JuiceFS 对比 3FS
3FS (Fire-Flyer File System) 是一款分布式文件系统,针对 AI 训练和推理工作负载设计,由 DeepSeek 开源。该系统使用 NVMe SSD 和 RDMA 网络提供共享存储层,面向大规模 AI 应用的 I/O 需求。
JuiceFS 是一个云原生分布式文件系统,其数据存储在对象存储中。社区版可与多种元数据服务集成,适用场景广泛,于 2021 年在 GitHub 开源。企业版专为高性能场景设计,广泛应用于大规模 AI 任务,涵盖生成式 AI、自动驾驶、量化金融和生物科技等。
本文从架构设计、文件分布、RPC 框架和功能特性等方面对 3FS 和 JuiceFS 进行全面对比。
架构对比
3FS
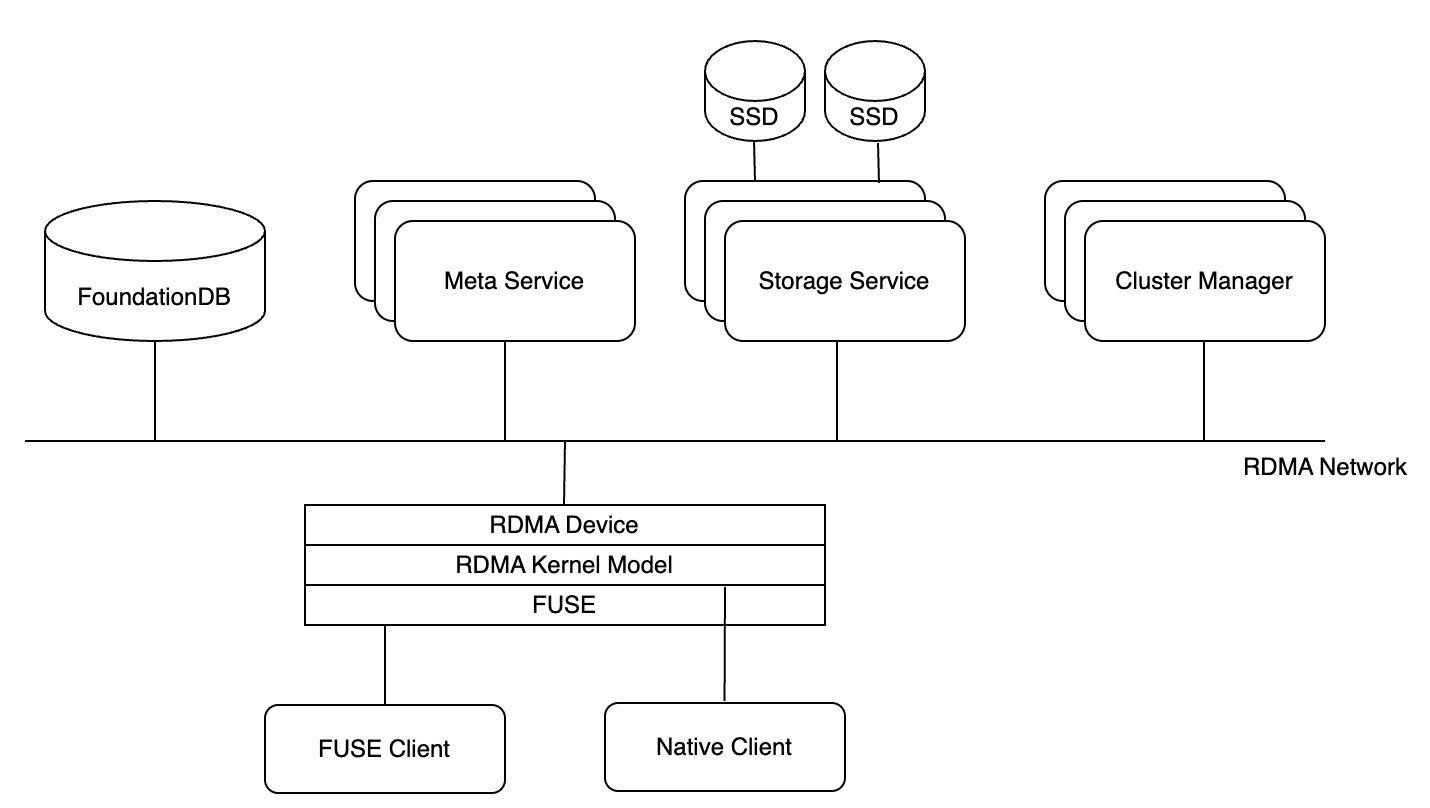
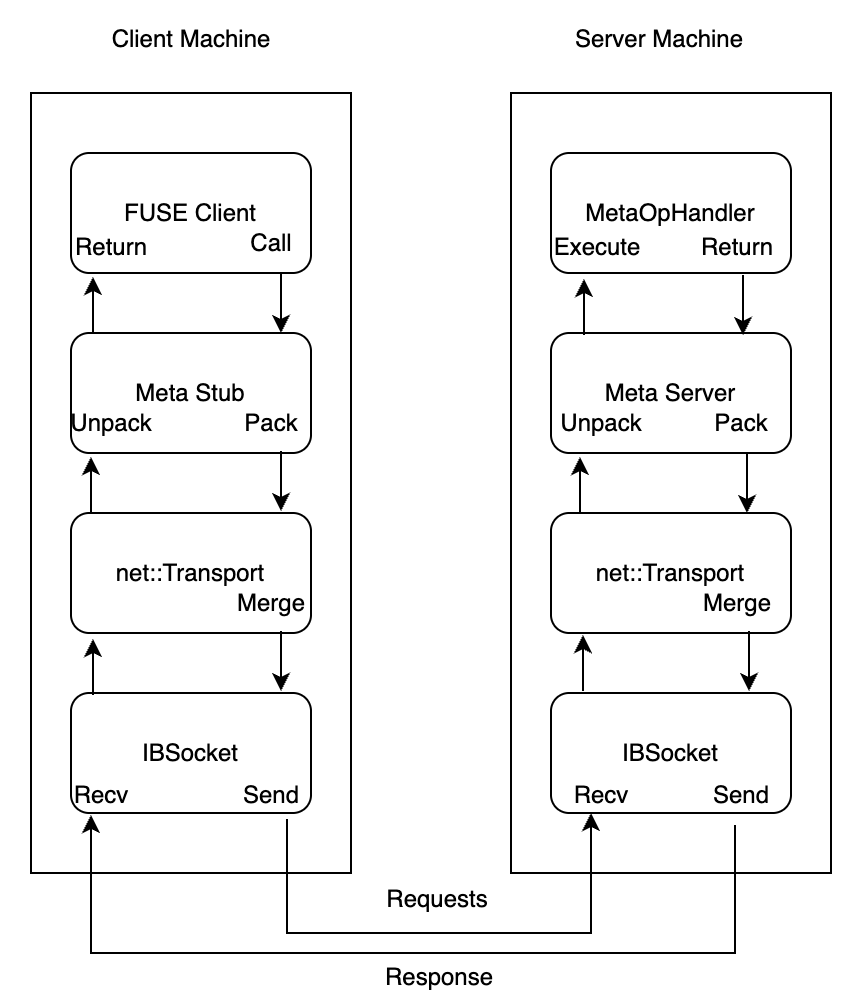
3FS 采用针对 AI 工作负载设计的架构,包含以下关键组件:
- 集群管理服务(Cluster Manager):处理成员变更,并将集群配置分发给其他服务和客户端。为了提高系统可靠性和避免单点故障,会部署多个集群管理服务,其中一个被选为主节点。
- 元数据服务(Metadata Service):无状态服务,处理文件元数据操作,依靠支持事务的键值数据库 FoundationDB 来存储元数据。
- 存储服务(Storage Service):使用本地 NVMe SSD 管理数据存储,采用 CRAQ(Chain Replication with Apportioned Queries)算法确保数据一致性。
- 客户端(Clients):提供 FUSE Client 以实现 POSIX 兼容性,以及 Native Client API 用于高性能零拷贝操作。
所有组件通过 RDMA 进行高性能网络通信。集群配置通常存储在可靠的分布式服务中,例如 ZooKeeper 或 etcd。
JuiceFS
JuiceFS 采用模块化的云原生架构,包含三个核心组件:
- 元数据引擎:用于存储文件元数据,包括常规文件系统的元数据和文件数据的索引。社区版支持 Redis、TiKV、MySQL、PostgreSQL、FoundationDB 等多种数据库。企业版使用自研高性能元数据服务。
