JuiceFS 对比 Lustre
Lustre 是一款专为高性能计算(HPC)环境设计的并行分布式文件系统,最初在美国政府资助下,由多个国家实验室联合开发,旨在支持大规模科学研究和工程计算任务。当前,Lustre 的主要开发与维护由 DDN(DataDirect Networks)负责,广泛应用于超算中心、科研机构及企业级 HPC 集群中。
JuiceFS 是一个云原生分布式文件系统,其数据存储在对象存储中。社区版可与多种元数据服务集成,适用场景广泛,于 2021 年在 GitHub 开源。企业版专为高性能场景设计,广泛应用于大规模 AI 任务,涵盖生成式 AI、自动驾驶、量化金融和生物科技等。
本文从架构设计、文件分布和功能特性等方面对 Lustre 和 JuiceFS 进行全面对比。
架构对比
Lustre
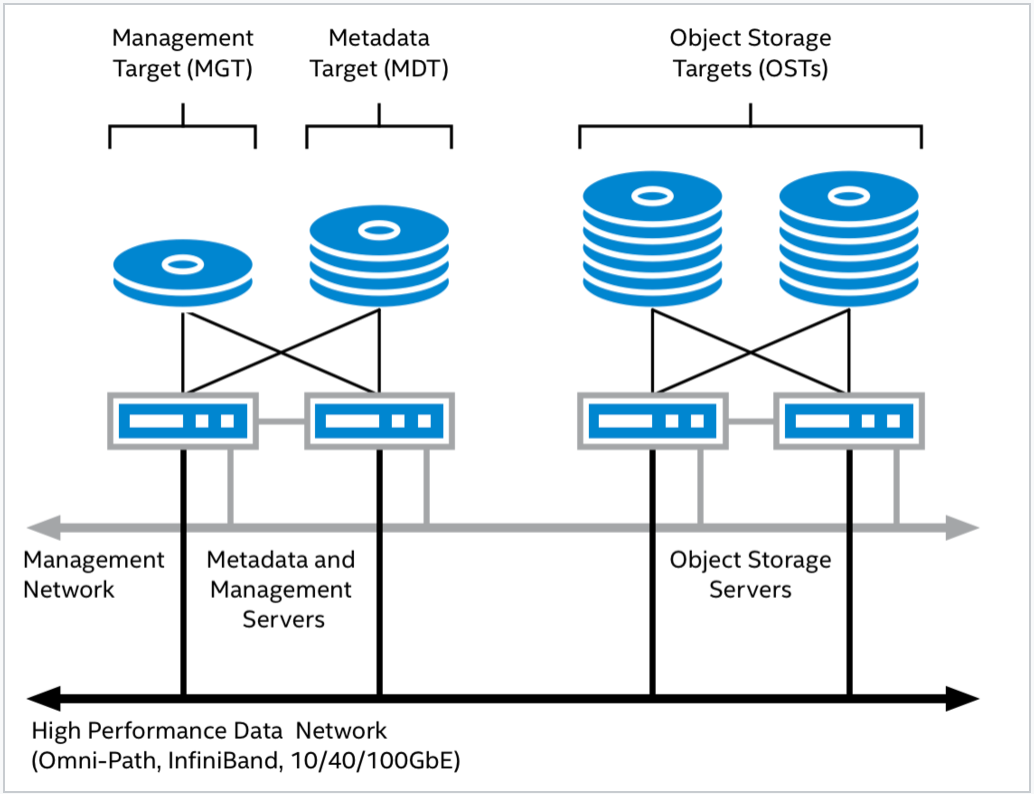
Lustre 采用传统的客户端 - 服务器架构,由以下几个核心模块组成:
- 元数据服务器(MDS):负责处理命名空间相关操作,如文件创建、删除、权限检查等。自 2.4 版本起引入了分布式命名空间(DNE)功能,支持将单个文件系统的不同目录分布在多个元数据服务器上,实现元数据访问负载的横向扩展。
- 对象存储服务器(OSS):负责实际的数据读写,提供高性能的大规模 I/O 服务。
- 管理服务器(MGS):作为全局配置注册中心,负责存储和分发 Lustre 文件系统的配置信息。MGS 在功能上独立于具体的 Lustre 实例。
- 客户端(Client):为用户应用程序提供访问 Lustre 文件系统的接口,实现标准的 POSIX 文件操作语义。
各组件通过 Lustre 专用的网络协议 LNet 连接,构成一个统一高效的文件系统整体。
JuiceFS
JuiceFS 采用模块化架构,包括三个核心组件:
- 元数据引擎:用于存储文件元数据,包括常规文件系统的元数据和文件数据的索引。社区版支持 Redis、TiKV、MySQL、PostgreSQL、FoundationDB 等多种数据库。企业版使用自研高性能元数据服务。
- 数据存储:一般是对象存储服务,可以是公有云的对象存储也可以是私有部署的对象存储服务。支持 30 多种对象存储,包括 AWS S3、Azure Blob、Google Cloud Storage、MinIO、Ceph RADOS 等。
- 客户端:提供 POSIX(FUSE)、Hadoop SDK、CSI Driver、S3 网关、Python SDK 等不同的接入方式。

架构差异
客户端实现
Lustre 采用 C 语言实现,其客户端模块运行在内核态;而 JuiceFS 使用 Go 语言开发,客户端通过 FUSE(Filesystem in Userspace)暴露文件系统接口,运行在用户态。由于 Lustre 客户端运行于内核空间,访问元数据服务器(MDS)或对象存储服务器(OSS)时无需进行用户态与内核态的上下文切换或额外的内存拷贝,从而显著减少了系统调用所带来的性能开销,在吞吐和延迟方面具备一定优势。
然而,内核态实现也带来了运维和调试的复杂性。相比用户态的开发环境和调试工具,内核态工具门槛更高,不易为普通开发者所掌握。同时,与 C 语言相比,Go 语言更易于学习、维护和开发,具备更高的开发效率和可维护性。
存储模块
Lustre 在部署时通常需要配置一块或多块共享磁盘来存储文件数据。这一设计源于其早期版本尚不支持文件级冗余(File Level Redundancy,FLR)。为了实现高可用性(HA),当某个节点下线时,必须将其文件系统挂载到对等节点,否则该节点上的数据块将不可访问�。因此,数据的可靠性需依赖于共享存储本身的高可用机制,或用户自行配置的软件 RAID 实现。
