









本文根据 Juicedata 技术专家高昌健在 DataFunSummit 大数据存储架构峰会所作主题演讲《JuiceFS 在数据湖存储架构上的探索》整理而成,现场视频可点击这里查看。
大家好,我是来自 Juicedata 的高昌健,今天想跟大家分享的主题是《JuiceFS 在数据湖存储架构上的探索》,以下是今天分享的提纲:
首先我会简单的介绍一下大数据存储架构变迁以及它们的优缺点,然后介绍什么是 JuiceFS,其次的话会再重点介绍一下关于 JuiceFS 和数据湖的一些结合和关联,最后会介绍一下 JuiceFS 和数据湖生态的集成。
大数据存储架构变迁
纵观整个大数据存储架构的变迁,可以看到有非常明显的三个阶段:第一个阶段就是从最早的 Hadoop、Hive 等项目诞生之后,有了数据仓库(Data Warehouse)的概念。随着数仓的逐步发展,同时有了云的诞生,对象存储的诞生,以及大数据与 AI 的时代到来之后,数据湖(Data Lake)这个概念就被凸显了出来。最近两三年有一个新的概念,或者是说到了一个新的阶段叫做湖仓一体(Lakehouse)。传统数仓大家都比较了解,今天会着重看一下后面这两个阶段,也就是数据湖和湖仓一体。
为什么要有「数据湖」?
数据湖很重要的一个诞生契机,其实是解决数据孤岛(Data Silos)问题。产生数据孤岛的根本原因,来自于不同的业务或者不同团队,因为一些历史原因造成了数据之间其实是一个孤岛或者互相之间没有办法去做连接。
随着不同业务的引入,在企业内部数据的格式会变得越来越多样,除了最早的传统的结构化数据以外,会发现还有很多半结构化的甚至是非结构化的数据。这些半结构化和非结构化数据也希望能逐步引入到整个公司的数据管理或者运维里面来,传统数仓的架构或者说存储的模型此时就没有办法去满足这种多样性的数据格式的存储需求。
然后第三点是分散的数据管理,这点其实是跟第一点数据孤岛也是有关联的。因为你的数据是分布或者分散在很多不同的地方的,数据的管理或者一些权限的控制上,也会相对的分散。这个时候你如果要去针对不同的业务与不同的团队去做管理,也会是一个比较大的工作量。
第四点是存储与计算的耦合(简称「存算耦合」),也是跟传统 Hadoop 的架构有关,传统的像 HDFS、YARN 的架构,是针对存算耦合架构来设计的,但在对于现在基于公有云的大数据架构来说,这种存算耦合的架构就比较缺乏弹性了,不管是在运维的弹性上,还是对成本的控制上。
最后一点随着 AI 行业的发展,在机器学习或深度学习这块的数据加入进来之后,也是希望能够在数仓或者说整个大数据架构里面为基于机器学习或深度学习的业务提供更好的支持。不仅是存储数据,例如还需要对接深度学习的框架,所以就要提供一些接口的支持,比如 POSIX 等对算法工程师更友好的方式,而不是传统的通过 SQL 或一些其它的方式来提供给业务团队。
什么是「数据湖」?
这里引用维基百科上的一句简介:
A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files.
其中一个比较重要的定义是 natural/raw format(原始格式),跟传统数仓比较大的区别是我们会倾向于把数据以原始的格式先存到数据湖里面来。数仓其实也还是存在的但它是一个后置的过程,为了实现这样一个数据湖,最根本的是需要一个足够便宜且能够支持海量数据规模的底层存储。目前看下来在云上的话,对象存储是一个非常好的选择,它既做到了便宜可靠,同时也能够支持海量的数据。但对象存储也不是一个绝对的方案,后面会详细地去做一些比较。
简单来说就是「Everything in one place」,意思是所有数据都先放到数据湖里面来,你要做数仓也好,做一些其他的后置 ETL 也好,那是下一个阶段的事情,但前提是要把所有的数据都放在一起。「后置 ETL」的意思是说 ETL 依然存在也依然需要,只是它变成了一个后置的流程。因为用到了对象存储,以及存算分离的架构,所以在整个的架构设计上也会更加的云原生 。
为什么要有「湖仓一体」?
在整个数据湖的架构里面数仓依然是存在的 ,但是它在整个 pipeline 的阶段被后置了,必然就会带来一些数据的滞后。同时传统的像 Hive 这些组件,其实你要做到近实时或者基于 Hive 来做增量的数据更新是比较麻烦的,特别是如果你要把分区(partition)的时间窗口缩得很短的话。
之前提到的机器学习和深度学习的结合问题,在数据湖阶段也还是存在。虽然有了数据湖,但对于整个深度学习这块的支持也还是不太够,所以在湖仓一体这个阶段依然是需要解决的一个问题。
然后就是数据重复拷贝和重复 ETL,因为 ETL 是后置的,数仓也是后置的,所以有很多数据有可能是会从湖里面再同步或复制到数仓里面,就会带来一些数据的重复拷贝或者重复 ETL,重复两次甚至三次都有可能。
最后就是基于对象存储这样的存储类型,希望能够提供更多高级特性的支持,比如 ACID 事务、多版本数据、索引、零拷贝克隆等。
什么是「湖仓一体」?