- 数据存储:一般是对象存储服务,可以是公有云的对象存储也可以是私有部署的对象存储服务。支持与各种存储后端集成。
- JuiceFS 客户端:提供 POSIX(FUSE)、Hadoop SDK、CSI Driver、S3 网关等不同的接入方式。

架构差异
存储模块
3FS 使用本地 NVMe SSD 进行数据存储,为了保证数据存储的一致性,采用 CRAQ(Chain Replication with Apportioned Queries)算法。几个副本被组成一个 Chain,写请求从 Chain 的 Head 开始,一直到达 Chain 的 Tail 时返回写成功应答。读请求可以发送到 Chain 的所有副本,如果读到脏节点的数据,该节点会联系 Tail 节点检查状态。
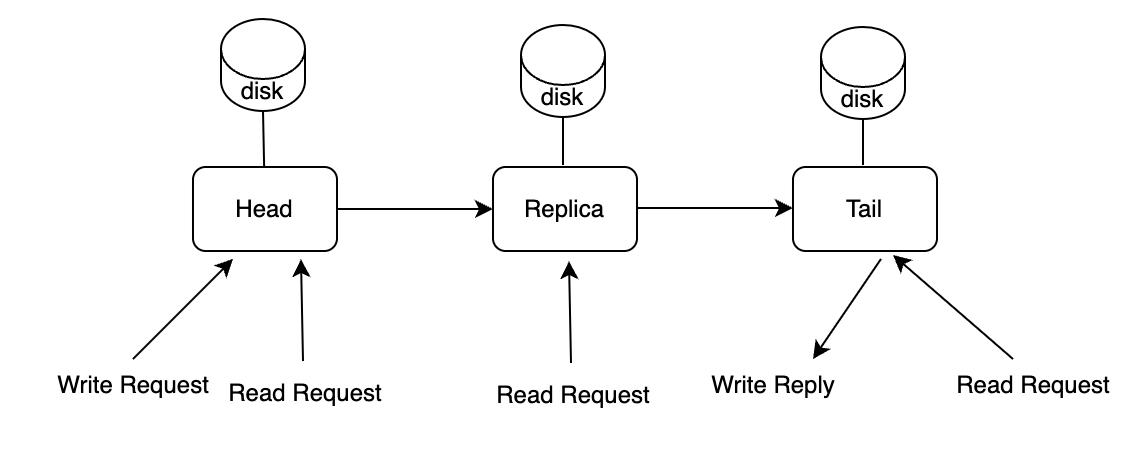
数据的写入是按顺序逐节点传递,因此会带来比较高的延时,但这种设计优先考虑读性能,这对于读密集型的 AI 工作负载至关重要。
相比之下,JuiceFS 利用对象存储作为数据存储解决方案,从而可享有对象存储带来的若干优势,如数据可靠性、一致性等。存储模块提供了一组用于对象操作的标准接口(GET/PUT/HEAD/LIST),可以与各种存储后端无缝集成。社区版 JuiceFS 提供本地缓存来应对 AI 场景下的带宽需求,企业版使用分布式缓存满足更大的聚合读带宽的需求。
元数据模块
在 3FS 中,文件的属性以 KV 的形式存储在元数据服务中。该服务是一个无状态的高可用服务,依靠 FoundationDB 做支撑。FoundationDB 所有键值使用 Key 做全局排序,然后均匀拆分到不同的节点上。为了优化 list 目录的效率,3FS 使用字符 "DENT" 前缀加父目录 inode 号和名字作为 dentry 的 Key。
JuiceFS 社区版的元数据模块提供一组操作元数据的接口,可以接入不同的元数据服务,比如 Redis、TiKV 等 KV 数据库,MySQL、PostgreSQL 等关系型数据库,也可以使用 FoundationDB。JuiceFS 企业版使用自研高性能元数据服务,可根据负载情况来平衡数据和热点操作,以避免大规模训练中元数据服务热点集中在某些节点的问题。
