产品初心、开发故事、设计理念
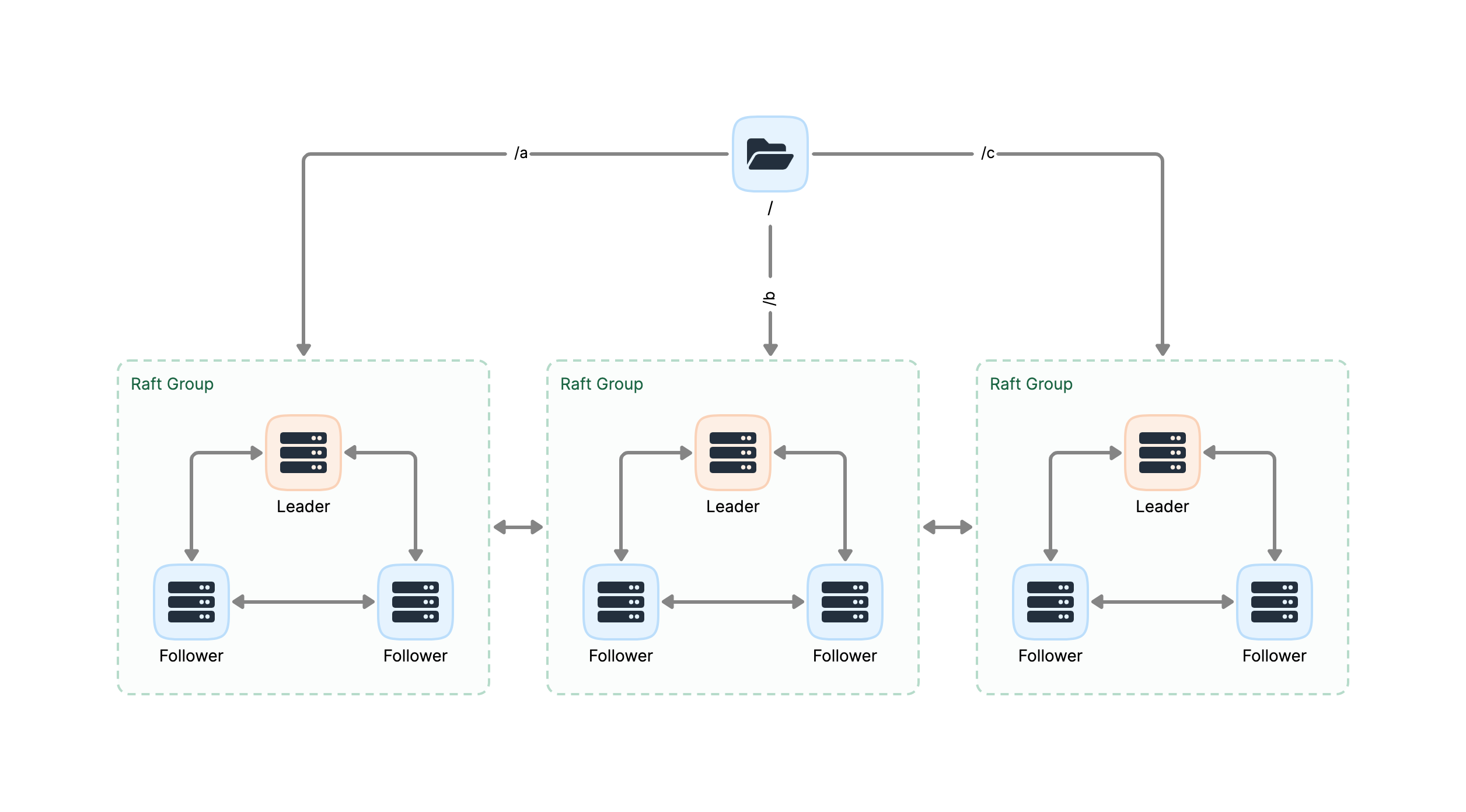
