分布式缓存 RDMA 加速
在 JuiceFS 企业版 5.3 中,系统首次引入了对 RDMA(远程直接内存访问)技术的支持,并将该技术专项应用于分布式缓存的数据传输链路中(即客户端与缓存节点之间)。
什么是 JuiceFS RDMA?
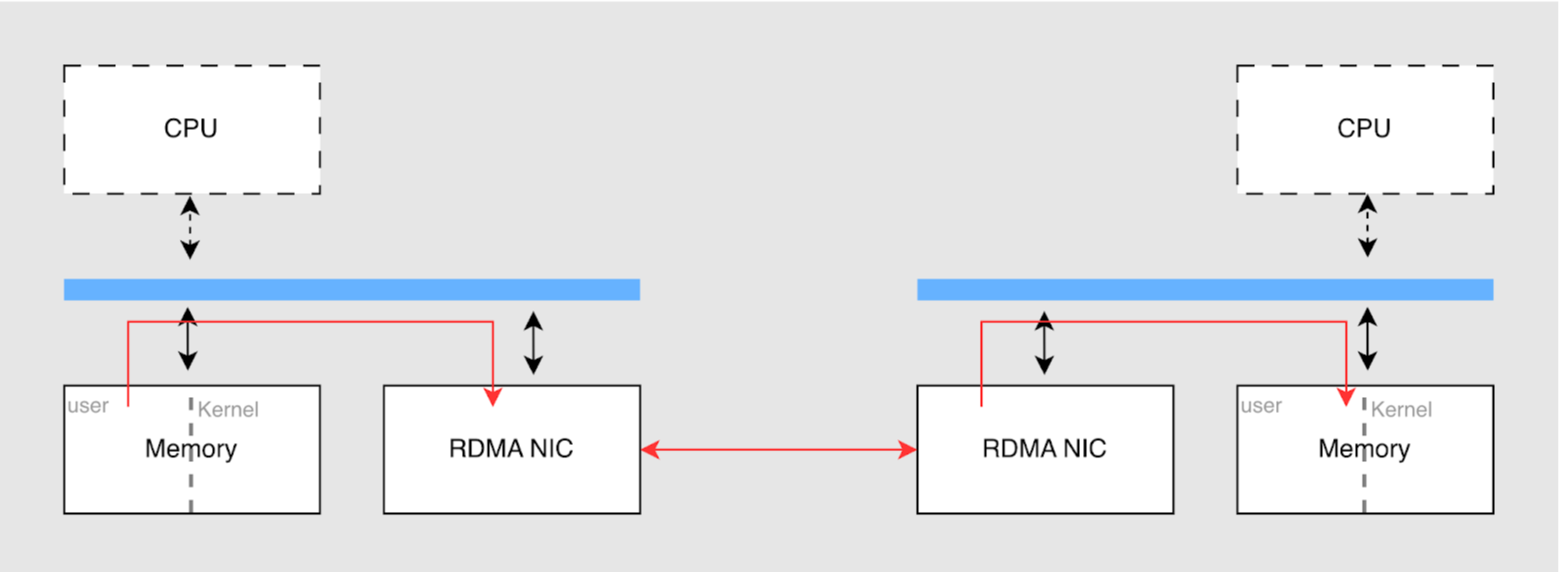
传统的 TCP 网络在传输数据时,需要经过操作系统的网络协议栈,并伴随多次 CPU 中断、上下文切换以及用户态与内核态缓冲区之间的内存拷贝。而 RDMA 技术允许网络上的两台节点直接读写对方的内存数据,整个过程由网卡硬件负责,网卡直接读写用户态缓冲区(即实现「零拷贝」),几乎完全绕过操作系统内核与 CPU 的干预。相当于为缓存数据的读取开辟了一条「硬件级专属高速公路」。
由于客户端与元数据服务网络之间传输的主要是控制消息,数据量较小,现有的 TCP 网络已完全足够,因此 RDMA 优化主要聚焦于大文件数据所在的分布式缓存层。
核心优势与性能飞跃
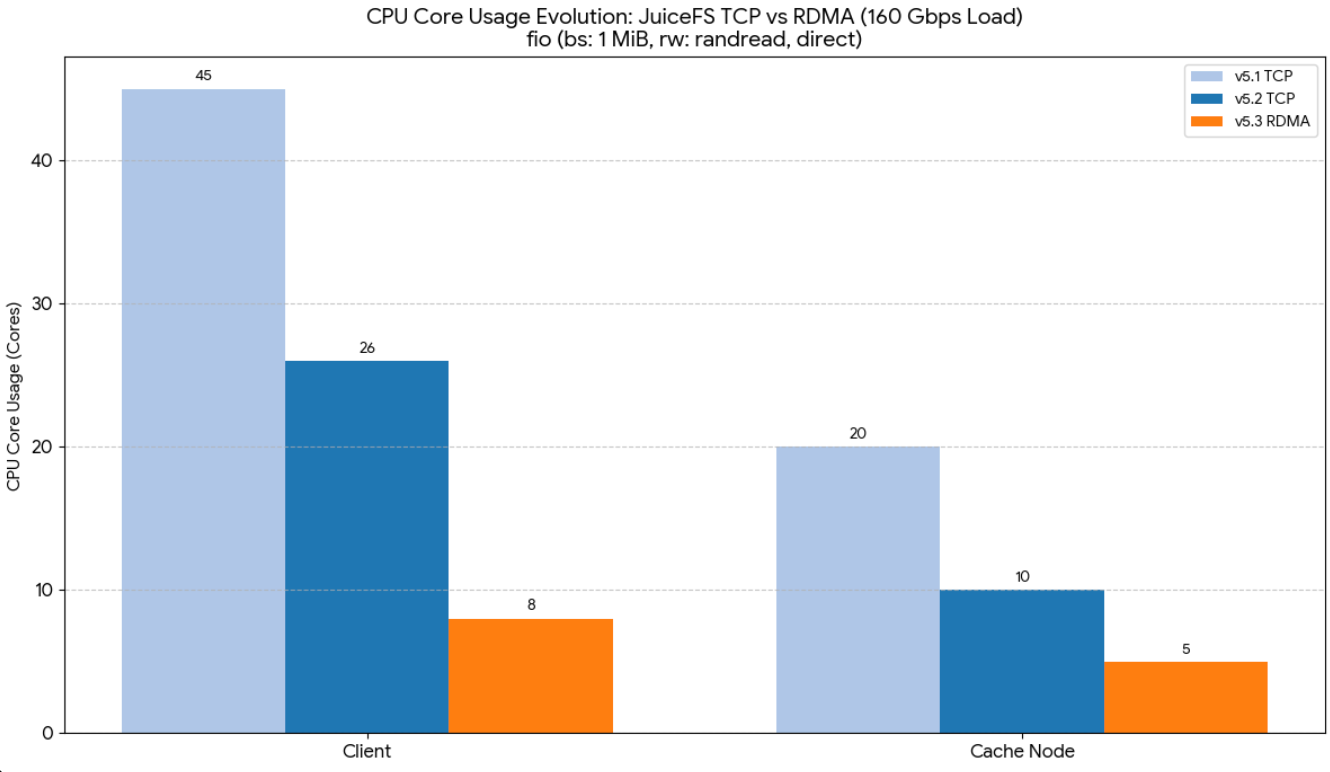
结合最新的实测数据,使用 RDMA 技术为 JuiceFS 带来了显著的性能与资源利用率提升:
- 打破带宽瓶颈(高吞吐量):在极高带宽场景下,传统的 TCP 网络往往难以完全发挥硬件性能(例如在 200 Gbps 网卡下通常只能达到 85% - 90% 的带宽利用率)。而 RDMA 能够更加充分地利用 100 Gbps、200 Gbps 甚至 400 Gbps 高性能网卡的硬件带宽上限。
- 大幅释放算力(降低 CPU 占用):由于数据拷贝工作交由网卡独立完成,CPU 被极大解放。在 160 Gbps 网络的 1 MB 随机读测试中,网络传输带宽达到了 20 GiB/s(约等于 160 Gbps 物理极限带宽),在此情况下,RDMA 使整体 CPU 占用率从近 50% 骤降至约三分之一(客户端 CPU 降至 8 核,缓存节点降至 5 核)。
- 极致的响应速度(低延迟):省去了内核协议栈的层层处理,节点间的数据传递时间被大幅度压缩。
推荐适用场景
目前该功能处于公测(Beta)阶段,如果满足以下条件,极其推荐尝试开启此功能:
- 极高带宽需求:网络环境大于 100 Gbps,且面临传统 TCP 无法满足传输瓶颈的情况。
- 算力资源紧张:希望大幅降低存储 I/O 对宿主机 CPU 的消耗,将算力留给核心业务(如 AI 训练、大模型推理等)。
环境与基础要求
为了顺利启用该功能,基础网络与硬件环境需要满足以下条件:
- 同构的硬件网络:要使用 RDMA 功能,客户端(即 JuiceFS 挂载点)和服务端(即分布式缓存节点)所在的宿主机,均必须配备支持 RDMA 技术的网卡。同时,通信两端必须处于「同构」的硬件网络环境中(例如两端均为 RoCE、InfiniBand 或 eRDMA 网卡)。如果硬件协议不一致(如一端为 RoCE,另一端为 InfiniBand),物理网卡将无法直接解析对方的数据格式��,从而无法建立 RDMA 通信通道。
