安装
准备
- 确认网络环境满足安装要求:
- 对于云服务,JuiceFS Hadoop SDK 需要通过外网访问 JuiceFS 元数据服务及控制台,需要部署 NAT 等给 Hadoop 集群提供外网访问能力。
- 对于私有部署,元数据服务和控制台已经部署在内网,Hadoop 节点需要能够访问元数据服务及控制台。
- JuiceFS 所使用的存储桶需要提前创建好,Hadoop Java SDK 不会自动创建。
- 下载最新的
juicefs-hadoop.jar,在后续安装步骤中需要用到。
以上链接下载的 Hadoop SDK 有几个注意事项:
- 仅支持 x86 架构的 Linux 发行版,如需下载其它环境的 Hadoop SDK 请联系 Juicedata 团队。
- 如果你希望使用 Ceph 作为 JuiceFS 的数据存储,请联系 Juicedata 团队获取特定版本的 Hadoop SDK。
- 由于文档更新滞后,下载的可能不是最新版本,请参考「版本更新」查看最新的版本号。
Hadoop 发行版
CDH
使用 Parcel 安装
-
在 Cloudera Manager 节点下载 Parcel 和 CSD,将 CSD 文件放入的
/opt/cloudera/csd目录,将 Parcel 文件解压并将内容放入/opt/cloudera/parcel-repo目录。 -
重启 Cloudera Manager
service cloudera-scm-server restart -
激活 Parcel
打开 CDH 管理界面 → Hosts → Check for New Parcels → JuiceFS → Distribute → Active
-
添加服务
打开 CDH 管理界面 → 集群名 → Add Service → JuiceFS → 选择安装机器 → 配置缓存目录(
cache_dirs) -
部署 JAR 文件
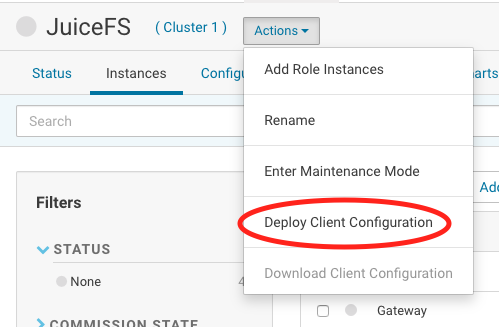
-
升级
如果需要升级,则下载新的 Parcel 文件,并进行第 3 步。
通过 Cloudera Manager 修改配置
-
Hadoop
-
CDH 5.x
通过 HDFS 服务界面修改
core-site.xml: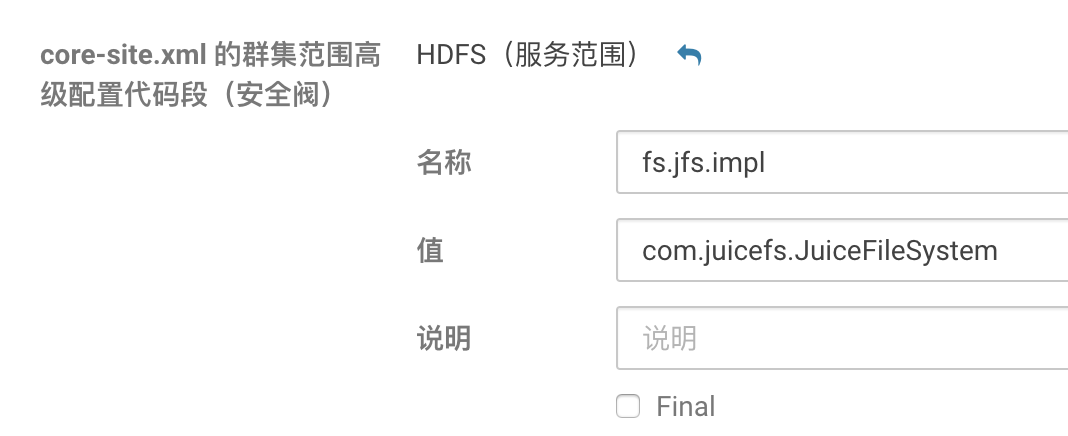
示例配置:
fs.jfs.impl=com.juicefs.JuiceFileSystem
fs.AbstractFileSystem.jfs.impl=com.juicefs.JuiceFS
juicefs.cache-size=10240
juicefs.cache-dir=xxxxxx