湖仓一体有一些关键的因素,其中第一个是需要一个统一开放的底层文件格式,这个格式比如说可以是 Parquet、ORC 等业界公认的格式。第二点我们需要一个开放的存储层,具体来讲是类似 Delta Lake、Iceberg、Hudi 的一些开源组件。第三点是要有开放的计算引擎集成,不管你使用哪一种存储,都需要能够支持上面多种多样的计算引擎,而不是把用户或者业务团队限定在某一个引擎里面,不管用 Spark 也好,Presto 也好,用其它的商业引擎也好,可以做到多样化的支持。最后一点就是和深度学习框架的结合,这里拿 Uber 开源的 Petastorm 项目举例,Petastorm 是为 TensorFlow、PyTorch 等框架提供 Parquet 格式读写支持的组件,目前初步做到了一些对深度学习框架的支持。
JuiceFS 简介
JuiceFS 一个开源的云原生分布式文件系统,为云环境设计,提供完备的 POSIX、HDFS 和 S3 API 兼容性。使用 JuiceFS 存储数据,数据本身会被持久化在对象存储(例如 Amazon S3),相对应的元数据可以按需持久化在 Redis、MySQL、TiKV 等多种数据库中。目前在 GitHub 上已经有超过 5000 个 star,也有超过 50 个外部贡献者来一起参与这个项目的维护。
JuiceFS 从架构设计上来说,更倾向于开放结合的态度。众所周知文件系统里面最重要的一个组件就是元数据引擎,JuiceFS 希望能够结合已有的开源项目,比如说 Redis、SQL 数据库、分布式 KV 等,把它们纳入进来作为整个 JuiceFS 架构里面的一个组件。在数据存储方面,目前 JuiceFS 也已经支持超过 30 种底层的存储系统,除了最主要的对象存储,还支持像 Ceph、MinIO、Ozone 这样开源的组件。同时 JuiceFS 也是一个跨平台的组件,在 Linux、macOS、Windows 上也都可以直接原生的运行。
在 Kubernetes 的环境里,JuiceFS 提供了原生的 CSI Driver,可以直接通过 Kubernetes 的 PV 或 PVC 的方式直接 mount 到 pod 里。最后就是一些更高级的特性,比如说数据缓存、加密、压缩、回收站、配额等,目前 JuiceFS 的开源社区里也有很多的团队和公司已经在生产环境中使用,例如小米、理想汽车、Shopee、知乎、火山引擎、网易游戏、携程等。
