













JuiceFS 是一款面向云原生环境设计的高性能 POSIX 文件系统,在 AGPL v3.0 开源协议下发布。作为一个云上的分布式文件系统,任何存入 JuiceFS 的数据都会按照一定规则拆分成数据块存入对象存储(如 Amazon S3),相对应的元数据则持久化在独立的数据库中。这种结构决定了 JuiceFS 的存储空间可以根据数据量弹性伸缩,可靠地存储大规模的数据,同时支持在多主机之间共享挂载,实现跨云跨地区的数据共享和迁移。
从 v0.13 发布以来, JuiceFS 新增了多项与性能监测和分析相关的功能,从某种程度上说,开发团队希望 JuiceFS 既能提供大规模分布式计算场景下的出色性能,也能广泛地覆盖更多日常的使用场景。
本文我们从单机应用入手,看依赖单机文件系统的应用是否也可以用在 JuiceFS 之上,并分析它们的访问特点进行针对性的调优。
测试环境
接下来的测试我们会在同一台亚马逊云服务器上进行,配置情况如下:
- 服务器配置:Amazon c5d.xlarge: 4 vCPUs, 8 GiB 内存, 10 Gigabit 网络, 100 GB SSD
- JuiceFS:使用本地自建的 Redis 作为元数据引擎,对象存储使用与服务器相同区域的 S3。
- EXT4:直接在本地 SSD 上创建
- 数据样本:使用 Redis 的源代码作为测试样本
测试项目一:Git
常用的 git 系列命令有 clone、status、add、diff 等,其中 clone 与编译操作类似,都涉及到大量小文件写。这里我们主要测试 status 命令。
分别将代码克隆到本地的 EXT4 和 JuiceFS,然后执行 git status 命令的耗时情况如下:
- Ext4:0m0.005s
- JuiceFS:0m0.091s
可见,耗时出现了数量级的差异。如果单从测试环境的样本来说,这样的性能差异微乎其微,用户几乎是察觉不到的。但如果使用规模更大的代码仓库时,二者的性能差距就会逐渐显现。例如,假设两者耗时都乘以 100 倍,本地文件系统需要约 0.5s,尚在可接受范围内;但 JuiceFS 会需要约 9.1s,用户已能感觉到明显的延迟。为搞清楚主要的耗时点,我们可以使用 JuiceFS 客户端提供的 profile 工具:
$ juicefs profile /mnt/jfs在分析过程中,更实用的方式是先记录日志,再用回放模式:
$ cat /mnt/jfs/.accesslog > a.log
# 另一个会话:git status
# Ctrl-C 结束 cat
$ juicefs profile --interval 0 a.log结果如下:
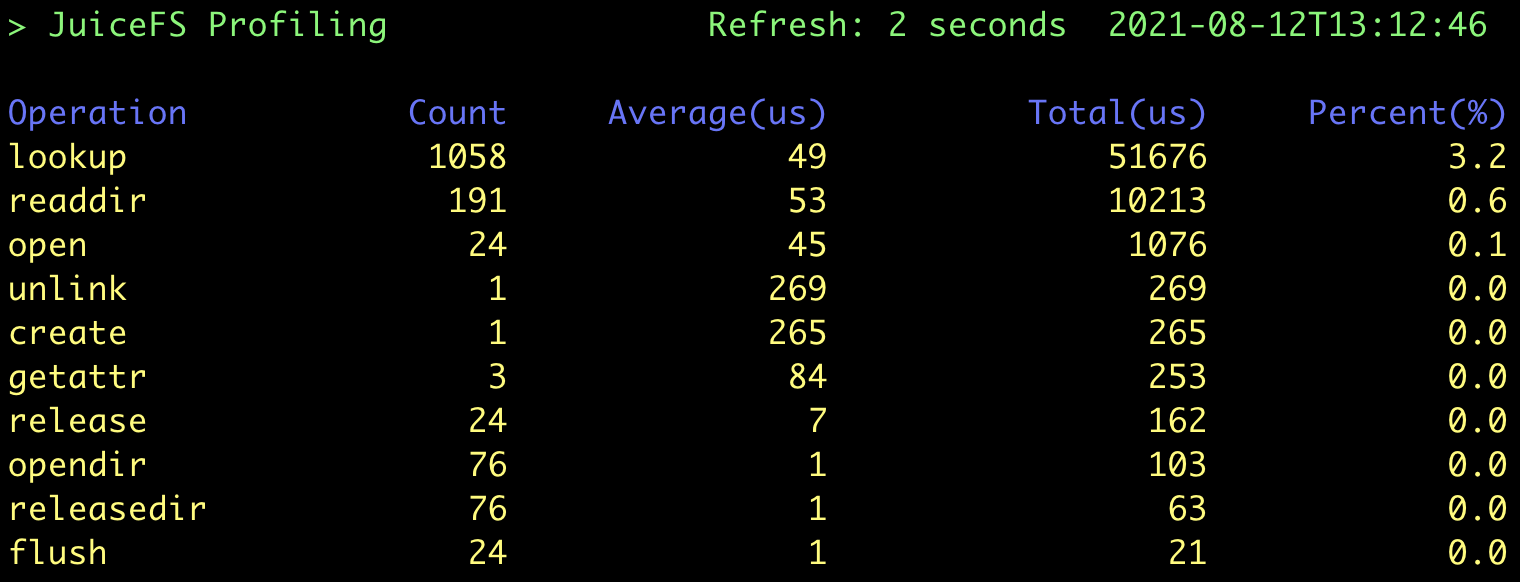
这里可以清楚地看到有大量的 lookup 请求,我们可以通过调整 FUSE 的挂载参数来延长内核中元数据的缓存时间,比如使用以下参数重新挂载文件系统:
$ juicefs mount -d --entry-cache 300 localhost /mnt/jfs然后我们再用 profile 工具分析,结果如下:
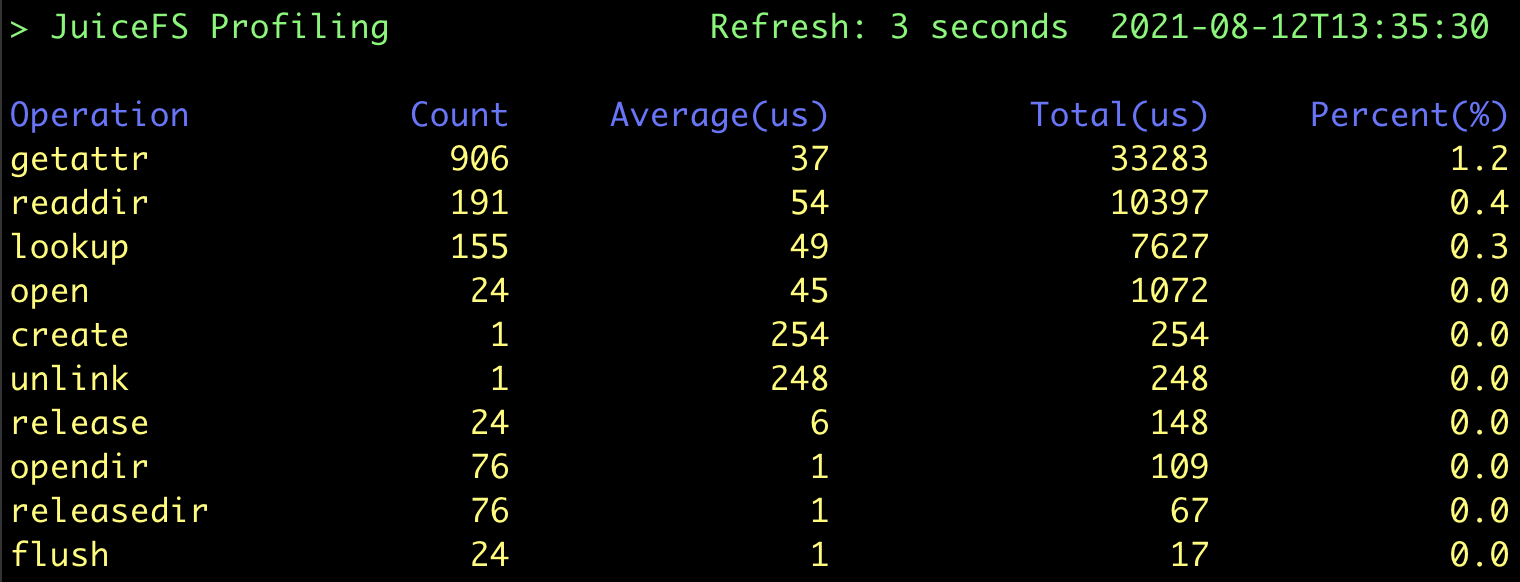
可以看到,lookup 请求减少了很多,但都转变成了 getattr 请求,因此还需要属性的缓存:
$ juicefs mount -d --entry-cache 300 --attr-cache 300 localhost /mnt/jfs此时测试发现 status 命令耗时下降到了 0m0.034s,profile 工具结果如下:
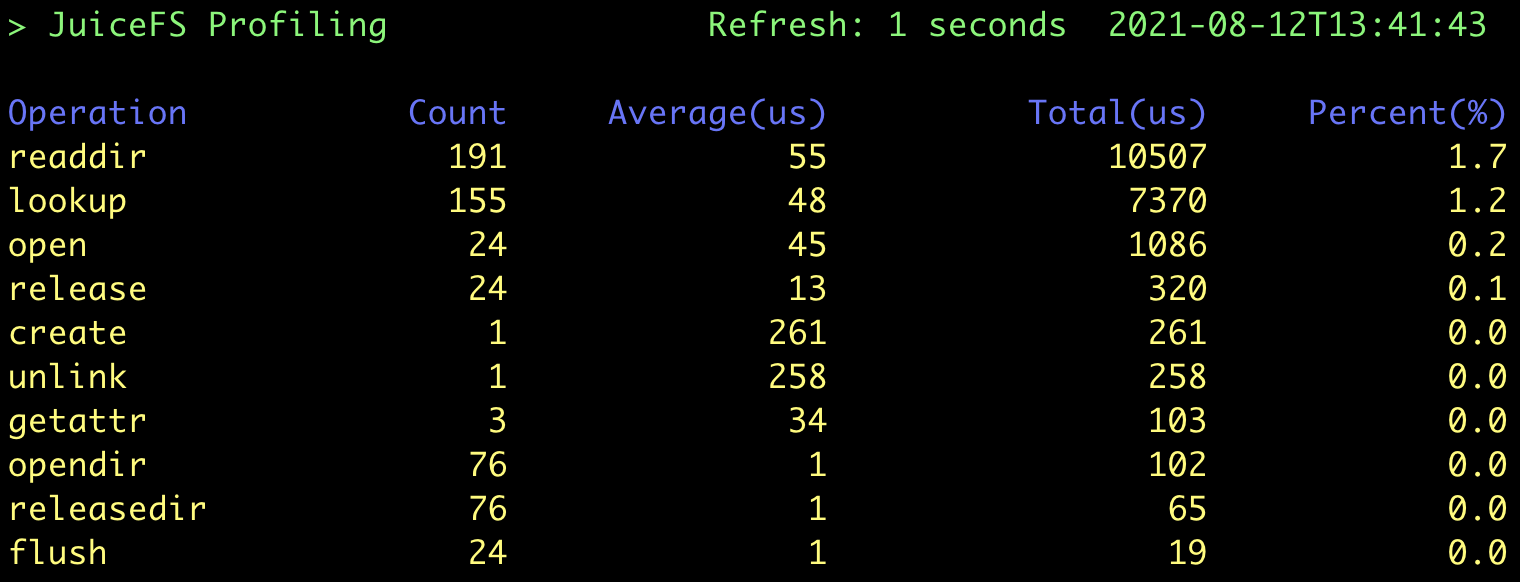
可见一开始最耗时的 lookup 已经减少了很多,而 readdir 请求变成新的瓶颈点。我们还可以尝试设置 --dir-entry-cache,但提升可能不太明显。
测试项目二:Make
大型项目的编译时间往往需要以小时计,因此编译时的性能显得更加重要。依然以 Redis 项目为例,测试编译的耗时为:
- Ext4:0m29.348s
- JuiceFS:2m47.335s
我们尝试调大元数据缓存参数,整体耗时下降约 10s。通过 profile 工具分析结果如下:
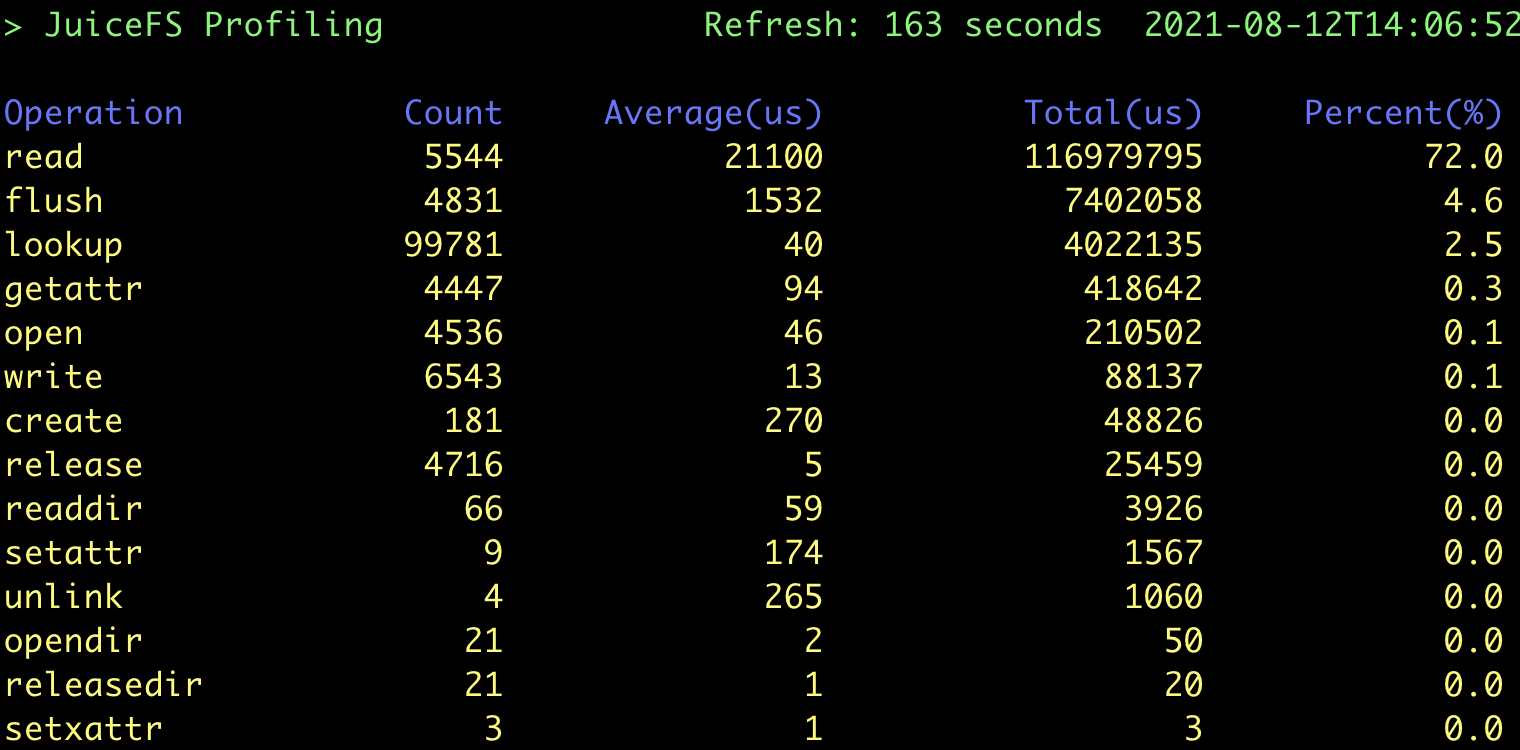
显然这里的数据读写是性能关键,我们可以使用 stats 工具做进一步的分析:
$ juicefs stats /mnt/jfs其中一段结果如下:
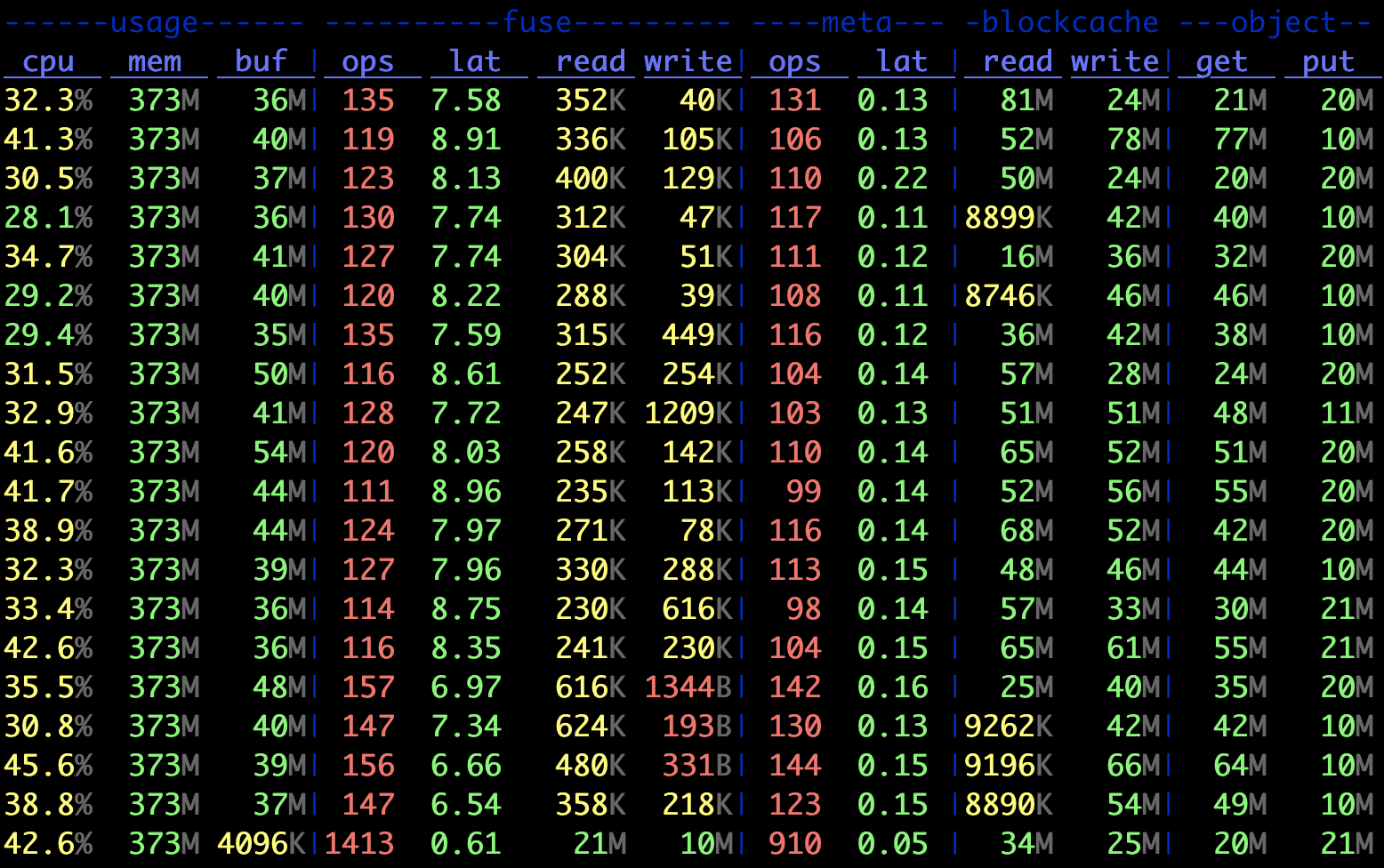