juicefs.cache-group=yarn
juicefs.discover-nodes-url=yarn
juicefs.accesskey=xxxxxx
juicefs.secretkey=xxxxxx
juicefs.token=xxxxxx
juicefs.access-log=/tmp/juicefs.access.log -
CDH 6.x
除了上述 5.x 内容外。您还需通过 YARN 服务界面修改
mapreduce.application.classpath,增加以下配置:$HADOOP_COMMON_HOME/lib/juicefs-hadoop.jar
-
-
HBase
通过 HBase 服务界面修改
hbase-site.xml: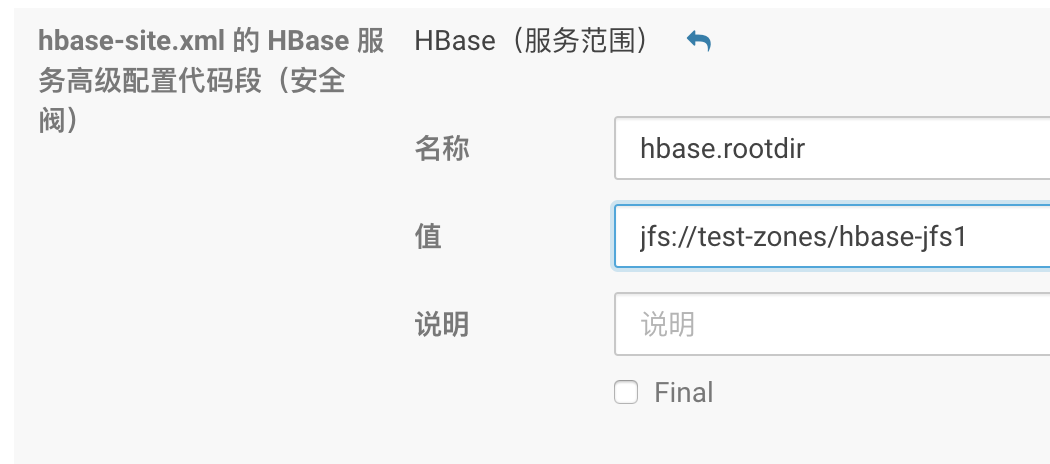
配置:
<property>
<name>hbase.rootdir</name>
<value>jfs://{VOL_NAME}/hbase</value>
</property>
<property>
<name>hbase.wal.dir</name>
<value>hdfs://your-hdfs-uri/hbase-wal</value>
</property>通过 ZooKeeper 客户端删除
zookeeper.znode.parent配置的 znode(默认/hbase),此操作将会删除原有 HBase 集群里的所有数据。 -
Hive
通过 Hive 服务界面修改
hive.metastore.warehouse.dir,可修改 Hive 建表默认位置(非必须)jfs://myjfs/your-warehouse-dir -
Impala
通过 Impala 服务界面修改 Impala 命令行参数高级配置
此参数可以使用
20 / 本地挂载磁盘数来设置,修改此参数主要是为了增加 JuiceFS 的读取 I/O 线程数。-num_io_threads_per_rotational_disk=4 -
Solr
通过 Solr 服务界面修改 Solr 服务环境高级配置代码段
hdfs_data_dir=jfs://myjfs/solr
最后重启集群,让配置修改生效。
HDP
将 JuiceFS 集成到 Ambari
-
下载 HDP 安装文件,解压后将内容放到
/var/lib/ambari-server/resources/stacks/HDP/{YOUR-HDP-VERSION}/services下 -
重启 Ambari
systemctl restart ambari-server -
添加 JuiceFS 服务
