









本文内容来自于 Juicedata 合伙人苏锐在上海举办的 CNutCon 2018 全球运维技术大会上的主题演讲。

大家好,我叫苏锐。今天分享的题目叫《打造运维友好的存储系统》,我们的团队过去一年半的时间里做了一个云上的分布式共享 POSIX 文件系统,说通俗点就是一个无限容量、弹性伸缩、多机共享的云硬盘。在我们最初设计这个产品的时候就定了一个目标:用户体验好。
谈用户体验,首先要明确谁是用户?日常工作中,和存储系统打交道最多的就是运维工程师啊。所以,我们的首要目标就是运维友好。今天我也主要分享下过去一年多在打造 JuiceFS 过程中做了哪些提升运维体验的事情。
回顾过去 20 年,每隔五年就有一次明显的数据爆发,2000年门户网站、2005年 Web2.0、2010年大数据、2015年人工智能、2020年有智能制造、IoT。但无论怎么涨,存储上最关心的的几个方面没变:容量、安全、性能。
容量规划和空间管理
接下来的分享我也会围绕这三方面。容量方面一项很重要的工作就是容量规划和空间管理。安全少不了备份。性能会围绕监控和性能分析。

首先说容量规划,一直都是个两难的问题。少了,业务增长快,不断要扩容。多了,资源利用率低,成本高。
机房时代还要涉及到采购,流程更长。上云了快一些,但是云盘空间仍然要做容量监控,手动扩容,手动做分区扩展等,有些云上还需要重启机器,整个过程也不轻松。

我们就思考云时代,一定要容量规划么? 我们的想法是:不需要。
云最大的优势之一就是按需使用,弹性伸缩啊。云上有这样的存储么?很自然想到对象存储。但是对象存储的 key-value 结构不能满足很多业务场景的需要,需要专门的 API,没有目录数据管理困难。大家不要小看没有目录这个问题,因为对象存储空间无限,用着特别爽,所以大家习惯把各种数据都丢进去,包括一些临时需要的,用完忘了删,我同事在 Facebook 工作时内部就做过一次数据大扫除,猜猜删掉多少无用数据?几十PB。再举一个例子,如果想知道一个 bucket 里都有哪些数据,遍历扫描一下也不轻松,同事在 Databrick 工作时也做过,工作量至少是“周”级别的。
我们认为在单机操作系统中文件管理、使用的体验是更好的。所以,JuiceFS 就完全继承了单机文件系统的使用体验,同时提供了无限容量、弹性伸缩。
回到刚才的例子,如果是文件系统就简单多了,ls 一下,或者 du 列出整体的目录容量分布。但是一个层次很深,文件数量很多的目录用 du 统计也是很慢的。这样的用户体验不好,我们想做个改变,目标有两个,一要快,二要更直观。
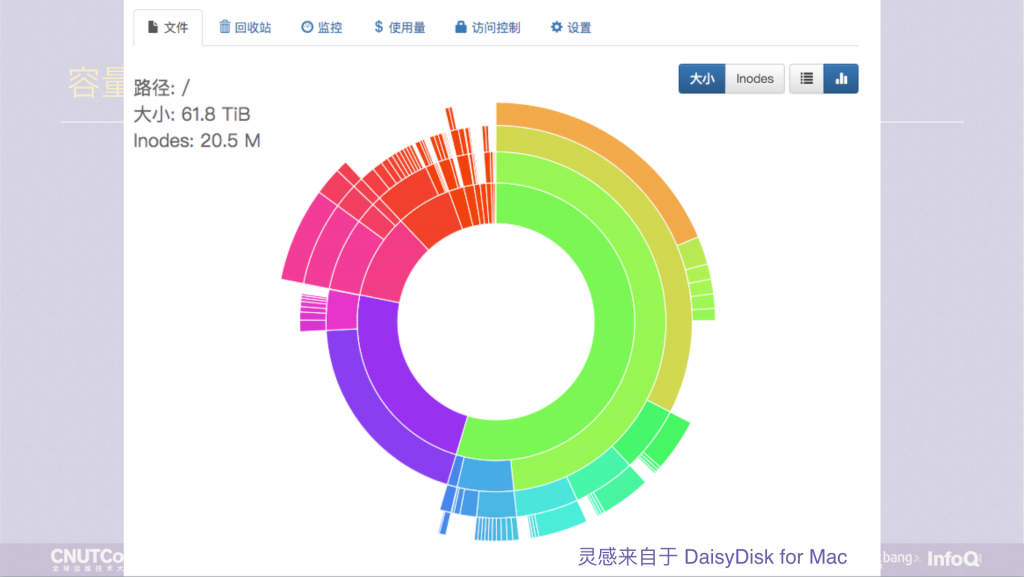
JuiceFS 有一个 Web 管理界面,在上面我们提供了一个图形化的数据分布展示,可以实时展示出当前的容量或 inodes 的分布情况。图片中的圆环有四层,代表顶部的四层目录,每个小色块是一个目录,鼠标放上去会显示目录名,这样一眼就能看出哪里最大。
假设图里红色的部分是个 /tmp 目录,里面有很多的子目录和文件,我要删掉它。用 rm -rf 会出现 du 命令一样的情况,等很久,因为也是层层递归的遍历删除。这种体验不好,我们希望能秒删,所以做了一个 juicefs rmr 的命令,任何目录可以秒删。而且,删错了也不怕,JuiceFS 有回收站,删错了去回收站恢复就行了。