JuiceFS 利用对象存储作为数据存储解决方案,从而可享有对象存储带来的若干优势,如数据可靠性、一致性等。用户可以根据自己的需求对接具体的存储系统,既包括主流云厂商的对象存储,也支持如 MinIO、Ceph RADOS 等私有部署的对象存储系统。社区版 JuiceFS 提供本地缓存来应对 AI 场景下的带宽需求,企业版使用分布式缓存满足更大的聚合读带宽的需求。
元数据模块
Lustre 的 MDS 高可用性依赖于软硬件协同实现:
- 硬件层面:MDS 使用的磁盘需配置 RAID,以避免因单点磁盘故障导致服务不可用;磁盘也需具备共享能力,以便当主节点宕机时,备节点能接管磁盘资源。
- 软件层面:使用 Pacemaker 与 Corosync 构建高可用集群,确保任一时刻仅有一个 MDS 实例处于活动状态。
JuiceFS 社区版的元数据模块提供一组操作元数据的接口,可以接入不同的元数据服务,包括 Redis、TiKV、MySQL、PostgreSQL、FoundationDB 等不同类型的数据库。JuiceFS 企业版使用自研高性能元数据服务,可根据负载情况来平衡数据和热点操作,以避免大规模训练中元数据服务热点集中在某些节点的问题。
文件分布对比
Lustre 文件分布
Normal File Layout (NFL)
Lustre 早期采用的文件分布方式被称为 Normal File Layout。在该模式下,文件被切分为多个数据块,并分别存储在多个对象存储目标(OSTs)上,其策略类似于 RAID 0。
文件分布策略主要由以下两个参数控制:
- Stripe Count:指定文件可以同时分布到多少个 OST 上。该值越大,文件并行访问能力越强,但也可能带来额外的调度和管理开销。
- Stripe Size:定义在切换到下一个 OST 之前,每个数据块的大小。也就是说,写入达到设定的 Stripe Size 后,数据将被写入下一个 OST,这也决定了每个 Chunk 的粒度。
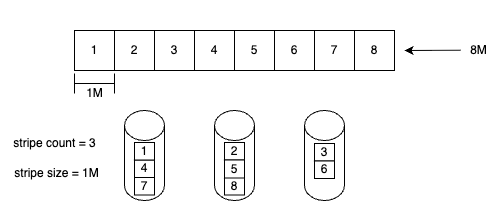
上图展示了一个 Stripe Count 为 3、Stripe Size 为 1 MB 的文件在多个 OST 上的分布方式。每个数据块(Stripe)采用轮询(Round-Robin)方式依次分布到不同的 OST 上。
主要限制包括:
- 一旦文件创建,配置参数不可变
- 如果任何目标 OST 空间耗尽,可能导致 ENOSPC(空间不足)错误
- 随时间推移可能导致存储不均衡
Progressive File Layout (PFL)
为了解��决 NFL 在应对动态数据增长和资源分配方面存在的局限,Lustre 引入了一种新的文件分布机制,称为 Progressive File Layout (PFL)。
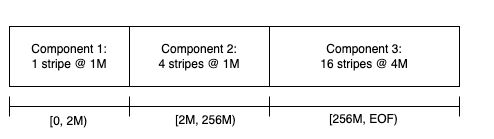
PFL 支持为同一个文件的不同区段定义不同的布局策略,具备以下优势:
- 动态适应文件增长
- 减缓磁盘不均衡问题
- 提高空间利用率和灵活性
虽然 PFL 引入了更具弹性的布局策略,但 Lustre 进一步结合 Lazy Initialization 技术,以实现更高效的资源调度。
File Level Redundancy (FLR)
Lustre 引入了文件级冗余来简化 HA 架构并提升系统容错能力。FLR 允许为每个文件配置一个或多个副本,实现文件级别的冗余保护。在写入操作发生时,数据仅写入其中一个副本,其余副本会被标记为 STALE(过期)。随后,系统通过一个称为 Resync 的同步过程,确保数据一致性。
JuiceFS 文件分布
JuiceFS 按照 Chunk、Slice、Block 的规则进行数据块管理。每个 Chunk 的大小固定为 64M,主要用于优化数据的查找和定位。实际的文件写入操作则在 Slice 上执行,每个 Slice 代表一次连续的写入过程,属于特定的 Chunk,并且不会跨越 Chunk 的边界,因此长度不超过 64M。Block(默认大小为 4M)则是物理存储的基本单位,用于在对象存储�和磁盘缓存中实现数据的最终存储。