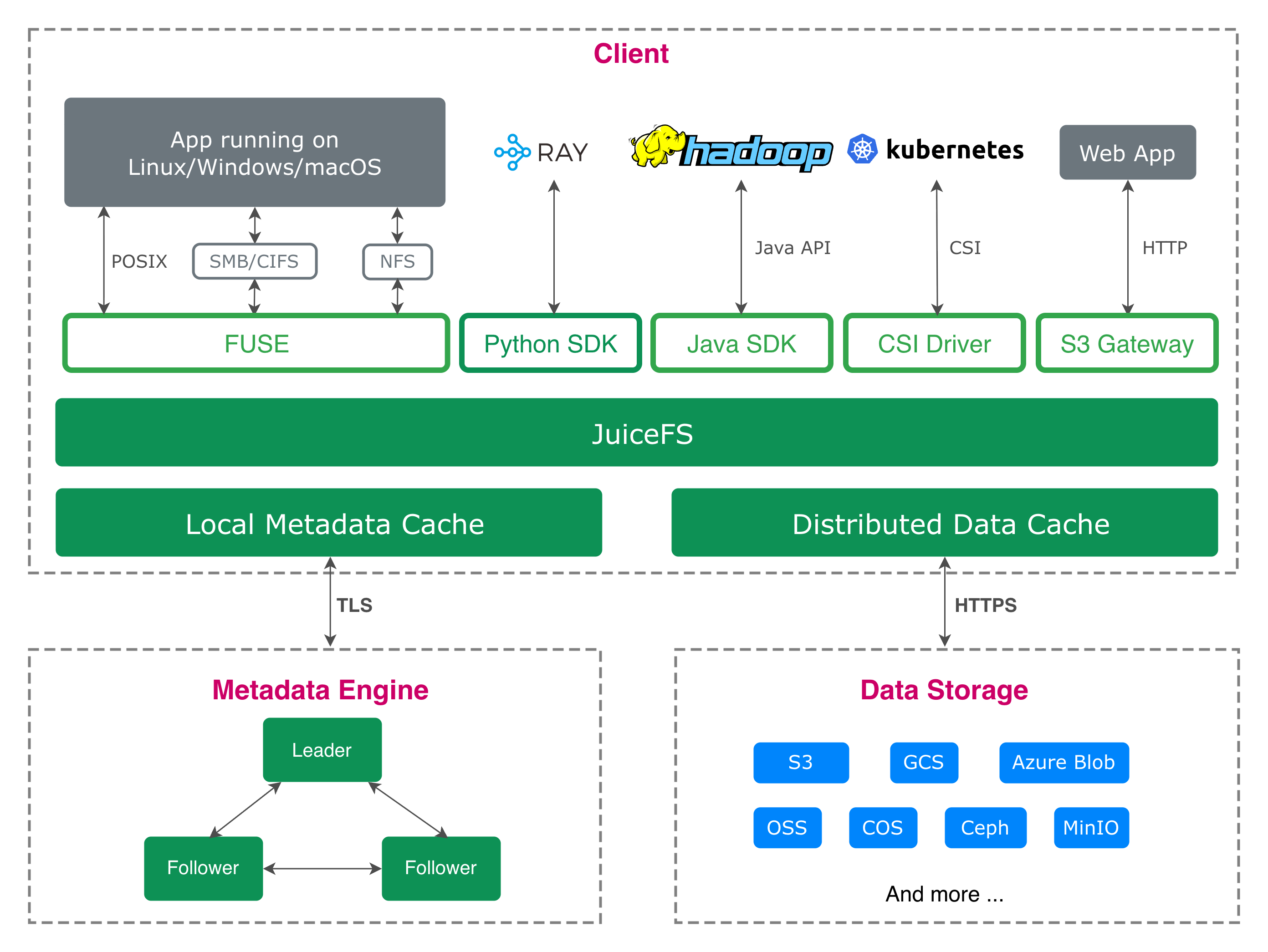
掌握 JuiceFS 企业版与社区版在架构、特性、服务支持上的核心差异。
