














JuiceFS 企业版 5.1 正式发布。作为面向海量文件高性能计算场景的分布式文件系统,JuiceFS 企业版广泛适用于多种 AI 和大数据处理任务,涵盖生成式 AI、自动驾驶、量化金融和生物科技等领域;合作企业包括 MiniMax、智谱 AI、阶跃星辰、小红书、知乎、Momenta、Metabit、深势科技等领先的科技公司。
为了更好地适应企业在多云和混合云架构下的数据管理,支持更广泛的 AI 应用场景,新版本增添了多项新特性,并在系统性能、可观测性方面等进行了全面的优化。
新增重要特性
特性1:支持可写镜像集群,高效管理多云混合云数据架构
GPU 算力资源随着大模型的普及正变得越来越稀缺,尤其是需要进行通用模型预训练的用户,传统的“算力跟着存储跑”的策略需要转变为“存储跟着算力跑”。因此,企业常常需要处理跨地域和多数据中心算力协作的问题。
为了确保数据一致性和管理的便捷性,企业会在特定地区选择公有云的对象存储作为所有模型数据的存储点。当进行计算任务调度时,需要人工介入,如提前进行数据拷贝。这是因为调度系统不清楚当前数据中心具体需要哪些数据,而这些数据又是动态变化的。传统的手动介入、拷贝和迁移方法不仅成本高,而且管理和维护也较为复杂,包括权限控制在内的各种问题都十分棘手。
JuiceFS 企业版镜像文件系统功能允许用户将数据从一个地区复制到多个地区,形成一对多的复制关系,确保数据的一致性的同时,大量减少人工运维工作。在之前的版本中,镜像文件系统的客户端仅支持只读模式,新的 5.1 版本中,我们增加数据写入功能,使得业务可以在任何数据中心以相同的方式访问统一的命名空间,在保证数据一致性的前提下,获得就近的缓存加速能力。
具体而言,开启了数据写入功能的客户端,会同时连接主集群和镜像集群的元数据服务。然后,系统会对客户端的读写操作进行分离。只读操作仍然发给镜像元数据服务,但是写入操作会发送给主元数据服务。客户端的写入请求在得到主元数据服务的回复后并不会立即返回,而是要等到此修改在镜像元数据服务中也更新后才会返回。这样,客户端再去镜像中读的时候,就能读到最新的元数据信息,从而确保了文件系统的一致性。
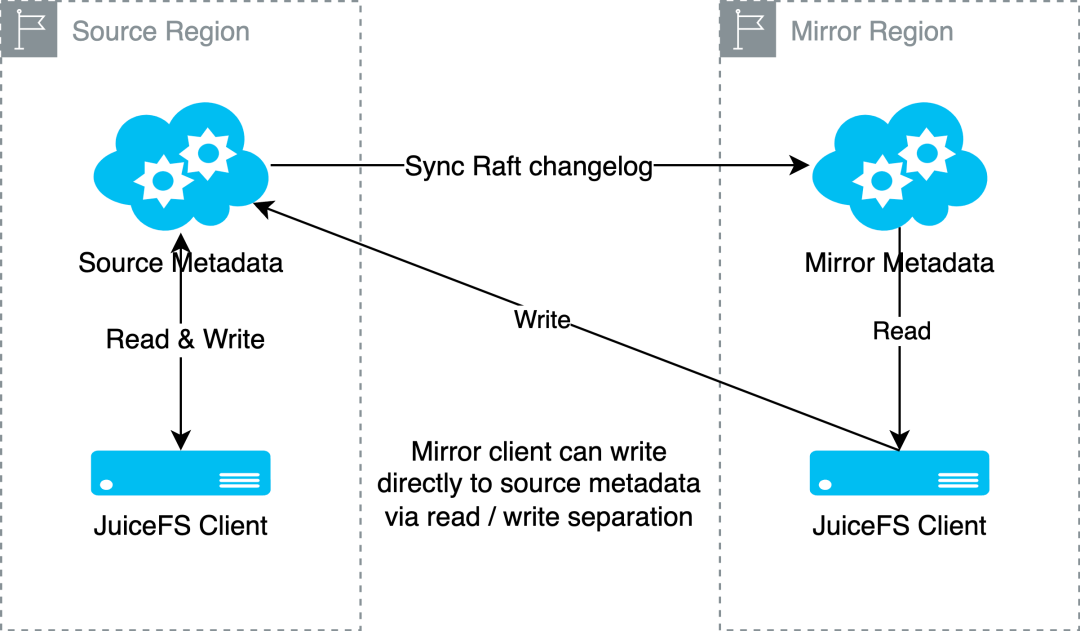
