









背景
存储是大数据的基石,存储系统的元数据又是它的核心大脑,元数据的性能对整个大数据平台的性能和扩展能力非常关键。本文选取了大数据平台中 3 个典型的存储方案来压测元数据的性能,来个大比拼。
其中 HDFS 是被广为使用的大数据存储方案,已经经过十几年的沉淀和积累,是最合适的参考标杆。
以 Amazon S3 和 Aliyun OSS 为代表的对象存储也是云上大数据平台的候选方案,但它只有 HDFS 的部分功能和语义,性能也差不少,实际使用并不广泛。在这个测试中对象存储以 Aliyun OSS 为代表,其他对象存储类似。
JuiceFS 是大数据圈的新秀,专为云上大数据打造,是符合云原生特征的大数据存储方案。JuiceFS 使用云上对象存储保存客户数据内容,通过 JuiceFS 元数据服务和 Java SDK 来实现 HDFS 的完整兼容,不需要对数据分析组件做任何修改就可以得到跟 HDFS 一样的体验。
测试方法
Hadoop 中有一个专门压测文件系统元数据性能的组件叫 NNBench,本文就是使用它来做压测的。
原版的 NNBench 有一些局限性,我们做了调整:
- 原版 NNBench 的单个测试任务是单线程的,资源利用率低,我们将它改成多线程,便于增加并发压力。