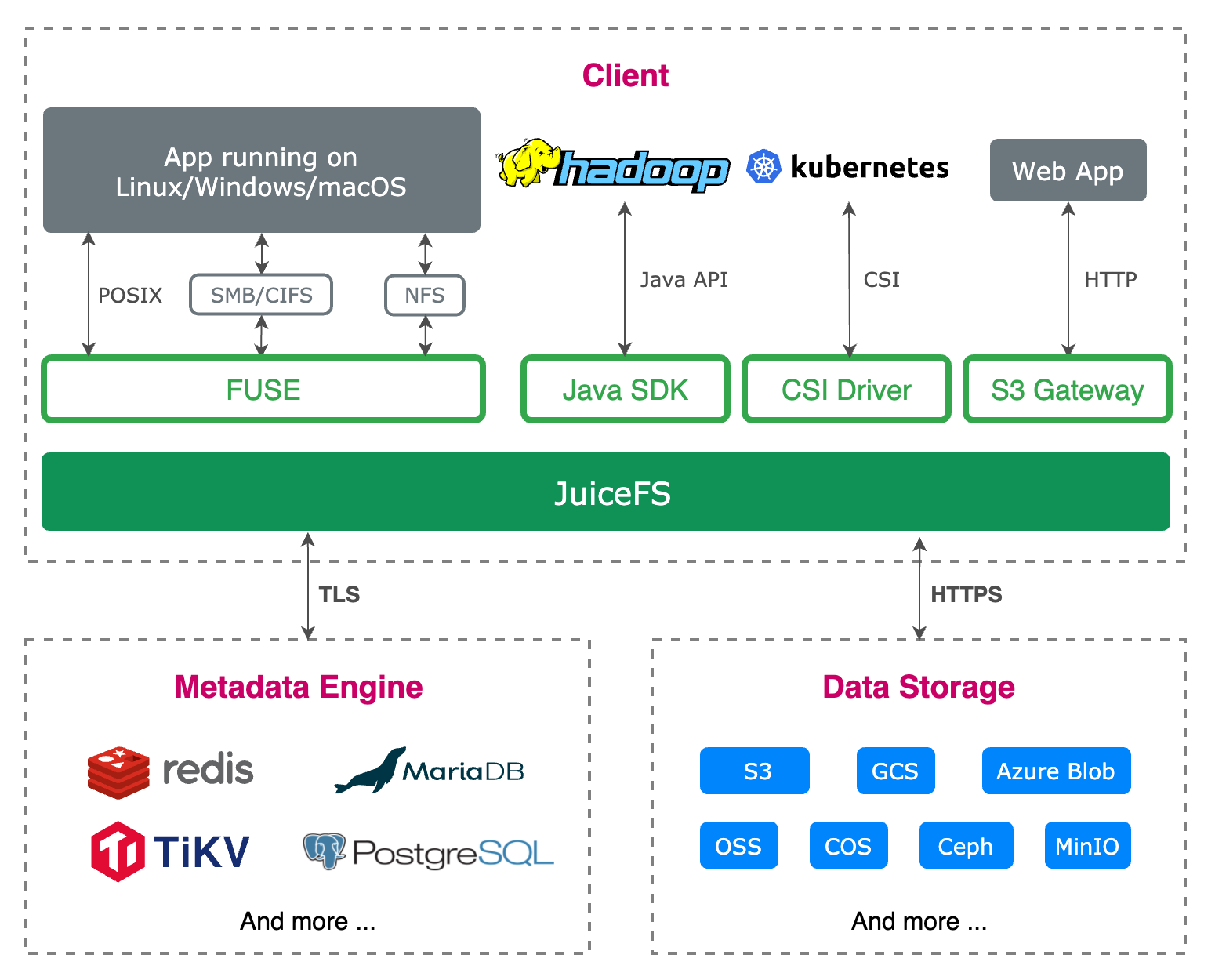
上图主要分了三块,一个是 Metadata Engine 也就是文件系统的元数据引擎,所谓元数据引擎就是要存储整个文件系统的元信息,比如文件的名字、大小以及权限信息和目录结构等。这里 JuiceFS 更希望和一些成熟的开源的并且大家日常会使用到的数据库做结合,所以上图列举了一些常用的数据库,都可以作为 JuiceFS 的元数据引擎。
然后 Data Storage 部分是 JuiceFS 底层需要依赖的一个数据存储,我们没有重复造轮子,而是选择了站在已有存储的肩膀上。云上的话对象存储是一个非常好的基础设施,大家都知道它有很多好处,例如低成本、高吞吐、高可用性。如果你是在 IDC 或者机房里面也可以有类似的基础设施提供,JuiceFS 作为使用方,可以直接把这些 Data Storage 对接上,并原生地把它作为整个文件系统的底层数据存储。
再上面的话就是客户端(Client),也就是 JuiceFS 的用户会直接接触到的这部分。通过不同的接口,让用户在不同的环境与不同的业务里面都可以访问到 JuiceFS,用户不用担心在不同的使用环境下会出现一些不一致的情况,只需要关心用哪个最熟悉的接口去访问就好了。
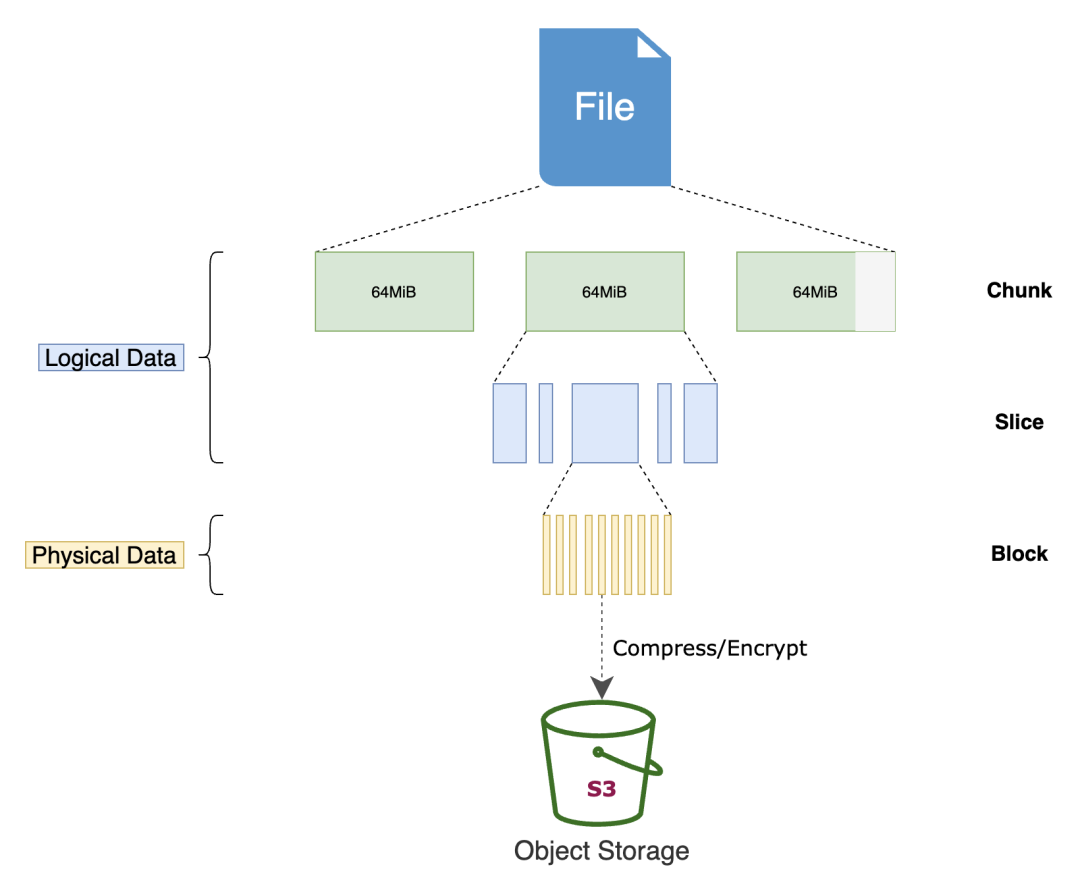
上图展示的是一个文件通过 JuiceFS 最终存储到对象存储上的一个流程,JuiceFS 会对一个文件做三个级别的拆分,就是最右边这一列的 Chunk、Slice、Block 三个级别。
首先 JuiceFS 默认会按照固定的 64MB 大小,把一个文件按照这个粒度来拆分成很多的 Chunk,然后每个 Chunk 内部的话又可能会有很多这种不同个数、不同长度的 Slice 来构成,每个 Slice 最终又会由很多定长的 Block 来构成。Block 的大小用户是可以配置的,默认情况下推荐使用 4MB 作为 Block 的大小。最终 Block 经过可选的比如压缩或者加密之后,再上传到对象存储里面,所以如果你直接去看对象存储里存储的数据的话,是不会看到原始文件的。比如说你的原始文件可能是 1G 大小的文件,但其实在对象存储上去看的话,会看到很多小的 4MB 的 Block。