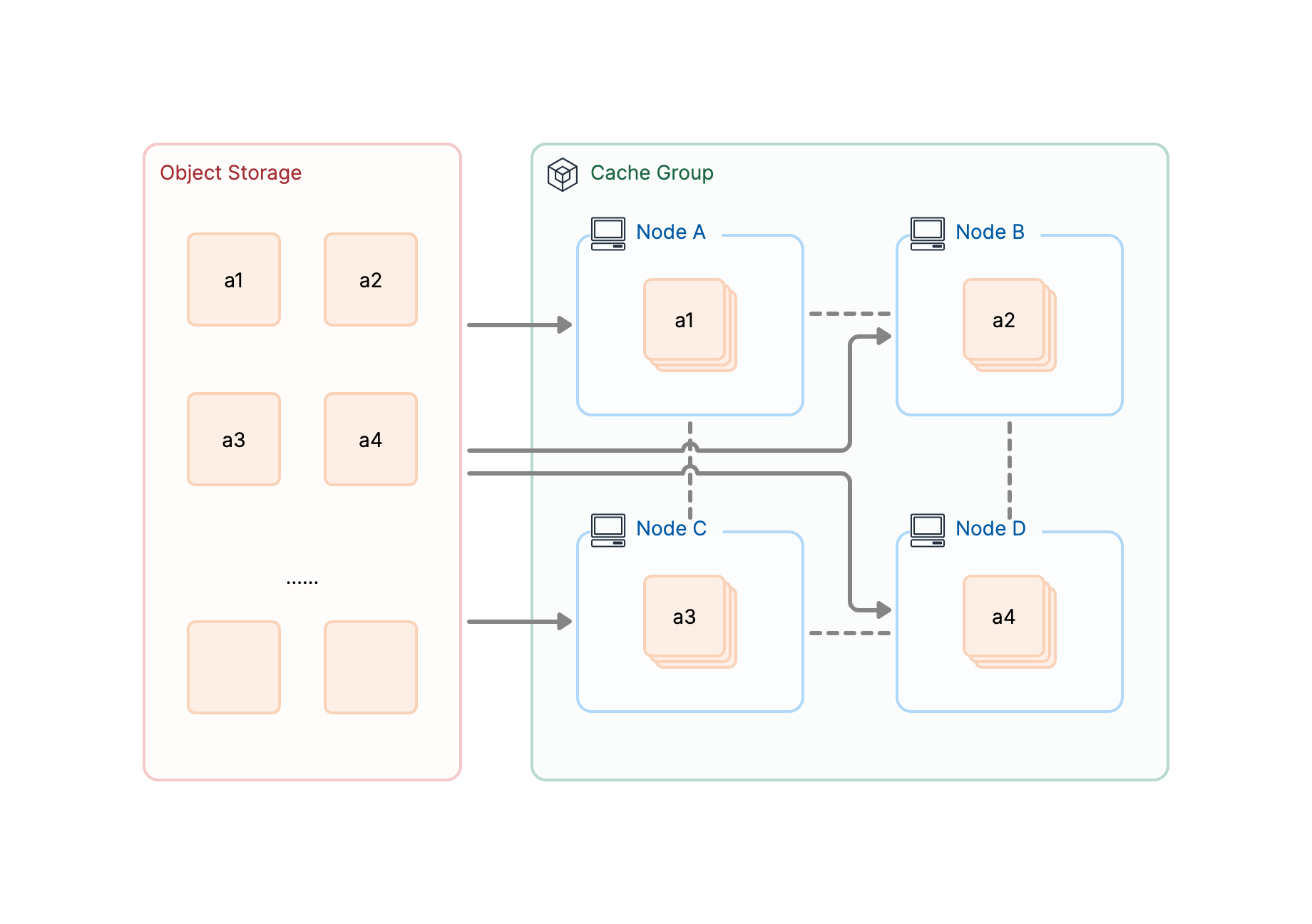
支持上层各类模型在数据清洗、模型训练、模型推理等场景上的高性能数据访问需求。