- IP 协议配置:RDMA 本身可以不依赖 IP,但缓存组及元数据服务仍需通过 IP 来标识和管理节点,因此支持 RDMA 的网卡仍必须配置 IPv4 地址(如 InfiniBand 网卡需配置 IPoIB)。
- 网络互通:分布式缓存的客户端与服务端网卡之间必须能够相互通信。
多网卡并发架构与通信机制
如果宿主机配备了多张 RDMA 网卡,并希望同时使用它们以叠加带宽,需要特别注意底层的网络架构与应用层的分发机制:
- 路由隔离与网卡绑定(网络层前提):由于操作系统默认的路由机制限制(处于同网段的多张网卡通常只有一张会被用来发送数据),系统默认只会使用一张网卡建立连接。为了让多张网卡实现真正的并行传输,必须采取以下两种网络架构之一:
- 网段隔离:将每一对网卡分别配置在不同的 IP 网段中。这可以从操作系统层面强制数据流在不同的物理链路上独立并行,互不干扰。
- 网卡绑定(推荐):将多张网卡在系统层做 Bond。这样操作系统只暴露一个逻辑网卡,底层的流量分发、并行传输和高可用切换全部交由网卡硬件和交换机(如 LACP 协议)自动完成,运维更简单。
- 多连接并行与伪随机分发(应用层机制):当网络层配置妥当,并且在软件层面明确指定了同时使用多张独立网卡时,JuiceFS 底层的通信机制并非严格的轮询,而是采用多连接并行与伪随机分发策略。
- 客户端会为每一个指定的网卡地址建立一条独立的连接通道。
- 当应用层发起多个并发请求时,系统会随机将请求分配给当前等待的空闲通道。
- 这种机制能够将整体负载均衡到多张物理网卡上。但需特别注意,单个请求只会被分配到其中一条连接(即一张网卡)上,系统绝不会将单个请求拆分打散到多张网卡上同时传输。
核心参数配置指南
- 启用 RDMA 传输(
--rdma-network):要使用 RDMA,需要在所有节点上指定--rdma-network(如--rdma-network eth1:eth2)。缓存服务端指定后即监听 RDMA 端口,纯客户端(--no-sharing)指定后通过 RDMA 向服务端拉取数据。不指定则回退到 TCP。RDMA 端口号由系统随机分配,无需也无法显式指定。 - IORPC 缓存读取方式(
--iorpc-mode=dio):控制 IORPC 服务端从磁盘读取缓存数据的方式。可选值:dio(Direct I/O,默认)、pagecache(Buffer 读)、splice(零拷贝,利用内核 pipe 在磁盘和网络间直接传输数据,不经过用户态。要求系统 pipe 最大值至少为 8 MiB,且 RDMA 启用时自动回退为dio。可通过sysctl fs.pipe-max-size查看当前值)、disable(禁用本节点的 IORPC 服务端)。 - 区分 TCP 与 RDMA 网络(