需要特别指出的一点是如果文件本身就是小于 4MB 的,比如一张图片只有 100KB,这时 JuiceFS 是不会补齐到 4MB 的,还是会按照它原始的大小,文件是 100KB 最终存储到对象存储上也还是 100KB,不会补齐,不会占用额外的空间。
最后讲一下 JuiceFS 为什么要对文件存储格式去做分级。首先是需要基于对象存储来支持一些高级的特性,比如说随机写入;其次对于不同的读写访问模式,通过分块之后也可以提升性能,比如说在并发写入或并发读取上能够做到更好的性能优化。
JuiceFS 与 HDFS、对象存储的比较
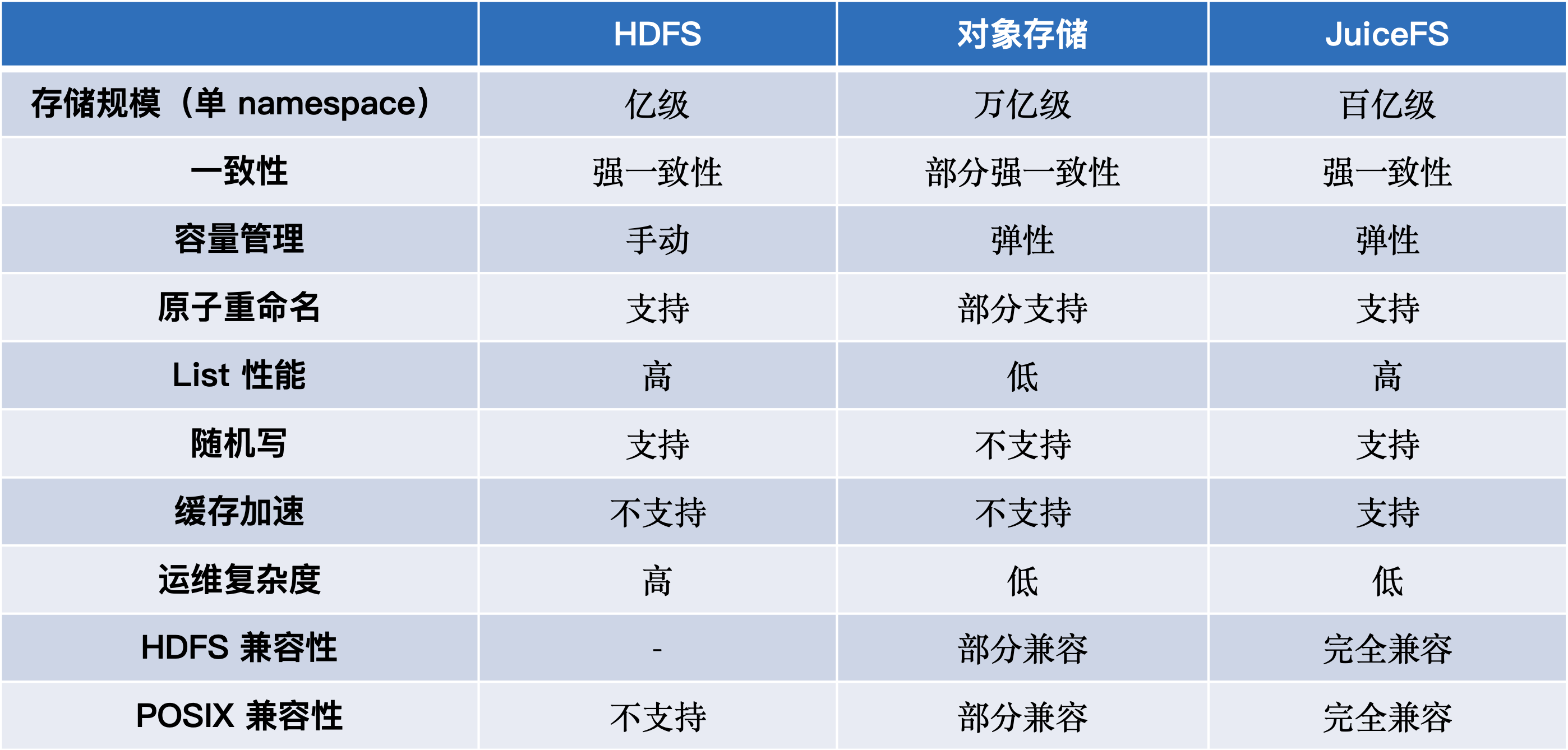
从存储规模上来说,其实大家都知道 HDFS 的 NameNode 在单 namespace 上是有存储上限的,一般来说到亿级别这个量级就差不多了,但如果你要存储更多的数据,你可能要做 federation 或者说一些其它的方式去扩展。对于对象存储和 JuiceFS 来说,是可以非常轻松的支撑到百亿级甚至更大的存储规模。
然后在一致性上对于文件系统来说,之前不论使用 HDFS 或者说其它的文件系统,默认情况下,都是希望文件系统提供的是强一致性的保证。但是因为对象存储的兴起之后,会发现最终一致性反而会是一个更常见的情况。不过目前也有一些对象存储,比如 S3 已经支持了强一致性。
在容量管理上 HDFS 是需要手动扩缩容的方式,所以你没有办法在云上做一个非常弹性的容量管理,但是反观对象存储和 JuiceFS 的话,在容量管理上是可以做到非常弹性的,按量付费,大幅节约了存储成本。
其它几个特性对于大数据场景也是比较关键的,比如说原子重命名、List 性能、随机写、并发写等,这些特性对于传统的 HDFS 都是默认支持的,但对于对象存储来说,有些特性它是部分支持的,有些特性完全无法支持。因为 JuiceFS 本身是一个完备的文件系统,所以这些特性都是具备的。
