














4 月 7 日,AWS 官方发布了一项新服务——Amazon S3 Files,允许用户无需搬迁数据,即可将 S3 存储桶作为高性能共享文件系统挂载到计算节点上。
这不是业界第一次尝试让 S3 以文件系统方式被访问:从早期的 s3fs,到 AWS 后来推出的 Mountpoint for Amazon S3,再到今天的 S3 Files,S3 “像文件系统一样被访问”这条路,其实已经走了很多年。区别在于,前两者更多是在访问层做文章,而这一次,AWS 终于把共享访问、文件系统语义和托管高性能层真正捏成了一个原生方案。
这也让 S3 Files 成为一个值得单独分析的新选项。对于希望以文件方式访问现有 S3 数据的业务来说,它提供了原生、轻量的方案;但放到 AI 模型训练、大数据分析等更复杂的场景中,它的实际表现究竟如何,仍需要结合其底层实现与运行机制来看。
本文将围绕 S3 Files 的底层实现、性能边界以及与 JuiceFS 的差异展开分析。
01 S3 Files :以 EFS 为高性能层的 S3 原生文件系统方案
从底层实现看,S3 Files 使用 Amazon EFS(Elastic File System)作为托管的高性能存储层,用来承接需要低延迟访问的数据和相关元数据,并在此基础上为 S3 提供完整的文件系统语义,包括一致性、文件锁和 POSIX 权限。
可以把它理解为:AWS 在对象存储之上增加了一层基于 EFS 的文件系统访问面,使原本只能通过对象接口访问的数据,也能以目录、文件和挂载点的形式被计算节点直接使用;而文件系统与 S3 之间的数据变化,则由服务在后台自动同步。
基于这种架构,S3 Files 并不会搬迁全量数据,而是只将当前工作集中的一部分数据按需放到高性能层中;而数据的“Source of Truth”依然保留在 S3 中。
02 S3 Files 如何工作:挂载、导入与同步机制
对 S3 Files 来说,挂载只是开始,真正影响体验的是挂载之后的数据路径:作用域如何确定,首次访问会导入什么,哪些请求会进入高性能层,写入后又会如何同步回 S3。这些机制,也直接决定了后文要讨论的性能边界与成本结构。
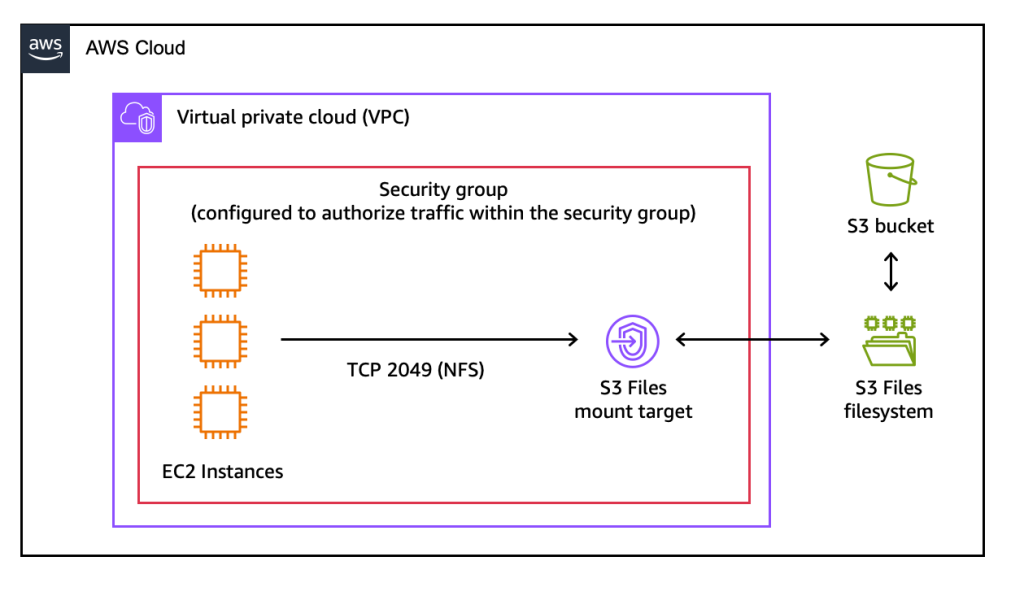
以 EC2 挂载现有 S3 bucket 为例,真正需要看清的不是挂载命令本身,而是挂载之后数据会如何被导入、访问与同步。下面是几个关键的技术细节与步骤。
a) 先确定作用域:导入全量 S3 桶,还是指定部分目录
两者皆可。 S3 Files 支持将整个 S3 存储桶作为文件系统挂载,也支持通过 Prefix(前缀) 限制作用域,
例如只挂载 s3://my-bucket/data/ml/ 目录下。对于包含数千万个对象的庞大 S3 桶尤为重要,因为过大的作用域会增加元数据同步的负担。