- 原版 NNBench 使用 hostname 作为路径名的一部分,没有考虑同一个主机里多个并发任务的冲突问题,会导致多个测试任务重复创建和删除文件,不太符合大数据工作负载的实际情况,我们改成使用 Map 的顺序号来生成路径名,避免的一个主机上多个测试任务的产生冲突。
我们使用了 3 台阿里云 4核 16G 的虚拟机来做压力测试。CDH 5 是目前被广泛使用的发行版,我们选用 CDH 5 作为测试环境,其中的 HDFS 是 2.6 版本。 HDFS 是使用 3 个 JournalNode 的高可用配置,JuiceFS 是 3 个节点的 Raft 组。HDFS 使用内网 IP,JuiceFS 使用的是弹性 IP,HDFS 的网络性能会好一些。OSS 是使用内网接口访问。
数据分析
先来看看大家都熟悉的 HDFS 的性能表现:
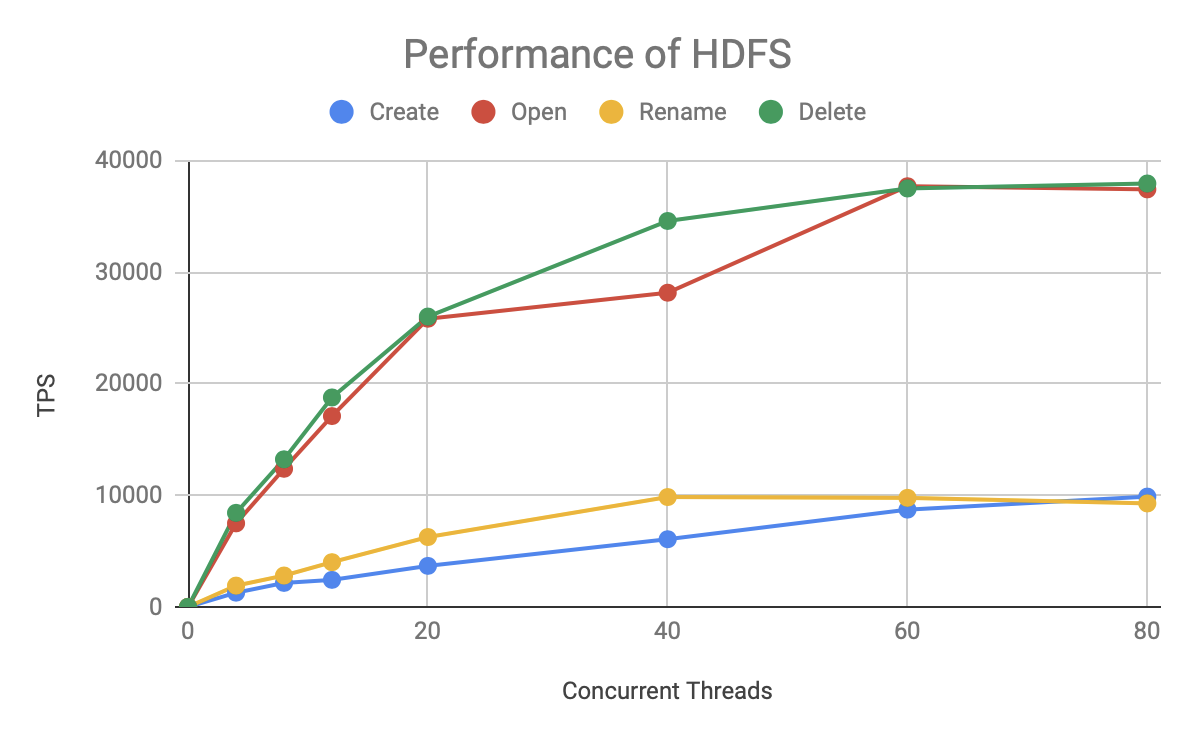
此图描述的是 HDFS 每秒处理的请求数(TPS)随着并发数增长的曲线,有两个发现:
- 其中 Open/Read 和 Delete 操作的性能要远高于 Create 和 Rename。
- 在 20 个并发前,TPS 随着并发数线性增长,之后就增长缓慢了,到 60 个并发已经能压到 TPS 的极限(满负载)。
再来看看 OSS 的性能情况:
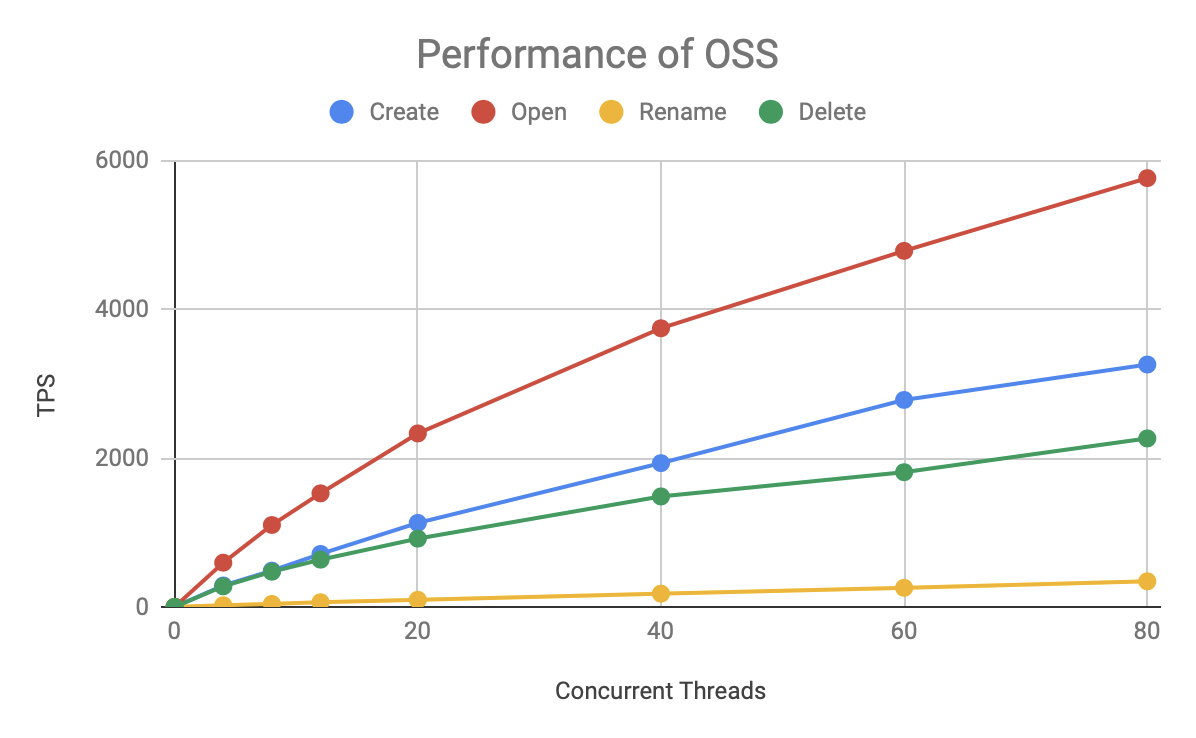
OSS 速度比 HDFS 慢了一个数量级,但它的各种操作的速度基本保持稳定,总的 TPS 随着并发数的增长而增长,在 80 个并发下还没遇到瓶颈。受测试资源所限,未能进一步加大压测知道它的上限。
最后看下 JuiceFS 的表现:
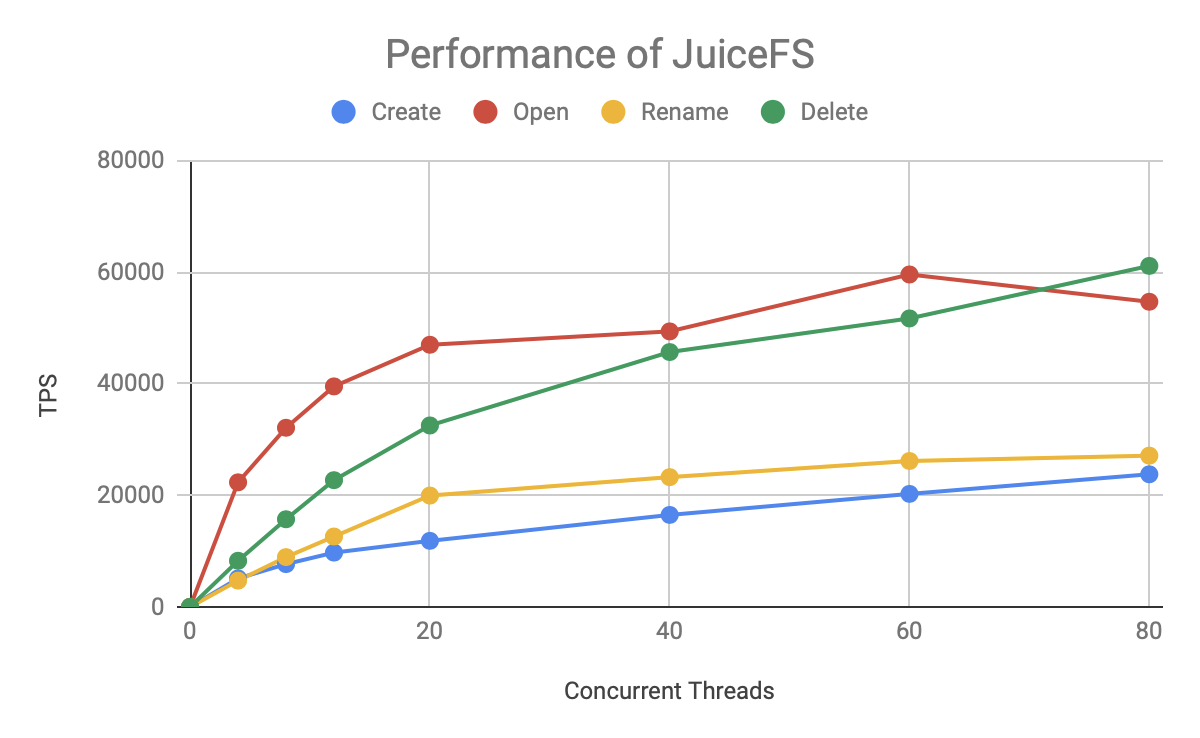
从图中可以看出,整体趋势和 HDFS 类似,Open/Read 和 Delete 操作明显比 Create/Rename 快很多。JuiceFS 的 TPS 也是在 20 个并发以内基本保持线程增长,之后增长放缓,在 60 个并发左右达到上线。但 JuiceFS 增幅更快,上限更高。
