数据迁移
从 JuiceFS 5.0 开始,对象存储中已有的数据可以直接以只读方式导入 JuiceFS 并利用上 JuiceFS 强大的缓存能力功能,详见 juicefs import。
如果导入的方式无法满足需求,那么需要将数据迁移到 JuiceFS,在此介绍平滑和离线迁移两种手段。
Hive
JuiceFS Java Client 支持创建指向 HDFS 的符号链接,可以实现将 HDFS 中的数据平滑地迁移到 JuiceFS,并且对业务透明。
以 Hive 为例,下面将会分别介绍两种方案,这两种方案本质上都是基于 JuiceFS 的符号链接来实现,只是一种需要修改 Hive metadata 中的 LOCATION,另一种不需要。可以根据实际情况选择其中一种方案。
方案一:修改 LOCATION
这个方案需要修改 Hive 库、表或者分区的 LOCATION 信息,将 hdfs://{ns} 改为 jfs://{vol_name}。迁移的时候可以做到表级别迁移。
准备阶段
在准备阶段,主要包含部署 JuiceFS 基础环境,在 JuiceFS 的根路径下建立对应 HDFS 的符号链接,以及迁移回收站目录到 JuiceFS 上。在此阶段,数据读写仍然是在 HDFS 上,所以不会出现任何的数据不一致问题。
注意此阶段所有命令都需要使用 HDFS 的 superuser 来运行,一般集群默认为 hdfs 用户。
-
为相关服务的(如 Hive)
core-site.xml增加新的 JuiceFS Java Client 配置:<property>
<name>juicefs.migrating</name>
<value>true</value>
</property> -
重启相关服务。
-
初始化 JuiceFS:
java -cp `hadoop classpath`:${HIVE_HOME}/lib/* juicefs-hadoop.jar com.juicefs.Main hive \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--init此操作会在 JuiceFS 的根路径
/下面创建到 HDFS 根路径/的所有符号链接,如下图: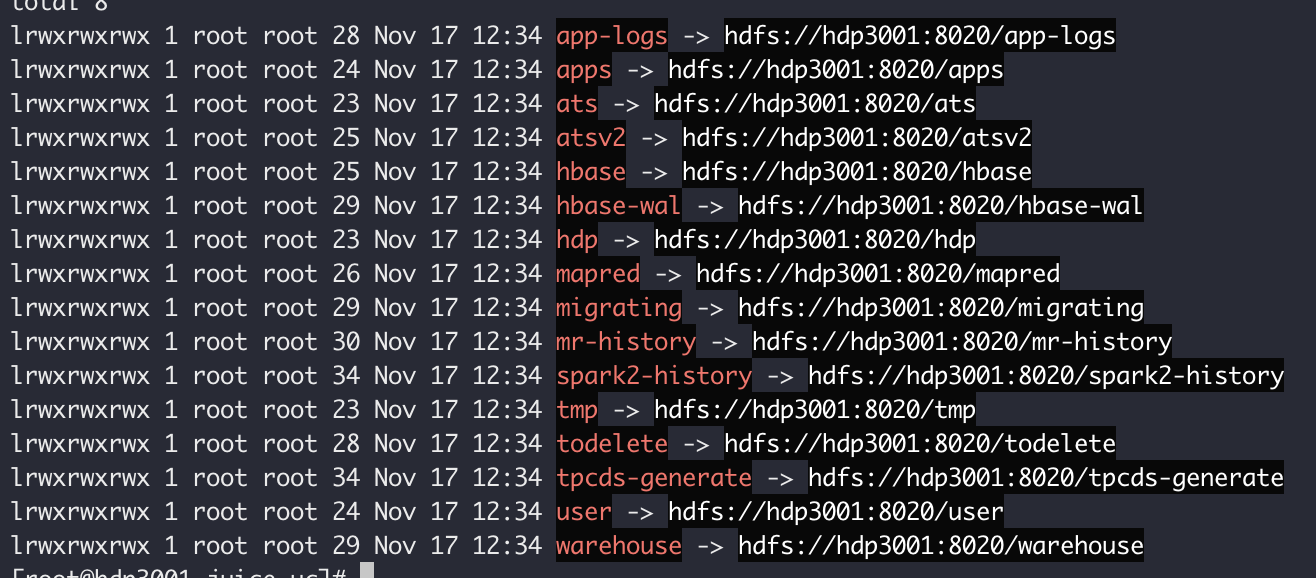
这些符号链接可以通过挂载 JuiceFS 以后看到,虽然能看到符号链接,但在 FUSE 下并没有办法解析,你只能在 Java Client 中看到符号链接指向的内容。
-
初始化
.Trash目录:java -cp `hadoop classpath`:${HIVE_HOME}/lib/* juicefs-hadoop.jar com.juicefs.Main hive \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--init-trash由于 Hive 或者 Spark 等任务运行的时候,会将部分删除的数据 rename 到
/user/{username}/.Trash目录下。由于不支持跨文件系统 rename,所以需要先将 Trash 目录迁移过来。
准备阶段完成以后可以查看 juicefs.access-log 配置的文件(默认为 /tmp/juicefs.access.log),看是否包含 cmd: Lookup (/.MIGRATING,1) 来验证配置是否成功。
数据迁移阶段
在此阶段,将会包含几个步骤:修改 Hive 表或者分区的 LOCATION 信息、同步目录结构以及数据迁移。
修改 LOCATION 以后,数据读写仍然在 HDFS 上。在同步目录结构步骤完成以后,新增数据将会写入 JuiceFS。在数据迁移步骤,历史数据也将拷贝到 JuiceFS 上来。