例如,在多站点训练场景中,当各个镜像站点的训练集群分别保存 checkpoint 文件并写入到各自站点的 JuiceFS 时,系统将自动写到主站点文件系统的元数据和对象存储,并同步到其他镜像站点,这一功能简化并加快后续训练任务的 checkpoint 恢复以及推理服务模型加载的流程,同时保证了在镜像集群训练和推理的数据一致性。
特性2:新增 Python SDK,增强 AI 场景文件系统访问能力
在 AI 领域,数据科学家和训练框架广泛使用 Python 语言。此外,JuiceFS 用户通常通过 POSIX 挂载方式访问文件系统,但在一些权限受限的环境中(如非特权容器和大部分 Serverless 环境),由于无法使用 FUSE 模块,POSIX 挂载方式受到限制。为了解决这些限制并更好地支持 AI 场景,JuiceFS 在 5.1 版本中推出了 Python SDK,允许应用程序在进程内直接访问 JuiceFS。JuiceFS SDK 的设计参考了 Python 的内置函数和 os 包中的部分函数,便于用户快速上手使用。
以下是一段代码示例:# 创建 JuiceFS 客户端,其中 'testvol' 是用户的文件系统名称
vol = juicefs.Client('testvol')
vol.makedirs('/dir')
with vol.open('/dir/file', 'w') as fd:
fd.write('helloworld')
with vol.open('/dir/file') as fd:
data = fd.read()
assert data == 'helloworld'
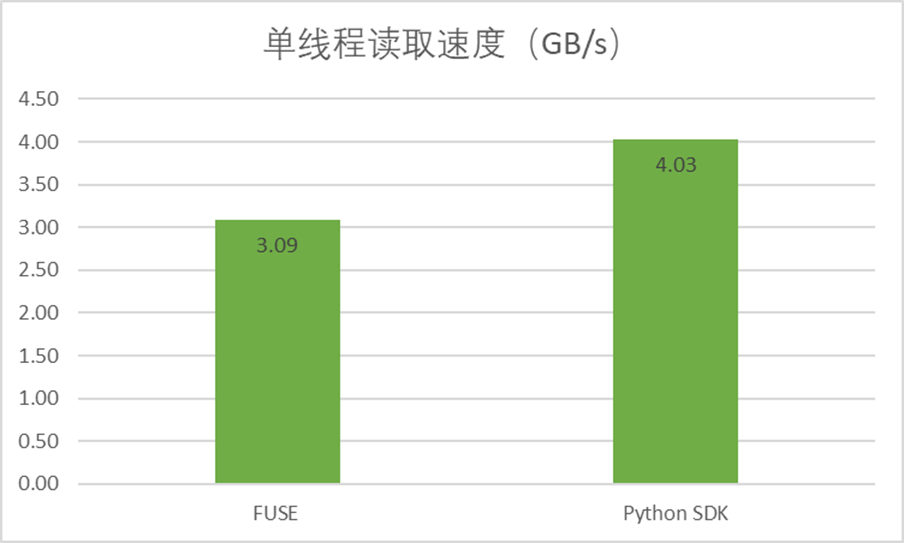
此外,我们希望通过 Python SDK 来克服 FUSE 在某些高性能场景中的性能瓶颈,实现更高效的数据处理。在单线程的读取性能测试中,使用 Python SDK 进行数据读取的速度明显优于使用 FUSE,速度提升超 30%。
特性3:S3 Gateway 升级,多用户场景权限管理更灵活
JuiceFS 通过将文件分块存储到底层的对象存储中,并向用户提供 POSIX 接口以访问文件。然而,当用户需要通过 S3 兼容接口访问这些文件时,他们则需使用 JuiceFS Gateway。在 5.1 版本中,JuiceFS Gateway 加入了身份管理和事件通知等高级功能,以适应多用户环境和复杂的业务需求。