打开 Ambari 管理界面 → Services → Add Service → JuiceFS → 选择安装机器 → 配置 → deploy
在配置步骤,主要是配置缓存目录(
cache_dirs)和下载版本(download_url)。如果 Ambari 没有外网,可以直接将下载好的 JAR 包收到放到
share_download_dir下,默认为 HDFS 的/tmp目录。 -
升级 JuiceFS
修改
download_url的版本号,保存并 Refresh configs。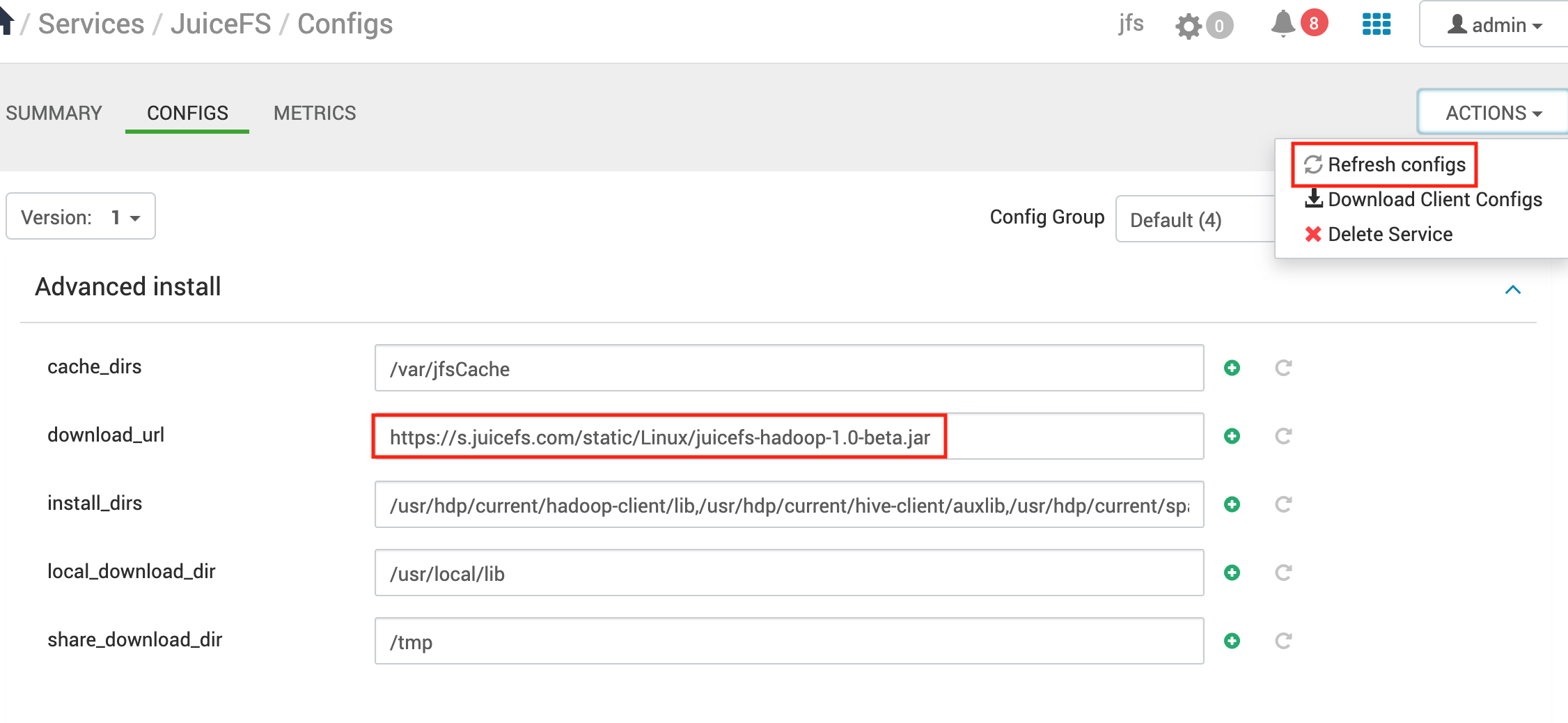
通过 Ambari 修改配置
-
Hadoop
通过 HDFS 服务界面修改
core-site.xml。 -
MapReduce2
通过 MapReduce2 服务界面修改配置
mapreduce.application.classpath,在末尾增加:/usr/hdp/${hdp.version}/hadoop/lib/juicefs-hadoop.jar(变量无需替换)。 -
Hive
通过 Hive 服务界面修改
hive.metastore.warehouse.dir,可修改 Hive 建表默认位置(非必须):jfs://myjfs/your-warehouse-dir如果配置了 Ranger 服务,则需要在
ranger.plugin.hive.urlauth.filesystem.schemes配置追加jfs支持:ranger.plugin.hive.urlauth.filesystem.schemes=hdfs:,file:,wasb:,adl:,jfs: -
Druid
通过 Druid 界面修改目录地址(如无权限,需手动创建目录):
"druid.storage.storageDirectory": "jfs://myjfs/apps/druid/warehouse"
"druid.indexer.logs.directory": "jfs://myjfs/user/druid/logs" -
HBase
通过 HBase 服务界面修改一下参数
hbase.rootdir=jfs://myjfs/hbase
hbase.wal.dir=hdfs://your-hdfs-uri/hbase-wal通过 ZooKeeper 客户端删除
zookeeper.znode.parent配置的 znode(默认/hbase),此操作将会删除原有 HBase 集群里的所有数据。 -
Sqoop
使用 Sqoop 将数据导入 Hive 时,Sqoop 会首先把数据导入
target-dir,然后在通过hive load命令将数据加载到 Hive 表,所以使用 Sqoop 时,需要修改target-dir。-