-
修改 Hive 表的
LOCATION信息:java -cp `hadoop classpath`:${HIVE_HOME}/lib/*:juicefs-hadoop.jar com.juicefs.Main hive \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--hive-meta thrift://{host:port} \
--tables {db_name}[:{table_name} [, {table_name}] ...]此命令会将 Hive 表的
LOCATION改为 JuiceFS 的地址,即将--src-fs替换为--dst-fs设置的值。对于分区表,还会同步修改所有分区的LOCATION。由于准备阶段已经在 JuiceFS 的根路径下面建立了指向 HDFS 的符号链接,因此这个时候 Hive 仍然是通过 HDFS 访问数据,只是地址改为了 JuiceFS 的地址。上面命令中的--tables选项支持几种格式:- 只指定数据库名称:
--tables {db_name}。这会修改对应数据库中的所有表。 - 指定一张或多张表:
--table {db_name}:{table_name},{table_name}。 - 你也可以重复输入多个
--tables选项,来实现同样的效果。
- 只指定数据库名称:
-
同步目录结构:
java -cp `hadoop classpath`:${HIVE_HOME}/lib/*:juicefs-hadoop.jar com.juicefs.Main hive \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--hive-meta thrift://{host:port} \
--tables {db_name}[:{table_name} [, {table_name}] ...] \
--link相比上一步的命令行多了
--link选项,此选项会将 Hive 表LOCATION下面的所有目录结构从 HDFS 迁移过来,目录内的文件则以符号链接的方式链接到 HDFS 上。因为这一步仅涉及元数据操作,没有数据拷贝,因此可以以极快的速度将历史数据的目录结构从 HDFS 迁移到 JuiceFS 上。当部分目录在 HDFS,而另外一部分在 JuiceFS 时,跨越文件系统的 rename 操作会失败。上述命令在牵涉的文件发生跨系统 rename 操作时会卡住等待,默认超时时间为 10 分钟,为了确保操作顺利完成,你可以:
- 调整
juicefs.migrate.wait配置,默认值为 10,单位 min - 调整
--tables参数,减少一次迁移的文件量
当目录结构已经存在于 JuiceFS 上后,后续新写入的数据将直接写在 JuiceFS 上(如下图所示)。
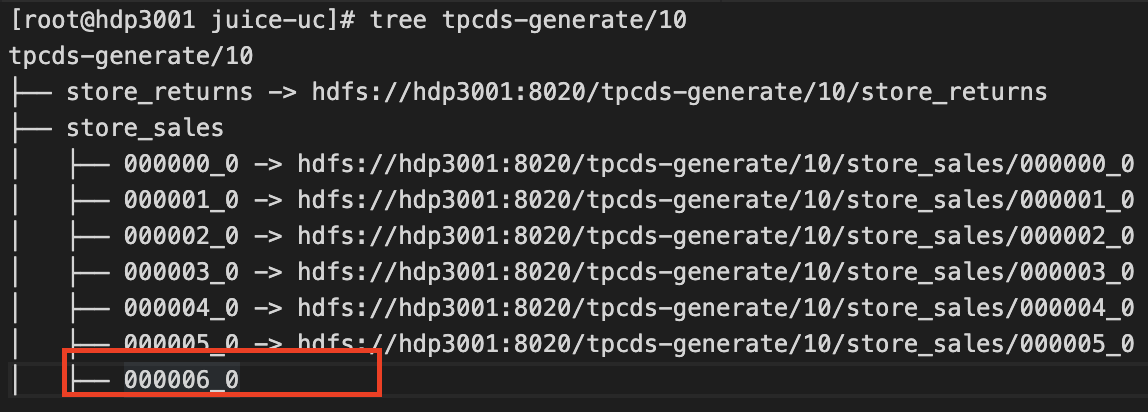
红框圈出的文件即为新增数据,直接存储于 JuiceFS 上。历史数据依旧以符号链接的方式指向 HDFS 中的地址。
- 调整
-
迁移数据:
java -cp `hadoop classpath`:${HIVE_HOME}/lib/*:juicefs-hadoop.jar com.juicefs.Main hive \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--hive-meta thrift://{host:port} \
--tables {db_name}[:{table_name} [, {table_name}] ...] \
--copy当指定