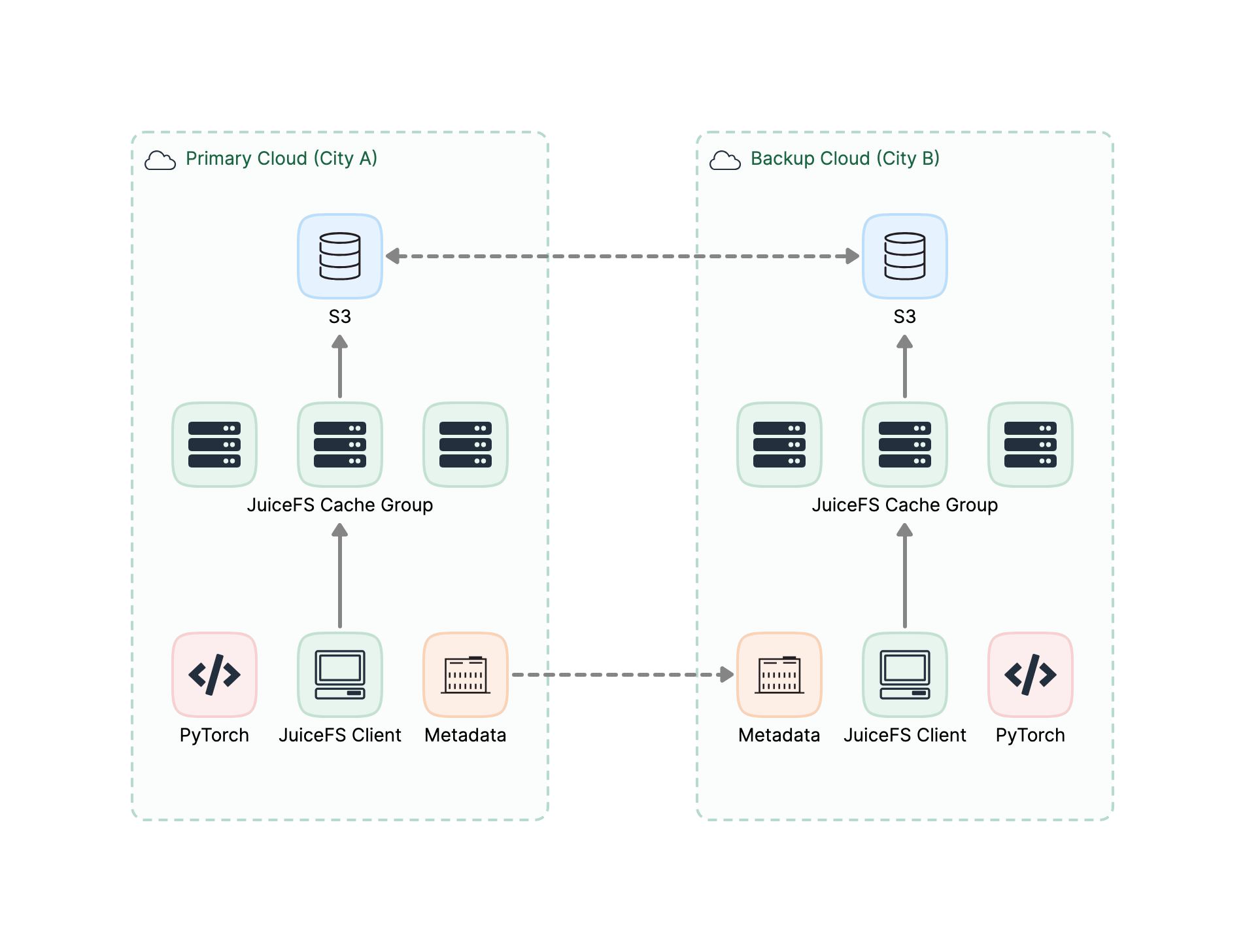
Lepton AI 在 JuiceFS 上存储的文件规模已达到数十亿个文件。