缓存加速这块,其实在 HDFS 或对象存储上目前都还是不具备的一个功能,需要结合一些外部组件来实现,但 JuiceFS 本身已经内置了这个特性。
最后就兼容性来说,对象存储可以用一些社区的组件去通过 HDFS 的 API 访问,但目前暂时无法做到完全的兼容。包括 POSIX 这块,虽然你可以用到如 S3FS 或者一些其它组件以 POSIX 的接口来访问对象存储,但它也只能达到一个部分兼容的状态。对于 JuiceFS 来说是完全兼容 HDFS 和 POSIX 接口的。
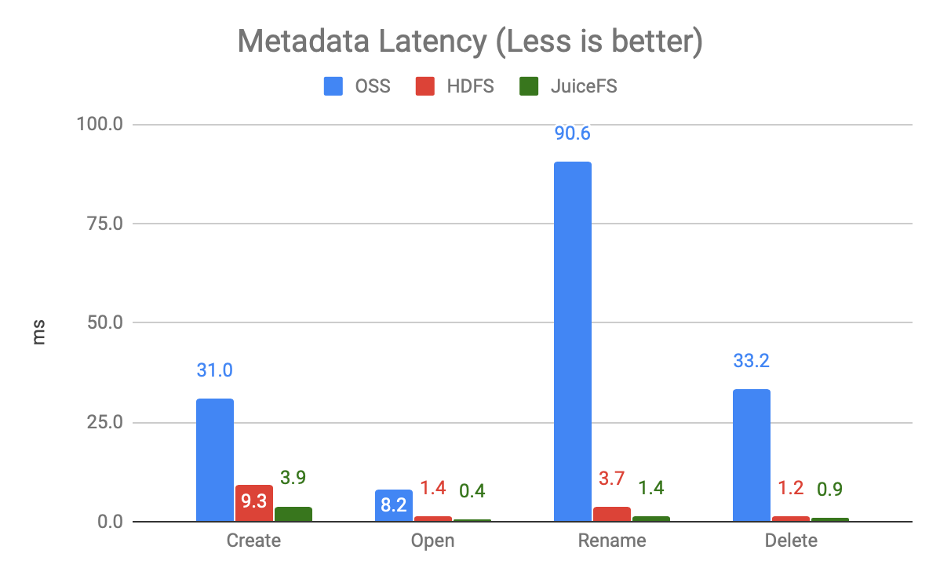
这里我们拿 HDFS 里面的一个组件 NNBench 做了元数据的性能比较,上图对比的是元数据请求延迟,越低越好。可以看到对象存储与 HDFS、JuiceFS 来相比的话,在延迟上是可以差到一个甚至多个数量级的,这个也很好理解,元数据请求对于对象存储来说本身就是比较大的开销。反过来看 JuiceFS 和 HDFS 的话,其实是可以做到旗鼓相当的性能表现的。
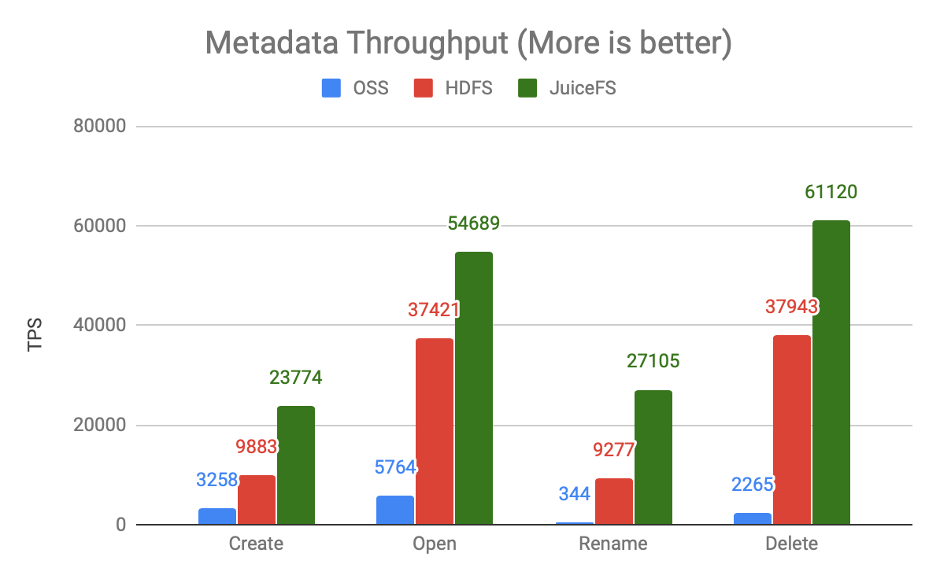
另一个对比是元数据请求吞吐,越大越好,在某些场景下 JuiceFS 甚至可以做到相较 HDFS 有更好的性能表现,而对象存储则会相差很多。
JuiceFS 与 Lakehouse
通过观察 Lakehouse 的特征,我们首先发现 Lakehouse 对于文件系统的依赖依然是存在的,如上文提到的 List 性能、原子重命名、并发写、强一致性等。其次,对象存储在使用上是有一些限制的,比如对象存储基于 key 前缀的请求限制,也包括对象存储的 API 请求是有成本的,特别是在大数据场景,API 请求成本还是蛮高的。最后就是缓存加速对于性能的影响。
Lakehouse 对文件系统的依赖
首先我们看一下 Lakehouse 对于文件系统的依赖。这里可以看下面这个表格,这个表格是直接从 Hudi 的官方文档里面摘抄过来的,Hudi 社区之前统计过直接用对象存储,并根据不同的文件规模或者文件数来做 List 的性能比较。
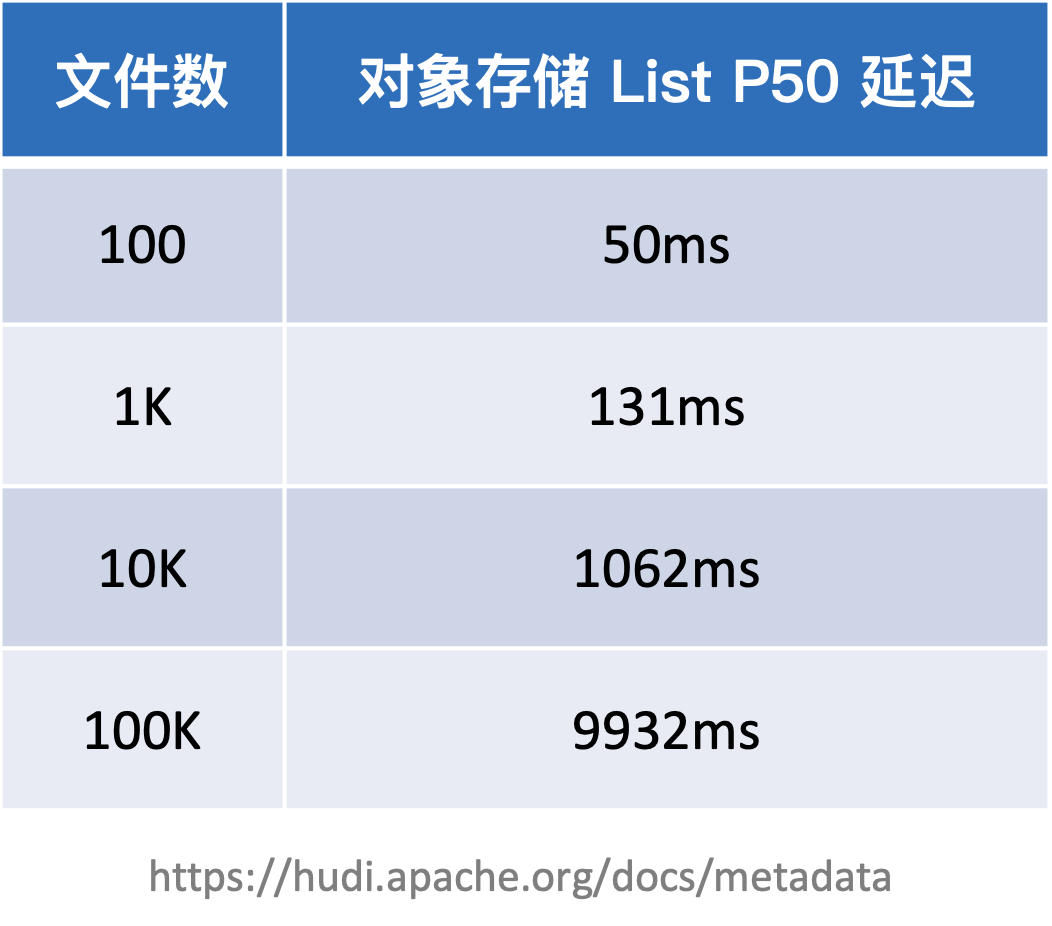
