














正文
为什么选择 JuiceFS ?
千亿文件规模
在自动驾驶模型训练中,每次训练多达数亿个文件。这对存储系统是很大的挑战。JuiceFS 的元数据引擎支持水平扩展,无单点瓶颈,可管理单个命名空间下千亿级文件和百 PB 数据。
高吞吐、低延迟
在模型训练中,JuiceFS 可提供数百 GiB/s 的读吞吐量,支持每秒读取数十万个文件,并具有毫秒级的元数据响应时间。通过灵活的缓存配置,JuiceFS 能够提供无限的聚合吞吐能力。
成本优势
自动驾驶领域数据增长迅速,JuiceFS 通过对象存储作为底层存储,实现了容量的弹性扩展,并有效降低了存储成本。同时,JuiceFS 的灵活架构有助于降低维护和迁移成本。
相关产品特性
方案:JuiceFS x 自动驾驶行业:百亿小文件、多云架构与成本优化
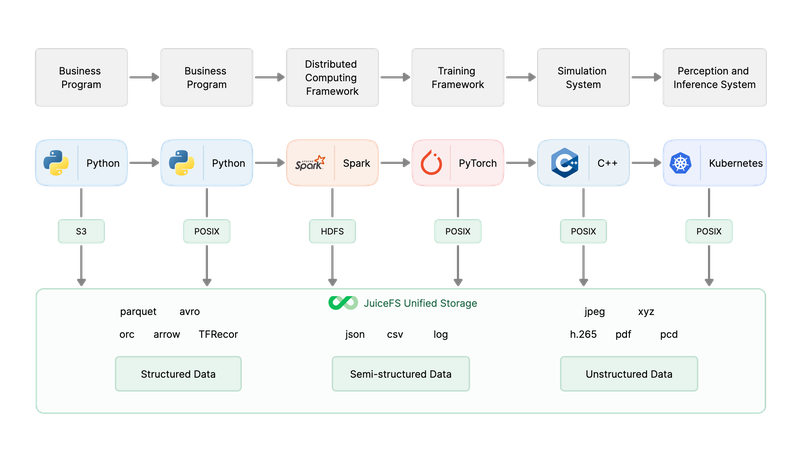
自动驾驶领域的数据量庞大且增长迅速,处理过程包括从视频中提取关键帧,标注关键信息(如红绿灯、道路标记等),最终形成数十亿张图片供训练使用。LOSF(海量小文件)是存储领域的难题,尤其在人工智能的计算机视觉训练中(如自动驾驶、人脸识别等)。本文分享了JuiceFS在百亿规模小文件训练中的应用实践,通过灵活配置缓存提升训练效率,并采用混合云架构下实现降本增效。[详情]
案例:自动驾驶车企如何借助 JuiceFS 打造混合云存储架构?
从 2021 年开始,团队决定自建云原生存储平台,在综合考虑成本、容量弹性和性能等因素后,最终选择了基于 JuiceFS 自建存储底座。目前,存储平台已成功管理百亿文件,IOPS 达到 40 万,吞吐量近 40GB/s,性能水平与原商用存储相当,同时大幅减少了存储成本。[详情]
自动驾驶领域的用户