详细性能对比
为了更直观的看出这三者的性能差异,我们直接把 HDFS、Aliyun OSS 和 JuiceFS 放在一起比较:
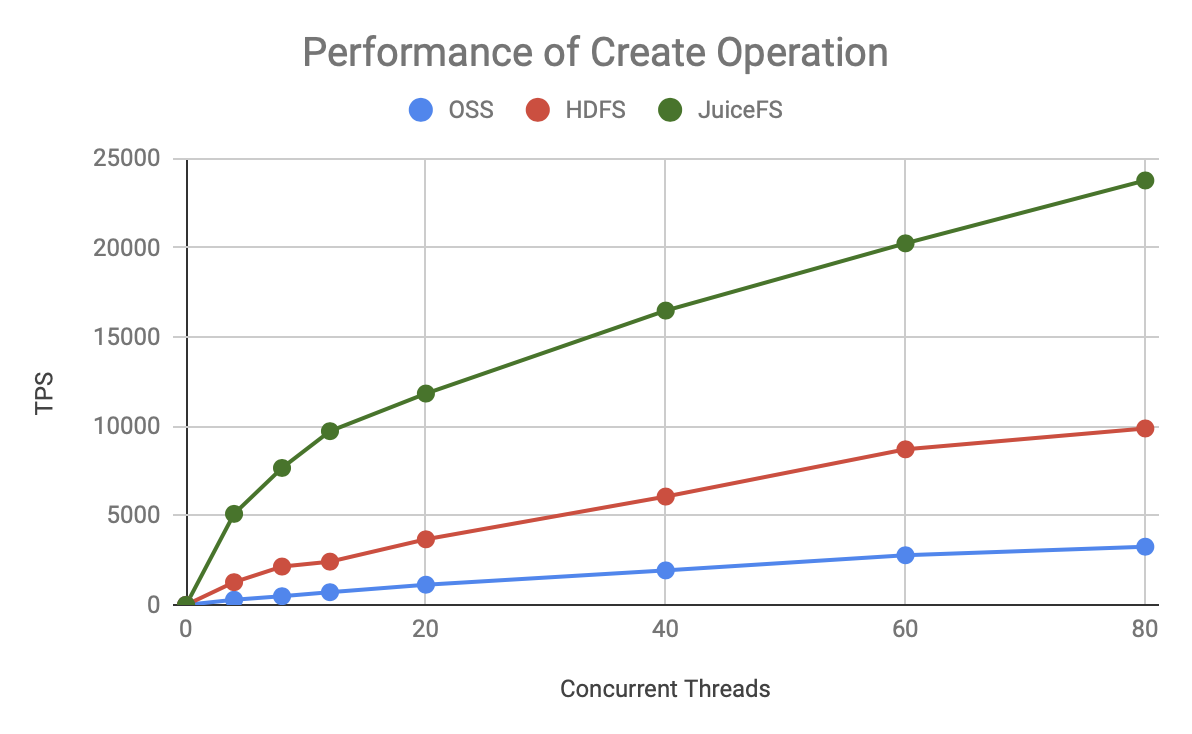
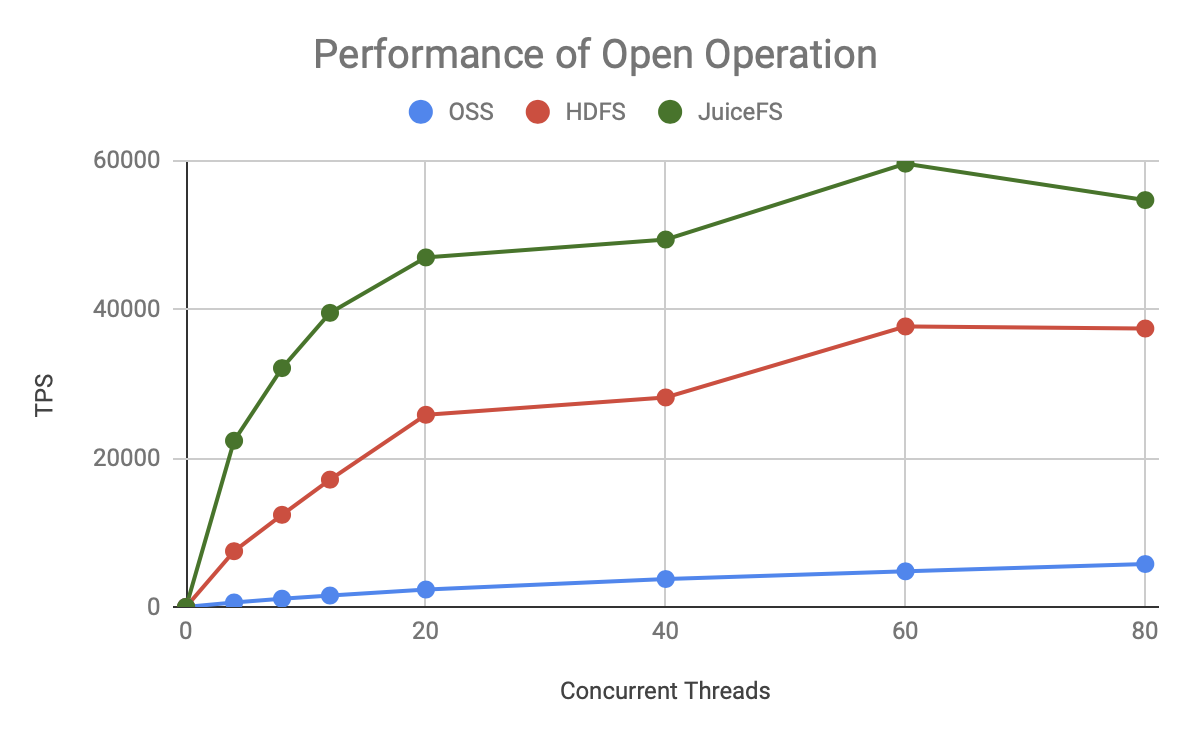
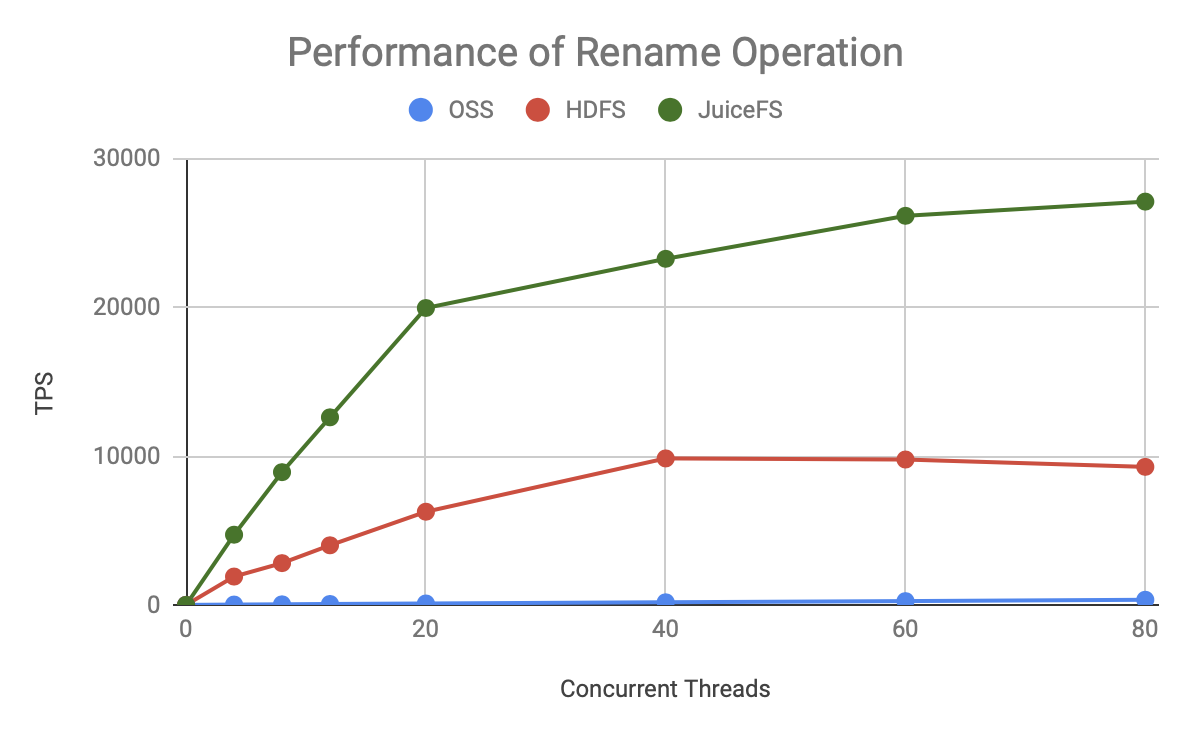
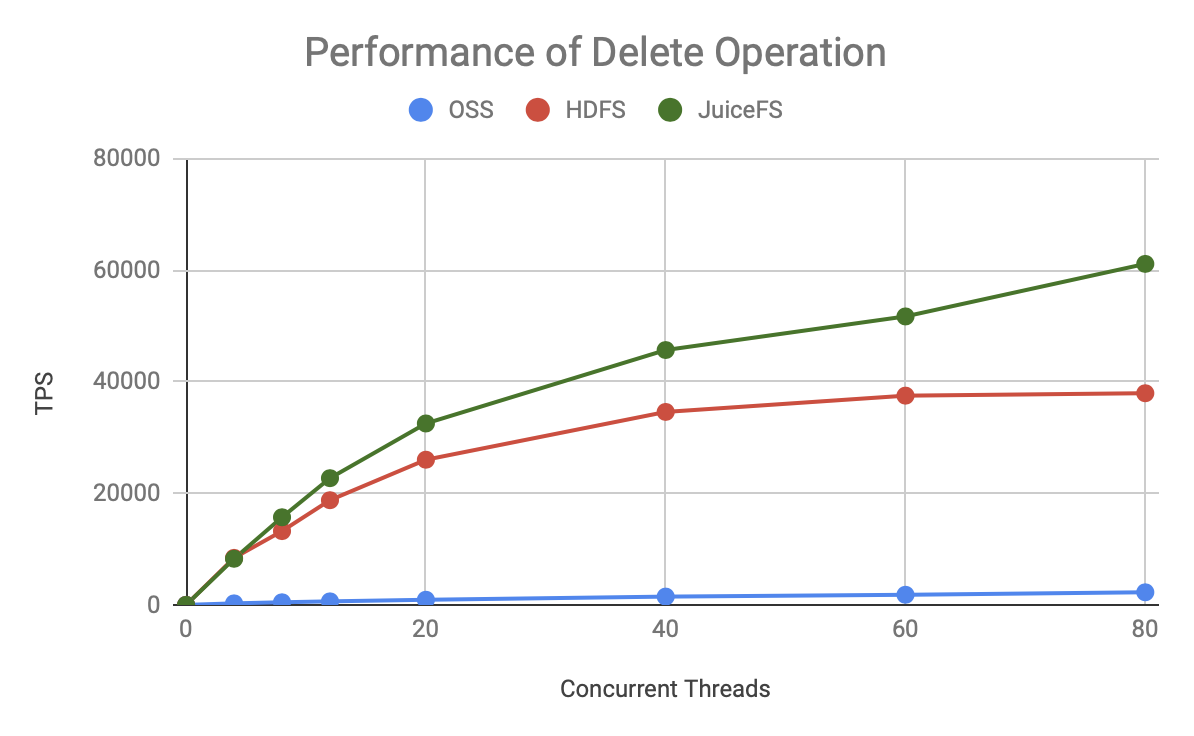