可以看到从 100 到 100K,随着文件数的增多,整个对象存储 List 的开销是逐步增大的,到后面已经变成了线性增长。所以在管理大量文件或者数据时,List 的性能开销无法忽视。
反过来看 HDFS 或 JuiceFS 这类有独立的元数据管理的文件系统,List 请求的开销其实是非常小的,可以做到毫秒级甚至更快,微秒级都是有可能的。正因为整个文件系统元数据管理对 List 非常友好,在一个很短的时间内就可以完成整个目录的 List。还有更多文件系统独有的特性,比如原子重命名、并发写、强一致性等都是非常关键的特性。
Specifically, Delta Lake relies on the following when interacting with storage systems:
- Atomic visibility: There must a way for a file to visible in its entirety or not visible at all.
- Mutual exclusion: Only one writer must be able to create (or rename) a file at the final destination.
- Consistent listing: Once a file has been written in a directory, all future listings for that directory must return that file.
上面这段话是从 Delta Lake 的官方文档上摘抄过来的,在这里就着重提到了对 Delta Lake 来说它依赖底层的存储系统需要具备的几个特性,比如说原子性,其中就包括并发写、原子重命名等,然后是一致性的 Listing,这是对于文件系统强一致性的要求。同样的,以上这些特性对于不管是 Hudi 或者 Iceberg 来说也都有类似的需求。所以对于文件系统的特性需求,在 Lakehouse 的组件上都属于一个隐性的,或者说最基本的依赖,如果对象存储或其它系统满足不了某些特性的话就会带来一些限制。比如说 Delta Lake 在用 S3 的时候,虽然可以并发读数据,但是无法支持并发写,只能在单个 Spark driver 里写数据来保证事务。