在计算节点上使用 S3 Files 时,AWS 提供了定制的挂载客户端 amazon-efs-utils。挂载时使用的并不是存储桶名称,而是 AWS 为 S3 Files 分配的 file system ID。
创建一个本地挂载目录,并使用专用的 s3files 文件系统类型进行挂载:
sudo yum -y install amazon-efs-utils
sudo mkdir /mnt/s3files
sudo mount -t s3files fs-1234567890abcdef0:/ /mnt/s3files
如果只希望访问某个子目录,也可以在挂载路径中进一步指定。但从实践上看,更推荐在创建 S3 Files 时就把作用域限定到明确的 prefix,而不是在一个过大的存储桶上再做后置控制。
b) 首次访问时会发生什么:导入触发方式与大小阈值
S3 Files 并不会在挂载后立即把整个数据集搬入高性能层。它的数据导入由访问事件触发,默认模式是 ON_DIRECTORY_FIRST_ACCESS:当你第一次访问某个目录时,系统会导入该目录下文件的元数据,并将符合条件的小文件数据异步导入 EFS 高性能层。
如果配置为 ON_FILE_ACCESS,则首次遍历目录时只导入元数据,只有在文件第一次被实际读取时,数据才会进入高性能层。这种方式更节省空间和导入成本,但首读延迟也会更高。
这里最关键的控制参数是 sizeLessThan。默认情况下,只有小于 128 KB 的文件才会在导入时进入高性能层;更大的文件通常只导入元数据,内容仍然主要通过 S3 获取。换句话说,S3 Files 优先优化的是小文件和低延迟访问,而不是把所有数据都预热到高性能层中。对于 AI 训练这类以 10 MB 级图片、音视频文件为主的数据集来说,这一点尤其关键:即使完成了目录遍历,这些大文件在默认配置下也未必会真正进入高性能层。
c) 同步周期与冲突解决机制
S3 Files 会在后台自动维护文件系统与 S3 之间的双向同步。S3 侧发生变化后,文件系统视图会随之更新;而在计算节点上的写入,则会先落到 EFS 高性能层,再由后台批量同步回 S3。默认情况下,系统会对修改进行一段时间的聚合,再执行回写。
冲突处理的原则也很明确:S3 始终是 Source of Truth。 如果文件系统侧的修改尚未同步回 S3,而对应对象已经在 S3 中被其他应用更新,系统会以 S3 中的最新版本为准,并将冲突文件移入 .s3files-lost+found-* 目录。
03 S3 Files 的性能边界与成本结构
上一节解释的是 S3 Files 如何运行,这一节进一步讨论的,则是这种运行方式会带来怎样的性能边界与成本结构。高性能层占用、大文件读取路径、写入流转,以及局部更新和目录操作带来的放大效应,是实际选型中最需要重点考量的四个方面。
a) EFS 高性能层的占用、回收与成本