1.4.6
使用此版本的 Sqoop 时还需要修改
fs, 此参数修改默认文件系统,所以需要将 HDFS 上面的mapreduce.tar.gz复制到 JuiceFS 上的相同路径,默认目录在 HDFS/hdp/apps/${hdp.version}/mapreduce/mapreduce.tar.gz。sqoop import \
-fs jfs://myjfs/ \
--target-dir jfs://myjfs/tmp/your-dir -
1.4.7
sqoop import \
--target-dir jfs://myjfs/tmp/your-dir
-
最后,重启相应服务让配置修改生效。
EMR 平台
EMR 平台集成 JuiceFS 十分简单,大致步骤:
- 对节点加入初始化配置,执行安装 SDK 的脚本(
emr-boot.sh),例如emr-boot.sh --jar s3://xxx/juicefs-hadoop.jar; - 修改
core-site.xml,加入 JuiceFS 相关配置。
已有 EMR 集群
常见的 EMR 平台大多不支持创建集群以后修改节点初始化设置,因此无法方便地在控制台进行配置,令新加入的节点启动时,在初始化阶段自动执行安装脚本。
因此如果你希望对已有的 EMR 集群进行 JuiceFS 集成,你需要自行设置,来确保初始化脚本随着节点初始化自动运行。
阿里云 EMR
-
在 EMR 软件配置界面配置高级设置
在软件配置 → 高级设置 → 修改配置(参考「常用配置」),格式如下:
[
{
"ServiceName": "HDFS",
"FileName": "core-site",
"ConfigKey": "fs.jfs.impl",
"ConfigValue": "com.juicefs.JuiceFileSystem"
},
{
"ServiceName": "HDFS",
"FileName": "core-site",
"ConfigKey": "fs.AbstractFileSystem.jfs.impl",
"ConfigValue": "com.juicefs.JuiceFS"
},
...
] -
在基础信息界面的高级�设置里面添加引导操作
下载
emr-boot.sh脚本和juicefs-hadoop.jar,并上传到您的对象存储上。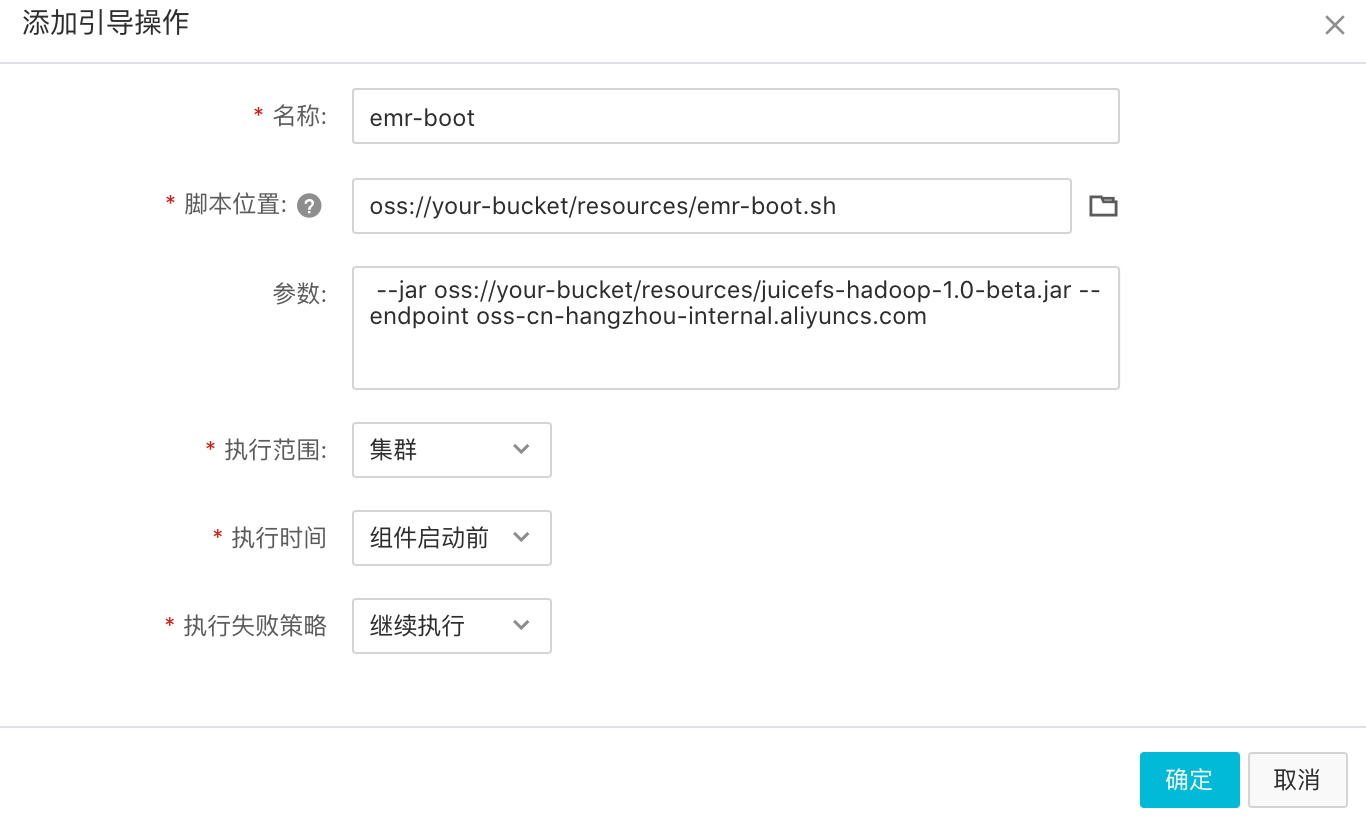
「脚本位置」填写
emr-boot.sh在 OSS 上面的地址,「参数」填写juicefs-hadoop-{version}.jar在 OSS 上面的地址。-
可以访问公网