对象存储的 API 请求限制和成本
提到对象存储的 API 请求限制和成本的话,这里我们以 S3 为例,在 AWS 官方文档上其实也已经明确告知用户,针对每个 prefix(这里 prefix 的定义就是存储到 S3 上的每一个对象的 key 的前缀)的 GET 请求最大 QPS 是 5500,PUT 请求的最大 QPS 是 3500,对于常规应用而言这个请求限制其实是没问题的,但是对于大数据场景来说,QPS 限制就会影响整体计算任务的性能甚至是稳定性了。对此 Iceberg 提出了一个优化方法是在 key 的最前面加上一个随机的哈希值,目的就是为了分散请求的 prefix,使其不会那么快地触碰到针对单个 prefix 的 QPS 限制。
对于 JuiceFS 来说,设计上已经天然具备分散请求 prefix 的理念。因为所有的文件数据最终上传到对象存储的时候,都会被切分成 4MB 的 block。每个 block 在对象存储上的 key 其实是一个多级的 prefix 来构成,它不是一个单级的目录结构。比如说 0/1/123_0_1024 这个 key,是根据每个 block 的 ID 做了两级 prefix,然后不同的 block 会分散到不同的 prefix 里面来。
然后对于同一个文件来说,如果它是个大文件的话,它的所有 block 也是分布在不同的 prefix 里面的。所以虽然看起来是访问同一个文件,但是对于对象存储来说你访问的是不同的 prefix,所以这也是 JuiceFS 给文件分 block 的好处,也是对于对象存储 API 请求限制的一个优化设计。
其次在对象存储请求成本上,就 JuiceFS 而言,对于对象存储 API 的依赖其实非常少,只有 GetObject、PutObject、DeleteObject 这三个 API,剩下的所有 API 都不依赖。所以接入 JuiceFS 数据存储的存储系统,只需要提供这三个 API 就够了,所有的元数据请求都不会经过对象存储,这部分的 API 请求成本就省掉了。