从上图可见 fuse 的 ops 与 meta 接近,但平均 latency 远大于 meta,因此可以判断出主要的瓶颈点在对象存储侧。不难想象,编译前期产生了大量的临时文件,而这些文件又会被编译的后几个阶段读取,以通常对象存储的性能很难直接满足要求。好在 JuiceFS 提供了数据 writeback 模式,可以在本地盘上先建立写缓存,正好适用于编译这种场景:
$ juicefs mount -d --entry-cache 300 --attr-cache 300 --writeback localhost /mnt/jfs此时编译总耗时下降到 0m38.308s,已经与本地盘非常接近了。后阶段的 stats 工具监控结果如下:
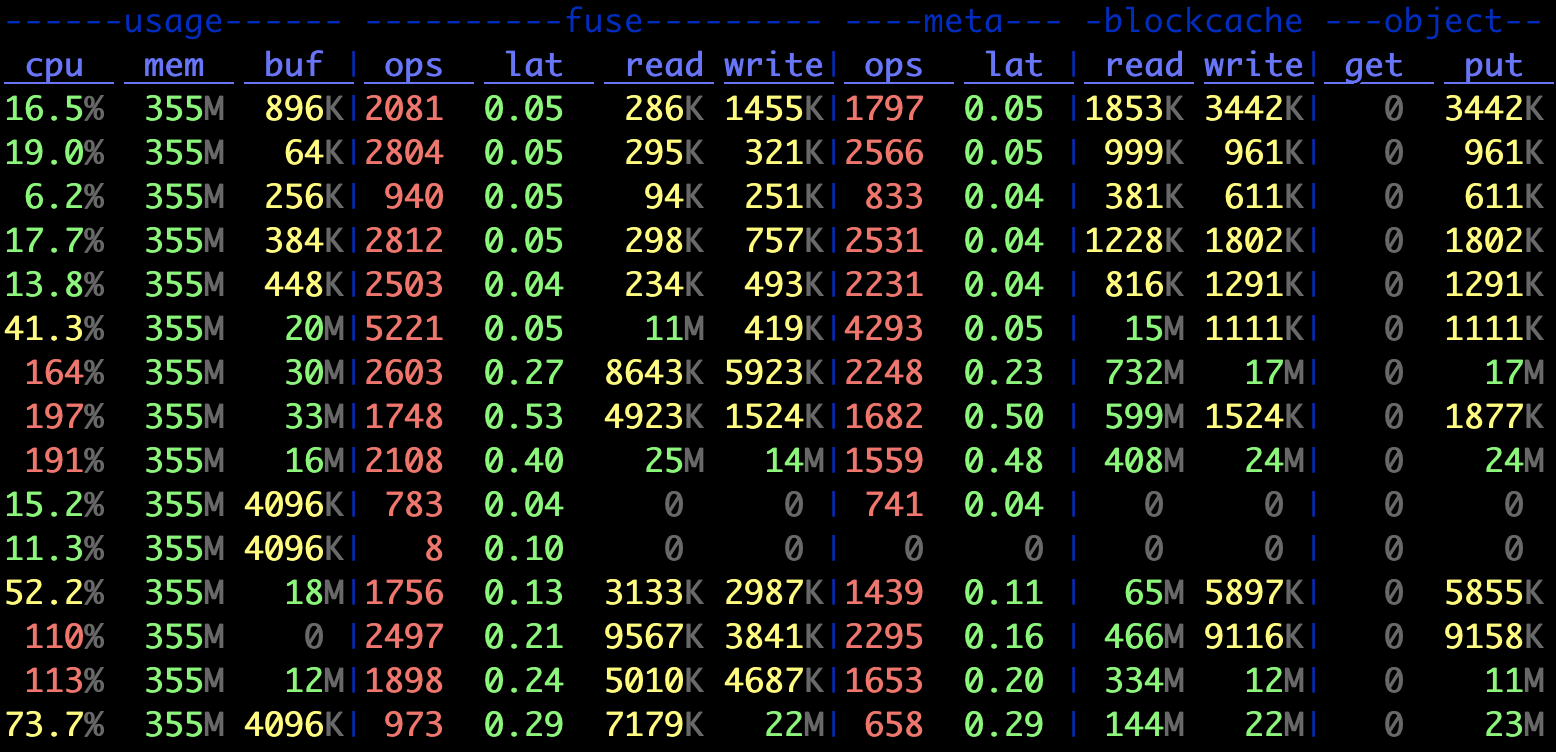
可见,读请求基本全部在 blockcache 命中,而不再需要去访问对象存储;fuse 和 meta 侧的 ops 统计也得到了极大提升,与预期吻合。
总结
本文以本地文件系统更擅长的 Git 仓库管理和 Make 编译任务为切入点,评估这些任务在 JuiceFS 存储上的性能表现,并使用 JuiceFS 自带的 profile 与 stats 工具进行分析,通过调整文件系统挂载参数做针对性的优化。