备份
接下来咱们聊聊备份。
以前在机房里,第一个数据安全机制就是 RAID。现在到云上,云硬盘是有多副本冗余的,但并不代表它 100% 安全,AWS 有官方数据:EBS 年损坏率 0.1%~0.2%,意味着如果你有 1000 块盘,每年会坏掉 1~2 块,而是这里的坏掉就是指数据部分或全部丢失。
做备份也不是复制一份到别处就OK了,很多应用的数据备份有逻辑正确性问题,比如数据库。2017 GitLab 线上维护误删了数据库,但是咱们有备份机制,而且是五份备份,结果发现没有一份能用的,就是因为这些备份没有去验证过,到需要做故障恢复的时候才发现。
备份完,验证过的数据就万事大吉了么?还不够,重要的数据还必须做异地备份,2015 年 Google 欧洲的数据中心被雷劈了,经过各种恢复之后仍然有一部分数据丢失了,就是因为这部分数据所有的副本都在这个数据中心,没有做异地备份。

刚才说的备份验证,我展开说一下,图中是一个 MySQL 物理备份的标准流程。在一个 MySQL 从库上用 xtrabackup 做物理备份,先写到本地盘,然后做压缩、加密后上传到对象存储或 HDFS。然后开始验证流程,从对象存储或 HDFS 再下载/拷贝出来,解密、解压,之后用一个新的 MySQL 实例加载这份数据,如果能成功启动,检查和 MySQL 主库的复制状态也正常,则说明这是一份有效的备份。