刚刚提到这三个 API 其实主要是用来读写或者删除数据用的,其中比如 GetObject 是可以通过后面会提到的「缓存加速」做进一步的优化,JuiceFS 会自动地把频繁访问的数据缓存到本地,这样能够大幅减少热数据对于对象存储 API 请求的依赖。相比直接访问对象存储, API 请求成本会降低很多。
缓存加速
第三点就是刚刚提到的缓存加速,这里我们拿一个 benchmark 为例,这个 benchmark 使用业界最常见的 TPC-DS 数据集,计算引擎用的是 Presto,数据采用了两种格式,分别是 ORC 和 Parquet。
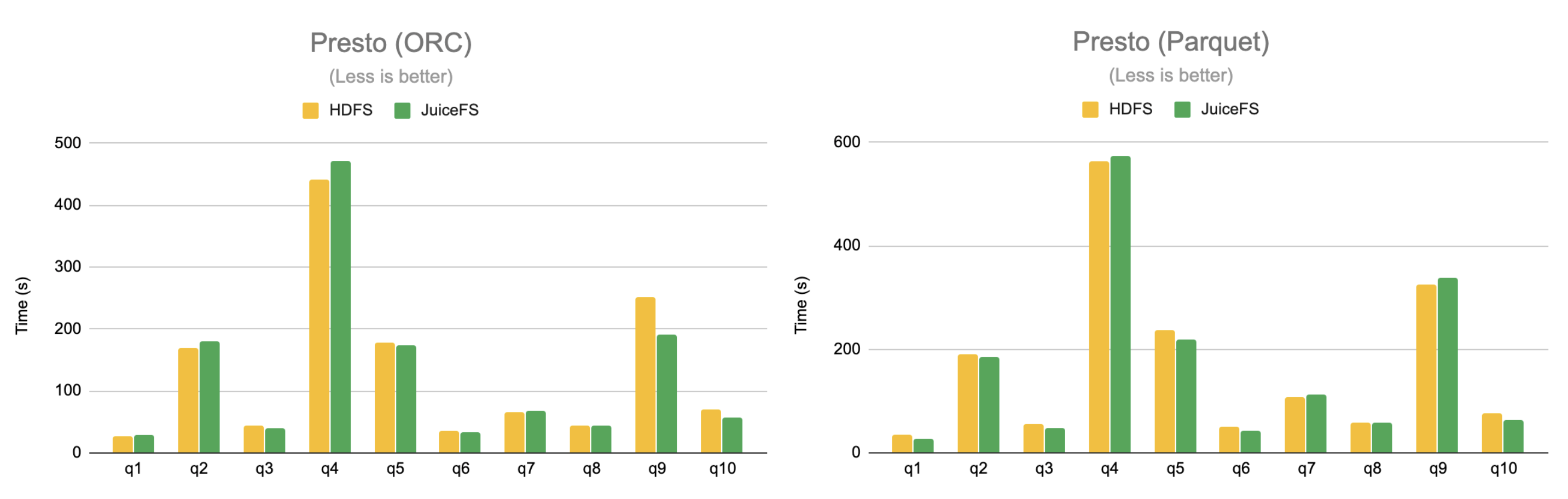
可以看到在缓存充分预热的情况下,JuiceFS 的整体性能表现是可以做到与 HDFS 相当的,所以这也是缓存加速能够体现的一些优势,特别是在存算分离的架构下。
JuiceFS 与数据湖生态
首先 JuiceFS 社区给 Hudi 贡献了一个 PR 可以在 Hudi 内原生支持 JuiceFS ,这个特性已经在 Hudi v0.10.0 及以上版本支持。具体使用方法可以参考 Hudi 的官方文档。这里只是拿 Hudi 举了个例子,其实用 Iceberg、Delta Lake 结合 JuiceFS 也是类似的,JuiceFS 本身已经提供了 HDFS 完全兼容的 API,任何使用 HDFS 的地方都可以直接替换为 JuiceFS。
另外 JuiceFS 跟 AI 社区一个比较流行的开源组件 Fluid 也有一些结合。Fluid 是一个开源的以 Kubernetes 环境为主的数据集编排以及访问加速的组件。目前它主要用在 AI 的场景,但是其实整个 Fluid 社区也想要跟大数据场景做一些结合。Fluid 主要由阿里云的团队以及南京大学的一些团队来维护和开发,它也是 CNCF 里的一个沙盒项目。
JuiceFS 社区和云知声团队一起给 Fluid 社区贡献了一个 PR,把 JuiceFS 作为一个 runtime 集成到 Fluid 中。如果用 Fluid 来做 AI 模型训练,就可以直接原生地使用 JuiceFS 作为其中的一个后端存储或者说加速组件,帮助你更快地在 Kubernetes 里把模型训练任务跑起来。大家有兴趣的话,可以查看 Fluid 的官方文档了解一下。
以上就是我今天的分享,感谢大家!