客户端
3FS 的客户端除了提供 FUSE 操作外,还提供了一组 API 用于绕过 FUSE 直接操作数据,也就是 Native Client。这组 API 的作用是避免使用 FUSE 模块带来的数据拷贝,从而减少 I/O 延迟和对内存带宽的占用,通过共享内存和信号量实现零拷贝通信。
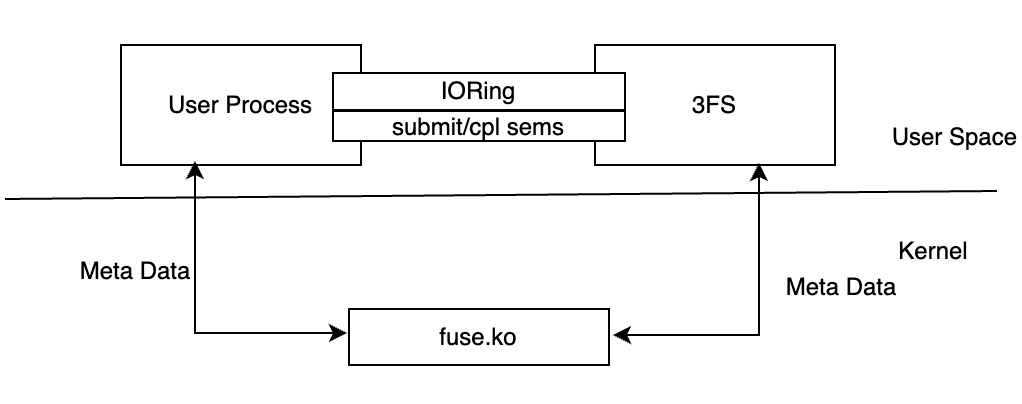
3FS 通过 hf3fs_iov 保存共享内存的大小、地址和其他一些属性,使用 IoRing 在两个进程间通信。系统创建虚拟文件并使用信号量来促进用户进程和 FUSE 进程之间的通信。
JuiceFS 的 FUSE 客户端实现更加全面,提供以下功能:
- 在每次成功上传对象后会立即更新文件长度。
- 支持 BSD 锁(flock)和 POSIX 锁(fcntl)。
- 支持高级接口如
file_copy_range、readdirplus和fallocate。
除了 FUSE 客户端,JuiceFS 社区版还提供 Java SDK、Python SDK、S3 网关、CSI Driver 等用于用户空间执行��的功能,企业版在此基础上提供了更多企业级特性。
文件分布对比
3FS 文件分布
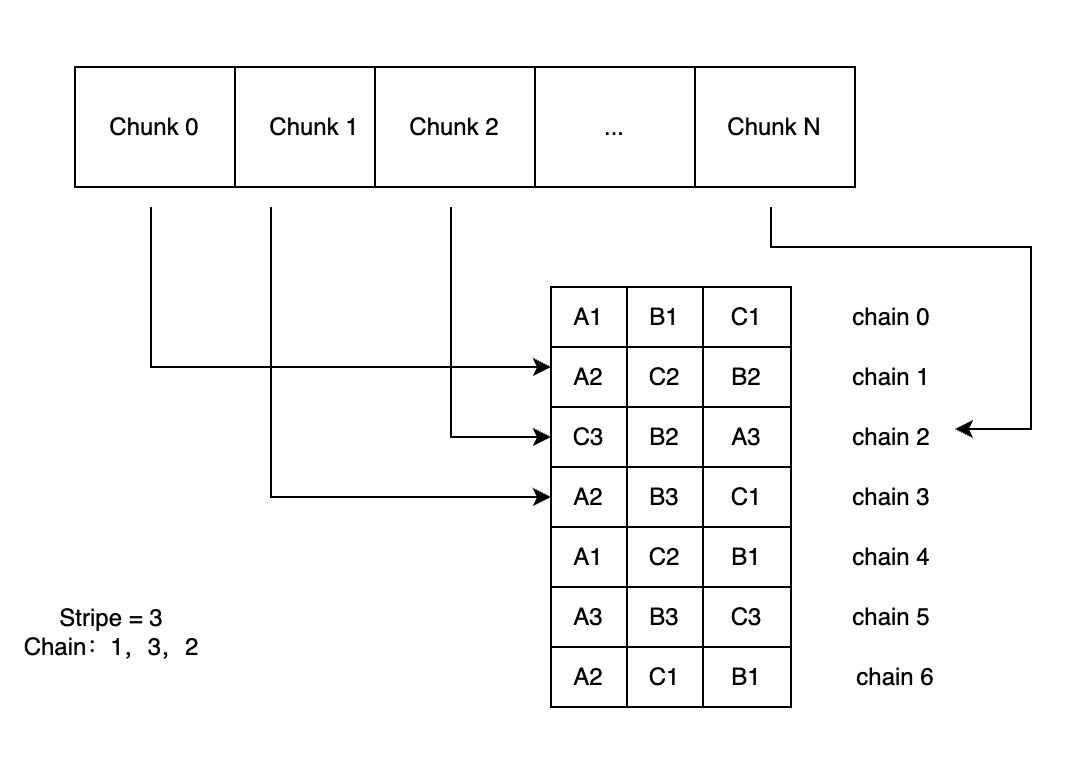
3FS 将每个文件分成固定长度的 chunk,每个 chunk 位于一个链上(CRAQ 算法)。因为 3FS 中的 chunk 是固定的,客户端只需要获取一次 inode 的 chain 信息,就可以根据文件 inode 和 I/O 请求的 offset、length 计算出这个请求位于哪些 chunk 上,从而避免了每个 I/O 都从数据库查询的需求。可以通过 offset/chunk_size 得到 chunk 的索引,而 chunk 所在的 chain 的索引就是 chunk_id%stripe。
为了应对数据不平衡问题,每个文件的第一个 chain 按照轮询(round robin)的方式选择。创建文件时,系统会将选择的 chain 做随机排序,然后存储到元数据中。
