统计:
http://localhost:<port>/debug/pprof/profile?seconds=30 - 内存分配统计:
http://localhost:<port>/debug/pprof/heap
为了便于分析这些运行时信息,可以将它们保�存到本地,例如:
curl 'http://localhost:<port>/debug/pprof/goroutine?debug=1' > juicefs.goroutine.txt
curl 'http://localhost:<port>/debug/pprof/profile?seconds=30' > juicefs.cpu.pb.gz
curl 'http://localhost:<port>/debug/pprof/heap' > juicefs.heap.pb.gz
你也可以使用 juicefs debug 命令自动收集这些运行时信息并保存到本地,默认保存到当前目录下的 debug 目录中,例如:
juicefs debug /mnt/jfs
关于 juicefs debug 命令的更多信息,请查看命�令参考。
如果你安装了 go 命令,那么可以通过 go tool pprof 命令直接分析,例如分析 CPU 性能统计:
$ go tool pprof 'http://localhost:<port>/debug/pprof/profile?seconds=30'
Fetching profile over HTTP from http://localhost:<port>/debug/pprof/profile?seconds=30
Saved profile in /Users/xxx/pprof/pprof.samples.cpu.001.pb.gz
Type: cpu
Time: Dec 17, 2021 at 1:41pm (CST)
Duration: 30.12s, Total samples = 32.06s (106.42%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 30.57s, 95.35% of 32.06s total
Dropped 285 nodes (cum <= 0.16s)
Showing top 10 nodes out of 192
flat flat% sum% cum cum%
14.73s 45.95% 45.95% 14.74s 45.98% runtime.cgocall
7.39s 23.05% 69.00% 7.41s 23.11% syscall.syscall
2.92s 9.11% 78.10% 2.92s 9.11% runtime.pthread_cond_wait
2.35s 7.33% 85.43% 2.35s 7.33% runtime.pthread_cond_signal
1.13s 3.52% 88.96% 1.14s 3.56% runtime.nanotime1
0.77s 2.40% 91.36% 0.77s 2.40% syscall.Syscall
0.49s 1.53% 92.89% 0.49s 1.53% runtime.memmove
0.31s 0.97% 93.86% 0.31s 0.97% runtime.kevent
0.27s 0.84% 94.70% 0.27s 0.84% runtime.usleep
0.21s 0.66% 95.35% 0.21s 0.66% runtime.madvise
也可以将运行时信息导出为可视化图表,以更加直观的方式进行分析。可视化图表支持导出为多种格式,如 HTML、PDF、SVG、PNG 等。例如导出内存分配统计信息为 PDF 文件的命令如下:
导出为可视化图表功能依赖 Graphviz,请先将它安装好。
go tool pprof -pdf 'http://localhost:<port>/debug/pprof/heap' > juicefs.heap.pdf
关于 pprof 的更多信息,请查看官方文档。
使用 Pyroscope 进行性能剖析
Pyroscope 是一个开源的持续性能剖析平台。它能够帮你:
- 找出源代码中的性能问题和瓶颈
- 解决 CPU 利用率高的问题
- 理解应用程序的调用树(call tree)
- 追踪随一段时间内变化的情况
JuiceFS 支持使用 --pyroscope 选项传入 Pyroscope 服务端地址,指标以每隔 10 秒的频率推送到服务端。如果服务端开启了权限校验,校验信息 API Key 可以通过环境变量 PYROSCOPE_AUTH_TOKEN 传入:
export PYROSCOPE_AUTH_TOKEN=xxxxxxxxxxxxxxxx
juicefs mount --pyroscope http://localhost:4040 redis://localhost /mnt/jfs
juicefs dump --pyroscope http://localhost:4040 redis://localhost dump.json