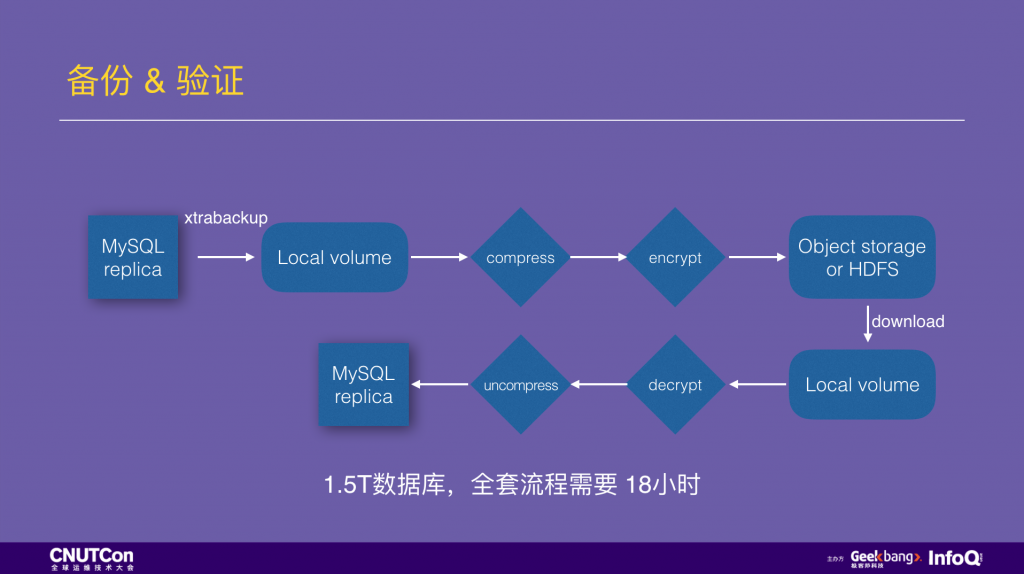
这样的 MySQL 备份是高度串行化的。在生产环境实践中,1.5T 的数据走完上面的流程需要 18 小时。如果换用 JuiceFS 来存储备份,xtrabackup 做的物理备份文件可以直接写入 JuiceFS,这个写入过程中会自动完成压缩和加密,而且是高度并行化的。备份数据写入完成,1 秒创建一个 snapshot,用一个空的 MySQL 实例加载这个快照,就可以验证完毕了。总共需要 2 小时,提升接近一个数量级。(附上详细说明文档和相关代码)
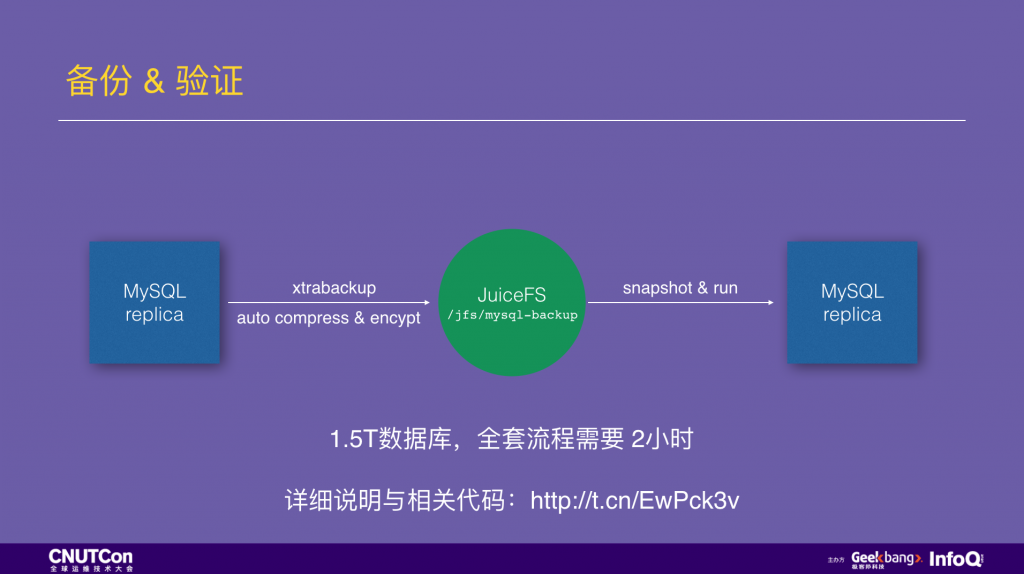
时间的节省在故障恢复时是最宝贵的,前一段 Github 停机 24 小时的事故中,恢复过程里有 10 小时就是用来下载数据库备份,如果他们用了 JuiceFS,就不用这么久了。
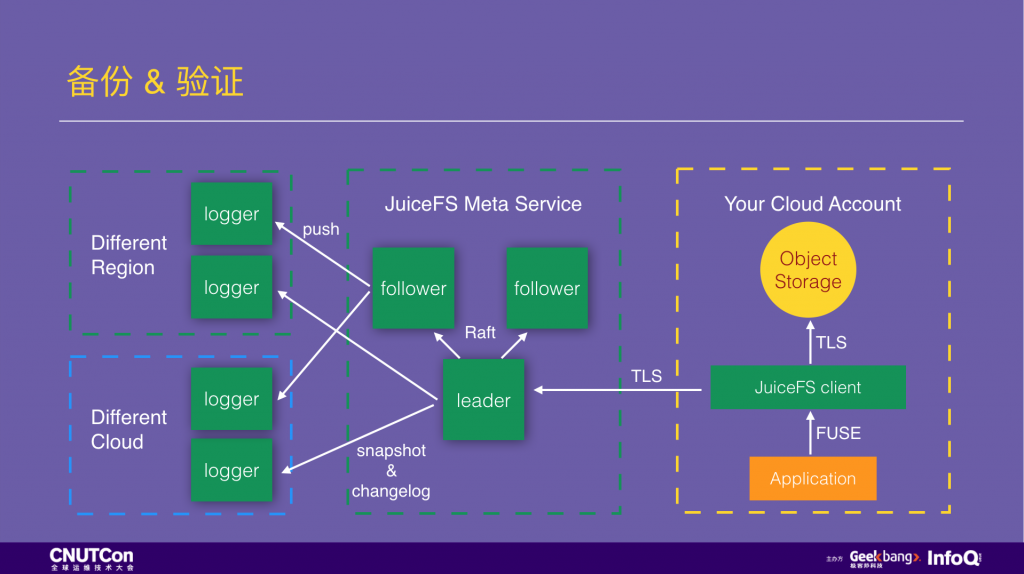
说完 MySQL 的备份,再说一下 JuiceFS 自己是如何做备份的。下面是 JuiceFS 的架构图,数据通过 JuiceFS 客户端写入后,数据内容会存到客户自己云平台的对象存储中,JuiceFS 永远接触不到,同时这部分数据的持久性安全也有对象存储提供,通常是 99.99999999%。