--copy选项后,历史数据将会�从 HDFS 逐步迁移到 JuiceFS 上,替换掉符号链接。默认会启动 10 个线程并发拷贝,你也可以通过--threads选项调整。或者在多个机器分别迁移不同的子目录来实现并行,加速数据拷贝。迁移数据完成后的示例如下图:
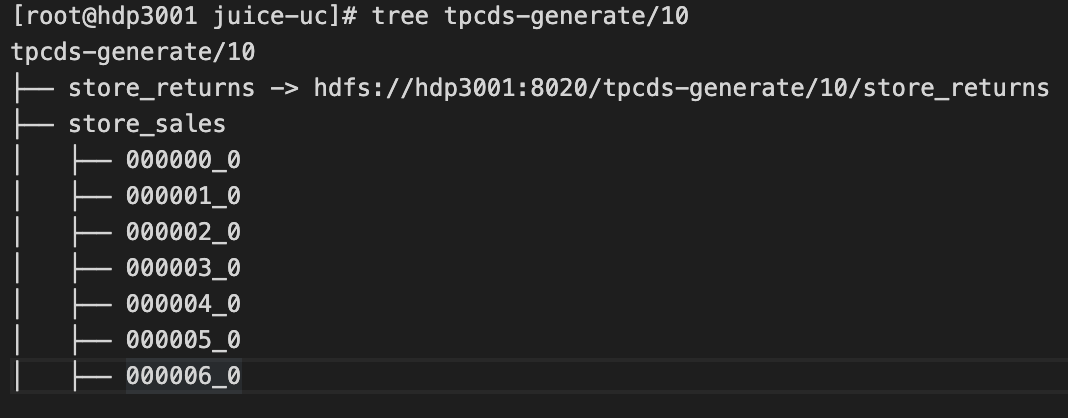
此目录下面的所有数据均已经拷贝到 JuiceFS。可以使用下面的命令确认此目录是否已经迁移完成:
find [path-to-table] -type l如果没有任何内容(即不存在符号链接),则此目录已经迁移完成,后续针对于此目录的所有操作均是在 JuiceFS 上面进行。
回滚
在迁移过程中可以随时回滚,来撤销迁移操作,不同阶段会对应不同的回滚操作。
-
在「准备阶段」回滚
在准备阶段由于所有的读写仍然在 HDFS 上,所以只需要修改 Hive 表或者分区的
LOCATION即可,然后滚动重启 Hive。java -cp `hadoop classpath`:${HIVE_HOME}/lib/* juicefs-hadoop.jar com.juicefs.Main hive \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--hive-meta thrift://{host:port} \
--tables {db_name}[:{table_name} [, {table_name}] ...] \
--reverse -
在「数据迁移阶段」回滚
首先关闭相关服务,让系统完全停止写入,然后用下方命令回滚 Hive 表或者分区的
LOCATION元信息,并且将数据更新同步回 HDFS。java -cp `hadoop classpath`:${HIVE_HOME}/lib/* juicefs-hadoop.jar com.juicefs.Main hive \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--hive-meta thrift://{host:port} \
--tables {db_name}[:{table_name} [, {table_name}] ...] \
--reverse
操作完成以后,滚动重启 Hive 以生效。
方案二:修改 HDFS 实现
这个方案不需要修改 Hive 库、表或者分区的 LOCATION 信息,只需要通过 core-site.xml 修改原有 HDFS 的实现,因此改动更少。但此法修改了 HDFS 的关键配置,可能对大数据平台��的其他组件产生兼容性影响,谨慎执行。
准备阶段
在准备阶段,主要包含部署 JuiceFS 基础环境,在 JuiceFS 的根路径下建立对应 HDFS 的符号链接,迁移回收站目录到 JuiceFS 上,以及修改 core-site.xml。
注意此阶段所有命令都需要使用 HDFS 的 superuser 来运行,一般集群默认为 hdfs 用户。在此阶段,数据读写仍然是在 HDFS 上,所以不会出现任何的数据不一致问题。
-
安装 Hadoop SDK。注意这一步可以暂时不用重启相关服务,后面会统一操作。
-
增加新的 JuiceFS Java 客户端配置:
<property>
<name>juicefs.migrating</name>
<value>true</value>
</property> -
初始化 JuiceFS:
java -cp $(hadoop classpath) juicefs-hadoop.jar com.juicefs.tools.Mover \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--init此操作会在 JuiceFS 的根路径“/”下面创建到 HDFS 根路径“/”的所有符号链接,如下图:
这些符号链接可以通过挂载 JuiceFS 以后看到,虽然能看到符号链接,但在 FUSE 下并没有办法解析,你只能在 Java Client 中看到符号链接指向的内容。
完成以后可以查看
juicefs.access-log配置的文件(默认为/tmp/juicefs.access.log),看是否包含cmd: Lookup (/.MIGRATING,1)来验证配置是否成功。 -
初始化 Trash 目录:
java -cp $(hadoop classpath) com.juicefs.tools.Mover \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--init-trash由于 Hive 或者 Spark 等任务运行的时候,会将部分删除的数据 rename 到
/user/{username}/.Trash目录下。由于不支持跨文件系统 rename,所以需要先将 Trash 目录迁移过来。 -
修改
core-site.xml,增加以下配置:<property>
<name>fs.hdfs.impl</name>
<value>com.juicefs.MigratingFileSystem</value>
</property>
<property>
<name>juicefs.migrate.src-fs</name>
<value>hdfs://{ns}/</value>
</property>
<property>
<name>juicefs.migrate.dst-fs</name>
<value>jfs://{vol_name}/</value>
</property>
<property>
<name>juicefs.caller-context</name>
<value>jfs</value>
</property>此步骤需要在所有 HDFS 节点上执行,使用 Ambari 可以方便地完成。
juicefs.caller-context是一个可选配置,用来在 HDFS audit log 中标识数据是通过 JuiceFS 访问的,在 audit log 里面会显示类似callerContext=*_jfs这样的字段。这个功能需要 Hadoop >= 2.8.0(HDFS-9184),并且开启hadoop.caller.context.enabled配置。 -
重启服务
常见的使用 JuiceFS 的服务有:YARN、HBase、Hive、Spark、Flume。建议直接重启机器上面的所有 Hadoop 相关服务。重启配置生效后,�后续提交的所有任务都将使用 JuiceFS 的实现去访问 HDFS。
数据迁移阶段
在此阶段,将会包含两个步骤:同步目录结构以及数据迁移。
-
同步目录结构:
java -cp $(hadoop classpath) com.juicefs.tools.Mover \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--dir [path-to-table]此操作将指定目录下的所有 HDFS 文件都在 JuiceFS 中创建出符号链接,效果如下:

当部分目录在 HDFS,而另外一部分在 JuiceFS 时,跨越文件系统的 rename 操作会失败。上述命令在牵涉的文件发生跨系统 rename 操作时会卡住等待,默认超时时间为 10 分钟,为了确保操作顺利完成,你可以:
- 调整
juicefs.migrate.wait配置,默认值为 10,单位 min - 调整