--jar oss://{bucket}/resources/juicefs-hadoop-{version}.jar --endpoint {endpoint}
# 或者
--jar https://{bucket}.{endpoint}/resources/juicefs-hadoop-{version}.jar
-
腾讯云 EMR
-
在 EMR 可用区与软件配置界面配置高级设置:
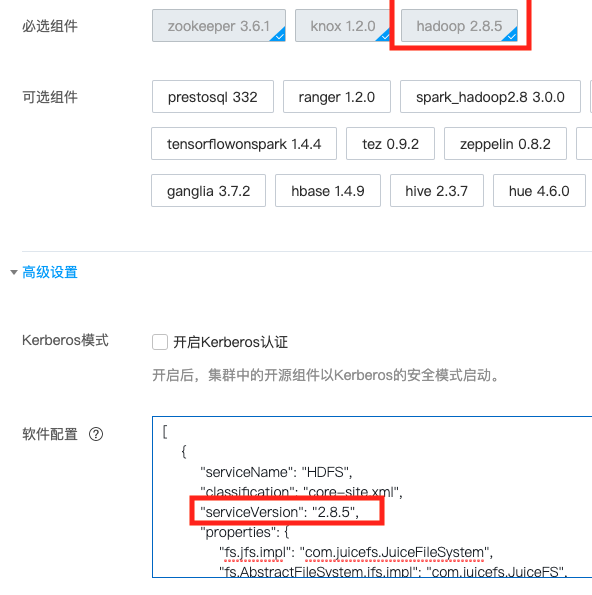
填入 JuiceFS 相关配置,注意:
-
serviceVersion需要和 Hadoop 版本匹配; -
由于腾讯云 EMR 默认使用
hadoop用户启动 HDFS,HDFS 的superuser为hadoop。为了保持一致所以还需要指定juicefs.superuser=hadoop。
[
{
"serviceName": "HDFS",
"classification": "core-site.xml",
"serviceVersion": "2.8.5",
"properties": {
"fs.jfs.impl": "com.juicefs.JuiceFileSystem",
"fs.AbstractFileSystem.jfs.impl": "com.juicefs.JuiceFS",
"juicefs.superuser": "hadoop",
...
}
}
] -
-
在基础信息界面的高级设置里面添加引导操作
下载
emr-boot.sh脚本和juicefs-hadoop.jar,并上传到您的对象存储上。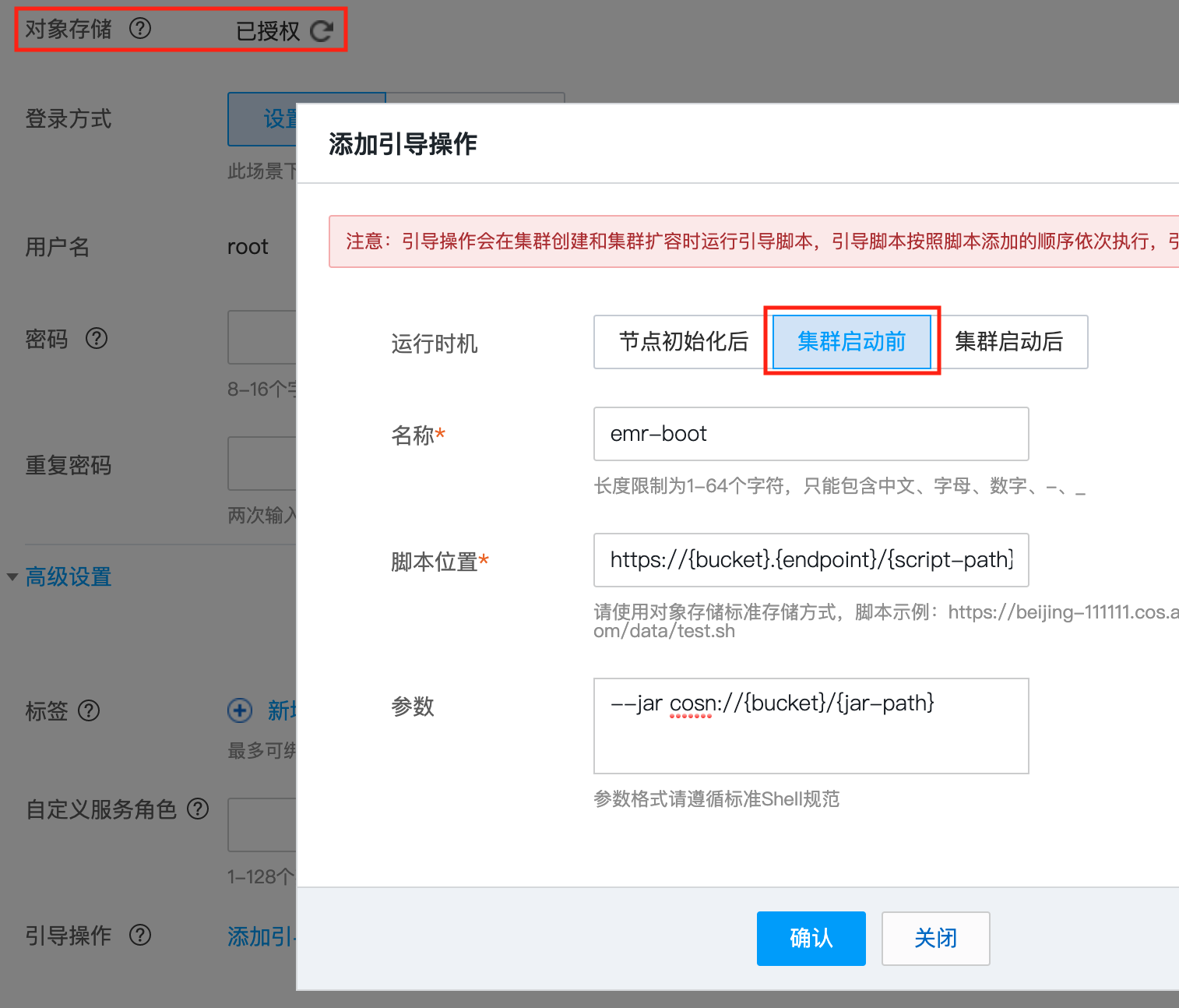
对象存储需授权,引导操作的运行时机为「集群启动前」。
「脚本位置」填写
emr-boot.sh在 COS 上面的地址,「参数」填写juicefs-hadoop-{version}.jar在 COS 上面的地址。-
可以访问公网
--jar cosn://{bucket}/{jar-path}
-
-
启动集群
金山云 KMR
Amazon EMR
-
进入 Software and Steps 界面:
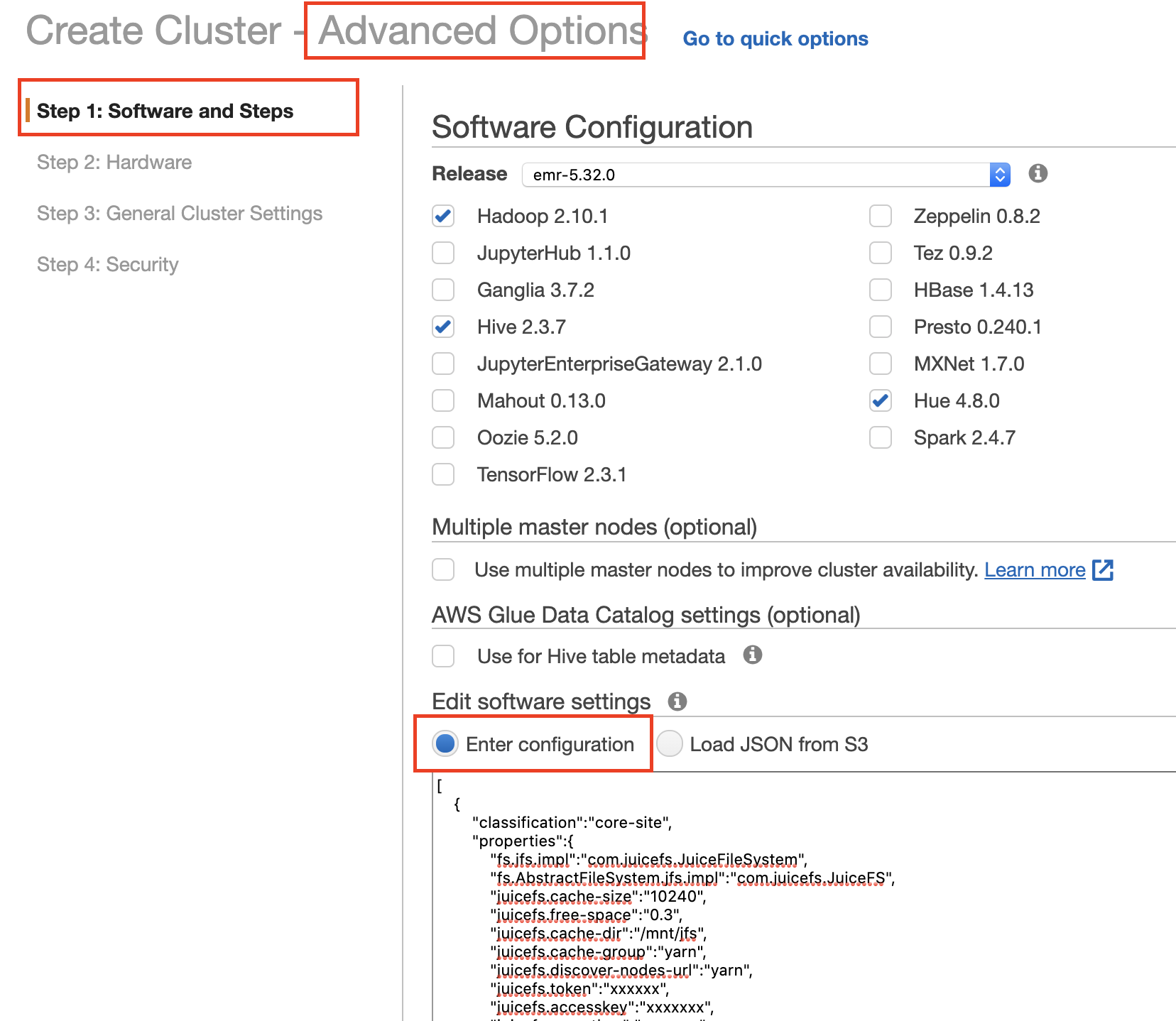
填写 JuiceFS 相关配置,格式如下:
[
{
"classification": "core-site",
"properties": {
"fs.jfs.impl": "com.juicefs.JuiceFileSystem",
"fs.AbstractFileSystem.jfs.impl": "com.juicefs.JuiceFS",
"juicefs.token": "",
...