Inodes 信息保存到 JuiceFS 的元数据服务中,这个服务部署三个节点,它们用 Raft 协议保证强一致性和高可用,每一个写入事物都需要两个节点 确认才算完成,数据首先保存在内存中,满足高性能访问的需求,同时写一份到硬盘上作为备份,同时有两个节点会各自推送两份事物日志到不同云平台、不同可用区的 logger 中做异地容灾。除了事物日志,元数据服务还会每 8 小时把内存里的元数据信息创建一份快照进行备份。
异地备份
现在来说一下异地备份,假设一家做出海业务的中国企业,服务部署在美国加州,想在国内做一个异地备份。通常的方式是运维同学自己配几个 cronjob 用 scp、rsync 之类的工具做定时同步。使用 JuiceFS 后异地备份是什么样呢?
只需要在 JuiceFS 网站控制台上给 “复制” 功能打个勾,选一下要复制到哪个云、哪个服务区,之后所有写入的数据就会自动复制过去,整个异地备份过程对使用者完全透明,而且在目的地的云平台上也能高性能的访问这些数据。
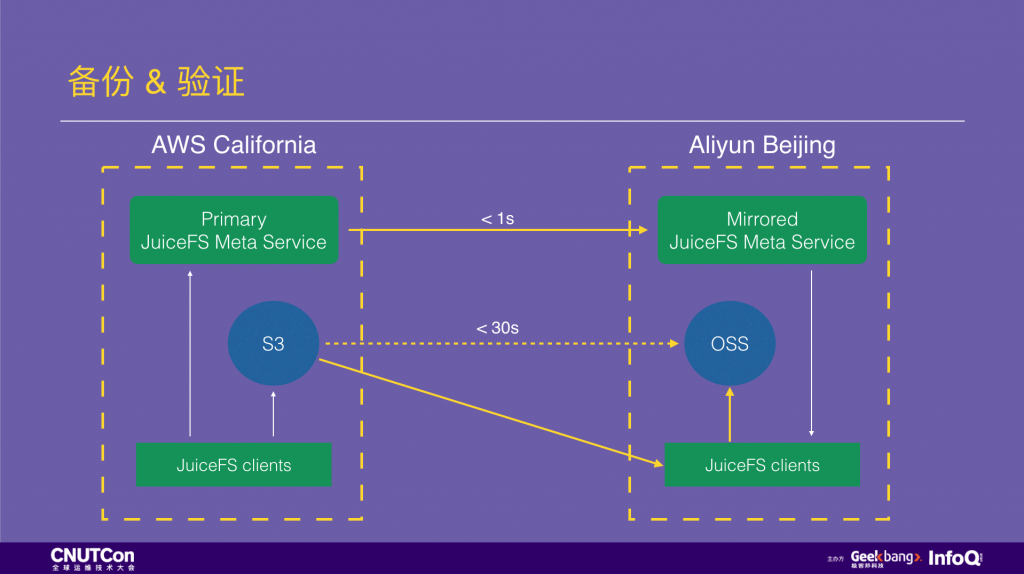
前面咱们提到过对象存储,如果我想给自己的对象存储做个备份呢?我们最近开源了一个工具 JuiceSync,它可以在两个任意的对象存储中做复制,目前支持全球 13 个对象存储服务商。