--group-network):--group-network用于控制传统的 TCP 网络通信,--rdma-network专门用于控制 RDMA 数据传输。两者可以指向同一张网卡,也可以完全分开(例如,让控制指令走千兆管理网,让海量缓存数据走专用的百 Gbps 高速 RDMA 网络)。
RDMA 与 TCP 对比
| 特性 | RDMA 模式 | TCP 模式 |
|---|---|---|
| 启用方式 | --rdma-network eth1 | 默认(无需额外参数) |
| 缓存读的 Direct I/O | 默认启用(--iorpc-mode=dio) | 需显式设置 --cache-try-dio |
| IORPC 协议 | 自动启用 | 需显式设置 --use-iorpc |
| 网卡指定 | --rdma-network(数据)+ --group-network(控制) | --group-network 或 --group-ip |
| 硬件要求 | 需要 RDMA 网卡 | 无特殊要求 |
| 端口分配 | RDMA 端口自动分配(随机端口) | 通过 --group-port 指定(默认为随机端口) |
IORPC 是分布式缓存底层的通信协议。指定 --rdma-network 后,IORPC 会自动启用并以 RDMA 方式传输数据,无需额外设置 --use-iorpc。--use-iorpc 仅在无 RDMA 硬件但仍希望使用 IORPC 协议(走 TCP)时单独使用。
部署与使用须知
- 使用专属组件:RDMA 依赖特定的底层环境,因此需要使用专属打包的二进制文件(如
mount.rdma)来启动服务。 - RDMA 与 TCP 混合网络支持:配置
--rdma-network后,分布式缓存服务端同时监听 RDMA 和 TCP 端口。这意味着服务端完全支持混合架构:配置了 RDMA 网卡的客户端通过 RDMA 接入,其他客户端继续通过 TCP 接入,二者互不干扰。 - 网络异常的降级与自动故障转移 新增自 v5.3.9:
- 启动期:如果未指定
--rdma-network,系统自动回退到 TCP。但如果已指定--rdma-network而初始化失败(如网卡不存在、内存分配失败),客户端会直接终止,不会回退到 TCP。请确认指定的网卡正确且 RDMA 驱动已安装。 - 运行期:RDMA 连接现在支持自动故障转移到 TCP 并故障恢复。运行期间若 RDMA 连接失败,系统会自动降级到 TCP 进行数据传输,并在可配置的时间间隔后重新尝试 RDMA。该时间间隔由环境变量
IORPC_RDMA_RETRY_DURATION控制(默认为5m,即 5 分钟),常见取值如30s、10m、1h等。这意味着遇到临时的 RDMA 网络问题时,无需手动重新挂载即可恢复 RDMA 通信。