JuiceFS 文件分布
JuiceFS 按照 Chunk、Slice、Block 的规则进行数据块管理。每个 Chunk 的大小固定为 64M,主要用于优化数据的查找和定位。实际的文件写入操作则在 Slice 上执行,Slice 代表块内连续的写入过程。Block(默认大小为 4M)则是物理存储的基本单位,用于在对象存储和磁盘缓存中实现�数据的最终存储。

JuiceFS 中的 Slice 是在其他文件系统中不常见的一个结构。主要功能是记录文件的写入操作,并在对象存储中进行持久化。由于对象存储不支持原地文件修改,JuiceFS 通过引入 Slice 结构允许更新文件内容,而无需重写整个文件。JuiceFS 的所有 Slice 均为一次性写入,这减少了对底层对象存储一致性的依赖,并大大简化了缓存系统的复杂度。
3FS RPC 框架
3FS 使用 RDMA 作为底层网络通信协议,目前 JuiceFS 尚未支持。3FS 通过实现一个 RPC 框架,来完成对底层 IB 网络的操作。除了网络操作外,RPC 框架还提供序列化、小包合并等能力,使用模版实现了一个反射库,用于序列化 RPC 使用的 request、response 等数据结构。
3FS 的缓存有两部份组成,一个 TLS(Thread-Local Storage)队列和一个全局队列。从 TLS 队列获取缓存时不需要加锁;当 TLS 缓存为空时就得加锁,从全局队列中获取缓存。多个 RPC 请求可能被合并为一个 InfiniBand 请求以提高效率。
功能特性对比
| 功能特性 | 3FS | JuiceFS 社区版 | JuiceFS 企业版 |
|---|---|---|---|
| 元数据 | 无状态元数据服务+FoundationDB | 独立数据库服务 | 自研高性能分布式元数据引擎(可横向扩展) |
| 数据存储 | 自主管理 | 使用对象存储 | 使用对象存储 |
| 冗余保护 | 多副本 | 对象存储提供 | 对象存储提供 |
| 数据缓存 | 无缓存 | 本地缓存 | 自研高性能多副本分布式缓存 |
| 数据加密 | 不支持 | 支持 | 支持 |
| 数据压缩 | 不支持 | 支持 | 支持 |