JuiceFS 中的 Slice 是在其他文件系统中不常见的一个结构。主要功能是记录文件的写入操作,并在对象存储中进行持久化。对象存储不支持原地文件修改,因此,JuiceFS 通过引入 Slice 结构允许更新文件内容,而无需重写整个文件。当修改文件时,系统会创建新的 Slice,并在该 Slice 上传完毕后更新元数据,从而将文件内容指向新的 Slice。
JuiceFS 的所有 Slice 均为一次性写入,这减少了对底层对象存储一致性的依赖,并大大简化了缓存系统的复杂度,使数据一致性更易于保证。
功能特性对比
| 功能特性 | Lustre | JuiceFS 社区版 | JuiceFS 企业版 |
|---|---|---|---|
| 元数据 | 分布式元数据服务 | 独立数据库服务 | 自研高性能分布式元数据引擎(可横向扩展) |
| 元数据冗余保护 | 需要存储设备提供 | 取决于使用的数据库 | 三副本 |
| 数据存储 | 自主管理 | 使用对象存储 | 使用对象存储 |
| 数据冗余保护 | 存储设备提供或异步复制 | 对象存储提供 | 对象存储提供 |
| 数据缓存 | 客户端本地缓存 | 客户端本地缓存 | 自研高性能多副本分布式缓存 |
| 数据加密 | 支持 | 支持 | 支持 |
| 数据压缩 | 支持 | 支持 | 支持 |
| 配额管理 | 支持 | 支持 | 支持 |
| 网络协议 | 支持多种网络协议 | TCP | TCP |
| 快照 | 文件系统级别快照 | 文件级别快照 | 文件级别快照 |
| POSIX ACL | 支持 | 支持 | 支持 |
| POSIX 兼容性 | 兼容 | 完全兼容 | 完全兼容 |
| CSI 驱动 | 非官方支持 | 支持 | 支持 |
| 客户端 | POSIX | POSIX(FUSE)、Java SDK、S3 网关、Python SDK | POSIX(FUSE)、Java SDK、S3 网关、Python SDK |
| 多云镜像 | 不支持 | 不支持 | 支持 |
| 跨云和跨区数据复制 | 不支持 | 不支持 | 支持 |
| 主要维护者 | DDN | Juicedata | Juicedata |
| 开发语言 | C | Go | Go |
| 开源协议 | GPL 2.0 | Apache License 2.0 | 商业软件 |
小结
Lustre 是一款高性能并行分布式文件系统,客户端运行于内核态,直接与元数据服务器(MDS)和对象存储服务器(OSS)交互,避免了用户态与内核态之间的上下文切换。结合高性能存储设备,Lustre 在高带宽 I/O 场景下展现出卓越的性能。
然而,由于客户端运行在内核态,这使得运维过程更具挑战性,运维团队需具备深入的内核调试经验和底层系统故障排查能力。此外,由于 Lustre 使用固定容量的存储方案,文件分布设计相对复杂,需要精细的规划与配置来实现资源的高效利用。因此,Lustre 的部署和运维门槛较高。
JuiceFS 是一款云原生、用户态分布式文件系统,紧密集成对象存储,并原生支持 Kubernetes CSI,从而简化了在云平台上的部署和运维。用户无需深入关注底层存储设备和复杂的存储调度机制,即可在容器化环境中实现弹性扩展、高可用数据服务。在性能方面,JuiceFS 企业版通过分布式缓存,有效降低对象存储的访问延迟,提升文件操作的响应速度。
从成本角度看,Lustre 需要依赖高性能的专用存储设备,初始投资和长期维护成本较高。对象存储则更加经济,具备天然的可扩展性以及按需付费的灵活性。
两个系统各有优势:Lustre 在传统 HPC 环境中追求极致性能方面表现卓越,而 JuiceFS 在云原生和 AI 工作负载方面提供了更好的灵活性、更容易的管理和更高的性价比。