- 启动期:如果未指定
- 前置连通性验证:在正式接入业务前,请验证 RDMA 网卡状态和通道连通性:
-
检查网卡状态:
rdma link(预期state ACTIVE physical_state LINK_UP) -
测试 RDMA 连通性:
# 服务端
rping -s -a <Server_IP> -C 10
# 客户端
rping -c -a <Server_IP> -C 10成功标志:
- 服务端输出
rdma_bind_addr successful / rdma_listen successful - 客户端输出
rdma_resolve_addr successful / rdma_resolve_route successful
- 服务端输出
-
完整挂载示例
# 缓存服务端
juicefs mount $VOLUME_NAME /jfs-cache --cache-group=cg --rdma-network=ib0:ib2 \
--cache-dir=/data/cache* --cache-size=-1 --buffer-size=8192 --max-downloads=800
# 纯客户端
juicefs mount $VOLUME_NAME /jfs --cache-group=cg --no-sharing \
--rdma-network=ib0:ib1 --max-write=1M --cache-size=0 --max-downloads=600 --buffer-size=8192
参考测试方法
挂载参数
推荐在客户端(即负责处理 FUSE 请求的客户端)上添加以下挂载参数:
--max-write=1M:这个参数可以增大单次 FUSE 请求的 I/O 大小,默认的 I/O 大小是 128KiB。增大 I/O 大小可以减少系统调用的次数和开销。
测试命令
fio --name=rdma_read_test --directory=/jfs --rw=read --ioengine=libaio --bs=1M --size=1G --direct --thread --group_report --time_based --runtime=300 --numjobs=128 --iodepth=1
--direct:绕过内核页缓存,确保测试结果反映的是 RDMA 网络吞吐而非缓存性能。--ioengine=libaio:Linux 原生异步 I/O 引擎,配合--direct可充分发挥 RDMA 高带宽优势。--bs=1M:较大的块大小减少 FUSE 调用开销,让 RDMA 传输成为性能瓶颈��。--numjobs:控制并发 job 数,应根据 CPU 核数和 RDMA 带宽灵活调整。建议从与 CPU 核数相当的并发开始,逐步增加,吞吐不再增长时即为合适值。过多 job 会导致 CPU 成为瓶颈。--iodepth:默认为 1,即每个 job 只保持一个在途 I/O 请求。RDMA 模式下低 iodepth 即可获得高吞吐;TCP 模式下通常需要更大的 iodepth 才能打满带宽。可调整该值来对比两种模式的吞吐差异。