}
}
]使用 HBase on JuiceFS 配置:
[
{
"classification": "core-site",
"properties": {
"fs.jfs.impl": "com.juicefs.JuiceFileSystem",
"fs.AbstractFileSystem.jfs.impl": "com.juicefs.JuiceFS"
...
}
},
{
"classification": "hbase-site",
"properties": {
"hbase.rootdir": "jfs://{VOLUME}/hbase"
}
}
] -
在 General Cluster Settings 界面添加引导操作
下载
emr-boot.sh脚本和juicefs-hadoop.jar,并上传到您的对象存储上。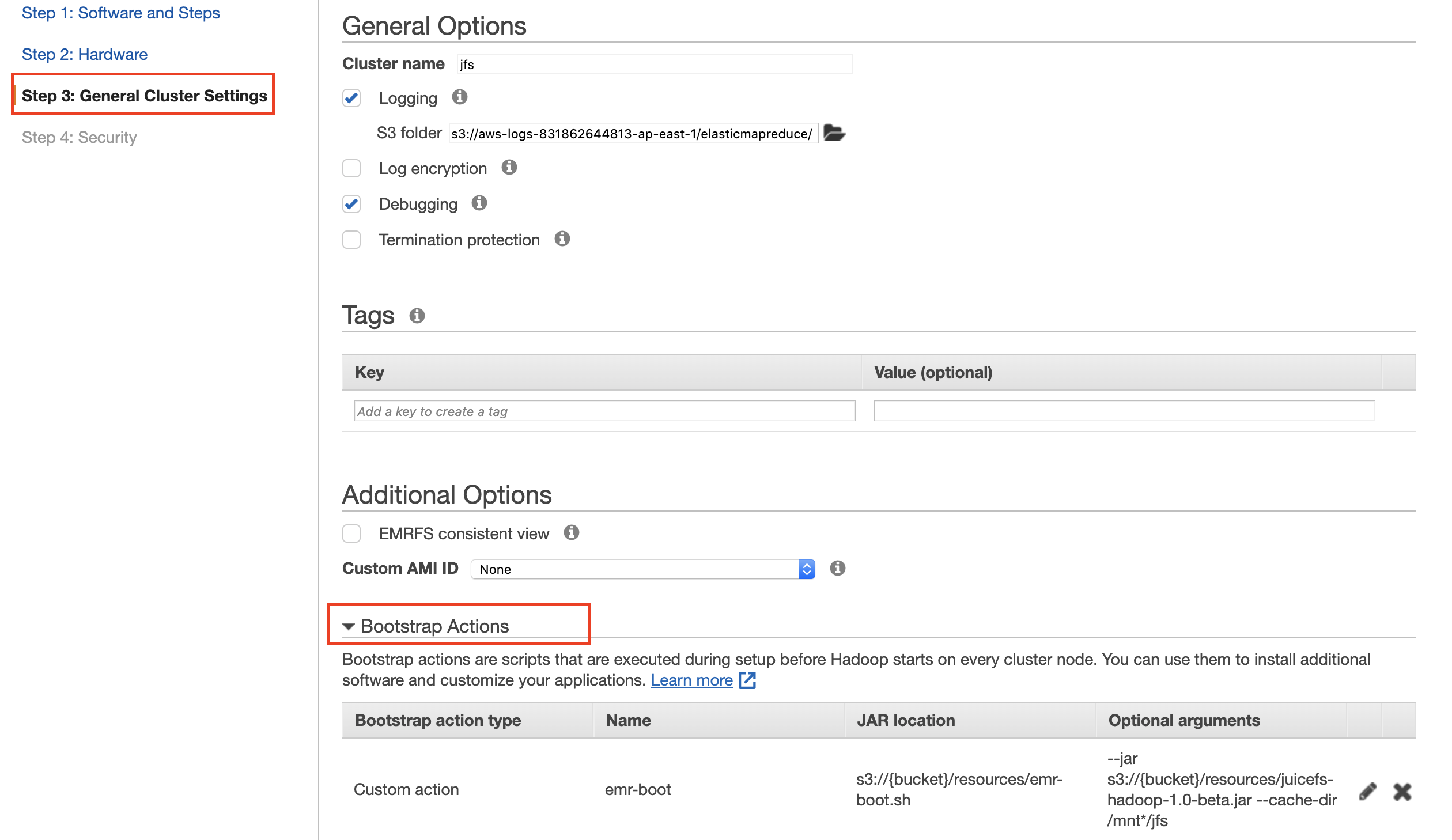
「脚本位置」填写
emr-boot.sh的 S3 地址,「参数」填写juicefs-hadoop-{version}.jar的 S3 地址。--jar s3://{bucket}/resources/juicefs-hadoop-{version}.jar
为特定 Hadoop 应用安装
如果你仅仅希望为特定应用安装 Hadoop SDK,需要将下载的 juicefs-hadoop.jar 和 $JAVA_HOME/lib/tools.jar 加入到应用对应的目录(下方表格所示)。
| 名称 | 安装目录 |
|---|---|
| Hadoop | ${HADOOP_HOME}/share/hadoop/common/lib/ |
| Hive | ${HIVE_HOME}/auxlib |
| Spark | ${SPARK_HOME}/jars |
| Presto | ${PRESTO_HOME}/plugin/hive-hadoop2 |
| Trino | ${TRINO_HOME}/plugin/hive 或者 ${TRINO_HOME}/plugin/hive/hdfs(当新版本 Trino 的 plugin/hive 目录下有 hdfs 文件夹时) |
| Flink | ${FLINK_HOME}/lib |
| DataX | ${DATAX_HOME}/plugin/writer/hdfswriter/libs ${DATAX_HOME}/plugin/reader/hdfsreader/libs |
Apache Spark
- 安装
juicefs-hadoop.jar文件 - 添加 JuiceFS 配置,Apache Spark 有多种方法引入配置:
-
修改
core-site.xml文件 -
命令行传入
spark-shell --master local[*] \
--conf spark.hadoop.fs.jfs.impl=com.juicefs.JuiceFileSystem \
--conf spark.hadoop.fs.AbstractFileSystem.jfs.impl=com.juicefs.JuiceFS \
--conf spark.hadoop.juicefs.token=xxx \
--conf spark.hadoop.juicefs.accesskey=xxx \
--conf spark.hadoop.juicefs.secretkey=xxx \
... -
通过修改 $SPARK_HOME/conf 目录下的
spark-defaults.conf文件
-
Apache Flink
- 安装
juicefs-hadoop.jar文件 - 添加 JuiceFS 配置,Apache Flink 有多种方法引入配置:
- 通过修改
core-site.xml文件 - 通过修改
flink-conf.yaml文件
- 通过修改
Presto
- 安装
juicefs-hadoop.jar文件 - 通过修改过
core-site.xml添加 JuiceFS 配置
DataX
-
安装
juicefs-hadoop.jar文件 -
修改 DataX 配置文件:
"defaultFS": "jfs://myjfs",
"hadoopConfig": {
"fs.jfs.impl": "com.juicefs.JuiceFileSystem",
"fs.AbstractFileSystem.jfs.impl": "com.juicefs.JuiceFS",
"juicefs.token": "xxx",
"juicefs.accesskey": "xxx",
"juicefs.secretkey": "xxx"
}
HBase
修改 hbase-site:
"hbase.rootdir": "jfs://myjfs/hbase"
修改 hbase:
"hbase.emr.storageMode": "jfs"
常用配置
安装完毕后,需要在 core-site.xml 中对 JuiceFS 进行初步配置,该小节中梳理了最为关键的一系列配置,完整配置列表请见参数设置。
基础配置
fs.jfs.impl=com.juicefs.JuiceFileSystem
fs.AbstractFileSystem.jfs.impl=com.juicefs.JuiceFS
juicefs.token=
juicefs.accesskey=
juicefs.secretkey=
# 文件系统访问日志,日志量可能会比较大,生产环境中此项可不配置
juicefs.access-log=/tmp/juicefs.access.log
# 如果是私有部署环境,还需要填写控制台地址
juicefs.console-url=http://host:port
缓存配置
为了方便 Hadoop 下各应用访问缓存数据,我们推荐你提前手动创建缓存目录,并将目录权限设置为 777。更多请阅读「缓存」以了解相关设计。
# 本地缓存目录
juicefs.cache-dir=
# 缓存大小,单位 MiB
juicefs.cache-size=
# 如果启用分布式缓存,在这里填写组名
juicefs.cache-group=
# 需要根据不同使用场景填写不同参数
juicefs.discover-nodes-url=
对于客户端不断变动的情况(比如容器场景),考虑使用「独立缓存集群」,可以在独立缓存节点上挂载 JuiceFS 客户端,来建立独立缓存集群:
juicefs mount \
--buffer-size=2000 \
--cache-group=xxx \
--cache-group-size=512 \
--cache-dir=xxx \
--cache-size=204800 \
{$VOL_NAME} /jfs
独立缓存集群对应的常见 SDK 缓存配置:
juicefs.cache-dir=