S3 Files 的高性能层并不是按容量上限做 LRU 淘汰,而是按访问时间进行生命周期管理。 默认情况下,已同步到 S3 且 30 天未被读取的数据会从 EFS 高性能层中移除;这一时间由 daysAfterLastAccess 控制,可配置范围为 1–365 天。
这意味着,它的成本取决于有多少数据需要驻留在 EFS 中,以及驻留多久。 如果工作集很大且长期保持活跃,相关费用就会持续上升。
b) 大文件直读与随机读:其实是客户端在“穿透”读取
S3 Files 对大文件的处理,并不是把所有读取都留在 EFS 高性能层中完成。默认情况下,sizeLessThan 的值为 128 KB,它决定的是哪些文件会在导入时把数据放入高性能层;而对于已经同步到 S3 的数据,128 KB 及以上的读取会直接从 S3 流式返回。
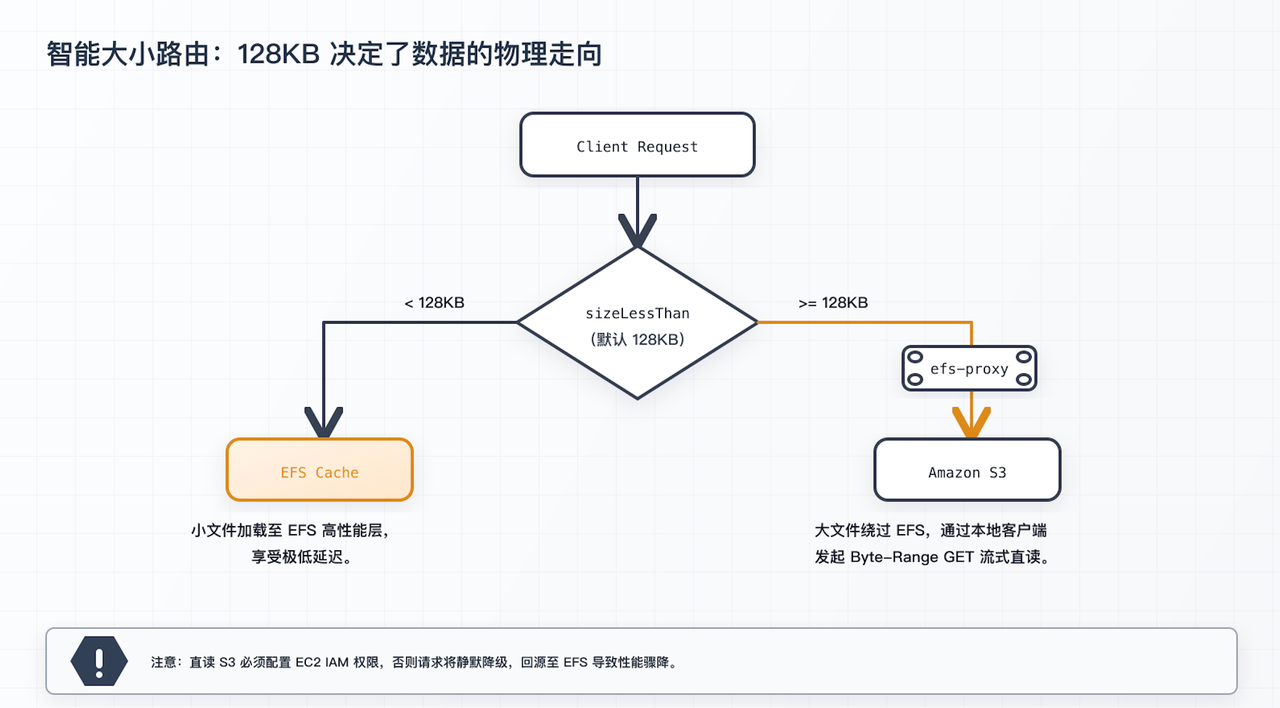
也就是说,S3 Files 的优化重点更偏向小文件和低延迟访问,而不是让大文件读取长期稳定命中高性能层。
这条直读路径依赖于计算资源本身具备读取源存储桶的权限。AWS 官方文档明确要求相关角色拥有 s3:GetObject 和 s3:GetObjectVersion 等权限;否则,客户端就无法直接从 S3 读取数据。
c) 顺序写的代价:大规模写入会引入额外流转成本
S3 Files 的写路径并不是直接落到 S3。所有写操作都会先进入 EFS 高性能层,再由后台同步回 S3。
这意味着,如果你的场景会持续产生大量结果数据,例如顺序写入数百 TB 的训练产物或分析结果,那么这些数据在流经 S3 Files 时,会额外引入两类成本:
- 数据流转成本:写入先进入高性能层,随后再同步回 S3。相比直接写入 S3,这条路径会多出一层中间流转开销。
- 短期驻留成本:数据同步完成后,并不会立刻从高性能层中移除,而是要等到满足过期条件后才会清理。默认情况下,这意味着大批量写入产生的临时数据,可能在一段时间内持续占用 EFS 容量。
以某一区域当前价格为例,写入 EFS 约为 $0.06/GB,后台同步回 S3 的读取约为 $0.03/GB,仅数据流转这一层,每 1 TB 写入就大约会多出 $90 的附加成本。如果这些数据在同步完成后仍然继续驻留在 EFS 中,还会进一步产生对应的高性能层存储费用。
这也是为什么,S3 Files 更适合读取现有数据,而不适合长期承接大规模、持续性的结果写入。
d) 局部更新与目录操作:对象模型带来的放大效应
S3 Files 底层不对数据进行切块,而是尽量保持文件与 S3 对象之间的直接映射。这带来的代价是:一旦涉及大文件的局部随机写或追加写,应用层看起来只是一次很小的更新,底层同步回 S3 时却更容易放大为显著的对象写入与版本开销。