监控
最后咱们来讲讲监控,先问大家一个问题:运维一个 HDFS 集群需要多少监控指标?下面的幻灯片中只列了一小部分核心指标,而且每次扩容 DataNode 节点还会加一批新指标进来。这些指标的采集、监控配置并不是最头疼的,头疼的是夜里有一个指标报警,就得爬起来处理。

我们认为维护分布式系统不是一件轻松的事情,这些复杂的运维过程也并没有为用户创造价值。所以, 我们把 JuiceFS 做成了一个全托管服务,用户不用部署,不用运维,只要在网站上点击两下,安装下客户端就能使用了。同时,JuiceFS 面向用户也不是一个黑盒子,而是通过 API 的方式把所有的关键指标暴露给用户,对于主流的监控系统,比如 Prometheus,我们还有预定义好的专用 API,只要添加一下就能监控到 JuiceFS 的各项指标了。

对于存储系统,除了监控健康状态,确保它能持续可靠的提供服务,还有一个重要方面是性能。存储系统经常成为性能瓶颈,但是在下这个结论的时候,我们需要能分析出上层应用使用存储系统的方式是否存在不合理的地方。很多时候 IO 瓶颈并不是存储系统的锅,而是应用用错了。
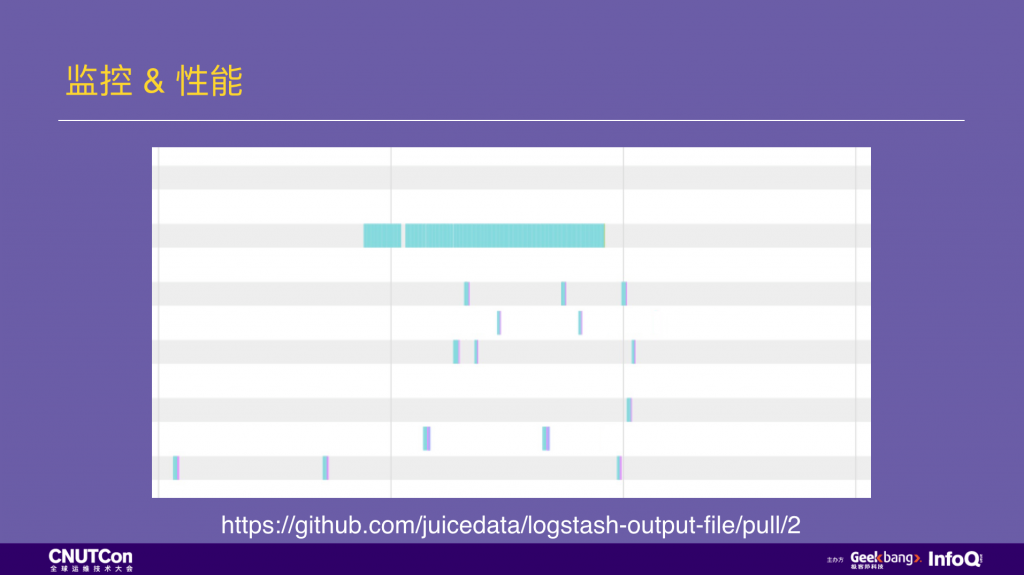
JuiceFS 在性能分析上同样提供了一个图形化的方式,下面举个例子。这是一个真实的客户案例,问题出在 logstash-output-file 这个插件,问题来自于客户说他们日志写入压力太大,JuiceFS 支持不了,出现了写入瓶颈。
用 JuiceFS 图形化的性能分析工具分析一段时间的读写特征。这里显示的是所有文件系统上的系统调用,当时这个文件系统只有 logstash 在写入,所以也很简单的做系统调用的隔离,确保不会混入其他无关信息影响分析。
在下图中,每一行代表一个线程,每一块有颜色的地方就是一个文件系统访问,不同颜色代表不同的系统访问函数。
从图中我们可以看出两个问题,第一是色块里绝大多数是蓝色的,蓝色是代表了 lookup 操作。另一个问题是对 JuiceFS 的操作已经沾满了整个进程时间,确实说明存储环节是瓶颈。