juicefs.cache-size=
juicefs.cache-group=xxx
juicefs.discover-nodes-url=all
# 计算节点可能会动态变化,不需要加入缓存组,因此将 juicefs.no-sharing 设为 true
juicefs.no-sharing=true
测试验证
此处罗列各类 Hadoop 应用的验证步骤,确保能正常使用 JuiceFS。
Hadoop
hadoop fs -ls jfs://${VOL_NAME}/
hadoop fs -mkdir jfs://${VOL_NAME}/jfs-test
hadoop fs -rm -r jfs://${VOL_NAME}/jfs-test
Hive、SparkSQL、Impala
create table if not exists person(
name string,
age int
)
location 'jfs://${VOL_NAME}/tmp/person';
insert into table person values('tom',25);
insert overwrite table person select name, age from person;
select name, age from person;
drop table person;
Spark Shell
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs._
val conf = sc.hadoopConfiguration
val p = new Path("jfs://${VOL_NAME}/")
val fs = p.getFileSystem(conf)
fs.listStatus(p)
HBase
create 'test', 'cf'
list 'test'
put 'test', 'row1', 'cf:a', 'value1'
scan 'test'
get 'test', 'row1'
disable 'test'
drop 'test'
Flume
jfs.sources =r1
jfs.sources.r1.type = org.apache.flume.source.StressSource
jfs.sources.r1.size = 10240
jfs.sources.r1.maxTotalEvents=10
jfs.sources.r1.batchSize=10
jfs.sources.r1.channels = c1
jfs.channels = c1
jfs.channels.c1.type = memory
jfs.channels.c1.capacity = 100
jfs.channels.c1.transactionCapacity = 100
jfs.sinks = k1
jfs.sinks.k1.type = hdfs
jfs.sinks.k1.channel = c1
jfs.sinks.k1.hdfs.path =jfs://${VOL_NAME}/tmp/flume
jfs.sinks.k1.hdfs.writeFormat= Text
jfs.sinks.k1.hdfs.fileType= DataStream
Flink
echo 'hello world' > /tmp/jfs_test
hadoop fs -put /tmp/jfs_test jfs://${VOL_NAME}/tmp/
rm -f /tmp/jfs_test
./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar --input jfs://${VOL_NAME}/tmp/jfs_test --output jfs://${VOL_NAME}/tmp/result
重启相关服务
安装、升级 Hadoop SDK,或者调整配置,需要重启相关服务,才能令配置生效。
-
无需重启组件:
- HDFS
- HUE
- ZooKeeper
-
以下各组件服务,只有当用到 JuiceFS 时才需要重启。如果启用 HA,可以通过滚动重启,不影响使用。
- YARN
- Hive Metastore Server, HiveServer2
- Spark ThriftServer
- Spark Standalone
- Master
- Worker
- Presto
- Coordinator
- Worker
- Impala
- Catalog Server
- Daemon
- HBase
- Master
- RegionServer
- Flume
最佳实践
Hadoop
Hadoop 生态组件一般通过 org.apache.hadoop.fs.FileSystem 类与 HDFS 对接,JuiceFS 同样也通过继承这个类来支持 Hadoop 生态的各个组件。
Hadoop SDK 启用后,就可以通过 hadoop fs 命令操作 JuiceFS:
hadoop fs -ls jfs://{VOL_NAME}/
如果想省去 jfs:// 协议前缀,可以将 fs.defaultFS 设置为 JuiceFS 地址,在 core-site.xml 里面增加如下配置:
<property>
<name>fs.defaultFS</name>
<value>jfs://{VOL_NAME}</value>
</property>
修改 defaultFS 会导致所有没有带协议的路径默认均指向 JuiceFS,可能会导致一些其他问题,建议先在测试环境中测试。
Hive
在 Hive 中建库建表时,使用 LOCATION 来指定存储数据的具体路径。
-
建库建表
-- create database
CREATE DATABASE ... database_name
LOCATION 'jfs://{VOL_NAME}/path-to-database';
-- create table
CREATE TABLE ... table_name
LOCATION 'jfs://{VOL_NAME}/path-to-table';Hive create 的表,默认会在 database 的 location 下。如果 database 的 location 已经在 JuiceFS 上,新建 table 默认也会在 JuiceFS 上。
-
改库改表
ALTER DATABASE database_name
SET LOCATION 'jfs://{VOL_NAME}/path-to-database';
ALTER TABLE table_name
SET LOCATION 'jfs://{VOL_NAME}/path-to-table';
ALTER TABLE table_name PARTITION(...)