例如,用户通过 S3 Files 在一个 100 GB 的 lmdb 文件中追加了一条 100 KB 的图片 key,应用侧看到的只是一次很小的写入;但这类修改并不会立刻回写到 S3,而是会在大约 60 秒内先做聚合,再同步回存储桶。它不会像块存储那样只改动一个离散块,而更可能放大为对象写入、同步时延和版本存储成本。 文件越大、修改越频繁,这种代价就越值得警惕。
目录重命名同样受 S3 扁平命名空间限制。S3 本身没有传统文件系统中的目录元数据,因此执行 rename 或 mv 时,S3 Files 不能只改一条元数据,而是必须在 S3 侧为目录中的每个文件写入新对象并删除旧对象。对于拥有千万级对象的目录,这会显著拉长同步时间,并增加 S3 请求成本;在同步完成前,文件系统视图与 S3 视图之间还可能暂时不完全一致。
总体来看,S3 Files 的优势在于原生接入、零数据迁移,以及对现有 S3 资产的良好兼容。它的代价则在于:一旦场景转向大文件读取、持续写入、频繁局部更新或大目录操作,性能和成本都会更快被放大。也正因为如此,S3 Files 的优势更适合发挥在轻量共享访问场景中;而在训练、数据生产和大规模分析等重负载场景下,它的代价往往会更早暴露出来。
04 JuiceFS vs S3 Files:两种不同的架构思路
前一节已经看到,S3 Files 的很多边界并非偶然,而是这类方案的共性结果。无论是早期的 s3fs、主打高吞吐读取的 Mountpoint for Amazon S3,还是今天的 S3 Files,它们都尽量保持文件与 S3 对象之间的直接映射,以换取对现有 S3 数据的透明访问能力。
这条路线的优势是透明和低改造,代价则是先天受制于 S3 的对象模型。 这也是为什么目录操作更容易退化为对象级请求,大文件的局部更新也更容易演化为写放大、同步延迟和额外成本。
也正因为如此,JuiceFS 与这类方案的差异,并不是某个功能点或单项指标的差别,而是两条架构路线的根本区别。JuiceFS 不是“把 S3 挂出来用”的访问层,而是构建在对象存储之上的云原生分布式文件系统。 它采用数据与元数据解耦的架构:文件数据存放在底层对象存储中,元数据则由高性能键值数据库独立管理,因此更适合承接训练、分析和数据生产等更重的生产型负载。
为了让大家能更直观地进行架构选型,我们从底层架构到高阶特性,将 JuiceFS 与 S3 Files 进行了全方位对比:
| 对比维度 | JuiceFS | Amazon S3 Files |
|---|---|---|
| 整体架构 | 数据与元数据分离,文件切块后写入对象存储 | 基于 EFS 代理,数据不切块,1:1 动态根据设置的文件大小来映射对象(默认<128KB) |
| 核心成本 | 软件开源免费,主要成本来自对象存储、元数据引擎和缓存资源 | 除 S3 存储外,需额外支付 EFS 存储费($0.30/GB)及数据读写 Sync 费 |
| 读写放大(随机写) | 部分场景极低。数据切块后,局部随机写通常只更新受影响的数据块,无需重写全量数据 | 数据生产场景会很高,大文件随机修改会导致整个对象的重传重写 |