身份和访问管理(Identity and Access Management,IAM):这一功能支持复杂的多用户管理和访问控制,包括用户添加、服务账户管理及其策略继承、临时安全凭证的发放,以及权限的配置和自定义。此外,还支持用户组的管理和匿名访问控制,从而在多用户环境中有效保障数据的安全性和访问灵活性。
事件通知:JuiceFS Gateway 允许使用桶事件通知来监控存储桶中对象的变动,用户可以根据对象的创建、修改、访问或删除等事件来触发自动化操作。支持的事件类型包括对象创建、完成多部分上传、访问头部信息、对象删除等,以及桶的创建和移除。事件通知可以配置以发布到多种目标,如 Redis、MySQL、PostgreSQL 和 WebHooks,进一步增强数据管理的自动化和实时监控能力。
特性4:分布式缓存集群支持备用副本,进一步提升稳定性
分布式缓存集群一直是 JuiceFS 企业版的核心特性之一,当大量客户端频繁访问同一数据集时,该功能可以让客户端共享同一批缓存数据,从而有效提升性能。
在 AI 场景下,模型文件通常达到百 GB 级别,对文件访问的性能提出挑战。JuiceFS 企业版的分布式缓存能够构建大规模的缓存空间,显著提升数据读取速度,特别是在同时启动数千个推理实例时表现尤为出色。此外,对于需要频繁切换模型的 AI 应用场景,例如 Stable Diffusion 的文生图服务,缓存集群可以极大减少模型加载时间,直接改善用户体验。
在之前的版本中,缓存集群中的数据仅有一副本,若某个缓存节点故障,可能导致对象存储访问量短时间内大幅增加。为了解决这一问题,JuiceFS 5.1 版本新增了备用副本的功能。用户可以选择使用更多缓存空间来保存额外的副本,从而在部分节点出现异常时,依然保持较高的缓存命中率。
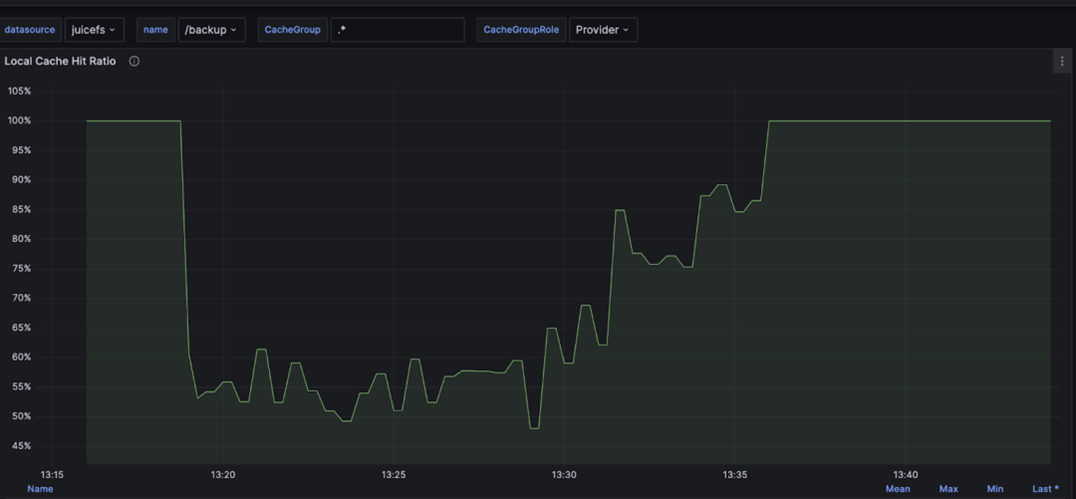
为了能直观呈现该功能对缓存命中率的影响,我们将2个缓存节点中的一个下线,在未使用副本的情况下,缓存命中率出现了大幅的下跌,有一段时间仅在 55% 左右。
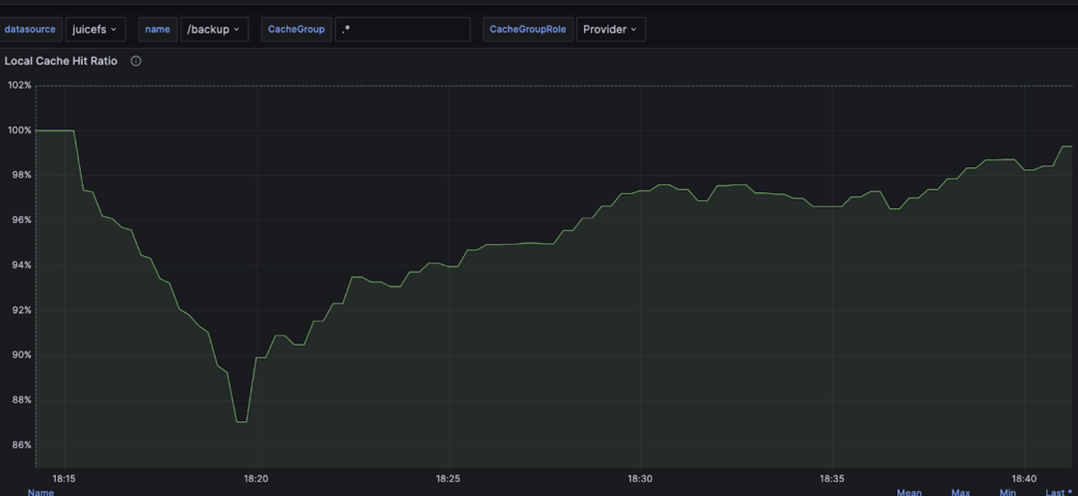