--tables参数,减少一次迁移的文件量
当目录结构已经存在于 JuiceFS 上后,后续新写入的数据将直接写在 JuiceFS 上(如下图所示)。
红框圈出的文件即为新增数据,直接存储于 JuiceFS 上。历史数据依旧以符号链接的方式指向 HDFS 中的地址。
- 调整
-
迁移数据:
java -cp $(hadoop classpath) com.juicefs.tools.Mover \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--dir [path-to-table] \
--copy当指定
--copy选项后,历史数据将会从 HDFS 逐步迁移到 JuiceFS 上,替换掉符号链接。默认会启动 10 个线程并发拷贝,你也可以通过--threads选项调整。或者在多个机器分别迁移不同的子目录来实现并行,加速数据拷贝。迁移数据完成后的示例如下图:
找不到指向 HDFS 的符号链接,即表示迁移已经完成,后续针对于此目录的所有操作均是在 JuiceFS 上面进行。
find [path-to-hive-table] -type l
回滚
在数据迁移过程中可以随时回滚,来撤销迁移操作。不同阶段会对应不同的回滚操作。
-
在「准备阶段」回滚
在准备阶段由于所有的读写仍然在 HDFS 上,所以只需要在
core-site.xml里面将fs.hdfs.impl配置项删除即可,然后分批滚动重启机器。 -
在「数据迁移阶段」回滚
此阶段可能已经有新增数据写入到 JuiceFS 里面了,所以需要关闭服务,让系统完全停止写入,然后用下方命令将新增数据拷贝回 HDFS:
java -cp $(hadoop classpath) juicefs-hadoop.tar com.juicefs.tools.Mover \
--src-fs hdfs://{ns} \
--dst-fs jfs://{vol_name} \
--dir [path-to-table] \
--reverse
方案三:离线迁移
停写,然后离线迁移,势必是更简单直接的迁移方式,推荐使用 juicefs sync 进行数据迁移,但你也可以用其他工具,比如 DistCp。
Hive 等数据仓库表的数据可以在不同的文件系统,迁移数据时可以使用 distcp 将 HDFS 中的数据拷贝至 JuiceFS,然后用 alter table 更新表的数据位置即可。
同一张表的不同分区的数据也可以在不同的文件系统,可以修改写入数据的代码,在插入新的分区数据时使用 JuiceFS,然后再逐步将已有分区的数据使用 distcp 拷贝过来后再更新分区的数据位置。
HBase
在线迁移
将历史数据导入新的 JuiceFS HBase 集群,并且和原 HBase 集群保持同步,一旦数据同步成功后,可以将业务切换到新的 JuiceFS HBase 集群。
在 原 HBase 集群中,
-
打开 replication
add_peer '1', CLUSTER_KEY => "jfs_zookeeper:2181:/hbase",TABLE_CFS => { "your_table" => []}
enable_table_replication 'your_table'此操作会在 JuiceFS HBase 集群自动�创建表(包括 splits)
-
关闭同步
disable_peer("1") -
创建快照
snapshot 'your_table','your_snapshot'
在 新的 JuiceFS HBase 集群中,
-
导入快照
sudo -u hbase hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot your_snapshot \