SET LOCATION 'jfs://{VOL_NAME}/path-to-partition';Hive 支持使用多种文件系统存储数据。对于未分区表,整张表的数据必须是在同一个文件系统上。对于分区表,每个分区可以独立设置文件系统。
如果想默认建库就在 JuiceFS 上,可以通过将
hive.metastore.warehouse.dir修改为 JuiceFS 上的路径。
Spark
Spark 有多种运行模式,如 Standalone、YARN、Kubernetes、Thrift Server 等。
由于 JuiceFS 分��布式缓存设计,JuiceFS 需要保证客户端的机器 IP 尽量不变才能保证缓存的高效利用。因此,Spark 各种运行模式对于 JuiceFS 的最主要区别就是 executor 进程是否常驻,executor 所在机器的 IP 是否经常变化。
在 executor 进程常驻(例如 Thrift Server 模式),或者在 executor 所在的机器 IP 基本固定并且集群使用率比较高时(Spark on YARN,Standalone),使用分布式缓存。juicefs.discover-nodes-url 参数需要做相应的设置。
在 executor 进程经常变化,并且机器 IP 也经常变化时(Spark on K8s),使用「独立缓存集群」方案。juicefs.discover-nodes-url 设置为 all。
-
Spark shell
scala> sc.textFile("jfs://{VOL_NAME}/path-to-input").count
HBase
HBase 主要在 HDFS 存储两部分数据,WAL 文件以及 HFile。写入数据时,会先写 WAL,然后再通过 hflush 将数据写入 RegionServer 的 memstore。这样可以保证即使 RegionServer 异常退出时,已经提交的数据仍然可以通过 WAL 恢复。当 RegionServer 里面的数据已经落入 HDFS 形成 HFile 后,WAL 文件会被删除,所以整体 WAL 文件对空间的使用量不会很大。
由于 JuiceFS hflush 的实现与 HDFS 有别,当 juicefs.hflush 设置为 sync 时,JuiceFS 的 hflush 性能比较慢,因此建议将 WAL 文件写入 HDFS,最终的 HFile 写入 JuiceFS。
<property>
<name>hbase.rootdir</name>
<value>jfs://{VOL_NAME}/hbase</value>
</property>
<property>
<name>hbase.wal.dir</name>
<value>hdfs://{NAME_SPACE}/hbase-wal</value>
</property>
Flink
Apache Flink 若使用 Streaming File Sink 从文件系统读写数据。为了保证数据的可靠性,Flink 需要在 checkpoint 时使用 RollingPolicy。
对于版本小于 2.7 的 Hadoop 版本,由于 HDFS 没有 truncate 功能,需要使用 OnCheckpointRollingPolicy,每次 checkpoint 都关闭并生成新的文件写入数据,会导致大量小文件。
Hadoop2.7 及以上版本的 HDFS,可以使用 DefaultRollingPolicy,可以根据文件大小、时间以及空闲时间来滚动文件。
JuiceFS 实现了 truncate 功能,所以同样也可以使用 DefaultRollingPolicy。
Flink 支持使用 plugin 的模式对接文件系统,将 juicefs-hadoop.jar 文件放到 lib 目录下即可。
Flume
JuiceFS 同样利用 HDFS sink 与 Flume 集成。hdfs.batchSize 表示多少消息调用一次 hflush 接口。
为了保证数据不丢失,juicefs.hflush 应设置为 sync,同时应该将 hdfs.batchSize 调大,将每个批次的数量控制在消息总大小 4MB(默认每个对象块的大小)左右。
另外如果启用了数据压缩(hdfs.fileType 设为 CompressedStream),极端情况下如果出现对象存储不可写入的情况,可能会导致整个压缩文件损坏,导致之前已经 hflush 的数据仍然不可读。如果有这方面的顾虑,建议将 hdfs.fileType 设置为 DataStream,后续再通过 ETL 任务进行数据压缩。
Sqoop
使用 Sqoop 将数据导入 Hive 时,Sqoop 会首先把数据导入 target-dir,然后在通过 hive load 命令将数据加载到 Hive 表,所以使用 Sqoop 时,需要修改 target-dir。
-
1.4.6
使用此版本的 Sqoop 时还需要将
fs设为 JuiceFS,因此还需将 HDFS 上面的mapreduce.tar.gz复制到 JuiceFS 上的相同路径,默认目录在 HDFS/hdp/apps/${hdp.version}/mapreduce/mapreduce.tar.gzsqoop import \
-fs jfs://{VOL_NAME}/ \
--target-dir jfs://{VOL_NAME}/path-to-dir -
1.4.7
sqoop import \
--target-dir jfs://{VOL_NAME}/path-to-dir