当我们启用缓存副本后再进行同样的故障模拟测试时,观察到缓存命中率能始终保持在 86% 以上,对象存储的穿透流量降低了70%。受缓存空间和性能的制约,并不能保证备份副本一定存在。
此外,在缓存集群扩容时,用户可以为新节点配置备用副本(通常指向已有的缓存节点),也能有效提高扩容期间的命中率,降低对线上业务的影响。
管理功能多项优化
数据管理与更新
- 更新导入文件(
--update和--force-update):允许用户更新已经导入的文件,解决数据同步和版本更新的问题。 - 自动排除分块模式的数据对象:导入时自动跳过 JuiceFS 自身的数据对象,即以 {
volname}/chunks/开头的对象,无须额外配置。 - 跳过回收站直接删除(
--skip-trash):用户管理员可以直接清理数据,而不必等待回收站机制,方便用户快速释放存储空间。 - 主动数据压缩:新增的 compact 命令允许用户主动触发数据压缩,清理对象存储中被覆盖的数据,以减少存储占用,适用于文件经常被修改的场景。
缓存管理
- 无限缓存大小(
--cache-size -1):用户可以将数据缓存大小设为无限,适用于需要将整个磁盘用于缓存的场景。 - 强制缓存对象写入(
--cache-large-write):用户可以明确选择在上传对象时构建缓存。 - 显示缓存位置(
--check):帮助用户了解缓存数据的分布位置,适用于有多节点缓存组的情况。
安全与隐私
- 增强密钥加密(
--encrypt-keys):为访问存储的凭证增加更强的加密,提升安全性,适用于对数据访问安全要求较高的用户。可观测性新版本为用户在使用过程中的各个环节提供了更精细的系统状态监控,帮助用户及时发现问题并优化性能。 -
缓存与错误监控:
- blockcache.errors:跟踪当前进程所有缓存盘的错误(包括超时)计数。
- remotecache.peers:显示当前进程连接的缓存组节点数量。
-
时延监控:新增 p50、p95 和 p99 时延指标,涵盖 FUSE 操作、元数据操作、远程缓存的读写时延。
- warmup 相关监控:包括预热目录、文件、数据块、分块模式文件、导入后的对象等指标,让用户能够详细了解 warmup 的执行过程和缓存使用情况。
- import 相关监控:涵盖导入成功、失败、跳过的文件总量及其对象大小,有助于监控导入过程中的状态和文件更新情况。