| 冷热分层策略 | 基于容量与访问热度,将热数据自动预热至计算节点的本地盘/内存缓存中 | 基于文件大小与访问时间。小文件(<128K)热数据缓存在 EFS,大文件绕过 EFS 直接读写 S3 |
| 小文件性能 | 依赖全内存的独立元数据引擎(Redis/TiKV 等),更适合大量小文件与元数据操作 | 依赖 EFS 性能与 NFS 协议 |
| 大文件吞吐 | 可结合本地 NVMe / 内存缓存提升吞吐 | 依赖 EFS 网关或 S3 直连性能,大规模并行吞吐与容量配额绑定 |
| 缓存一致性 | 强一致性 (Close-to-open)。由独立元数据服务统一仲裁 | NFS Close-to-open。但遇到底层 S3 和文件系统并发修改冲突时,本地 EFS 数据会被丢弃至 lost+found,S3 强行作为 Truth |
| POSIX 兼容性 | 几乎 100% 兼容。 支持 Hard Links、原子级 Rename、各类锁语义 | 支持 NFSv4.1/4.2 子集。 不支持硬链接(Hard links)、不支持原子重命名 |
| 权限管理 | 支持标准 POSIX 权限、ACL、Extended ACL 等多种鉴权 | 支持标准 POSIX 权限、ACL、Extended ACL 等多种鉴权 |
| 加密与安全 | 传输加密、静态加密、并提供国密支持 | 传输级 TLS 加密、静态 SSE-KMS 密钥加密 |
| AI 场景优化 | 深度优化了 LMDB、Safetensors 等 AI 常见格式的 mmap 读取与本地预热机制 | 无专门针对 AI 格式的底层优化,依赖基础文件流式读取 |
05 小结
没有绝对完美的银弹,只有最适合特定场景的方案。
S3 Files 的面世,填补了 AWS 官方生态中“无缝、免搬迁将 S3 原生转换为文件系统”的空白。它的设计非常明显:S3 对象生态的 100% 格式透明,并针对性优化 AI 场景的小文件(<128KB)的读写性能。
什么时候选择 S3 Files?
如果核心诉求是在不改动现有架构的前提下,让旧应用、Shell 脚本或传统软件直接以文件方式访问现有 S3 数据;或者需要一个通用的共享文件空间,且以只读、小文件、顺序读写为主,那么 S3 Files 会是更自然的选择。它的原生托管、即插即用和零数据迁移能力,可以显著降低接入门槛(但是为了这个便利性可能需要付出高昂的 EFS 存储和同步成本来交换)。
什么时候选择 JuiceFS?
如果业务面向 AI 模型训练、数据生产、高性能计算(HPC)或大数据分析,面临千万级小文件、TB 级大文件随机读写,或对 mmap、缓存命中率和整体吞吐有更高要求,那么 JuiceFS 会更适合。相比 S3 Files,JuiceFS 的数据切块、独立元数据引擎和更灵活的缓存体系,更适合承接重负载和长期运行的生产型和 AI 训推文件系统场景。
