














一个高精度 AI 模型离不开大量的优质数据集,这些数据集往往由标注结果文件和海量的图片组成。在数据量比较大的情况下,模型训练周期也会相应加长。那么有什么加快训练速度的好方法呢?
壕气的老板第一时间想到的通常是提升算力,增加资源。如果足够有钱的话,基本不需要再继续看其他解决方案了。
但大多数情况下,面对昂贵的算力资源,我们不可能无限增加的。那在花了大价钱买到了有限资源的情况下,我们还可以通过什么方式加快模型训练,提高资源利用率呢?
本文将为大家介绍的就是:

我们先看一张简单的 AI 工作全流程服务示意图
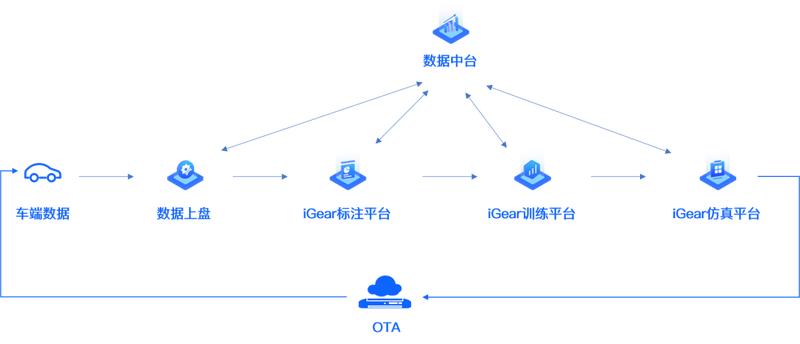
采集的数据通过 iGear 数据中台的筛选预处理、iGear 标注平台的标注后会形成优质训练数据集,这些数据集会流转到 iGear 训练平台来训练算法模型。
iGear 训练平台基于 Kubernetes 集群完成异构计算资源调度。在这个架构体系中计算和存储是分离的,数据集会放在远端的对象存储集群中,当运行模型训练任务时就需要访问远程存储来获取数据集,带来较高的网络 I/O 开销,也会造成数据集管理不便的问题。
本文提出的 iGear 高性能缓存加速方案 要做的就是:
- 如何降低 I/O 开销,提高训练效率和 GPU 利用率?
- 如何管理数据集,提高用户易用性和便利性?
缓存方案概述
前文已经提及,数据集是存储在远端的对象存储集群中的。为了提高数据集的易用性,常用方案是用 FUSE 方式挂载给到训练任务,方便用户以普通文件目录的方式识别并使用数据集。这种方式虽然满足了易用性,但高 I/O 的开销使得用户必须手动或者用脚本的方式将数据集提前同步到计算节点,这会增加用户在训练过程中的心智负担。
针对上述问题,我们对训练数据集做了优化,当用户开始准备训练时,通过 JuiceFS 实现数据集缓存引擎,为用户提供数据集缓存和预热功能,这既可以降低对远端对象存储的访问,又可以减少用户操作。充分利用计算集群本地存储来缓存数据集,通过两级缓存(训练节点的系统缓存 + 训练节点的磁盘缓存),加速模型训练速度,一定程度上也能提高 GPU 的利用率。
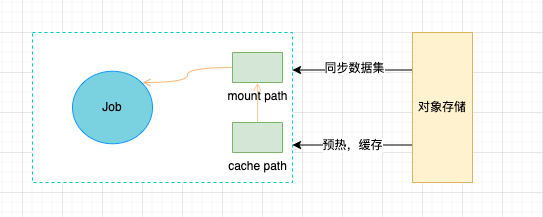
JuiceFS 是一款开源的面向云环境设计的高性能共享文件系统,在数据组织管理和访问性能上进行了大量针对性的优化,社区版本也有非常好的文档支撑,这里就不赘述了。
缓存方案测试
测试方案
我们之前使用的方案是使用 FUSE 的方式直接挂载对象存储系统,将 S3 的 bucket 通过挂载的方式挂载到本地,提供访问远端对象存储数据的能力。优化后的高性能缓存加速方案,后端也是基于对象存储,只是在此基础之上提供了缓存、预热等功能,优化了存储的性能。
基于此我们做了以下两组对比实验,两组实验都是基于同一套对象存储,且其它条件保持一致。
一. 开启或关闭高性能缓存加速的性能对比