性能参考
在 400Gbps InfiniBand × 2、128C CPU、本地 NVMe 缓存盘的测试环境中,RDMA 模式单客户端吞吐约 60 GB/s,相比 TCP 模式的 25 GB/s 提升了一倍以上。在由 3 台缓存节点组成的集群中(理论提供约 300 GB/s 吞吐),通过 6 台客户端压测达到了 288 GB/s 的聚合吞吐,利用率高达 96%。实际性能取决于网卡带宽、CPU 核数、缓存盘速度等硬件配置。
监控 RDMA 指标 新增自 v5.3.9
从 5.3.9 起,使用 RDMA 的挂载进程和执行 juicefs stats 的客户端需同时升级到 5.3.9 或更高版本,才能使用 RDMA 指标。挂载进程负责产出指标数据,stats 命令负责解析展示,两者缺一不可。
使用 juicefs stats 命令配合 e 字符可以实时监控 RDMA 专属指标:
juicefs stats -l 1 --schema=ufmcreo /jfs
rdma 板块仅统计 RDMA 通道的流量。可与 remotecache 板块(包含 TCP 和 RDMA)对比,计算 RDMA 覆盖比例:
write:向请求方发送的数据量(字节/秒)。作为服务端,将缓存数据发送给请求方。read:从请求方拉取的请求信息数据量(字节/秒)。不包含文件数据本身,通常较小。w_ops/lat:RDMA 写操作次数(次/秒)和平均延迟(毫秒)。recv:从服务方接收的数据量(字节/秒)。作为客户端,收到服务方返回的缓存数据。
write 和 recv 测量的是同一条数据流的正反面:一方发出的 write 等于另一方收到的 recv。
详见 juicefs stats 了解所有可用的 schema 字符和指标。
常见问题
| 现象 | 排查方向 |
|---|---|
客户端日志只有 iorpc client started 没有 transport:RDMA | 服务端未启用 RDMA,检查 rdma link 并确认使用的是 mount.rdma 二进制 |
客户端出现 get iorpc address from <ip> failed: rpc disabled | 服务端版本低于 5.3,不支持 RDMA |
客户端出现 Cannot establish rpc connection 循环重试 | 物理 RDMA 不通,用 rping 验证;或检查 --rdma-network 是否配置 |
| I/O 延迟飙升至 100s 以上 | 检查 --group-network 和 --rdma-network 网卡配置是否正确 |