毫无疑问,本地文件系统与 JuiceFS 等分布式文件系统存在着天然的特征差异,二者面向的应用场景也截然不同。本文选择了两种特殊的应用场景,只是为了在差异鲜明的情境下介绍如何为 JuiceFS 做性能调优,旨在抛砖引玉,希望大家举一反三。如果你有相关的想法或经验,欢迎在 JuiceFS 论坛或用户群分享和讨论。
开源社区贡献指南
JuiceFS 是在 AGPLv3 协议下开源的项目,开源软件的发展离不开每一个人的支持,一篇文章、一页文档、一个想法、一个建议、报告或修复一个 Bug,这些贡献不论大小都是推动开源项目不断发展的动力。
你可以为开源社区做的事情:
- 加星关注项目 https://github.com/juicedata/juicefs
- 在论坛发表你的看法
- 在 Issues 认领开发任务
- 完善 JuiceFS 开源文档
- 在你自己的博客、微博、微信、Vlog 等自媒体分享有关 JuiceFS 的一切
- 加入 JuiceFS 的微信群或 Slack 频道
- 把 JuiceFS 告诉更多人,让更多人使用由你我共同维护的产品!
我们诚挚的邀请每一个热爱开源的人加入到我们的社区,让我们一起把 JuiceFS 做的更好!