二. 使用高性能缓存加速方案和使用 FUSE 挂载的性能对比

测试方式
在服务器物理机环境下,我们使用 PyTorch /examples 仓库中提供的 ResNet50 v1.5 进行模型训练,对其进行单机单卡、单机多卡的结果复现,同时对比执行过程花费的时长。
测试环境
- 硬件:Tesla V100-SXM2-32GB
- 驱动:NVIDIA 450.80.02
- 操作系统:Ubuntu 20.04.1 LTS
- 测试工具:PyTorch ResNet50 v1.5提供的脚本
- 数据集:ImageNet
实验一:开启高性能缓存加速 vs. 关闭高性能缓存加速
ResNet50 v1.5 batch_size = 128, worker=8
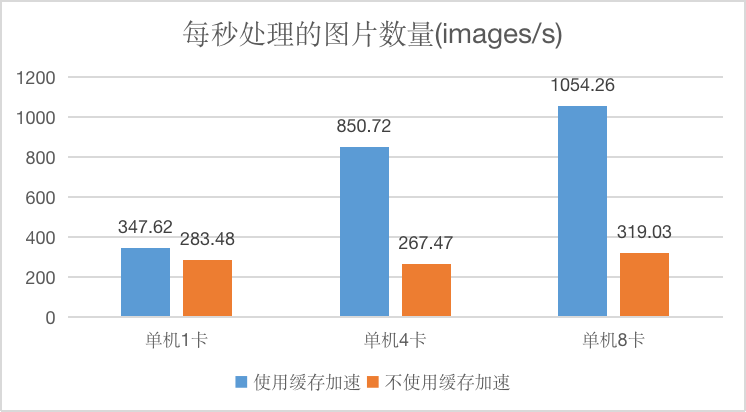
从上图可以看出,在没有缓存的情况下,训练任务处理的图片数并没有随着算力的增加而明显变化,说明已经到了 I/O 瓶颈阶段。而使用缓存后,随着算力的增加,处理的图片数也相应增加。
这证明使用缓存加速后,大大降低了 I/O 开销,同等算力情况下,训练速度也有了很大提升,其中单机 1 卡的训练速度提升了 22.3%,单机 4 卡的速度提升了 218%,单机 8 卡的速度提升了 230% 。
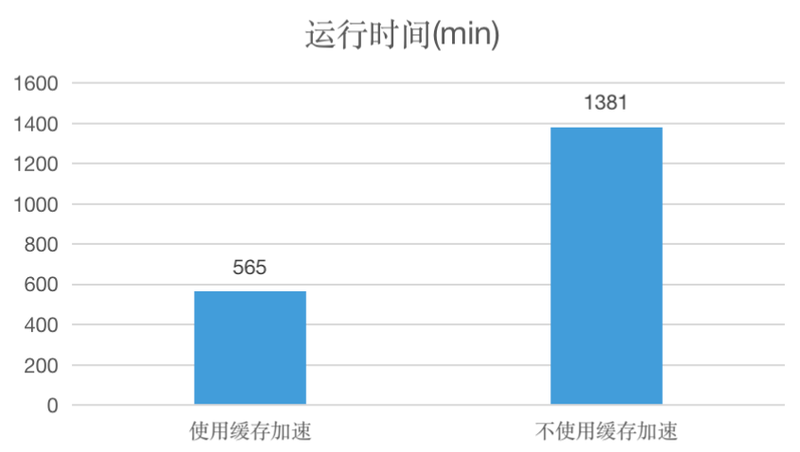
从模型训练时间角度来看,训练时间从未使用缓存加速的 1381 min 降低到 565 min,只用了原来 1⁄3 的时间就完成了模型训练。
第一组实验对比了数据集缓存前后的性能差异,验证了使用高性能缓存方案来加速 iGear 训练任务的必要性。
实验二:高性能缓存加速 vs. FUSE 挂载
当前较为通用的方案是采用 FUSE 的方式来挂载远端的对象存储到本地,提供用户对数据集的访问请求。为了对比目前普通 FUSE 挂载的方案和高性能缓存加速的优化方案,我们设计了第二组实验:
ResNet50 v1.5 batch_size = 128, worker=8
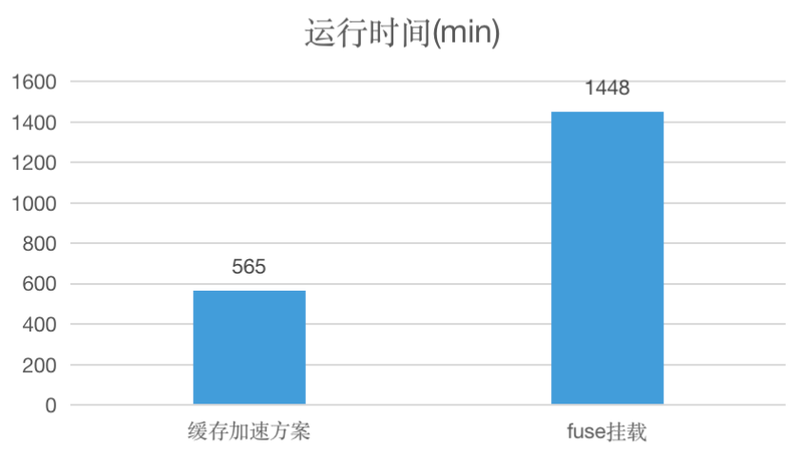
从模型训练时间角度来看,FUSE 挂载方案训练时间为 1448 min,高性能缓存加速优化方案可将训练时间减少到 565 min,将近 FUSE 挂载方案的 1/3。
因此,相比于传统直接使用对象存储,我们的高性能存储在训练速度上和训练时间上都有大幅度的提升。
第二组实验对比了不同方案下的模型训练时间,验证了使用高性能缓存方案来加速 iGear 训练任务的重要性。
结论
面对昂贵且有限的算力资源,我们可以通过高性能缓存加速方案去大幅加速 iGear 平台上训练任务的速度,极大地缩短模型训练时间,同时提高了 GPU 资源的利用率。如果算力进一步提升,收益也不仅仅止步于当前的测试环境。