-copy-from s3://your_s3/hbase \
-copy-to jfs://your_jfs/hbase \
-mappers 1 \
-bandwidth 20您可以根据需要调整
map数和带宽(MB/s) -
恢复快照
disable 'your_table'
restore_snapshot 'your_snapshot'
enable 'your_table' -
在 原 HBase 集群中打开同步:
enable_peer("1")
离线迁移
在 原 HBase 集群中关闭所有表:
bin/disable_all_tables.sh
在 新的 JuiceFS HBase 集群中,
-
通过
distcp导入数据sudo -u hbase hadoop distcp -Dmapreduce.map.memory.mb=1500 your_filesystem/hbase/data jfs://your_jfs/hbase/data -
删除 HBase 元数据
sudo -u hbase hadoop fs -rm -r jfs://your_jfs/hbase/data/hbase -
修复元数据
sudo -u hbase hbase hbck -fixMeta -fixAssignments
数据校验
离线数据迁移大多需要专门进行完整性校验,推荐使用 juicefs sync 提供的 --check-all,--check-new 功能来进行完整性检查,十分便利。
如果你使用 DistCp,他使用 HDFS 的 getFileChecksum() 接口来获得 文件的校验码,然后对比拷贝后的文件的校验码来确保数据是一样的。
Hadoop 默认使用的 Checksum 算法是 MD5-MD5-CRC32, 严重依赖 HDFS 的实现细节。它是根据文件目前的分块形式,使用 MD5-CRC32 算法汇总每一个数据块的 Checksum(把每一个 64K 的 block 的 CRC32 校验码汇总,再算一个 MD5),然后再用 MD5 计算校验码。如果 HDFS 集群的分块大小不同,就没法用这个算法进行比较。
为了兼容 HDFS,JuiceFS 也实现了该 MD5-MD5-CRC32 算法,它会将文件的数据读一遍,用同样的算法计算得到一个 checksum,用于比较。
因为 JuiceFS 是基于对象存储实现的,后者已经通过多种 Checksum 机制保证了数据完整性,JuiceFS 默认没有启用上面的 Checksum 算法,需要通过参数 juicefs.file.checksum 来启用。
该算法的结果与分块大小相关,因此需要通过参数 juicefs.block.size 将分块大小设置为跟 HDFS 一样(默认 128MB,与 dfs.blocksize 相同)。注意,这里的 juicefs.block.size 中的 block,是 SDK 中对应着 dfs.blocksize 的逻辑概念,而不是 JuiceFS 在对象存储上传数据块的大小。
另外,HDFS 里支持给每一个文件设置不同的分块大小,而 JuiceFS 不支持,如果启用 Checksum 校验的话会导致拷贝部分文件失败(因为分块大小不同),JuiceFS 的 SDK 对 DistCp 打了一个热补丁(需要 tools.jar)来跳过这些分块不同的文件(不做比较,而不是抛异常)。
在使用 DistCp 做增量拷贝时,默认只是通过文件的修改时间和大小来判断文件内容是否相同,这对于 HDFS 是足够的(因为 HDFS 不允许修改文件内容)。如果想进一步确保两边的数据是相同的,可以通过 -update 参数来启用 Checksum 比较。