根据第一问题我们想为什么绝大部分的调用是 lookup?应用层在做什么?带着这个问题我们查看 logstash-output-file 的源代码。发现这里是 logstash 在写文件,lookup 调用是每次写文件之前要先判断一下文件是否存在,在 POSIX 中这个判断会按照目录层级一级级的查找,产生了大量的 lookup 操作。这里的问题是 logstash-output-file 虽然开启了写入缓存,但仍然会在每次写入新数据时检查文件是否被删除。这种频繁判断文件是否存在的操作非常低效,跟它的写入缓存并不一致,于是我们做了一个修改:把数据写入的 buffer 由它自己管理(而不是 JRuby的默认 buffer),这样可以只在要将数据写入文件时才做是否被删除的检查,大大减少了它的调用频次,提升了整体性能。
做完这个修改后的效果如下图,写文件的操作合并在一起,整个进程已经不再被 IO 操作沾满,存储已经不再是瓶颈。这个改进请见图中的 Pull Request 链接。

但是还看到一个问题,在多个线程中,IO 操作并没有并行,线程之间在互相等待,这是为什么呢?我们有个假设,程序中用了全局锁,导致了上述情况。
带着问题,我们继续看 logstash-output-file 的源代码,果然找到一把全局锁,并且通过分析判断这把全局锁粒度过大了。我们做了修改,将锁粒度降低到文件级,再运行应用,截取到下图这一段性能日志,可见多个线程之间的 IO 操作已经可以并行起来,性能得到进一步提升。这里对锁的修改我们也提交了 Pull Request。
以上是我今天要分享的内容,再让我们回顾一下。
在容量方面,JuiceFS 提供了弹性容量,不再需要容量规划。同时提供完全兼容 POSIX 的使用体验,有目录结构、文件权限、所有 Linux 命令行工具和脚本都兼容等体验上的优势,还提供了图形化管理、优化的命令来加速执行时间。
安全方面,JuiceFS 非常适合做各种应用的数据备份,可以简单的完成备份验证,可以全透明的做压缩、加密、异地备份容灾等,效率比以往提升一个数量级。
性能与监控方面,JuiceFS 提供了监控 API 来让用户了解各方面指标,还提供了图形化的方式做性能分析,让性能优化工作变得更加简单直观。

今天的分享就到这里,谢谢大家。