可见无论是哪种元数据操作,JuiceFS 的 TPS 增长更快,上限也更高,明显优于 HDFS 和 OSS。
总结
一般我们在看一个系统的性能时,主要关注它的操作时延(单个操作所消耗的时间)和吞吐量(满负载下的处理能力),我们把这两个指标再汇总一下:
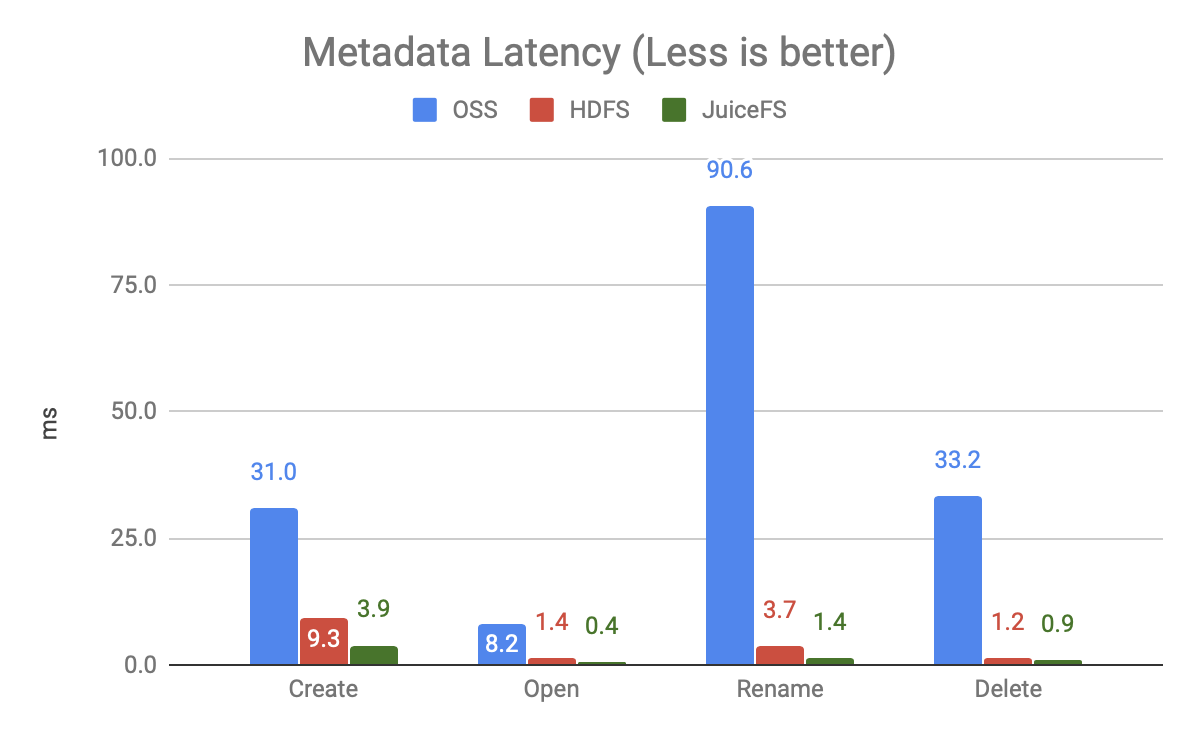
上图是 20 个并发下的各操作的时延(未跑满负载),可以发现:
- OSS 非常慢,尤其是 Rename 操作,因为它是通过 Copy + Delete 实现的。本文测试的还只是单个文件的 Rename,而大数据场景常用的是对整个目录的 Rename,差距会更大。