| 配额管理 | 不支持 | 支持 | 支持 |
| 网络协议 | RDMA | TCP | TCP/RDMA |
| 快照 | 不支持 | 支持克隆 | 支持克隆 |
| POSIX ACL | 不支持 | 支持 | 支持 |
| POSIX 兼容性 | 少量子集 | 完全兼容 | 完全兼容 |
| CSI 驱动 | 没有官方支持 | 支持 | 支持 |
| 客户端 | FUSE + Native Client | POSIX(FUSE)、Java SDK、Python SDK、S3 网关 | POSIX(FUSE)、Java SDK、S3 网关、Python SDK |
| 多云镜像 | 不支持 | 不支持 | 支持 |
| 跨云和跨区数据复制 | 不支持 | 不支持 | 支持 |
| 主要维护者 | DeepSeek | Juicedata | Juicedata |
| 开发语言 | C++, Rust (本地存储引擎) | Go | Go |
| 开源协议 | MIT | Apache License 2.0 | 商业软件 |
总结
大规模 AI 训练中最主要的需求是高读带宽,为此 3FS 采用了性能优先的设计策略:
- 本地存储:将数据存储在本地 NVMe SSD 上,用户需要自行管理底层数据存储基础设施。
- 零拷贝优化:实现了客户端到网卡的零拷贝,利用共享内存和信号量减少 I/O 延迟和内存带宽占用。
- RDMA 网络:引入了 RDMA 技术,提供更好的网络性能。
- 优化的 I/O:通过带 TLS 的 I/O buffer pool 和合并网络请求,增强了小 I/O 和文件元数据操作的能力。
这种方法提升了性能,但成本较高,维护也更繁重。
JuiceFS 使用对象存储作为底层数据存储,用户因此可大幅降低存储成本并简化维护工作。为了满足 AI 场景的对读性能的需求:
- 企业版功能:分布式缓存、分布式元数据服务和 Python SDK。
- 高性能网络:5.2 版本起支持 TCP 零拷贝,5.3 版本起支持 RDMA。
- 云原生优势:提供完整的 POSIX 兼容性和成熟活跃的开源生态,支持 Kubernetes CSI。
- 企业级能力:Quota、安全管理和数据灾备等多项企业级管理功能。