- JuiceFS 的速度比 HDFS 更快,快一倍多。
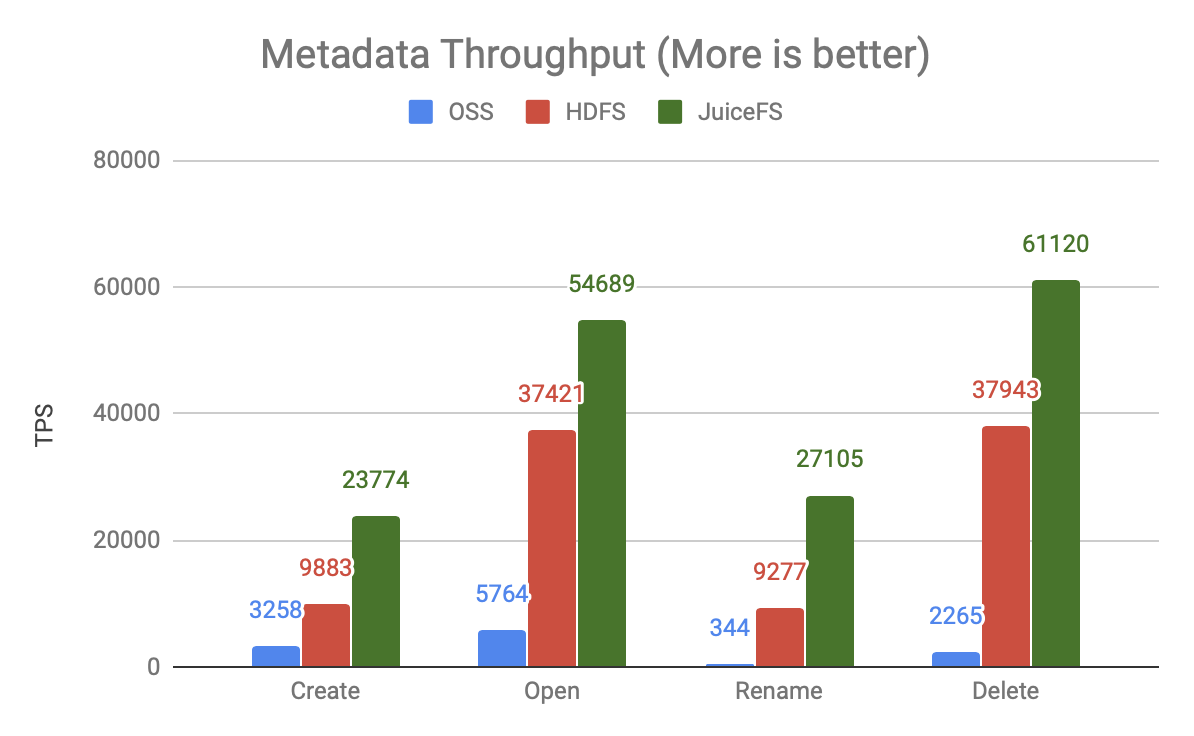
上图是 80 个并发时的吞吐量对比,可以发现:
- OSS 的吞吐量非常低,和其它两个产品有一到两个数量级的差距,意味着它需要使用更多的计算资源,产生更高的并发,才能获得同等的处理能力。
- JuiceFS 比 HDFS 的处理能力高 50-200%,同样的资源能够支撑更大规模的计算。
从以上两个核心性能指标来看,对象存储不适合要求性能的大数据分析场景。JuiceFS 作为后来者已经全面超越 HDFS,能够以更快的性能支撑更大规模的计算处理。




